
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Veamos ahora cómo pueden utilizarse los grafos de conocimiento para mejorar los LLM.
Los LLM son capaces de generar textos bien escritos, pero no pueden evaluar su exactitud fáctica. En la mayoría de los casos, el conjunto de datos de entrenamiento original no tenía información (como un manual de usuario específico) relevante para una tarea práctica (como responder a las consultas de los usuarios sobre cómo utilizar una herramienta concreta).
Un LLM con acceso a información contextual y específica del dominio puede utilizar ese conocimiento para formular respuestas significativas y correctas. Los KG permiten a los LLM acceder mediante programación a información relevante y objetiva, respondiendo así mejor a las consultas de los usuarios.
Los grafos de conocimiento sirven para organizar, almacenar y recuperar información semánticamente. Sin embargo, sólo se puede acceder a ellos mediante lenguajes de consulta especializados como SPARQL (un lenguaje de consulta de bases de datos para manipular y recuperar datos almacenados en formato RDF).
El resultado de los KG también está en forma de código y los usuarios necesitan una formación específica para interpretarlo. Los LLM cubren este vacío convirtiendo las peticiones de los usuarios en lenguaje llano a lenguaje de consulta y generando texto legible por humanos a partir de la salida de la KG. Así, permiten a los usuarios no técnicos interactuar con las KG.
El texto generado por los LLM depende del conjunto de datos de entrenamiento, que a menudo está obsoleto en el momento en que el LLM se pone en producción. Volver a formar continuamente a los LLM en información actualizada requiere muchos recursos y, por tanto, es poco práctico.
Sin embargo, las KG, como cualquier otra base de datos, pueden actualizarse fácilmente en tiempo real. Sólo hay una ligera sobrecarga computacional para actualizar las conexiones entre nodos basándose en la nueva información. Así, al integrarse con los KG, los LLM pueden acceder a información actualizada en tiempo real y dar respuestas actualizadas.
A continuación se describen los pasos clave de un flujo de trabajo de ejemplo que utiliza conjuntamente KGs y LLMs para dar respuestas actualizadas a las consultas de los usuarios.
La figura siguiente muestra un esquema de estos pasos:
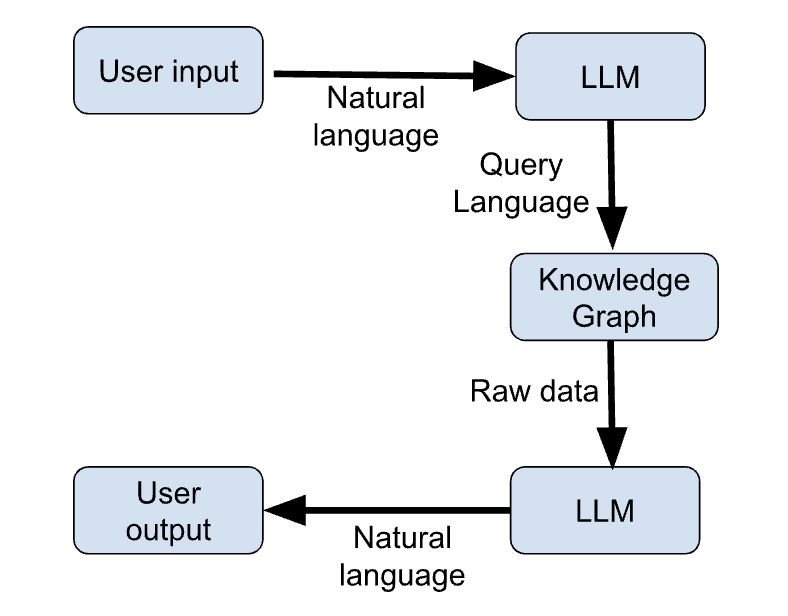
Figura 1: Flujo de trabajo LLM + KG (imagen del autor)
Son muchos los casos de uso que permite la integración de las KG y la GenAI. Repasemos las más interesantes.
Las KG proporcionan un repositorio de conocimientos estructurado y actualizado al que un chatbot puede acceder mediante programación para obtener información actualizada y ofrecer respuestas más relevantes a las consultas de los usuarios.
El KG complementa el conocimiento por defecto del chatbot, que se basa en el conjunto de datos de entrenamiento. El chatbot aprende a construir frases basándose en el conjunto de datos de entrenamiento y adquiere información específica de la aplicación de la KG. Así, el uso de KGs también permite utilizar la misma arquitectura de chatbot para diferentes aplicaciones sin necesidad de reentrenamiento.
Los LLM se han utilizado como motores de recomendación.
Por ejemplo, un LLM puede analizar el contenido de un artículo y recomendar artículos relevantes. Los LLM también se utilizan para crear sistemas interactivos, en los que el usuario puede "hablar" con el motor de recomendación.
Las KG pueden organizar y almacenar información sobre el comportamiento de los usuarios, sus intereses, interacciones, etc. Los LLM pueden analizar esta información y utilizarla para generar respuestas a medida. Así, los usuarios se benefician de recomendaciones personalizadas basadas en sus preferencias individuales.
En ámbitos basados en el conocimiento como la medicina, las finanzas y el derecho, los LLM combinados con los KG mejoran la facilidad de acceso a la información.
En medicina, sugieren posibles diagnósticos basándose en los síntomas y el historial del paciente. En finanzas, complementan los esfuerzos de los analistas facilitando el acceso a la información relevante de los informes financieros. En Derecho, ayudan a los abogados recuperando casos y sentencias anteriores relevantes y proporcionando resúmenes de grandes documentos jurídicos.
Combinar grandes modelos lingüísticoscon grafos de conocimiento es fundamental en aplicaciones en tiempo real como la agregación de noticias y el análisis bursátil.
Los LLM tradicionales no conocen acontecimientos que no se hayan producido durante la formación. Por tanto, no pueden dar respuestas significativas a preguntas basadas en temas de actualidad.
Los KG son eficientes procesando y organizando nueva información en tiempo real. Así, proporcionan el backend informático para que los LLM gestionen aplicaciones basadas en la actualidad (agregación de noticias) y entornos que cambian rápidamente (por ejemplo, el mercado de valores).
En los apartados anteriores se han tratado los principios básicos de los LLM y los KG. En esta sección, presentamos las herramientas y bibliotecas utilizadas para integrar los KG y los LLM.
Las KG se implementan más comúnmente utilizando bases de datos de grafos como:
Una base de datos de grafos especializada (sólo funciona con grafos). Neo4j utiliza Cypher, un lenguaje declarativo de consulta de grafos, para insertar y recuperar información. Cypher es estilísticamente similar a SQL, lo que facilita su aprendizaje a los desarrolladores.
Neo4j gestiona eficazmente datos complejos interconectados porque su motor de almacenamiento de datos subyacente está construido desde cero para adaptarse a los casos de uso de las bases de datos de grafos. Es una opción popular para las bases de datos de grafos porque se conecta a fuentes de datos externas como Apache Kafka y es fácil de escalar horizontalmente.
ArangoDB es una base de datos gráfica multimodelo. Además de gráficos, también admite documentos JSON y almacenes de valores clave. Esto permite a los usuarios mejorar los gráficos con otra información que no pueda convertirse fácilmente a formato gráfico.
Debido a esta flexibilidad, a menudo se prefiere para aplicaciones empresariales que manejan diversos tipos de datos. Utiliza el Lenguaje de Consulta Arango (AQL) para trabajar con todos los tipos de datos. Bajo el capó, ArangoDB utiliza RocksDB como motor de almacenamiento de datos.
Neptune de Amazon admite gráficos de propiedades y modelos RDF (Marco de Descripción de Recursos). Utiliza los lenguajes de consulta SPARQL y Gremlin. Se integra perfectamente en la infraestructura de AWS para ejecutarse como una base de datos gráfica totalmente administrada, lo que la convierte en una opción habitual para integrarse en la infraestructura existente para aplicaciones empresariales.
Los LLM y las bases de datos de grafos se complementan, pero en general no pueden interactuar directamente. En los párrafos siguientes, hablaremos de las bibliotecas y marcos de integración utilizados para canalizar datos de los KG a los LLM y viceversa.
RDFlib es un paquete Python de código abierto para trabajar con datos RDF. Dispone de funciones para manipular y consultar grafos RDF. Esto facilita la integración con los gráficos de conocimiento. Permite almacenar datos RDF en memoria, en disco o remotamente mediante endpoints SPARQL. Un punto final SPARQL, análogo a un punto final API, puede recibir y procesar consultas SPARQL remotas.
RDFlib trabaja con estructuras de datos basadas en grafos y formadas por tripletas sujeto-predicado-objeto. Cada componente de la tripleta es un URI o un valor literal. Tiene funciones para analizar y serializar triplas, XML y otros tipos de datos como JSON-LD.
PyTorch Geometric (PyG) es una biblioteca basada en PyTorch diseñada para crear y entrenar Redes Neuronales Gráficas (GNNs). Una GNN es una arquitectura de red neuronal que funciona con grafos y puede aceptar estructuras de datos de grafos como entrada. PyG tiene funciones para aplicar técnicas de aprendizaje profundo a los grafos.
PyG incluye muchas arquitecturas GNN preconstruidas que pueden implementarse directamente o ampliarse mediante la API de paso de mensajes.
Se afirma que PyG es adecuado para aplicaciones a gran escala con millones de nodos de distintos tipos de nodos y aristas. Este subcampo también se conoce como aprendizaje profundo geométrico.
Las redes neuronales tradicionales son buenas para codificar relaciones lineales, pero los datos del mundo real suelen ser complejos y multidimensionales. Los grafos son mejores para representar interconexiones de mayor dimensión, en las que cualquier nodo de un grafo puede relacionarse con cualquier otro nodo. Esto hace que los gráficos sean más adecuados para almacenar relaciones complejas del mundo real.
LangChain se lanzó en 2022 como marco de integración de modelos lingüísticos. Facilita la creación de aplicaciones de usuario encadenando LLM con otras herramientas relevantes, como envoltorios de API, scripts de shell, raspadores web, lectores de PDF, Google Docs, bases de datos relacionales, bases de datos vectoriales y bases de datos gráficas (incluidas las KG). Por lo tanto, se utiliza habitualmente para crear aplicaciones que impliquen LLMs.
Las API de OpenAI eliminan la molestia de construir una canalización utilizando herramientas como PyG. La API de OpenAI puede recibir la consulta en lenguaje natural de un usuario, comprenderla y devolver una consulta estructurada en un lenguaje de programación (por ejemplo, SPARQL). Esta consulta se introduce en la KG, que devuelve los datos relevantes. Estos datos se envían de vuelta a la API de OpenAI, junto con el contexto de la consulta original. El OpenAI LLM genera una respuesta en lenguaje natural basada en los datos recuperados de la KG.
Las API de OpenAI te permiten elegir entre distintos LLM, en función de la tarea y el presupuesto. Por tanto, no necesitas desplegar LLMs ni las canalizaciones de datos para interactuar con la KG.
En esta sección, proporcionamos una ilustración de alto nivel de un canal de integración utilizando pseudocódigo.
Utilizamos Neo4j, LangChain y la API OpenAI para mostrar los pasos para crear un chatbot basado en RAG. El LLM genera su respuesta basándose en la información almacenada en el KG.
## Import relevant packages
# Handling chat prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_openai import ChatOpenAI
# Implementing the Runnable protocol for chaining components
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
# Processing text inputs in the chat
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# Working with Neo4j graphs
from neo4j import GraphDatabase
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
# Vector embeddings for the LLM
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Load data from a source like Wiki, PDF documents, etc.
from langchain.document_loaders import WikipediaLoader
# Create a Neo4jGraph to store the KG
graph = Neo4jGraph()
# Load the document(s) based on which to build the KG. In this snippet, we use Wiki. In practice, this is a business-specific document
raw_documents = WikipediaLoader(...).load()
# Split the document into tokens
documents = create_tokens(raw_documents)
# Instantiate the LLM
llm = ChatOpenAI(model_name="...", …)
llm_transformer = LLMGraphTransformer(llm=llm)
# Use the LLM to convert the tokenized documents into graph entities
graph_docs = llm_transformer.convert_to_graph_documents(documents)
# Add the graph entities to the Neo4j graph
graph.add_graph_documents(graph_docs, …)
# Create a retriever to run on the graph
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
# Create a class to extract entities from the text corresponding to nodes from the graph
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that appear in the text",
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Create a chain by piping the prompt to the LLM with the Entities class.
# This chain identifies entities in a given prompt string
entity_chain = prompt | llm.with_structured_output(Entities)
# Create a structured retriever to extract the entities in the query. Given a text query, it retrieves all the relevant nodes in the neighborhood of the entities in that query.
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
# CYPHER QUERY TEMPLATE,
{"query": generate_full_text_query(entity)})
result += el['output'] for el in response
return result
# Chain together the different components
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Invoke the chain
chain.invoke({"question": "The user’s question goes here"})Las KG aumentan las capacidades de las LLM y las hacen relevantes para casos de uso práctico. Para conseguir el mejor rendimiento, recomiendo las siguientes prácticas recomendadas.
El KG contiene el repositorio de información a partir del cual el LLM formula sus respuestas. Por tanto, es necesario actualizar continuamente la base de datos gráfica con la información más reciente. Un KG obsoleto hace que el LLM dé respuestas obsoletas.
Los LLM y los KG son programas complejos con grandes requisitos computacionales. Como se ha mostrado en la sección anterior, encadenar LLM y KG implica muchos pasos, desde la tokenización de la consulta del usuario y la generación de la consulta del grafo relevante, hasta la recuperación de la información del KG y la generación de texto a partir de ella.
Esto puede provocar ineficiencias y retrasos entre la consulta y la respuesta. Los métodos de optimización, como se explica a continuación, ayudan a minimizar la latencia.
Los LLM son modelos que consumen mucha memoria y a menudo necesitan un hardware caro para funcionar. Es útil reducir el tamaño de los modelos de IA utilizando técnicas como la Destilación LLM y la Cuantización:
Debes asegurarte de que el modelo lingüístico elegido funciona bien con el tipo de consultas que se espera que gestione.
Herramientas como MLFlow ayudan a evaluar el rendimiento del LLM en diversas tareas. Al igual que las necesidades de los usuarios cambian y evolucionan, la información almacenada en el grafo de conocimiento también cambia con el tiempo. Por ello, es esencial reevaluar periódicamente el rendimiento del LLM tras su despliegue. Podría ser necesario afinar el modelo en un conjunto de datos actualizado, utilizar una versión actualizada del modelo, o incluso desplegar un nuevo modelo.
El LLM obtiene información de la KG y sus capacidades lingüísticas y de razonamiento del conjunto de datos de entrenamiento.
Los LLM de modelo base se entrenan en vastos conjuntos de datos genéricos, normalmente utilizando texto de todo Internet. Afinar el LLM en un conjunto de datos de un dominio específico mejora sus capacidades de razonamiento en ese dominio y le permite construir frases utilizando la estructura y la jerga adecuadas. Por ejemplo, para utilizar un LLM para responder a preguntas médicas utilizando una KG médica, recomiendo encarecidamente afinar el LLM base en un conjunto de datos de textos médicos.
En este artículo hemos tratado los principios fundamentales de los Grandes Modelos del Lenguaje (LLM) y los Grafos de Conocimiento (KG) y cómo se complementan entre sí. También presentamos algunas de las herramientas más utilizadas para utilizar conjuntamente LLMs y KGs para construir aplicaciones de cara al usuario. Por último, proporcionamos una ilustración de alto nivel de cómo Neo4j y OpenAI pueden utilizarse juntos utilizando LangChain.
Tras comprender estos conceptos fundamentales, podrás aplicar estas herramientas en la práctica:
Aprende a trabajar con LLMs en Python directamente en tu navegador

¡Aprende más sobre los LLM con estos cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
10 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita

