
Course
Large Language Models (LLMs) Concepts
2 hr
99.8K
Now, let’s see how knowledge graphs can be used to enhance LLMs.
LLMs are capable of generating well-written text, but they cannot assess its factual accuracy. In most cases, the original training dataset did not have information (such as a specific user manual) relevant to a practical task (such as answering user queries about how to use a specific tool).
An LLM with access to contextual and domain-specific information can use that knowledge to formulate meaningful and correct responses. KGs allow LLMs to programmatically access relevant and factual information, thus better responding to user queries.
Knowledge graphs are good for semantically organizing, storing, and retrieving information. However, they can be accessed only via specialized query languages like SPARQL (a database query language for manipulating and retrieving data stored in the RDF format).
The output of KGs is also in code-form and users need specific training to interpret it. LLMs bridge this gap by converting plain-language user requests to query language and by generating human-readable text from the KG’s output. Thus, they allow non-technical users to interface with KGs.
The text generated by LLMs depends on the training dataset, which is often outdated by the time the LLM is put into production. Continuously re-training LLMs on up-to-date information is resource-intensive and thus impractical.
However, KGs, like any other database, can be easily updated in real time. There is only a slight computational overhead to update the connections between nodes based on the new information. Thus, by integrating with KGs, LLMs can access information updated in real time and provide up-to-date responses.
The steps below outline the key steps of an example workflow that uses KGs and LLMs together to give up-to-date responses to user queries.
The figure below shows a schematic sketch of these steps:
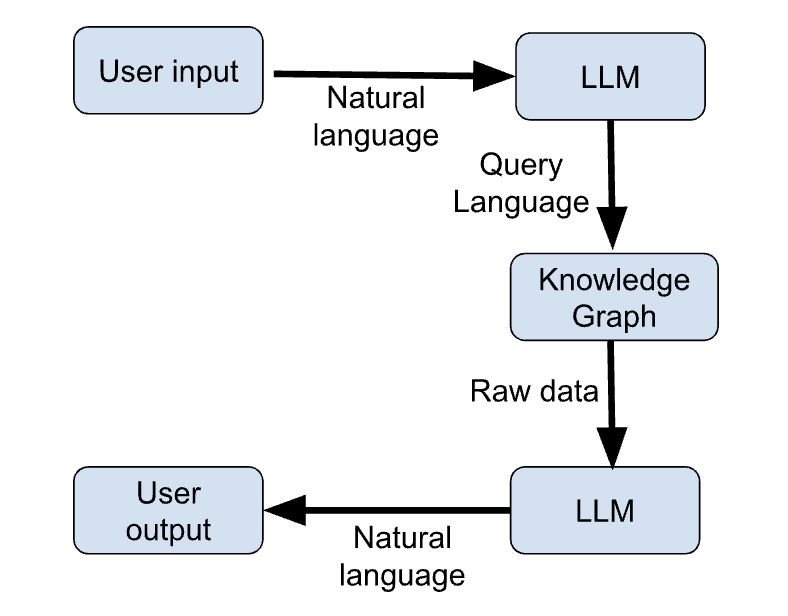
Figure 1: LLM + KG workflow (image by author)
There are many use cases that are enabled by the integration of KGs and GenAI. Let’s review the most interesting ones.
KGs provide a structured and up-to-date repository of knowledge that a chatbot can programmatically access to get current information and provide more relevant responses to user queries.
The KG supplements the chatbot’s default knowledge, which is based on the training dataset. The chatbot learns how to construct sentences based on the training dataset and acquires application-specific information from the KG. Thus, using KGs also allows using the same chatbot architecture for different applications without retraining.
LLMs have been used as recommendation engines.
For example, an LLM can analyze an article's content and recommend relevant articles. LLMs are also used to create interactive systems, where the user can “talk to” the recommendation engine.
KGs can organize and store information on user behavior, interests, interactions, and so on. LLMs can analyze this information and use it to generate tailored responses. Thus, users get the benefit of personalized recommendations based on their individual preferences.
In knowledge-based domains like medicine, finance, and law, LLMs combined with KGs improve the ease of accessing information.
In medicine, they suggest possible diagnoses based on patient symptoms and history. In finance, they supplement analyst efforts by making accessing relevant information from financial reports easier. In law, they aid lawyers by assisting with retrieving relevant past cases and judgments and providing summaries of large legal documents.
Combining Large Language Models with Knowledge Graphs is critical in real-time applications like news aggregation and stock market analysis.
Traditional LLMs don’t know of events that hadn’t occurred during training. Thus, they cannot give meaningful responses to questions based on current affairs.
KGs are efficient at processing and organizing new information in real time. Thus, they provide the informatics backend for LLMs to handle applications based on current affairs (news aggregation) and rapidly changing environments (e.g., the stock market).
The previous sections discussed the basic principles of LLMs and KGs. In this section, we introduce the tools and libraries used for integrating KGs and LLMs.
KGs are most commonly implemented using graph databases like:
A specialized graph database (it works only with graphs). Neo4j uses Cypher, a declarative graph query language, to insert and retrieve information. Cypher is stylistically similar to SQL, which makes it easier for developers to learn.
Neo4j efficiently manages complex interconnected data because its underlying data storage engine is built from scratch to suit graph database use cases. It is a popular choice for graph databases because it connects to external data sources like Apache Kafka and is easy to scale horizontally.
ArangoDB is a multi-model graph database. In addition to graphs, it also supports JSON documents and key-value stores. This allows users to enhance graphs with other information that may not easily be converted to graph format.
Because of this flexibility, it is often preferred for enterprise applications that deal with various kinds of data. It uses the Arango Query Language (AQL) to work across all data types. Under the hood, ArangoDB uses RocksDB as a data storage engine.
Amazon’s Neptune supports property graphs and RDF (Resource Description Framework) models. It uses SPARQL and Gremlin query languages. It seamlessly integrates into the AWS infrastructure to run as a fully managed graph database, making it a common choice for integrating with existing infrastructure for enterprise applications.
LLMs and graph databases complement each other but cannot generally interface directly. In the following paragraphs, we discuss integration libraries and frameworks used to pipe data from KGs into LLMs and vice versa.
RDFlib is an open-source Python package for working with RDF data. It has functions for manipulating and querying RDF graphs. This facilitates integration with knowledge graphs. It allows to store RDF data in memory, on disk, or remotely using SPARQL endpoints. A SPARQL endpoint, analogous to an API endpoint, can receive and process remote SPARQL queries.
RDFlib works with graph-based data structures consisting of subject-predicate-object triples. Each component of the triple is a URI or a literal value. It has functions to parse and serialize triples, XML, and other data types like JSON-LD.
PyTorch Geometric (PyG) is a PyTorch-based library designed to create and train Graph Neural Networks (GNNs). A GNN is a neural network architecture that operates on graphs and can accept graph data structures as input. PyG has functions to apply deep learning techniques to graphs.
PyG comes with many prebuilt GNN architectures that can be directly implemented or further extended via the message-passing API.
PyG is claimed to be suitable for large-scale applications with millions of nodes across different types of nodes and edges. This subfield is also known as geometric deep learning.
Traditional neural networks are good at encoding linear relationships, but real-world data tends to be complex and multidimensional. Graphs are better at representing higher-dimensional interconnections where any node in a graph can relate to any other node. This makes graphs better suited to store complex real-world relationships.
LangChain was launched in 2022 as a language model integration framework. It facilitates building user applications by chaining together LLMs with other relevant tools, like API wrappers, shell scripts, web scrapers, PDF readers, Google Docs, relational databases, vector databases, and graph databases (including KGs). Thus, it is commonly used to create applications involving LLMs.
OpenAI APIs remove the hassle of building a pipeline using tools like PyG. The OpenAI API can receive a user’s natural language query, understand it, and return a structured query in a programming language (e.g., SPARQL). This query is fed into the KG, which returns the relevant data. This data is sent back to the OpenAI API, along with the context of the original query. The OpenAI LLM generates a natural language response based on the data retrieved from the KG.
OpenAI APIs allow you to choose from a variety of different LLMs, depending on the task and budget. Thus, you don’t need to deploy LLMs or the data pipelines to interface with the KG.
In this section, we provide a high-level illustration of an integration pipeline using pseudo-code.
We use Neo4j, LangChain, and the OpenAI API to show the steps to create a chatbot based on RAG. The LLM generates its response based on information stored in the KG.
## Import relevant packages
# Handling chat prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_openai import ChatOpenAI
# Implementing the Runnable protocol for chaining components
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
# Processing text inputs in the chat
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# Working with Neo4j graphs
from neo4j import GraphDatabase
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
# Vector embeddings for the LLM
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Load data from a source like Wiki, PDF documents, etc.
from langchain.document_loaders import WikipediaLoader
# Create a Neo4jGraph to store the KG
graph = Neo4jGraph()
# Load the document(s) based on which to build the KG. In this snippet, we use Wiki. In practice, this is a business-specific document
raw_documents = WikipediaLoader(...).load()
# Split the document into tokens
documents = create_tokens(raw_documents)
# Instantiate the LLM
llm = ChatOpenAI(model_name="...", …)
llm_transformer = LLMGraphTransformer(llm=llm)
# Use the LLM to convert the tokenized documents into graph entities
graph_docs = llm_transformer.convert_to_graph_documents(documents)
# Add the graph entities to the Neo4j graph
graph.add_graph_documents(graph_docs, …)
# Create a retriever to run on the graph
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
# Create a class to extract entities from the text corresponding to nodes from the graph
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that appear in the text",
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Create a chain by piping the prompt to the LLM with the Entities class.
# This chain identifies entities in a given prompt string
entity_chain = prompt | llm.with_structured_output(Entities)
# Create a structured retriever to extract the entities in the query. Given a text query, it retrieves all the relevant nodes in the neighborhood of the entities in that query.
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
# CYPHER QUERY TEMPLATE,
{"query": generate_full_text_query(entity)})
result += el['output'] for el in response
return result
# Chain together the different components
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Invoke the chain
chain.invoke({"question": "The user’s question goes here"})KGs augment the capabilities of LLMs and make them relevant to practical use cases. To achieve the best performance, I recommend the following best practices.
The KG contains the repository of information based on which the LLM formulates its responses. Thus, it is necessary to continually update the graph database with the latest information. An outdated KG results in the LLM giving outdated answers.
LLMs and KGs are complex software with heavy computational requirements. As shown in the previous section, chaining together LLMs and KGs involves many steps, from tokenizing the user’s query and generating the relevant graph query to retrieving the information from the KG and generating text from it.
This can lead to inefficiencies and time lags between the query and the response. Optimization methods, as explained below, help to minimize the latency.
LLMs are memory-heavy models and often need expensive hardware to run on. It is helpful to reduce the size of AI models using techniques like LLM Distillation and Quantization:
You should ensure that the chosen language model performs well with the kind of queries it is expected to handle.
Tools like MLFlow help evaluate LLM performance on various tasks. Just as users’ needs change and evolve, the information stored in the knowledge graph also changes over time. Thus, it is essential to periodically re-evaluate the LLM's performance after deployment. It might prove necessary to fine-tune the model on an updated dataset, use an updated version of the model, or even deploy a new model.
The LLM gets information from the KG and its language and reasoning capabilities from the training dataset.
Base model LLMs are trained on vast generic datasets, typically using text from all over the internet. Finetuning the LLM on a domain-specific dataset enhances its reasoning abilities in that domain and enables it to construct sentences using the right structure and jargon. For example, to use an LLM to answer medical questions using a medical KG, I strongly recommend fine-tuning the base LLM on a dataset of medical texts.
In this article, we discussed the fundamental principles of Large Language Models (LLMs) and Knowledge Graphs (KGs) and how they complement each other. We also introduced some of the commonly used tools to use LLMs and KGs together to build user-facing applications. Lastly, we provided a high-level illustration of how Neo4j and OpenAI can be used together using LangChain.
After understanding these foundational concepts, you could implement these tools in practice:
Learn how to work with LLMs in Python right in your browser

Learn more about LLMs with these courses!
Course
Course
Course
blog
Amberle McKee
8 min
blog
Javier Canales Luna
12 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
code-along
Richie Cotton

