
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
100K
Sehen wir uns nun an, wie Wissensgraphen genutzt werden können, um LLMs zu verbessern.
LLMs sind in der Lage, gut geschriebene Texte zu verfassen, aber sie können deren sachliche Richtigkeit nicht beurteilen. In den meisten Fällen enthielt der ursprüngliche Trainingsdatensatz keine Informationen (wie z. B. ein spezielles Benutzerhandbuch), die für eine praktische Aufgabe (z. B. die Beantwortung von Benutzeranfragen zur Verwendung eines bestimmten Tools) relevant waren.
Ein LLM mit Zugang zu kontextuellen und domänenspezifischen Informationen kann dieses Wissen nutzen, um sinnvolle und korrekte Antworten zu formulieren. KGs ermöglichen es LLMs, programmatisch auf relevante und sachliche Informationen zuzugreifen und so besser auf Nutzeranfragen zu reagieren.
Wissensgraphen sind gut geeignet, um Informationen semantisch zu organisieren, zu speichern und abzurufen. Auf sie kann jedoch nur über spezielle Abfragesprachen wie SPARQL zugegriffen werden (eine Datenbankabfragesprache zur Bearbeitung und Abfrage von im RDF-Format gespeicherten Daten).
Der Output der KGs ist ebenfalls in Codeform und die Nutzer brauchen eine spezielle Schulung, um ihn zu interpretieren. LLMs überbrücken diese Lücke, indem sie einfachsprachige Benutzeranfragen in Abfragesprache umwandeln und aus der KG-Ausgabe menschenlesbaren Text erzeugen. So können auch nicht-technische Benutzer mit KGs arbeiten.
Der von LLMs generierte Text hängt vom Trainingsdatensatz ab, der oft schon veraltet ist, wenn das LLM in Betrieb genommen wird. Es ist ressourcenintensiv und daher nicht praktikabel, LLMs ständig auf aktuelle Informationen zu schulen.
KGs können jedoch, wie jede andere Datenbank auch, leicht in Echtzeit aktualisiert werden. Es gibt nur einen geringen Rechenaufwand, um die Verbindungen zwischen den Knotenpunkten anhand der neuen Informationen zu aktualisieren. Durch die Integration mit den KGs können die LLMs also in Echtzeit auf aktualisierte Informationen zugreifen und aktuelle Antworten geben.
Im Folgenden werden die wichtigsten Schritte eines Beispiel-Workflows beschrieben, bei dem KGs und LLMs zusammen verwendet werden, um aktuelle Antworten auf Benutzeranfragen zu geben.
Die folgende Abbildung zeigt eine schematische Skizze dieser Schritte:
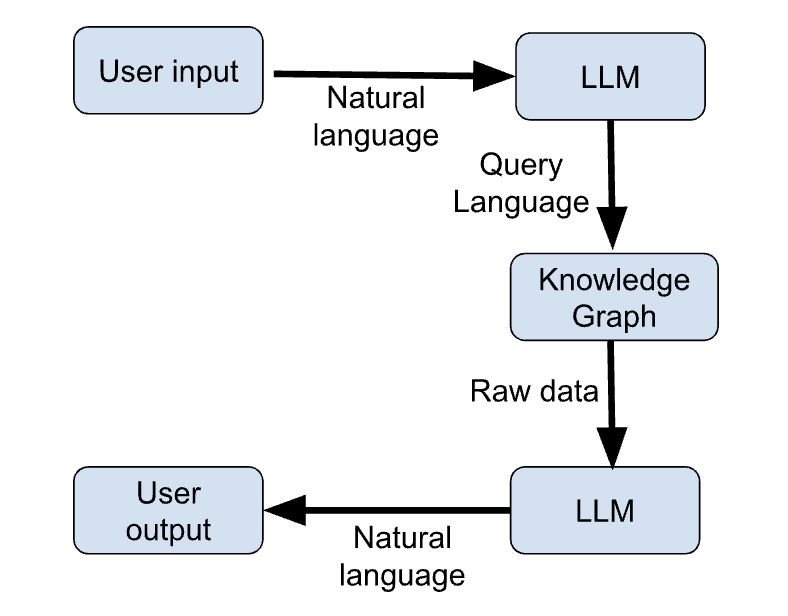
Abbildung 1: LLM + KG Arbeitsablauf (Bild vom Autor)
Es gibt viele Anwendungsfälle, die durch die Integration von KGs und GenAI ermöglicht werden. Sehen wir uns die interessantesten davon an.
KGs bieten einen strukturierten und aktuellen Wissensspeicher, auf den ein Chatbot programmatisch zugreifen kann, um aktuelle Informationen zu erhalten und relevantere Antworten auf Nutzeranfragen zu geben.
Die KG ergänzt das Standardwissen des Chatbots, das auf dem Trainingsdatensatz basiert. Der Chatbot lernt anhand des Trainingsdatensatzes, wie man Sätze konstruiert, und erwirbt anwendungsspezifische Informationen von der KG. Die Verwendung von KGs ermöglicht es also, dieselbe Chatbot-Architektur für verschiedene Anwendungen zu nutzen, ohne sie neu zu trainieren.
LLMs wurden als Empfehlungsmaschinen eingesetzt.
Ein LLM kann zum Beispiel den Inhalt eines Artikels analysieren und relevante Artikel empfehlen. LLMs werden auch verwendet, um interaktive Systeme zu erstellen, bei denen der Nutzer mit der Empfehlungsmaschine "sprechen" kann.
KGs können Informationen über Nutzerverhalten, Interessen, Interaktionen usw. organisieren und speichern. LLMs können diese Informationen analysieren und sie nutzen, um maßgeschneiderte Antworten zu geben. So profitieren die Nutzer/innen von personalisierten Empfehlungen, die auf ihren individuellen Vorlieben basieren.
In wissensbasierten Bereichen wie Medizin, Finanzen und Recht verbessern LLMs in Kombination mit KGs den Zugang zu Informationen.
In der Medizin schlagen sie anhand der Symptome und der Krankengeschichte des Patienten mögliche Diagnosen vor. Im Finanzwesen ergänzen sie die Arbeit von Analysten, indem sie den Zugang zu relevanten Informationen aus Finanzberichten erleichtern. In der Rechtswissenschaft helfen sie Anwälten, indem sie relevante frühere Fälle und Urteile abrufen und Zusammenfassungen großer juristischer Dokumente bereitstellen.
Die Kombination von großen Sprachmodellenmit Wissensgraphen ist entscheidend für Echtzeitanwendungen wie Nachrichtenaggregation und Börsenanalyse.
Traditionelle LLMs wissen nichts von Ereignissen, die nicht während der Ausbildung stattgefunden haben. Daher können sie keine aussagekräftigen Antworten auf Fragen geben, die sich auf aktuelle Themen beziehen.
KGs sind effizient darin, neue Informationen in Echtzeit zu verarbeiten und zu organisieren. So bieten sie das Informatik-Backend für LLMs, um Anwendungen zu bearbeiten, die sich auf das aktuelle Geschehen (Nachrichtenaggregation) und sich schnell verändernde Umgebungen (z. B. den Aktienmarkt) beziehen.
In den vorherigen Abschnitten wurden die Grundprinzipien von LLMs und KGs besprochen. In diesem Abschnitt stellen wir die Werkzeuge und Bibliotheken vor, die für die Integration von KGs und LLMs verwendet werden.
KGs werden am häufigsten mit Graphdatenbanken implementiert:
Eine spezialisierte Graphdatenbank (sie funktioniert nur mit Graphen). Neo4j verwendet Cypher, einerative Graphenabfragesprache, um Informationen einzufügen und abzurufen. Cypher ist stilistisch ähnlich wie SQL, was es für Entwickler einfacher macht, es zu lernen.
Neo4j verwaltet komplexe, miteinander verknüpfte Daten effizient, da die zugrunde liegende Datenspeicher-Engine von Grund auf für den Einsatz in Graphdatenbanken entwickelt wurde. Sie ist eine beliebte Wahl für Graphdatenbanken, weil sie sich mit externen Datenquellen wie Apache Kafka verbinden lässt und leicht horizontal skalierbar ist.
ArangoDB ist eine Multi-Model-Graph-Datenbank. Neben Graphen unterstützt es auch JSON-Dokumente und Key-Value-Stores. So können die Nutzer/innen die Diagramme mit anderen Informationen anreichern, die nicht ohne Weiteres in ein Diagrammformat umgewandelt werden können.
Wegen dieser Flexibilität wird es oft für Unternehmensanwendungen bevorzugt, die mit verschiedenen Arten von Daten arbeiten. Es verwendet die Arango Query Language (AQL), um mit allen Datentypen zu arbeiten. Unter der Haube nutzt ArangoDB RocksDB als Datenspeicher-Engine.
Amazons Neptune unterstützt Eigenschaftsgraphen und RDF-Modelle (Resource Description Framework). Es verwendet die Abfragesprachen SPARQL und Gremlin. Sie fügt sich nahtlos in die AWS-Infrastruktur ein und wird als vollständig verwaltete Graphdatenbank betrieben, was sie zu einer gängigen Wahl für die Integration in die bestehende Infrastruktur für Unternehmensanwendungen macht.
LLMs und Graphdatenbanken ergänzen sich gegenseitig, können aber im Allgemeinen nicht direkt miteinander verbunden werden. In den folgenden Abschnitten gehen wir auf Integrationsbibliotheken und Frameworks ein, die verwendet werden, um Daten von KGs in LLMs und umgekehrt zu übertragen.
RDFlib ist ein Open-Source-Python-Paket für die Arbeit mit RDF-Daten. Es verfügt über Funktionen zur Manipulation und Abfrage von RDF-Graphen. Dies erleichtert die Integration mit Wissensgraphen. Es ermöglicht die Speicherung von RDF-Daten im Speicher, auf der Festplatte oder aus der Ferne über SPARQL-Endpunkte. Ein SPARQL-Endpunkt kann, analog zu einem API-Endpunkt, entfernte SPARQL-Anfragen empfangen und verarbeiten.
RDFlib arbeitet mit graphbasierten Datenstrukturen, die aus Subjekt-Prädikat-Objekt-Tripeln bestehen. Jede Komponente des Tripels ist ein URI oder ein literaler Wert. Es hat Funktionen zum Parsen und Serialisieren von Triples, XML und anderen Datentypen wie JSON-LD.
PyTorch Geometric (PyG) ist eine PyTorch-basierte Bibliothek zum Erstellen und Trainieren von Graph Neural Networks (GNNs). Ein GNN ist eine neuronale Netzarchitektur, die mit Graphen arbeitet und Graphdatenstrukturen als Eingabe akzeptieren kann. PyG hat Funktionen, um Deep Learning-Techniken auf Graphen anzuwenden.
PyG wird mit vielen vorgefertigten GNN-Architekturen geliefert, die direkt implementiert oder über die Message-Passing-API weiter ausgebaut werden können.
PyG soll sich für große Anwendungen mit Millionen von Knoten und verschiedenen Arten von Knoten und Kanten eignen. Dieser Teilbereich wird auch als geometrisches Deep Learning bezeichnet.
Herkömmliche neuronale Netze sind gut darin, lineare Beziehungen zu kodieren, aber die Daten der realen Welt sind meist komplex und mehrdimensional. Graphen sind besser geeignet, um höherdimensionale Zusammenhänge darzustellen, bei denen jeder Knoten in einem Graphen mit jedem anderen Knoten in Beziehung stehen kann. Dadurch sind Graphen besser geeignet, um komplexe Beziehungen in der realen Welt zu speichern.
LangChain wurde 2022 als Framework zur Integration von Sprachmodellen eingeführt. Es erleichtert die Erstellung von Benutzeranwendungen, indem LLMs mit anderen relevanten Tools wie API-Wrappern, Shell-Skripten, Web-Scrapern, PDF-Readern, Google Docs, relationalen Datenbanken, Vektordatenbanken und Graphdatenbanken (einschließlich KGs) verknüpft werden. Daher wird es häufig verwendet, um Bewerbungen mit LLMs zu erstellen.
OpenAI APIs machen den Aufbau einer Pipeline mit Tools wie PyG überflüssig. Die OpenAI API kann die natürlichsprachliche Anfrage eines Nutzers entgegennehmen, sie verstehen und eine strukturierte Anfrage in einer Programmiersprache (z. B. SPARQL) zurückgeben. Diese Abfrage wird in die KG eingespeist, die die relevanten Daten zurückgibt. Diese Daten werden zusammen mit dem Kontext der ursprünglichen Anfrage an die OpenAI API zurückgeschickt. Der OpenAI LLM generiert eine natürlichsprachliche Antwort auf der Grundlage der von der KG abgerufenen Daten.
Mit den OpenAI-APIs kannst du je nach Aufgabe und Budget aus einer Vielzahl verschiedener LLMs wählen. Du musst also keine LLMs oder Datenpipelines einsetzen, um die Schnittstelle zur KG zu nutzen.
In diesem Abschnitt stellen wir eine Integrationspipeline anhand von Pseudocode dar.
Wir verwenden Neo4j, LangChain und die OpenAI API, um die Schritte zur Erstellung eines Chatbots auf der Grundlage von RAG zu zeigen. Das LLM generiert seine Antwort anhand der im KG gespeicherten Informationen.
## Import relevant packages
# Handling chat prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_openai import ChatOpenAI
# Implementing the Runnable protocol for chaining components
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
# Processing text inputs in the chat
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# Working with Neo4j graphs
from neo4j import GraphDatabase
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
# Vector embeddings for the LLM
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Load data from a source like Wiki, PDF documents, etc.
from langchain.document_loaders import WikipediaLoader
# Create a Neo4jGraph to store the KG
graph = Neo4jGraph()
# Load the document(s) based on which to build the KG. In this snippet, we use Wiki. In practice, this is a business-specific document
raw_documents = WikipediaLoader(...).load()
# Split the document into tokens
documents = create_tokens(raw_documents)
# Instantiate the LLM
llm = ChatOpenAI(model_name="...", …)
llm_transformer = LLMGraphTransformer(llm=llm)
# Use the LLM to convert the tokenized documents into graph entities
graph_docs = llm_transformer.convert_to_graph_documents(documents)
# Add the graph entities to the Neo4j graph
graph.add_graph_documents(graph_docs, …)
# Create a retriever to run on the graph
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
# Create a class to extract entities from the text corresponding to nodes from the graph
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that appear in the text",
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Create a chain by piping the prompt to the LLM with the Entities class.
# This chain identifies entities in a given prompt string
entity_chain = prompt | llm.with_structured_output(Entities)
# Create a structured retriever to extract the entities in the query. Given a text query, it retrieves all the relevant nodes in the neighborhood of the entities in that query.
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
# CYPHER QUERY TEMPLATE,
{"query": generate_full_text_query(entity)})
result += el['output'] for el in response
return result
# Chain together the different components
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Invoke the chain
chain.invoke({"question": "The user’s question goes here"})KGs erweitern die Fähigkeiten von LLMs und machen sie für praktische Anwendungsfälle relevant. Um die beste Leistung zu erzielen, empfehle ich die folgenden Best Practices.
Das KG enthält den Informationsbestand, auf dessen Grundlage das LLM seine Antworten formuliert. Daher ist es notwendig, die Graphdatenbank ständig mit den neuesten Informationen zu aktualisieren. Ein veraltetes KG führt dazu, dass der LLM veraltete Antworten gibt.
LLMs und KGs sind komplexe Software mit hohen Anforderungen an die Rechenleistung. Wie im vorherigen Abschnitt gezeigt, umfasst die Verkettung von LLMs und KGs viele Schritte, von der Tokenisierung der Nutzeranfrage und der Generierung der relevanten Graphenanfrage bis hin zum Abrufen der Informationen aus dem KG und der Generierung von Text daraus.
Das kann zu Ineffizienzen und Zeitverzögerungen zwischen Anfrage und Antwort führen. Optimierungsmethoden, wie sie im Folgenden erläutert werden, helfen dabei, die Latenzzeit zu minimieren.
LLMs sind speicherintensive Modelle und brauchen oft teure Hardware, um darauf zu laufen. Es ist hilfreich, die Größe von KI-Modellen mit Techniken wie LLM Distillation und Quantisierung zu reduzieren:
Du solltest sicherstellen, dass das gewählte Sprachmodell für die Art von Abfragen, die es bearbeiten soll, gut geeignet ist.
Tools wie MLFlow helfen dabei, die LLM-Leistung bei verschiedenen Aufgaben zu bewerten. So wie sich die Bedürfnisse der Nutzer/innen ändern und weiterentwickeln, ändern sich auch die im Wissensgraphen gespeicherten Informationen mit der Zeit. Daher ist es wichtig, die Leistung des LLM nach dem Einsatz regelmäßig neu zu bewerten. Es könnte sich als notwendig erweisen, das Modell mit einem aktualisierten Datensatz abzustimmen, eine aktualisierte Version des Modells zu verwenden oder sogar ein neues Modell einzusetzen.
Der LLM erhält Informationen vom KG und seine Sprach- und Schlussfolgerungsfähigkeiten aus dem Trainingsdatensatz.
Basismodell-LLMs werden auf riesigen generischen Datensätzen trainiert, in der Regel mit Texten aus dem gesamten Internet. Die Feinabstimmung des LLM auf einen domänenspezifischen Datensatz verbessert seine Argumentationsfähigkeiten in dieser Domäne und ermöglicht es ihm, Sätze mit der richtigen Struktur und dem richtigen Jargon zu konstruieren. Wenn du zum Beispiel ein LLM zur Beantwortung medizinischer Fragen mit einer medizinischen KG verwenden willst, empfehle ich dringend, das Basis-LLM auf einem Datensatz mit medizinischen Texten zu verfeinern.
In diesem Artikel haben wir die grundlegenden Prinzipien von Large Language Models (LLMs) und Knowledge Graphs (KGs) diskutiert und wie sie sich gegenseitig ergänzen. Außerdem haben wir einige gängige Tools vorgestellt, mit denen LLMs und KGs zusammen verwendet werden können, um nutzerorientierte Anwendungen zu erstellen. Zum Schluss haben wir gezeigt, wie Neo4j und OpenAI mithilfe von LangChain zusammen verwendet werden können.
Nachdem du diese grundlegenden Konzepte verstanden hast, kannst du diese Werkzeuge in der Praxis anwenden:
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Erfahre mehr über LLMs mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
