
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Voyons à présent comment les graphes de connaissances peuvent être utilisés pour améliorer les LLM.
Les LLM sont capables de produire des textes bien écrits, mais ils ne peuvent pas en évaluer l'exactitude factuelle. Dans la plupart des cas, l'ensemble de données de formation original ne contenait pas d'informations (telles qu'un manuel d'utilisation spécifique) pertinentes pour une tâche pratique (telle que répondre aux questions des utilisateurs sur la manière d'utiliser un outil spécifique).
Un MLD ayant accès à des informations contextuelles et spécifiques à un domaine peut utiliser ces connaissances pour formuler des réponses significatives et correctes. Les KG permettent aux LLM d'accéder de manière programmatique à des informations pertinentes et factuelles, ce qui leur permet de mieux répondre aux demandes des utilisateurs.
Les graphes de connaissances permettent d'organiser, de stocker et d'extraire des informations de manière sémantique. Cependant, on ne peut y accéder qu'au moyen de langages d'interrogation spécialisés comme SPARQL (un langage d'interrogation de base de données permettant de manipuler et d'extraire des données stockées au format RDF).
Les résultats des KG sont également sous forme de code et les utilisateurs ont besoin d'une formation spécifique pour les interpréter. Les LLM comblent cette lacune en convertissant les demandes des utilisateurs en langage clair en langage d'interrogation et en générant un texte lisible par l'homme à partir des résultats du KG. Ils permettent donc aux utilisateurs non techniques d'interagir avec les KG.
Le texte généré par les LLM dépend de l'ensemble de données d'apprentissage, qui est souvent obsolète au moment où le LLM est mis en production. La formation continue des gestionnaires de l'apprentissage tout au long de la vie sur les informations les plus récentes demande beaucoup de ressources et n'est donc pas pratique.
Cependant, les KG, comme toute autre base de données, peuvent être facilement mises à jour en temps réel. La mise à jour des connexions entre les nœuds sur la base des nouvelles informations n'entraîne qu'une légère surcharge de calcul. Ainsi, en s'intégrant aux KG, les LLM peuvent accéder à des informations mises à jour en temps réel et fournir des réponses actualisées.
Les étapes ci-dessous décrivent les principales étapes d'un exemple de flux de travail qui utilise les KG et les LLM pour fournir des réponses actualisées aux demandes des utilisateurs.
La figure ci-dessous présente une esquisse schématique de ces étapes :
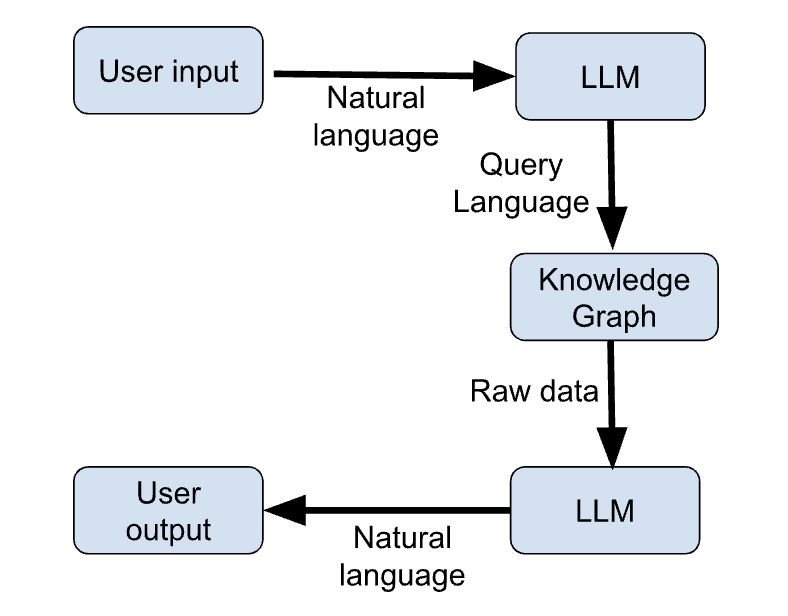
Figure 1 : LLM + KG workflow (image par l'auteur)
L'intégration des KG et de la GenAI permet de nombreux cas d'utilisation. Passons en revue les plus intéressantes.
Les KG constituent un référentiel de connaissances structuré et actualisé auquel un chatbot peut accéder de manière programmatique pour obtenir des informations actualisées et fournir des réponses plus pertinentes aux questions des utilisateurs.
Le KG complète les connaissances par défaut du chatbot, qui sont basées sur l'ensemble des données de formation. Le chatbot apprend à construire des phrases sur la base de l'ensemble de données de formation et acquiert des informations spécifiques à l'application auprès du KG. Ainsi, l'utilisation des KG permet également d'utiliser la même architecture de chatbot pour différentes applications sans avoir à suivre une nouvelle formation.
Les LLM ont été utilisés comme moteurs de recommandation.
Par exemple, un LLM peut analyser le contenu d'un article et recommander des articles pertinents. Les LLM sont également utilisés pour créer des systèmes interactifs, dans lesquels l'utilisateur peut "parler" au moteur de recommandation.
Les KG peuvent organiser et stocker des informations sur le comportement des utilisateurs, leurs intérêts, leurs interactions, etc. Les LLM peuvent analyser ces informations et les utiliser pour générer des réponses sur mesure. Les utilisateurs bénéficient ainsi de recommandations personnalisées basées sur leurs préférences individuelles.
Dans les domaines fondés sur la connaissance tels que la médecine, la finance et le droit, les LLM combinés aux KG améliorent la facilité d'accès à l'information.
En médecine, ils suggèrent des diagnostics possibles sur la base des symptômes et des antécédents du patient. Dans le domaine financier, ils complètent les efforts des analystes en facilitant l'accès aux informations pertinentes contenues dans les rapports financiers. En droit, ils aident les avocats à retrouver les affaires et les jugements antérieurs pertinents et à fournir des résumés de documents juridiques volumineux.
La combinaison de grands modèles de langageavec des graphes de connaissances est essentielle dans les applications en temps réel telles que l'agrégation de nouvelles et l'analyse des marchés boursiers.
Les LLM traditionnels n'ont pas connaissance d'événements qui ne se sont pas produits pendant la formation. Ils ne peuvent donc pas donner de réponses significatives à des questions basées sur l'actualité.
Les KG sont capables de traiter et d'organiser de nouvelles informations en temps réel. Ils fournissent donc aux LLM le support informatique nécessaire pour traiter les applications basées sur l'actualité (agrégation de nouvelles) et les environnements en évolution rapide (par exemple, le marché boursier).
Les sections précédentes ont abordé les principes de base des LLM et des KG. Dans cette section, nous présentons les outils et les bibliothèques utilisés pour intégrer les KG et les LLM.
Les KG sont le plus souvent mis en œuvre à l'aide de bases de données graphiques telles que :
Une base de données spécialisée dans les graphes (elle ne fonctionne qu'avec des graphes). Neo4j utilise Cypher, un langage d'interrogation graphique déclaratif, pour insérer et récupérer des informations. Cypher est stylistiquement similaire à SQL, ce qui facilite son apprentissage par les développeurs.
Neo4j gère efficacement des données interconnectées complexes, car son moteur de stockage de données sous-jacent est entièrement conçu pour répondre aux cas d'utilisation des bases de données graphiques. C'est un choix populaire pour les bases de données graphiques parce qu'il se connecte à des sources de données externes comme Apache Kafka et qu'il est facile à mettre à l'échelle horizontalement.
ArangoDB est une base de données graphique multi-modèle. Outre les graphes, il prend également en charge les documents JSON et les magasins de valeurs clés. Cela permet aux utilisateurs d'enrichir les graphiques avec d'autres informations qui ne peuvent pas être facilement converties en format graphique.
En raison de cette flexibilité, il est souvent préféré pour les applications d'entreprise qui traitent différents types de données. Il utilise le langage de requête Arango (AQL) pour travailler avec tous les types de données. Sous le capot, ArangoDB utilise RocksDB comme moteur de stockage de données.
Neptune d'Amazon prend en charge les graphes de propriété et les modèles RDF (Resource Description Framework). Il utilise les langages d'interrogation SPARQL et Gremlin. Elle s'intègre de manière transparente dans l'infrastructure AWS pour fonctionner comme une base de données graphique entièrement gérée, ce qui en fait un choix courant pour l'intégration à l'infrastructure existante des applications d'entreprise.
Les LLM et les bases de données graphiques se complètent mais ne peuvent généralement pas s'interfacer directement. Dans les paragraphes suivants, nous examinons les bibliothèques d'intégration et les cadres utilisés pour acheminer les données des KG vers les LLM et vice versa.
RDFlib est un paquetage Python open-source pour travailler avec des données RDF. Il dispose de fonctions pour la manipulation et l'interrogation des graphes RDF. Cela facilite l'intégration avec les graphes de connaissances. Il permet de stocker des données RDF en mémoire, sur disque ou à distance à l'aide de points d'extrémité SPARQL. Un point d'accès SPARQL, analogue à un point d'accès API, peut recevoir et traiter des requêtes SPARQL à distance.
RDFlib travaille avec des structures de données basées sur des graphes constitués de triples sujet-prédicat-objet. Chaque composant du triple est un URI ou une valeur littérale. Il dispose de fonctions pour analyser et sérialiser les triplets, XML et d'autres types de données comme JSON-LD.
PyTorch Geometric (PyG) est une bibliothèque basée sur PyTorch conçue pour créer et entraîner des réseaux neuronaux graphiques (GNNs). Un réseau neuronal GNN est une architecture de réseau neuronal qui fonctionne sur des graphes et peut accepter des structures de données graphiques en entrée. PyG dispose de fonctions permettant d'appliquer des techniques d'apprentissage profond aux graphes.
PyG est livré avec de nombreuses architectures GNN préconstruites qui peuvent être directement mises en œuvre ou étendues via l'API de passage de messages.
PyG est censé convenir à des applications à grande échelle comportant des millions de nœuds et différents types de nœuds et d'arêtes. Ce sous-domaine est également connu sous le nom d'apprentissage profond géométrique.
Les réseaux neuronaux traditionnels codent bien les relations linéaires, mais les données du monde réel ont tendance à être complexes et multidimensionnelles. Les graphes représentent mieux les interconnexions à plus haute dimension, où tout nœud d'un graphe peut être relié à n'importe quel autre nœud. Les graphiques sont donc mieux adaptés pour stocker des relations complexes dans le monde réel.
LangChain a été lancé en 2022 en tant que cadre d'intégration de modèles linguistiques. Il facilite la création d'applications utilisateur en associant des LLM à d'autres outils pertinents, tels que des wrappers d'API, des scripts shell, des scanners web, des lecteurs PDF, des Google Docs, des bases de données relationnelles, des bases de données vectorielles et des bases de données de graphes (y compris des KG). Il est donc couramment utilisé pour créer des applications impliquant des MLD.
Les API OpenAI éliminent les difficultés liées à la construction d'un pipeline à l'aide d'outils tels que PyG. L'API OpenAI peut recevoir une requête en langage naturel d'un utilisateur, la comprendre et renvoyer une requête structurée dans un langage de programmation (par exemple, SPARQL). Cette requête est introduite dans le KG, qui renvoie les données pertinentes. Ces données sont renvoyées à l'API OpenAI, avec le contexte de la requête originale. Le LLM OpenAI génère une réponse en langage naturel basée sur les données extraites du KG.
Les API de l'OpenAI vous permettent de choisir parmi une variété de LLM, en fonction de la tâche et du budget. Ainsi, vous n'avez pas besoin de déployer des LLM ou des pipelines de données pour assurer l'interface avec le KG.
Dans cette section, nous fournissons une illustration de haut niveau d'un pipeline d'intégration à l'aide d'un pseudo-code.
Nous utilisons Neo4j, LangChain et l'API OpenAI pour montrer les étapes de la création d'un chatbot basé sur RAG. Le LLM génère sa réponse sur la base des informations stockées dans le KG.
## Import relevant packages
# Handling chat prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_openai import ChatOpenAI
# Implementing the Runnable protocol for chaining components
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
# Processing text inputs in the chat
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# Working with Neo4j graphs
from neo4j import GraphDatabase
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
# Vector embeddings for the LLM
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Load data from a source like Wiki, PDF documents, etc.
from langchain.document_loaders import WikipediaLoader
# Create a Neo4jGraph to store the KG
graph = Neo4jGraph()
# Load the document(s) based on which to build the KG. In this snippet, we use Wiki. In practice, this is a business-specific document
raw_documents = WikipediaLoader(...).load()
# Split the document into tokens
documents = create_tokens(raw_documents)
# Instantiate the LLM
llm = ChatOpenAI(model_name="...", …)
llm_transformer = LLMGraphTransformer(llm=llm)
# Use the LLM to convert the tokenized documents into graph entities
graph_docs = llm_transformer.convert_to_graph_documents(documents)
# Add the graph entities to the Neo4j graph
graph.add_graph_documents(graph_docs, …)
# Create a retriever to run on the graph
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
# Create a class to extract entities from the text corresponding to nodes from the graph
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that appear in the text",
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Create a chain by piping the prompt to the LLM with the Entities class.
# This chain identifies entities in a given prompt string
entity_chain = prompt | llm.with_structured_output(Entities)
# Create a structured retriever to extract the entities in the query. Given a text query, it retrieves all the relevant nodes in the neighborhood of the entities in that query.
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
# CYPHER QUERY TEMPLATE,
{"query": generate_full_text_query(entity)})
result += el['output'] for el in response
return result
# Chain together the different components
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Invoke the chain
chain.invoke({"question": "The user’s question goes here"})Les KG augmentent les capacités des LLM et les adaptent à des cas d'utilisation pratiques. Pour obtenir les meilleures performances, je vous recommande de suivre les meilleures pratiques suivantes.
Le KG contient le référentiel d'informations sur la base duquel le LLM formule ses réponses. Il est donc nécessaire d'actualiser en permanence la base de données graphique avec les informations les plus récentes. Un KG obsolète conduit le LLM à donner des réponses obsolètes.
Les LLM et les KG sont des logiciels complexes qui nécessitent de lourds calculs. Comme le montre la section précédente, l'enchaînement des LLM et des KG implique de nombreuses étapes, depuis la symbolisation de la requête de l'utilisateur et la génération de la requête graphique pertinente jusqu'à l'extraction des informations du KG et la génération de texte à partir de celles-ci.
Cela peut conduire à des inefficacités et à des délais entre la demande et la réponse. Les méthodes d'optimisation expliquées ci-dessous permettent de minimiser la latence.
Les LLM sont des modèles gourmands en mémoire et nécessitent souvent un matériel coûteux pour fonctionner. Il est utile de réduire la taille des modèles d'IA en utilisant des techniques telles que la distillation LLM et la quantification :
Vous devez vous assurer que le modèle linguistique choisi fonctionne bien avec le type de requêtes qu'il est censé traiter.
Des outils tels que MLFlow permettent d'évaluer les performances du LLM sur diverses tâches. Tout comme les besoins des utilisateurs changent et évoluent, les informations stockées dans le graphe de connaissances changent également au fil du temps. Il est donc essentiel de réévaluer périodiquement les performances du mécanisme d'apprentissage tout au long de la vie après son déploiement. Il peut s'avérer nécessaire d'affiner le modèle sur un ensemble de données actualisé, d'utiliser une version actualisée du modèle, voire de déployer un nouveau modèle.
Le LLM obtient des informations du KG et ses capacités linguistiques et de raisonnement à partir de l'ensemble de données de formation.
Les modèles de base LLM sont formés sur de vastes ensembles de données génériques, généralement constitués de textes provenant de l'ensemble de l'internet. Le réglage fin du LLM sur un ensemble de données spécifiques à un domaine améliore ses capacités de raisonnement dans ce domaine et lui permet de construire des phrases en utilisant la bonne structure et le bon jargon. Par exemple, pour utiliser un LLM afin de répondre à des questions médicales à l'aide d'un KG médical, je recommande vivement d'affiner le LLM de base sur un ensemble de données de textes médicaux.
Dans cet article, nous avons abordé les principes fondamentaux des grands modèles linguistiques (LLM) et des graphes de connaissances (KG), ainsi que leur complémentarité. Nous avons également présenté certains des outils couramment utilisés pour utiliser les LLM et les KG ensemble afin de construire des applications orientées vers l'utilisateur. Enfin, nous avons fourni une illustration de haut niveau de la façon dont Neo4j et OpenAI peuvent être utilisés ensemble à l'aide de LangChain.
Après avoir compris ces concepts fondamentaux, vous pourrez mettre ces outils en pratique :
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Apprenez-en plus sur les LLM grâce à ces cours !
Cours
Cours
Cours