
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Agora, vamos ver como os gráficos de conhecimento podem ser usados para aprimorar os LLMs.
Os LLMs são capazes de gerar textos bem escritos, mas não podem avaliar sua precisão factual. Na maioria dos casos, o conjunto de dados de treinamento original não tinha informações (como um manual de usuário específico) relevantes para uma tarefa prática (como responder a consultas de usuários sobre como usar uma ferramenta específica).
Um LLM com acesso a informações contextuais e específicas do domínio pode usar esse conhecimento para formular respostas significativas e corretas. Os KGs permitem que os LLMs acessem de forma programática informações relevantes e factuais, respondendo melhor às consultas dos usuários.
Os gráficos de conhecimento são bons para organizar, armazenar e recuperar informações semanticamente. No entanto, eles só podem ser acessados por meio de linguagens de consulta especializadas, como SPARQL (uma linguagem de consulta de banco de dados para manipular e recuperar dados armazenados no formato RDF).
O resultado dos KGs também está em forma de código e os usuários precisam de treinamento específico para interpretá-lo. Os LLMs preenchem essa lacuna convertendo solicitações de usuários em linguagem simples para linguagem de consulta e gerando texto legível para humanos a partir da saída do KG. Assim, eles permitem que usuários não técnicos façam interface com os KGs.
O texto gerado pelos LLMs depende do conjunto de dados de treinamento, que geralmente está desatualizado no momento em que o LLM é colocado em produção. O retreinamento contínuo dos LLMs com informações atualizadas consome muitos recursos e, portanto, não é prático.
No entanto, os KGs, como qualquer outro banco de dados, podem ser facilmente atualizados em tempo real. Há apenas uma pequena sobrecarga computacional para atualizar as conexões entre os nós com base nas novas informações. Assim, ao se integrarem aos KGs, os LLMs podem acessar informações atualizadas em tempo real e fornecer respostas atualizadas.
As etapas abaixo descrevem as principais etapas de um exemplo de fluxo de trabalho que usa KGs e LLMs juntos para fornecer respostas atualizadas às consultas dos usuários.
A figura abaixo mostra um esboço esquemático dessas etapas:
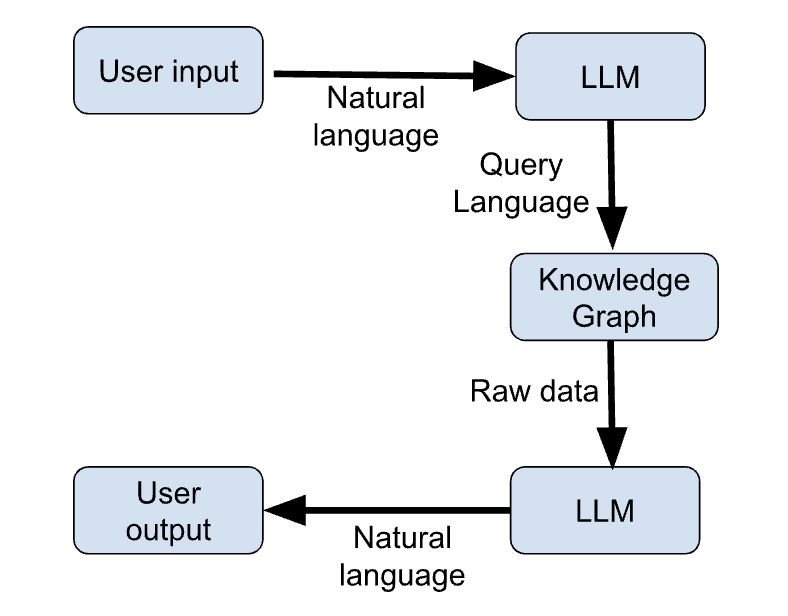
Figura 1: Fluxo de trabalho do LLM + KG (imagem do autor)
Há muitos casos de uso que são possibilitados pela integração de KGs e GenAI. Vamos analisar os mais interessantes.
Os KGs fornecem um repositório estruturado e atualizado de conhecimento que um chatbot pode acessar de forma programática para obter informações atuais e fornecer respostas mais relevantes às consultas dos usuários.
O KG complementa o conhecimento padrão do chatbot, que é baseado no conjunto de dados de treinamento. O chatbot aprende a construir frases com base no conjunto de dados de treinamento e adquire informações específicas do aplicativo a partir do KG. Assim, o uso de KGs também permite que você use a mesma arquitetura de chatbot para diferentes aplicativos sem precisar treinar novamente.
Os LLMs têm sido usados como mecanismos de recomendação.
Por exemplo, um LLM pode analisar o conteúdo de um artigo e recomendar artigos relevantes. Os LLMs também são usados para criar sistemas interativos, nos quais o usuário pode "conversar" com o mecanismo de recomendação.
Os KGs podem organizar e armazenar informações sobre o comportamento do usuário, interesses, interações e assim por diante. Os LLMs podem analisar essas informações e usá-las para gerar respostas personalizadas. Assim, os usuários obtêm o benefício de recomendações personalizadas com base em suas preferências individuais.
Em domínios baseados em conhecimento, como medicina, finanças e direito, os LLMs combinados com os KGs melhoram a facilidade de acesso às informações.
Na medicina, eles sugerem possíveis diagnósticos com base nos sintomas e no histórico do paciente. Em finanças, eles complementam os esforços dos analistas, facilitando o acesso às informações relevantes dos relatórios financeiros. Na área jurídica, eles auxiliam os advogados, ajudando-os a recuperar casos e julgamentos anteriores relevantes e fornecendo resumos de grandes documentos jurídicos.
A combinação de grandes modelos de linguagemcom gráficos de conhecimento é fundamental em aplicativos em tempo real, como agregação de notícias e análise do mercado de ações.
Os LLMs tradicionais não sabem de eventos que não ocorreram durante o treinamento. Assim, eles não conseguem dar respostas significativas a perguntas baseadas em assuntos atuais.
Os KGs são eficientes no processamento e na organização de novas informações em tempo real. Assim, eles fornecem o backend de informática para os LLMs lidarem com aplicativos baseados em assuntos atuais (agregação de notícias) e ambientes em rápida mudança (por exemplo, o mercado de ações).
As seções anteriores discutiram os princípios básicos dos LLMs e KGs. Nesta seção, apresentamos as ferramentas e as bibliotecas usadas para integrar KGs e LLMs.
Os KGs são mais comumente implementados usando bancos de dados de gráficos, como:
Um banco de dados de gráficos especializado (funciona somente com gráficos). O Neo4j usa o Cypher, uma linguagem de consulta de gráficos declarativa, para inserir e recuperar informações. O Cypher é estilisticamente semelhante ao SQL, o que facilita o aprendizado para os desenvolvedores.
O Neo4j gerencia com eficiência dados interconectados complexos porque seu mecanismo de armazenamento de dados subjacente foi criado do zero para atender aos casos de uso de bancos de dados de gráficos. É uma opção popular para bancos de dados de gráficos porque se conecta a fontes de dados externas, como o Apache Kafka, e é fácil de dimensionar horizontalmente.
O ArangoDB é um banco de dados de gráficos com vários modelos. Além de gráficos, ele também oferece suporte a documentos JSON e armazenamentos de valores-chave. Isso permite que os usuários aprimorem os gráficos com outras informações que podem não ser facilmente convertidas para o formato de gráfico.
Devido a essa flexibilidade, ele é geralmente preferido para aplicativos corporativos que lidam com vários tipos de dados. Ele usa a linguagem de consulta Arango (AQL) para trabalhar com todos os tipos de dados. O ArangoDB usa o RocksDB como mecanismo de armazenamento de dados.
O Neptune da Amazon oferece suporte a gráficos de propriedades e modelos RDF (Resource Description Framework). Ele usa as linguagens de consulta SPARQL e Gremlin. Ele se integra perfeitamente à infraestrutura do AWS para ser executado como um banco de dados gráfico totalmente gerenciado, o que o torna uma opção comum para integração com a infraestrutura existente para aplicativos corporativos.
Os LLMs e os bancos de dados de gráficos se complementam, mas geralmente não podem interagir diretamente. Nos parágrafos seguintes, discutiremos as bibliotecas e estruturas de integração usadas para canalizar dados de KGs para LLMs e vice-versa.
RDFlib é um pacote Python de código aberto para você trabalhar com dados RDF. Ele tem funções para manipulação e consulta de gráficos RDF. Isso facilita a integração com gráficos de conhecimento. Ele permite que você armazene dados RDF na memória, no disco ou remotamente usando pontos de extremidade SPARQL. Um ponto de extremidade SPARQL, análogo a um ponto de extremidade de API, pode receber e processar consultas SPARQL remotas.
O RDFlib trabalha com estruturas de dados baseadas em gráficos que consistem em triplas de sujeito-predicado-objeto. Cada componente da tripla é um URI ou um valor literal. Ele tem funções para analisar e serializar triplas, XML e outros tipos de dados, como JSON-LD.
O PyTorch Geometric (PyG) é uma biblioteca baseada no PyTorch projetada para criar e treinar redes neurais de gráficos (GNNs). Uma GNN é uma arquitetura de rede neural que opera em gráficos e pode aceitar estruturas de dados de gráficos como entrada. O PyG tem funções para aplicar técnicas de aprendizagem profunda a gráficos.
O PyG vem com muitas arquiteturas GNN pré-construídas que podem ser implementadas diretamente ou ampliadas por meio da API de passagem de mensagens.
O PyG é considerado adequado para aplicativos de grande escala com milhões de nós em diferentes tipos de nós e bordas. Esse subcampo também é conhecido como aprendizagem profunda geométrica.
As redes neurais tradicionais são boas para codificar relações lineares, mas os dados do mundo real tendem a ser complexos e multidimensionais. Os gráficos são melhores para representar interconexões de dimensões mais altas, em que qualquer nó em um gráfico pode se relacionar com qualquer outro nó. Isso torna os gráficos mais adequados para armazenar relacionamentos complexos do mundo real.
O LangChain foi lançado em 2022 como uma estrutura de integração de modelos de linguagem. Facilita a criação de aplicativos de usuário encadeando LLMs com outras ferramentas relevantes, como wrappers de API, scripts de shell, raspadores da Web, leitores de PDF, Google Docs, bancos de dados relacionais, bancos de dados vetoriais e bancos de dados gráficos (incluindo KGs). Portanto, ele é comumente usado para criar aplicativos que envolvem LLMs.
As APIs da OpenAI eliminam o incômodo de criar um pipeline usando ferramentas como o PyG. A API da OpenAI pode receber uma consulta em linguagem natural do usuário, entendê-la e retornar uma consulta estruturada em uma linguagem de programação (por exemplo, SPARQL). Essa consulta é inserida no KG, que retorna os dados relevantes. Esses dados são enviados de volta à API da OpenAI, juntamente com o contexto da consulta original. O OpenAI LLM gera uma resposta em linguagem natural com base nos dados recuperados do KG.
As APIs da OpenAI permitem que você escolha entre uma variedade de LLMs diferentes, dependendo da tarefa e do orçamento. Assim, você não precisa implantar LLMs ou pipelines de dados para fazer a interface com o KG.
Nesta seção, apresentamos uma ilustração de alto nível de um pipeline de integração usando pseudocódigo.
Usamos Neo4j, LangChain e a API OpenAI para mostrar as etapas de criação de um chatbot baseado em RAG. O LLM gera sua resposta com base nas informações armazenadas no KG.
## Import relevant packages
# Handling chat prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_openai import ChatOpenAI
# Implementing the Runnable protocol for chaining components
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
# Processing text inputs in the chat
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
# Working with Neo4j graphs
from neo4j import GraphDatabase
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
# Vector embeddings for the LLM
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Load data from a source like Wiki, PDF documents, etc.
from langchain.document_loaders import WikipediaLoader
# Create a Neo4jGraph to store the KG
graph = Neo4jGraph()
# Load the document(s) based on which to build the KG. In this snippet, we use Wiki. In practice, this is a business-specific document
raw_documents = WikipediaLoader(...).load()
# Split the document into tokens
documents = create_tokens(raw_documents)
# Instantiate the LLM
llm = ChatOpenAI(model_name="...", …)
llm_transformer = LLMGraphTransformer(llm=llm)
# Use the LLM to convert the tokenized documents into graph entities
graph_docs = llm_transformer.convert_to_graph_documents(documents)
# Add the graph entities to the Neo4j graph
graph.add_graph_documents(graph_docs, …)
# Create a retriever to run on the graph
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
# Create a class to extract entities from the text corresponding to nodes from the graph
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that appear in the text",
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Create a chain by piping the prompt to the LLM with the Entities class.
# This chain identifies entities in a given prompt string
entity_chain = prompt | llm.with_structured_output(Entities)
# Create a structured retriever to extract the entities in the query. Given a text query, it retrieves all the relevant nodes in the neighborhood of the entities in that query.
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
# CYPHER QUERY TEMPLATE,
{"query": generate_full_text_query(entity)})
result += el['output'] for el in response
return result
# Chain together the different components
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Invoke the chain
chain.invoke({"question": "The user’s question goes here"})Os KGs aumentam os recursos dos LLMs e os tornam relevantes para casos de uso prático. Para obter o melhor desempenho, recomendo que você siga as práticas recomendadas a seguir.
O KG contém o repositório de informações com base nas quais o LLM formula suas respostas. Portanto, é necessário atualizar continuamente o banco de dados de gráficos com as informações mais recentes. Um KG desatualizado faz com que o LLM dê respostas desatualizadas.
Os LLMs e KGs são softwares complexos com grandes requisitos de computação. Conforme mostrado na seção anterior, o encadeamento de LLMs e KGs envolve muitas etapas, desde a tokenização da consulta do usuário e a geração da consulta de gráfico relevante até a recuperação das informações do KG e a geração de texto a partir delas.
Isso pode levar a ineficiências e atrasos entre a consulta e a resposta. Os métodos de otimização, conforme explicado abaixo, ajudam a minimizar a latência.
Os LLMs são modelos com muita memória e geralmente precisam de hardware caro para serem executados. É útil reduzir o tamanho dos modelos de IA usando técnicas como LLM Distillation e Quantization:
Você deve garantir que o modelo de linguagem escolhido tenha um bom desempenho com o tipo de consulta que se espera que ele manipule.
Ferramentas como o MLFlow ajudam a avaliar o desempenho do LLM em várias tarefas. Assim como as necessidades dos usuários mudam e evoluem, as informações armazenadas no gráfico de conhecimento também mudam com o tempo. Portanto, é essencial reavaliar periodicamente o desempenho do LLM após a implantação. Pode ser necessário fazer um ajuste fino do modelo em um conjunto de dados atualizado, usar uma versão atualizada do modelo ou até mesmo implantar um novo modelo.
O LLM obtém informações do KG e seus recursos de linguagem e raciocínio do conjunto de dados de treinamento.
Os LLMs de modelo básico são treinados em vastos conjuntos de dados genéricos, normalmente usando texto de toda a Internet. O ajuste fino do LLM em um conjunto de dados específico do domínio aprimora suas habilidades de raciocínio nesse domínio e permite que ele construa frases usando a estrutura e o jargão corretos. Por exemplo, para usar um LLM para responder a perguntas médicas usando um KG médico, recomendo enfaticamente que você faça o ajuste fino do LLM básico em um conjunto de dados de textos médicos.
Neste artigo, discutimos os princípios fundamentais dos modelos de linguagem ampla (LLMs) e dos gráficos de conhecimento (KGs) e como eles se complementam. Também apresentamos algumas das ferramentas comumente usadas para usar LLMs e KGs juntos para criar aplicativos voltados para o usuário. Por fim, fornecemos uma ilustração de alto nível de como o Neo4j e o OpenAI podem ser usados juntos usando o LangChain.
Depois de entender esses conceitos básicos, você poderá implementar essas ferramentas na prática:
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Saiba mais sobre LLMs com estes cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
