
Curso
Fundamentos de PySpark
4 h
157.5K
La gestión de datos ha visto surgir nuevas soluciones para hacer frente a las limitaciones de las arquitecturas tradicionales, como los lagos de datos y los almacenes de datos. Aunque ambas arquitecturas han sido fundamentales para el almacenamiento y el análisis de datos, pueden presentar retos a la hora de abordar las necesidades modernas de procesamiento de datos.
A pesar de ser escalables y flexibles, los lagos de datos a menudo se enfrentan a problemas de gobernanza y rendimiento. Por otra parte, los almacenes de datos, aunque potentes para el análisis, son costosos y menos flexibles. El lago de datos pretende resolver estos problemas combinando los puntos fuertes de los lagos de datos y los almacenes, y minimizando al mismo tiempo sus puntos débiles.
En esta guía, te explicaré qué es un lago de datos, en qué se diferencia de las arquitecturas de datos tradicionales y por qué está ganando popularidad entre los profesionales de datos que buscan una solución unificada de gestión de datos.
Un lago de datos es una arquitectura que combina la escalabilidad y el almacenamiento de bajo coste de los lagos de datos con las capacidades de rendimiento, fiabilidad y gobernanza de los almacenes de datos.
Al integrar los puntos fuertes de ambas arquitecturas, un lago de datos ofrece una plataforma unificada para almacenar, procesar y analizar todo tipo de datos: estructurados, semiestructurados y no estructurados.
El enfoque unificado permite una mayor flexibilidad en el procesamiento de datos y admite una amplia gama de casos de uso analítico, desde la inteligencia empresarial al aprendizaje automático.
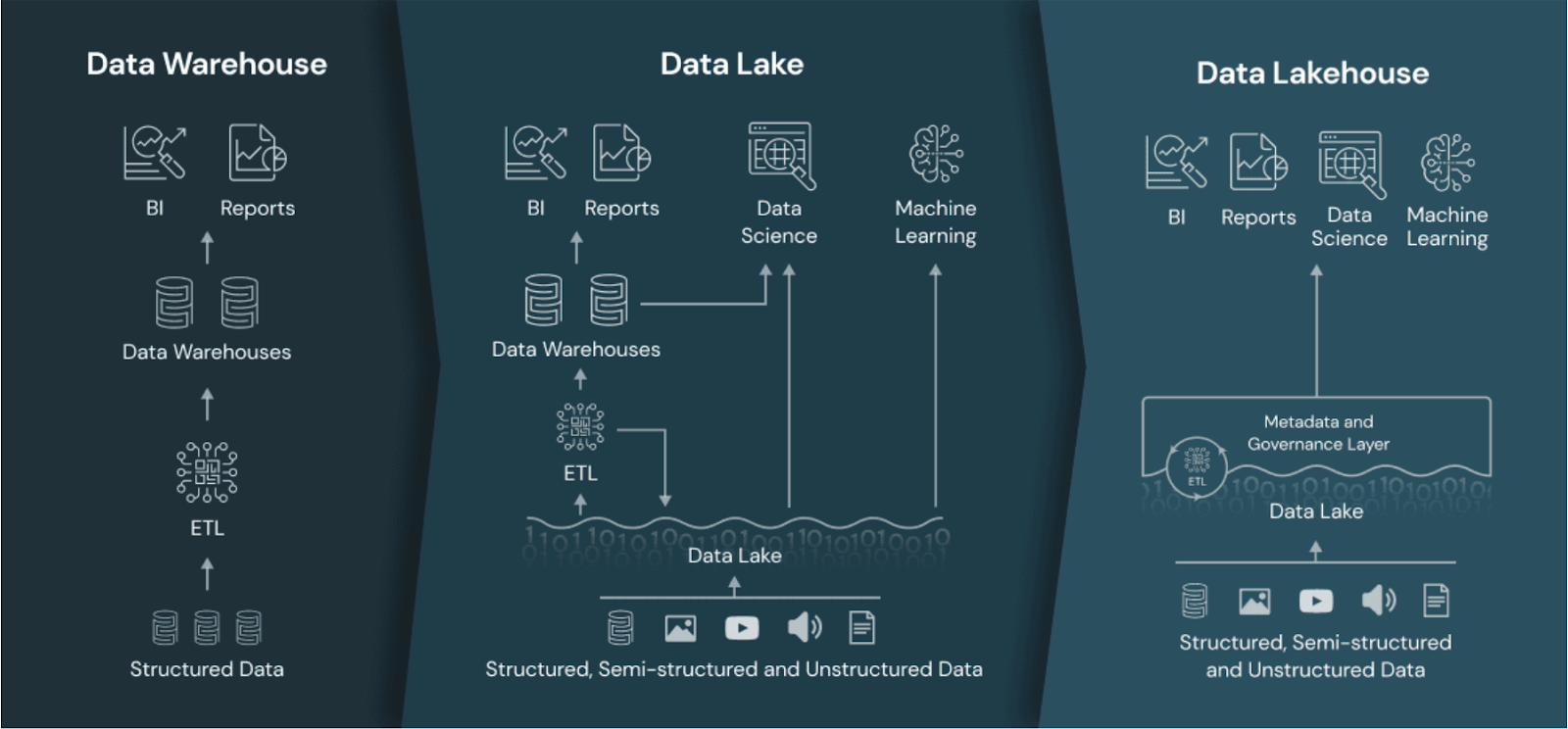
El lago de datos comparado con el almacén de datos y el lago de datos. Fuente de la imagen: Databricks.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Matt Crabtree
10 min
blog
Mike Shakhomirov
11 min
blog
Kurtis Pykes
10 min
blog
Tim Lu
12 min
blog
Javier Canales Luna
12 min


