
Curso
Fundamentos do PySpark
4 h
157.5K
O gerenciamento de dados tem visto o surgimento de novas soluções para lidar com as limitações das arquiteturas tradicionais, como data lakes e data warehouses. Embora ambas as arquiteturas tenham sido fundamentais para o armazenamento e a análise de dados, elas podem apresentar desafios para atender às necessidades modernas de processamento de dados.
Apesar de serem dimensionáveis e flexíveis, os data lakes geralmente enfrentam problemas de governança e desempenho. Por outro lado, os data warehouses, embora sejam poderosos para a análise, são caros e menos flexíveis. O objetivo do data lakehouse é resolver esses problemas combinando os pontos fortes dos data lakes e dos data warehouses e minimizando seus pontos fracos.
Neste guia, mostrarei a você o que é um data lakehouse, como ele difere das arquiteturas de dados tradicionais e por que ele está ganhando popularidade entre os profissionais de dados que buscam uma solução unificada de gerenciamento de dados.
Um data lakehouse é uma arquitetura que combina a escalabilidade e o armazenamento de baixo custo dos data lakes com os recursos de desempenho, confiabilidade e governança dos data warehouses.
Ao integrar os pontos fortes de ambas as arquiteturas, um data lakehouse oferece uma plataforma unificada para armazenar, processar e analisar todos os tipos de dados - estruturados, semiestruturados e não estruturados.
A abordagem unificada permite maior flexibilidade no processamento de dados e oferece suporte a uma ampla variedade de casos de uso de análise, desde business intelligence até aprendizado de máquina.
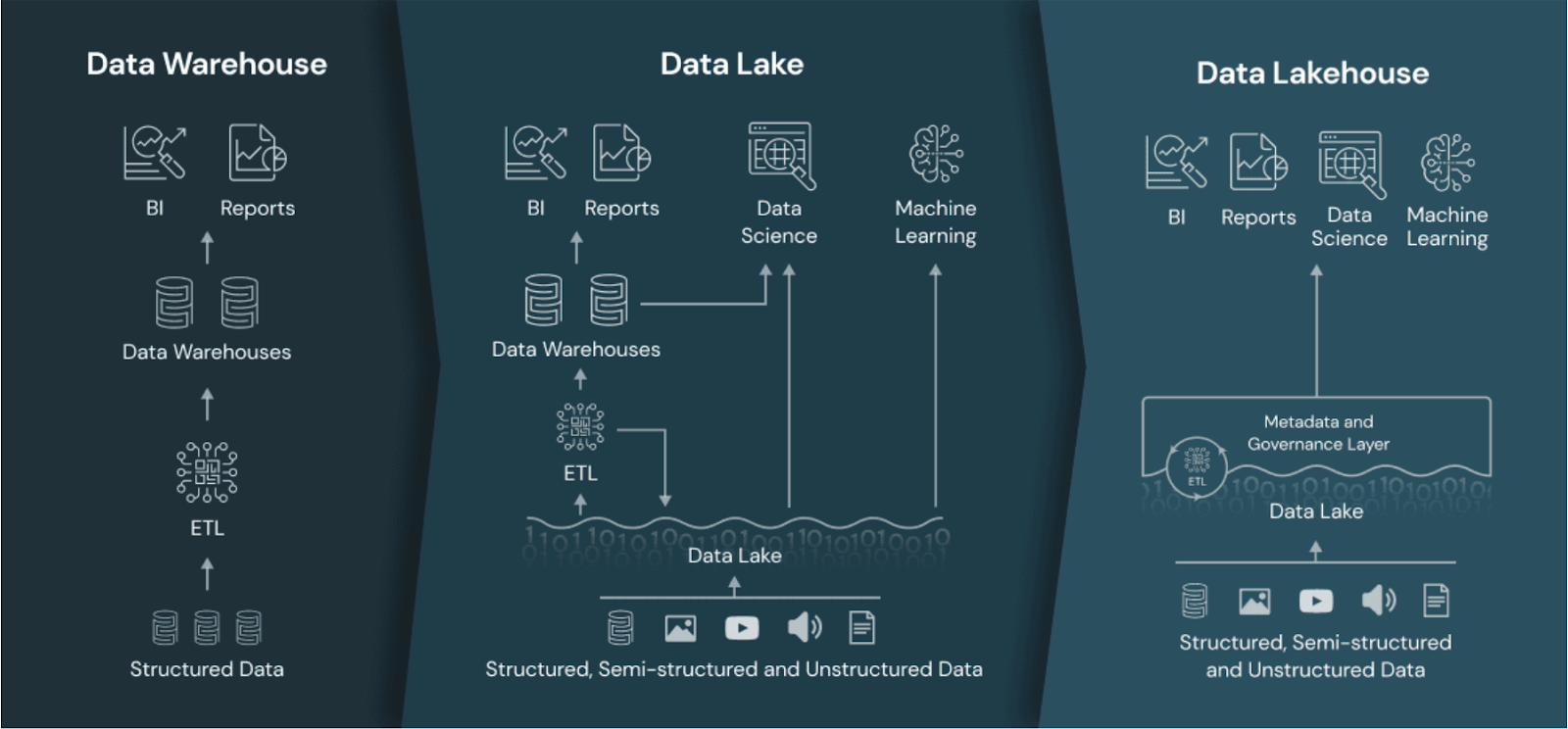
O data lakehouse em comparação com o data warehouse e o data lake. Fonte da imagem: Databricks.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
11 min
blog
Elena Kosourova
15 min
blog
Kurtis Pykes
10 min
blog
Tim Lu
12 min
blog
Javier Canales Luna
12 min
Tutorial
Kurtis Pykes




