
Cours
Introduction à PySpark
4 h
157.5K
La gestion des données a vu l'émergence de nouvelles solutions pour répondre aux limites des architectures traditionnelles telles que les lacs de données et les entrepôts de données. Si ces deux architectures ont joué un rôle déterminant dans le stockage et l'analyse des données, elles peuvent présenter des difficultés lorsqu'il s'agit de répondre aux besoins modernes en matière de traitement des données.
Bien qu'ils soient évolutifs et flexibles, les lacs de données sont souvent confrontés à des problèmes de gouvernance et de performance. D'autre part, les entrepôts de données, bien que puissants pour l'analyse, sont coûteux et moins flexibles. Le data lakehouse vise à résoudre ces problèmes en combinant les forces des data lakes et des entrepôts de données tout en minimisant leurs faiblesses.
Dans ce guide, je vous expliquerai ce qu'est un data lakehouse, en quoi il diffère des architectures de données traditionnelles et pourquoi il gagne en popularité parmi les professionnels des données à la recherche d'une solution de gestion unifiée des données.
Un data lakehouse est une architecture qui combine l'évolutivité et le stockage à faible coût des data lakes avec les performances, la fiabilité et les capacités de gouvernance des data warehouses.
En intégrant les points forts des deux architectures, un data lakehouse offre une plateforme unifiée pour le stockage, le traitement et l'analyse de tous les types de données - structurées, semi-structurées et non structurées.
L'approche unifiée permet une plus grande flexibilité dans le traitement des données et prend en charge un large éventail de cas d'utilisation analytique, de la veille stratégique à l'apprentissage automatique.
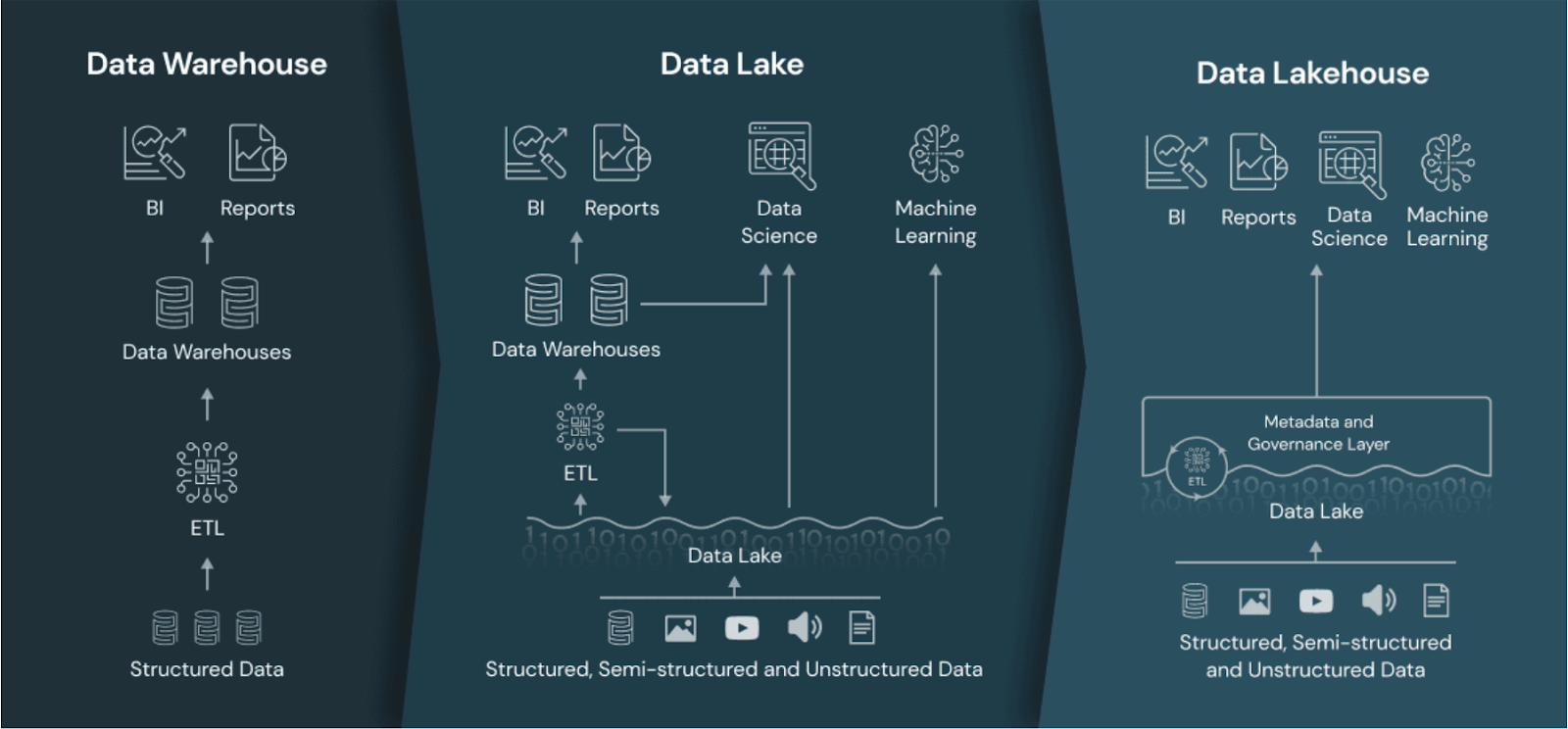
Le data lakehouse comparé au data warehouse et au data lake. Source de l'image : Les banques de données.
Avant d'explorer plus en détail l'architecture data lakehouse, il est important de comprendre comment elle se compare aux entrepôts de données et aux lacs de données.
Les entrepôts de données sont conçus pour stocker données structurées et fournir des analyses et des rapports de haute performance.
L'un de leurs principaux atouts est leur capacité à exécuter des requêtes rapides, ce qui les rend bien adaptés aux activités suivantes l'intelligence économique et le reporting cas d'utilisation.
Les entrepôts de données utilisent un schéma bien défini qui permet une bonne gouvernance des données. Cela garantit que les données sont exactes, cohérentes et facilement accessibles pour l'analyse.
Toutefois, ces avantages ont un coût. Les entrepôts de données sont généralement coûteux à maintenir parce qu'ils reposent sur du matériel spécialisé et des processus de transformation de données étendus, nécessitant généralement des pipelines ETL (extraction, transformation, chargement).
La structure rigide des entrepôts de données les rend également moins aptes à traiter des données non structurées ou à s'adapter rapidement à des changements de format de données. Cemanque de flexibilité du site peut constituer une limitation importante pour les organisations qui souhaitent travailler avec des sources de données en évolution rapide ou des données qui ne se conforment pas à un schéma prédéfini, comme le texte, les images, l'audio, etc.
Pour en savoir plus sur les principes fondamentaux de l'entreposage de données, consultez le cours gratuit Introduction à l'entreposage de données.
Les lacs de données sont conçus pour stocker de grandes quantités de données semi-structurées ou non structurées. Leur principal avantage réside dans leur capacité à évoluer, ce qui en fait une option attrayante pour les équipes qui traitent des types de données divers et des volumes de données massifs.
La flexibilité des lacs de données vous permet de stocker des données brutes dans leur format d'origine, ce qui les rend idéaux pour l'exploration des données et les projets scientifiques.
Cependant, les lacs de données sont souvent confrontés à des problèmes de gouvernance et de qualité des données. Les données étant stockées à l'état brut sans grande structure, il peut s'avérer difficile de garantir une qualité constante des données.
L'absence de manque de gouvernance peut conduire à ce que l'on appelle communément un "marécage de données", où des informations précieuses sont enfouies sous des données mal organisées.
La performance est une autre préoccupation essentielle dans les lacs de données, en particulier pour l'exécution de requêtes analytiques complexes. Les lacs de données ne sont pas optimisés pour une interrogation rapide ou pour la combinaison de différents types de données, tels que les images, le texte et l'audio.
Un data lakehouse vise à combiner le meilleur des data lakes et des data warehouses. Il offre une solution plus équilibrée en intégrant l'évolutivité et les capacités de stockage à faible coût des lacs de données aux performances et à la gouvernance des entrepôts de données.
En théorie, dans un Lakehouse, vous pouvez stocker des données structurées et non structurées à moindre coût tout en tirant parti des capacités nécessaires à une analyse performante.
Les lacs de données prennent en charge les transactions ACID, ce qui signifie que les mises à jour et les suppressions de données peuvent être gérées de manière fiable, ce qui fait souvent défaut dans les lacs de données traditionnels. Cela permet d'améliorer l'intégrité et la gouvernance des données, ce qui rend les entrepôts de données plus adaptés aux applications d'entreprise.
Les entrepôts de données prennent également en charge le traitement des données en temps réel, ce qui permet aux organisations de traiter des données en continu et d'obtenir des informations en temps réel, ce qui est important dans certains contextes.
Comment est-il possible d'avoir le meilleur des deux mondes dans une seule plateforme ? Dans cette section, j'expliquerai les éléments qui rendent possible l'architecture d'une maison de lac.
Dans un lac de données, le stockage et l'informatique sont séparés mais étroitement intégrés, ce qui permet une utilisation flexible et évolutive des ressources.
Les données sont stockées dans un magasin d'objets dans le cloud rentable, tandis que les ressources de calcul peuvent être mises à l'échelle de manière indépendante en fonction des demandes de charge de travail. Cette approche réduit la nécessité de déplacer les données entre les systèmes, ce qui permet aux utilisateurs de traiter les données sur place sans avoir à les extraire et à les charger.
En intégrant le stockage et le calcul de cette manière, les entrepôts de données rationalisent la gestion des données, améliorent l'efficacité et réduisent la latence, ce qui permet d'obtenir des informations plus rapidement.
L'allocation dynamique des ressources permet également une meilleure optimisation des coûts et garantit une utilisation efficace des ressources informatiques.
Les entrepôts de données (data lakehouses) appliquent des schémas pour maintenir la qualité des données tout en offrant des fonctions de gouvernance pour la conformité des données.
L'application des schémas garantit que les données sont organisées dans un format structuré, ce qui facilite la recherche et l'analyse. Cela permet d'éviter les incohérences dans les données et d'améliorer la qualité des données dans l'ensemble de l'organisation.
Les fonctions de gouvernance des entrepôts de données vous permettent de gérer l'accès aux données, le suivi et la conformité. Grâce à des outils de gouvernance intégrés, les entrepôts de données peuvent répondre aux exigences réglementaires et protéger les données sensibles. Ceci est particulièrement important pour des secteurs tels que les soins de santé et la finance, où la confidentialité des données et la conformité sont essentielles.
Les transactions ACID garantissent la fiabilité des données, ce qui vous permet de gérer les mises à jour et les suppressions en toute confiance.
Dans un entrepôt de données, les transactions ACID offrent le même niveau d'intégrité des données que celui attendu d'un entrepôt de données traditionnel, mais avec la flexibilité supplémentaire de traiter des données non structurées.
La capacité à prendre en charge les transactions ACID signifie que les entrepôts de données peuvent être utilisés pour des charges de travail critiques où l'exactitude des données est essentielle. Cette caractéristique fait des entrepôts de données un choix intéressant pour les entreprises qui doivent maintenir la cohérence des données entre les différentes opérations de données.
Les entrepôts de données peuvent traiter les données en temps réel, ce qui permet des cas d'utilisation tels que l'analyse en temps réel et les informations en continu. Le traitement des données en temps réel permet aux équipes de prendre plus rapidement des décisions fondées sur des données, ce qui améliore la réactivité et l'adaptabilité.
Par exemple, le traitement des données en temps réel peut être utilisé pour surveiller les interactions avec les clients, suivre les niveaux de stocks ou détecter des anomalies dans les transactions financières. En vous permettant d'obtenir des informations immédiates, les entrepôts de données vous aident à garder une longueur d'avance sur l'évolution des conditions du marché et à réagir de manière proactive aux nouvelles opportunités.
Les data lakehouses peuvent fonctionner dans des environnements multi-cloud ou hybrides, offrant ainsi flexibilité et évolutivité.
La prise en charge multi-cloud permet aux équipes chargées des données d'éviter le verrouillage des fournisseurs et de tirer parti des meilleurs services des différents fournisseurs de cloud. La prise en charge de l'architecture hybride garantit que les systèmes sur site s'intègrent aux environnements cloud, offrant ainsi une expérience de gestion des données unifiée.
Cette flexibilité profite particulièrement aux équipes ayant des besoins complexes en matière d'infrastructure ou à celles qui procèdent à une migration vers le cloud.
Dans cette section, nous examinerons les avantages de l'utilisation d'un lac de données pour gérer divers besoins en matière de traitement des données.
Les data lakehouses héritent de l'évolutivité des data lakes, ce qui leur permet de répondre à des besoins croissants en matière de données. Vous pouvez facilement ajouter des données sans vous soucier des limites de stockage, ce qui garantit que votre architecture de données évolue avec l'entreprise.
Par exemple, Apache Hudi, Delta Lake et Apache Iceberg peuvent mettre à l'échelle le stockage de milliers de fichiers dans des systèmes de stockage d'objets comme Amazon S3, Azure Blob Storage ou Google Cloud Storage.
La flexibilité est un autre avantage important, car les entrepôts de données prennent en charge les données structurées (par exemple, les enregistrements de transactions) et non structurées (par exemple, les fichiers journaux, les images et les vidéos). Cela signifie que vous pouvez stocker toutes vos données en un seul endroit, quel que soit leur format, et les utiliser pour divers cas d'utilisation en matière d'analyse et d'apprentissage automatique.
Les lacs de données stockent les données à un coût inférieur à celui des entrepôts de données, tout en permettant des analyses avancées.
Par exemple, les entrepôts de données construits sur le stockage d'objets dans le nuage (comme Amazon S3 ou Google Cloud Storage) tirent parti de leurs niveaux de stockage rentables. Combinés aux formats de fichiers Apache Parquet et ORC, qui compressent les données pour minimiser les coûts de stockage, les entrepôts de données vous permettent de réaliser des économies substantielles.
La nature unifiée des entrepôts de données signifie qu'il n'est pas nécessaire de maintenir des systèmes distincts pour le stockage et l'analyse, ce qui permet de réduire les coûts et fait des entrepôts de données une option attrayante.
Les capacités unifiées de stockage et de traitement des données réduisent le temps nécessaire pour obtenir des informations. Les entrepôts de données éliminent la nécessité de déplacer les données entre les environnements de stockage et de calcul, rationalisant ainsi les flux de travail et minimisant les temps de latence.
Des technologies comme Apache Spark et Databricks permettent de traiter les données directement dans le lac, ce qui évite de les déplacer vers des environnements d'analyse distincts.
En regroupant toutes les données en un seul endroit et en les traitant efficacement, vous pouvez rapidement obtenir des informations qui vous permettront de prendre de meilleures décisions. Cette rapidité d'exécution est particulièrement précieuse pour les secteurs où il est crucial de disposer d'informations en temps voulu, comme la finance, le commerce de détail et les soins de santé.
Les fonctions d' application des schémas et de gouvernance des données répondent aux normes de qualité et de conformité des données. Les entrepôts de données fournissent des outils permettant de gérer l'accès aux données, les pistes d'audit et le cheminement des données, ce qui est essentiel pour maintenir l'intégrité des données et répondre aux exigences réglementaires.
Des outils tels que AWS Lake Formation, Azure Purview et Apache Ranger offrent un contrôle centralisé de l'accès aux données, des autorisations et des pistes d'audit, ce qui vous permet de gérer les données en toute sécurité et d'empêcher les accès non autorisés.
Ces caractéristiques de gouvernance et de sécurité font que les entrepôts de données conviennent aux entreprises qui doivent se conformer aux réglementations en matière de confidentialité des données, telles que le GDPR ou l'HIPAA. En veillant à ce que les données soient correctement gérées et protégées, les entrepôts de données contribuent à renforcer la confiance dans les données et les informations qu'elles contiennent.
Dans cette section, nous allons passer en revue tous les cas d'utilisation possibles pour le data lakehouse.
Les équipes chargées des données utilisent les entrepôts de données pour l'analyse en temps réel, la veille stratégique et les flux de travail d'apprentissage automatique. En fournissant une plateforme de données unifiée, les entrepôts de données permettent aux professionnels d'analyser les données historiques et en temps réel, et d'obtenir des informations qui améliorent les résultats de l'entreprise.
Par exemple, les détaillants peuvent utiliser les entrepôts de données pour analyser les données de vente en temps réel, identifier les tendances et ajuster leurs stocks en conséquence. Les institutions financières peuvent s'appuyer sur les entrepôts de données pour effectuer des analyses de risque et détecter les fraudes, en combinant les données historiques et les données de transaction en temps réel pour obtenir une vue d'ensemble.
Consultez le cours gratuit Comprendre l'architecture des données modernes pour en savoir plus sur le fonctionnement des plateformes de données modernes, depuis l'ingestion et le service jusqu'à la gouvernance et l'orchestration.
Les data lakehouses fournissent l'infrastructure nécessaire à la construction et à la mise à l'échelle des modèles d'IA et de ML, avec un accès facile aux données structurées et non structurées. Les modèles d'apprentissage automatique nécessitent souvent une variété de types de données, et les entrepôts de données permettent de rassembler toutes les données pertinentes en un seul endroit.
Cet accès unifié aux données simplifie le processus de formation, de test et de déploiement des modèles d'apprentissage automatique. Les scientifiques des données peuvent rapidement expérimenter avec différents ensembles de données, itérer sur les modèles et les adapter à la production sans avoir à se soucier des silos de données ou des mouvements entre les systèmes.
Les entrepôts de données (data lakehouses) alimentent des applications basées sur les données qui nécessitent des informations en temps réel et des capacités de prise de décision. Ces applications s'appuient souvent sur des informations actualisées pour offrir aux utilisateurs des expériences personnalisées ou des recommandations automatisées.
Par exemple, le moteur de recommandation d'un site de commerce électronique peut utiliser un lac de données pour analyser le comportement de l'utilisateur en temps réel et fournir des suggestions de produits pertinentes. De même, les entreprises de logistique peuvent utiliser les entrepôts de données pour optimiser les itinéraires de livraison sur la base des données de trafic en temps réel et des schémas de livraison historiques.
Il est temps de découvrir les technologies qui rendent possible l'architecture du lac de données. Dans cette section, j'explique les plus populaires d'entre eux.
Databricks a été le pionnier de l'architecture de lac de données, en proposant Delta Lake comme élément central de sa plateforme. Delta Lake améliore la fiabilité et les performances des lacs de données, en permettant des transactions ACID et en garantissant la qualité des données.
Databricks Lakehouse combine l'évolutivité des lacs de données avec les fonctionnalités de gestion des données des entrepôts de données, fournissant une plateforme unifiée pour l'analyse et l'apprentissage automatique. Son intégration avec Apache Spark en fait un choix intéressant pour les organisations qui exploitent les capacités de traitement des big data.
Si vous souhaitez en savoir plus sur la plateforme Databricks Lakehouse et sur la façon dont elle peut moderniser les architectures de données et améliorer les processus de gestion des données, consultez le cours gratuit Introduction à Databricks.
BigLake de Google intègre les principes du data lakehouse à son écosystème cloud existant, fournissant ainsi une plateforme unifiée de stockage de données et d'analyse. BigLake permet aux utilisateurs de gérer des données structurées et non structurées, facilitant ainsi l'analyse de différents types de données.
Grâce à l'intégration avec les services Google Cloud, BigLake offre une solution complète aux équipes chargées des données qui cherchent à utiliser des outils cloud-native pour leurs besoins en la matière. Il prend en charge le traitement par lots et en temps réel, ce qui le rend adapté à un large éventail de cas d'utilisation.
AWS Lake Formation fournit des outils pour mettre en place un lac de données en utilisant les services cloud d'AWS, offrant une intégration et une gestion transparentes. Avec AWS Lake Formation, vous pouvez facilement ingérer, cataloguer et sécuriser les données, créant ainsi un lac de données unifié.
AWS Lake Formation s'intègre également à d'autres services d'analyse AWS, tels qu'Amazon Redshift et AWS Glue, offrant ainsi une suite complète d'outils pour le traitement et l'analyse des données. Cela en fait une option intéressante pour les organisations qui utilisent déjà AWS pour leur infrastructure.
L'architecture de Snowflake évolue pour prendre en charge les capacités de data lakehouse, permettant aux utilisateurs de gérer efficacement les données structurées et semi-structurées. Snowflake permet de réaliser des analyses très performantes tout en offrant une grande souplesse dans le stockage et la gestion des données.
Les fonctionnalités de data lakehouse de Snowflake vous permettent de combiner différents types de données et d'effectuer des analyses avancées sans avoir besoin de plusieurs systèmes. Sa conception cloud-native et sa prise en charge des déploiements multi-cloud en font un choix populaire pour les équipes qui cherchent à moderniser leur infrastructure de données.
Si vous êtes intéressé par Snowflake, consultez le cours Introduction à Snowflake.
Azure Synapse Analytics de Microsoft combine les capacités de big data et d'entreposage de données dans une solution unifiée de lac de données.
Synapse permet aux équipes d'analyser des données structurées et non structurées à l'aide de divers outils, notamment SQL, Apache Spark et Data Explorer. Son intégration profonde avec d'autres services Azure, tels que Azure Data Lake Storage et Power BI, offre une expérience transparente pour le traitement, l'analyse et la visualisation des données de bout en bout, ce qui en fait une option idéale pour les organisations au sein de l'écosystème Azure.
Apache Hudi est un projet open-source qui apporte des capacités transactionnelles aux lacs de données. Il prend en charge les transactions ACID, les insertions et les versions de données.
Hudi s'intègre bien aux plateformes de stockage dans le cloud comme Amazon S3 and Google Cloud Storage, ce qui le rend adapté à l'analyse en temps réel et aux pipelines d'apprentissage automatique. Avec la prise en charge de moteurs big data populaires comme Apache Spark et Presto, Hudi offre la flexibilité nécessaire pour construire un data lakehouse personnalisé sur une technologie open-source.
Dremio fournit une plateforme de lac de données ouverte pour des charges de travail analytiques et de BI rapides directement sur des lacs de données dans le cloud.
Grâce à son approche basée sur SQL et à son intégration avec Apache Arrow, Dremio permet aux équipes d'effectuer des analyses de haute performance sans déplacement de données. Il est avantageux pour les organisations qui cherchent à prendre en charge les requêtes SQLsur leurs lacs de données, ce qui en fait un choix populaire pour les équipes de données qui donnent la priorité à la vitesse et à l'efficacité.
Comme vous pouvez l'imaginer, toutes les technologies qui soutiennent l'architecture du lac de données ne sont pas égales. Le tableau suivant les compare sur plusieurs catégories :
|
Plate-forme |
Type de stockage primaire |
Prise en charge des données structurées et non structurées |
Moteur de calcul |
Transactions ACID |
Traitement en temps réel |
Intégration avec ML/AI |
Cas d'utilisation idéal |
|
Maison du lac de Databricks |
Lac Delta (Parquet Apache) |
Oui |
Apache Spark |
Oui |
Oui |
Fort (MLflow, Spark ML) |
Analyse des big data, IA/ML |
|
Google BigLake |
Stockage dans le nuage de Google |
Oui |
Google BigQuery |
Oui |
Oui |
Intégré à Google Cloud AI |
Analyses basées sur le cloud |
|
Formation d'AWS Lake |
Amazon S3 |
Oui |
Amazon Redshift / AWS Glue |
Oui |
Limitée |
Intégration d'Amazon SageMaker |
Centre de données centré sur AWS |
|
Snowflake |
Propriétaire (basé sur le cloud) |
Principalement structuré |
Snowflake Compute |
Oui |
Limitée |
Limitée |
Analyse multi-cloud et haute performance. |
|
Azure Synapse Analytics |
Stockage de lac de données Azure |
Oui |
SQL, Apache Spark, Data Explorer |
Oui |
Oui |
Fort (Azure ML, Power BI) |
Analyse de l'écosystème Microsoft |
|
Apache Hudi |
Stockage d'objets dans le cloud (par exemple, S3, GCS) |
Oui |
Apache Spark, Presto |
Oui |
Oui |
Soutien externe au ML |
Lacs de données en temps réel open-source |
|
Dremio |
Lacs de données en nuage |
Oui |
Dremio (Flèche Apache) |
Non |
Oui |
Pas d'intégration native |
SQL haute performance sur les lacs en nuage |
Certaines choses sont trop belles pour être vraies, et la maison des données ne fait pas exception à la règle. Il semble tout offrir, mais il présente aussi quelques inconvénients. Passons-les en revue dans cette section.
L'intégration d'un data lakehouse avec des systèmes existants peut s'avérer complexe et nécessite une planification minutieuse. Les équipes peuvent avoir besoin de migrer des données à partir de lacs de données ou d'entrepôts existants, ce qui peut prendre du temps et nécessiter des ressources importantes.
Des problèmes de compatibilité peuvent également survenir lors de l'intégration avec des systèmes plus anciens qui ne sont pas conçus pour fonctionner avec des architectures de données modernes. Pour réussir la mise en place d'un data lakehouse, vous devez évaluer votre infrastructure actuelle, planifier la migration des données et vous assurer que tous les systèmes peuvent fonctionner harmonieusement ensemble.
Trouver un équilibre entre l'évolutivité, la gouvernance et la sécurité peut s'avérer difficile, en particulier dans les secteurs réglementés. Les entrepôts de données doivent fournir des outils de gouvernance robustes pour gérer l'accès aux données, le lignage et la conformité, tout en maintenant l'évolutivité nécessaire pour gérer de grands ensembles de données.
Il est également essentiel de veiller à ce que les données sensibles soient correctement sécurisées. Vous devez mettre en place des contrôles d'accès, un cryptage et un audit pour protéger vos données et répondre aux exigences réglementaires. Cela peut s'avérer particulièrement difficile dans les environnements hybrides et multiclouds, où les données sont réparties sur différents sites.
Lors de la mise en place d'un data lakehouse, il peut être difficile de trouver le bon équilibre entre rentabilité et performance. Alors que les entrepôts de données offrent un stockage rentable, la réalisation d'analyses de haute performance peut nécessiter un investissement supplémentaire dans les ressources informatiques.
Vous devez évaluer soigneusement les exigences de la charge de travail et déterminer le moyen le plus rentable de répondre à vos besoins en matière de performances. Il peut s'agir d'optimiser l'allocation des ressources, de choisir les bons services cloud ou d'ajuster la configuration du data lakehouse pour s'assurer que les objectifs de coût et de performance sont atteints.
Les data lakehouses représentent une évolution significative dans l'architecture des données, combinant les forces des data lakes et des data warehouses en une seule plateforme unifiée !
Grâce au respect des schémas, à la prise en charge des transactions ACID, à l'évolutivité et au traitement des données en temps réel, les entrepôts de données constituent une solution puissante pour répondre aux besoins modernes en matière de données.
Les entrepôts de données (data lakehouses) constituent une option intéressante pour les équipes chargées des données qui cherchent à simplifier leur paysage de données et à améliorer leurs capacités d'analyse.
Explorez le cours gratuit Comprendre l'ingénierie des données pour en savoir plus sur les entrepôts de données (data lakehouses) et les autres technologies émergentes d'ingénierie des données.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Les entrepôts de données combinent l'évolutivité et l'analyse robuste, ce qui les rend rentables pour les entreprises qui recherchent la flexibilité, la haute performance et la connaissance des données en temps réel.
Les entrepôts de données doivent équilibrer les performances pour les données structurées et non structurées, ce qui peut être complexe. La mise en œuvre de la gouvernance et de la sécurité pour différents types de données et l'intégration avec des systèmes existants posent également des défis.
Les entrepôts de données utilisent des couches de métadonnées (comme le traitement des métadonnées de Delta Lake) pour organiser, appliquer des schémas et optimiser les requêtes, améliorant ainsi la découverte, la gouvernance et la performance des données.
Bien que les lacustres puissent souvent remplacer les lacs de données et les entrepôts, certains cas d'utilisation spécialisés peuvent encore nécessiter des systèmes dédiés. Pour la plupart des besoins, les maisons de lac offrent une solution unifiée et flexible.
Des technologies comme Delta Lake et Apache Hudi autorisent le versionnage des données, ce qui permet aux utilisateurs de suivre les modifications, d'effectuer des retours en arrière et de garantir la cohérence des données au fil du temps.
Les entrepôts de données favorisent la démocratisation des données en offrant une plateforme unique où toutes les données sont accessibles et gérées, ce qui permet à des équipes plus larges d'accéder aux données et de les exploiter en toute sécurité.
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours