
Kurs
Einführung in PySpark
4 Std.
157.5K
Im Datenmanagement sind neue Lösungen entstanden, die die Grenzen traditioneller Architekturen wie Data Lakes und Data Warehouses überwinden. Obwohl beide Architekturen bei der Datenspeicherung und -analyse eine wichtige Rolle gespielt haben, können sie bei der Bewältigung moderner Datenverarbeitungsanforderungen eine Herausforderung darstellen.
Obwohl Data Lakes skalierbar und flexibel sind, gibt es oft Probleme mit der Governance und der Leistung. Andererseits sind Data Warehouses zwar leistungsfähig für Analysen, aber kostspielig und weniger flexibel. Das Data Lakehouse zielt darauf ab, diese Probleme zu lösen, indem es die Stärken von Data Lakes und Warehouses kombiniert und ihre Schwächen minimiert.
In diesem Leitfaden erkläre ich dir, was ein Data Lakehouse ist, wie es sich von traditionellen Datenarchitekturen unterscheidet und warum es bei Datenexperten, die nach einer einheitlichen Datenmanagementlösung suchen, immer beliebter wird.
Ein Data Lakehouse ist eine Architektur, die die Skalierbarkeit und kostengünstige Speicherung von Data Lakes mit der Leistung, Zuverlässigkeit und den Governance-Funktionen von Data Warehouses kombiniert.
Durch die Integration der Stärken beider Architekturen bietet ein Data Lakehouse eine einheitliche Plattform zum Speichern, Verarbeiten und Analysieren aller Arten von Daten - strukturierte, halbstrukturierte und unstrukturierte.
Der einheitliche Ansatz ermöglicht eine größere Flexibilität bei der Datenverarbeitung und unterstützt eine breite Palette von Analyseanwendungen, von Business Intelligence bis hin zum maschinellen Lernen.
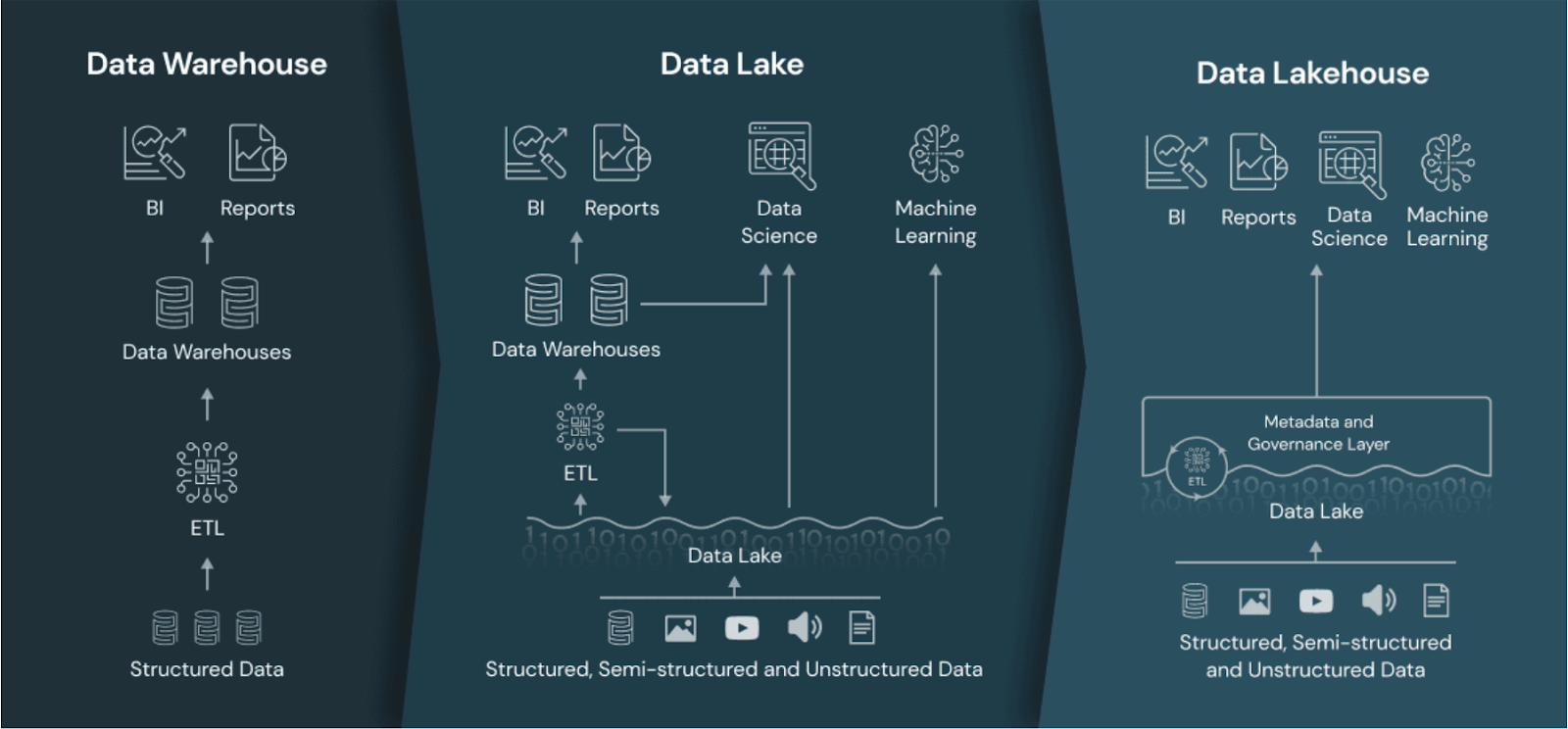
Das Data Lakehouse im Vergleich zum Data Warehouse und Data Lake. Bildquelle: Databricks.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
