
Course
Foundations of PySpark
4 hr
157.5K
Data management has seen the emergence of new solutions to address the limitations of traditional architectures like data lakes and data warehouses. While both architectures have been instrumental in data storage and analytics, they can present challenges in addressing modern data processing needs.
Despite being scalable and flexible, data lakes often face governance and performance issues. On the other hand, data warehouses, although powerful for analytics, are costly and less flexible. The data lakehouse aims to solve these problems by combining the strengths of data lakes and warehouses while minimizing their weaknesses.
In this guide, I’ll walk you through what a data lakehouse is, how it differs from traditional data architectures, and why it is gaining popularity among data professionals looking for a unified data management solution.
A data lakehouse is an architecture that combines the scalability and low-cost storage of data lakes with the performance, reliability, and governance capabilities of data warehouses.
By integrating the strengths of both architectures, a data lakehouse offers a unified platform for storing, processing, and analyzing all types of data—structured, semi-structured, and unstructured.
The unified approach allows for greater flexibility in data processing and supports a wide range of analytics use cases, from business intelligence to machine learning.
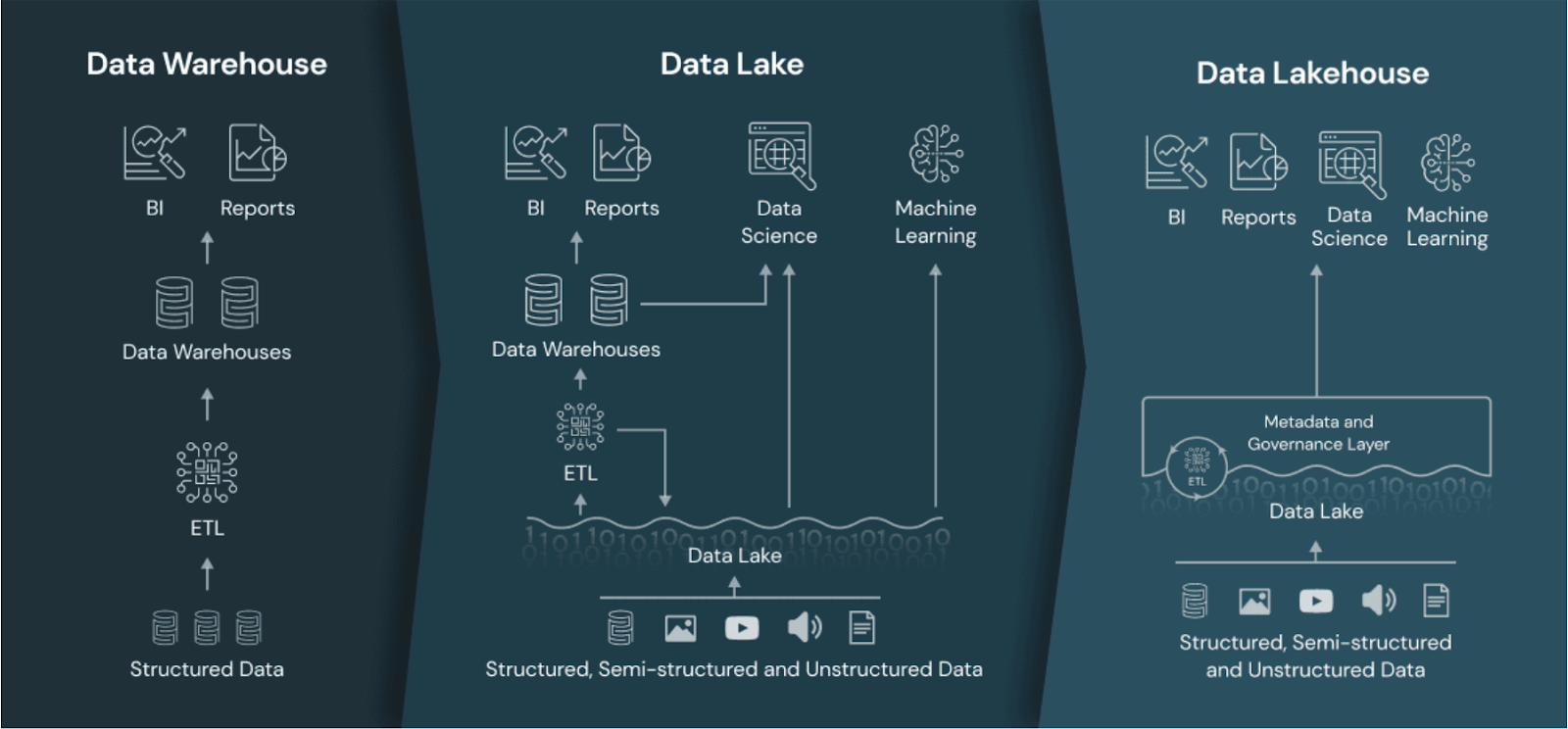
The data lakehouse compared to the data warehouse and data lake. Image source: Databricks.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn more about data engineering with these courses!
Course
Course
Course
blog
Amberle McKee
8 min
blog
DataCamp Team
4 min
blog
Alex Castrounis
13 min
blog
Amberle McKee
13 min
blog
Sanjana Putchala
10 min
Tutorial
Arunn Thevapalan

