Course
Introduction to Natural Language Processing in Python
4 hr
141K
This blog post will introduce the concept of 'transfer learning' and how it is used in machine learning applications. Transfer learning is not a machine learning model or technique; it is rather a 'design methodology' within machine learning. Another type of 'design methodology' is, for example, active learning.

A next blog post will explain how you can use active learning in conjunction with transfer learning to optimally leverage existing (and new) data. In a broad sense, machine learning applications that leverage external information to improve the performance or generalisation capabilities use transfer learning.
The general idea of transfer learning is to use knowledge learned from tasks for which a lot of labelled data is available in settings where only little labelled data is available. Creating labelled data is expensive, so optimally leveraging existing datasets is key.
In a traditional machine learning model, the primary goal is to generalise to unseen data based on patterns learned from the training data. With transfer learning, you attempt to kickstart this generalisation process by starting from patterns that have been learned for a different task. Essentially, instead of starting the learning process from a (often randomly initialised) blank sheet, you start from patterns that have been learned to solve a different task.
Transfer of knowledge and patterns is possible in a wide variety of domains. Today's post will illustrate transfer learning by looking at several examples of these different domains. The goal is to incentivise data scientists to experiment with transfer learning in their machine learning projects and to make them aware of the advantages and disadvantages.
There are three reasons why I believe a good understanding of transfer learning is a critical skill as a data scientist:
 |
 |
Transfer learning, as the name states, requires the ability to transfer knowledge from one domain to another. Transfer learning can be interpreted on a high level, that is, NLP model architectures can be re-used in sequence prediction problems, since a lot of NLP problems can inherently be reduced to sequence prediction problems. Transfer learning can also be interpreted on a low level, where you are actually reusing parameters from one model in a different model (skip-gram, continuous bag-of-words, etc.). The requirements of transfer learning are on one hand problem specific and on the other one model specific. The next two sections will discuss respectively a high level and low level approach to transfer learning. Although you will typically find these concepts with different names in literature, the overarching concept of transfer learning is still present.
In multi-task learning, you train a model on different tasks at the same time. Typically, deep learning models are used as they can be adapted flexibly.
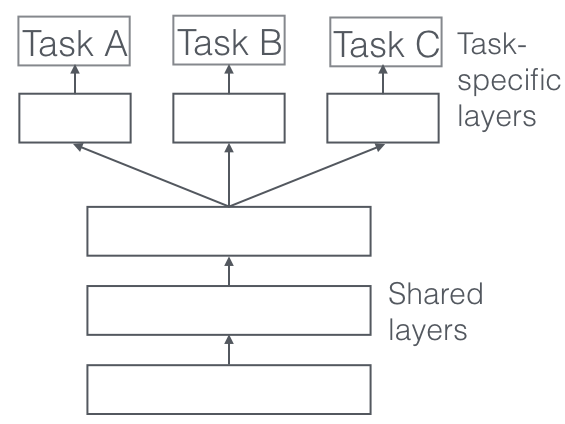
The network architecture is adapted in such a way that the first layers are used across different tasks, followed with different task-specific layers and outputs for the different tasks. The general idea is that by training a network on different tasks, the network will generalise better, as the model is required to perform well on tasks for which similar 'knowledge' or 'processing' is required.
An example in the case of Natural Language Processing is a model for which the end goal is to perform entity recognition. Instead of training the model purely on the entity recognition task, you also use it to perform part of speech classification, next word prediction, ... As such, the model wil benefit from the structure learned from those tasks and the different datasets. I highly recommend this blog by Sebastian Rude and this blog, which both tackle multi-task learning to learn more about multi-task learning.
One of the great advantages of a deep learning model is that feature extraction is 'automatic'. Based on the labelled data and backpropagation, the network is able to determine the useful features for a task. The network 'figures out' what part of the input is important in order to, for example, classify an image. This means that the manual job of feature definition is abstracted away. Deep learning networks can be reused in other problems, as the type of features that are extracted, are often useful for other problems as well. Essentialy, in a featuriser you use the first layers of the network to determine the useful feature, but you dont use the output of the network, as it is too task-specific.
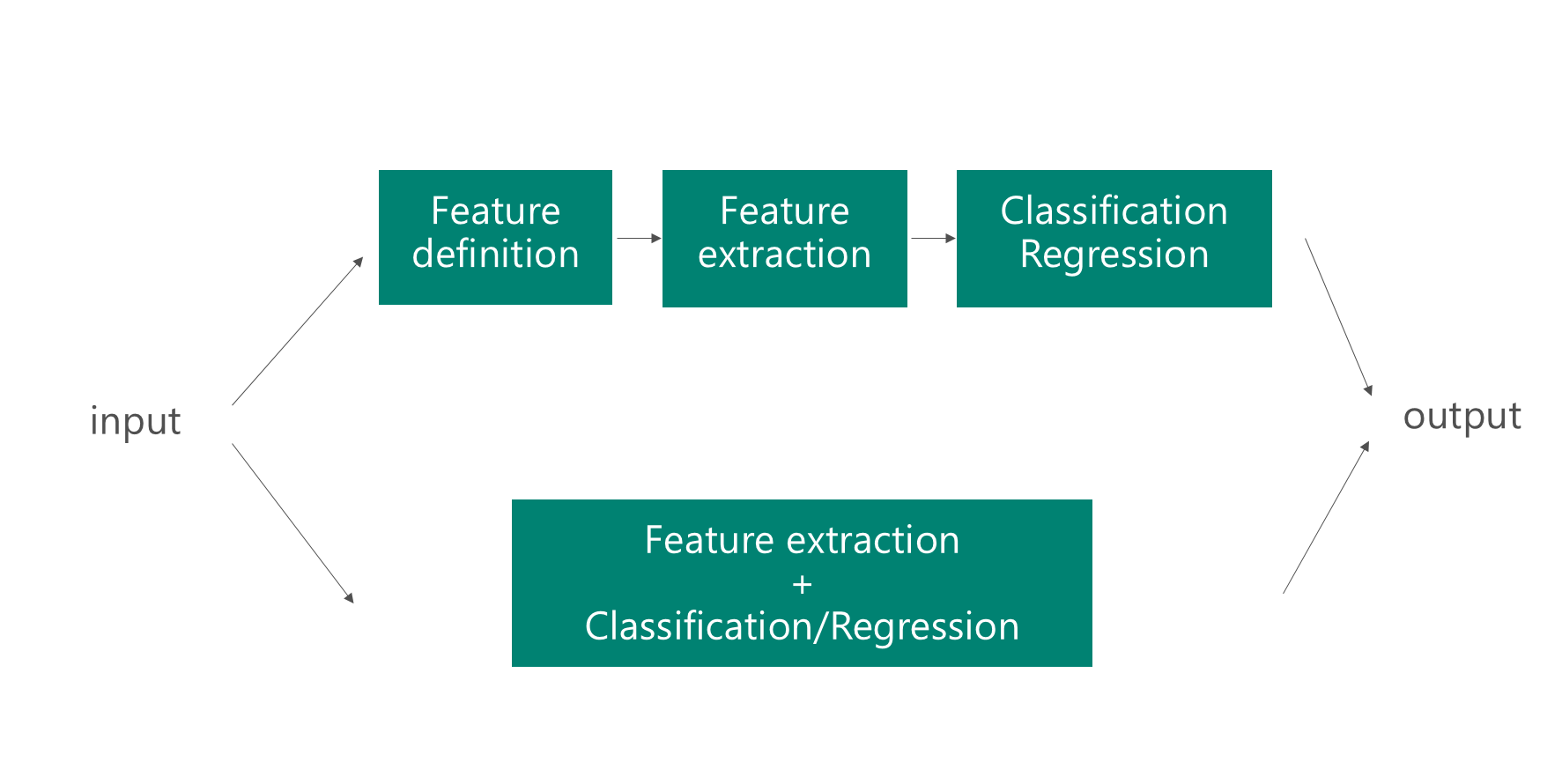
Given that deep learning systems are good at feature extraction, how can you reuse existing networks to perform feature extraction for other tasks? It is possible to feed a data sample into the network, and take one of the intermediate layers in the network as output. This intermediate layer can be interpreted as a fixed length, processed representation of raw data. Typically, the concept of a featuriser is used in the context of computer vision. Images are then fed into a pre-trained network (for example, VGG or AlexNet) and a different machine learning method is used on the new data representation. Extracting an intermediate layer as a representation of the image significantly reduces the original data size, making them more amenable for traditional machine learning techniques (for example, logistic regression or SVMs work better with a small representation of an image, such as dimension 128, compared to the original, for example, 128x128=16384 dimension).
One of my previous blog posts discussed how a lot of NLP pipelines nowadays use word embeddings. These word embeddings are a more informative way of representing words, compared to one-hot encodings. They are widely used, and different variants exist. Typically these variants differ in the corpus they originate from, such as Wikipedia, news articles, etc., and the differences in the embedding models. It is important to understand the background of these models and corpuses in order to know whether transfer learning with word embeddings is sensible. People typically wouldn't call the use of word embeddings transfer learning, yet I disagree, given the similarity with transfer learning with computer vision. Essentially, using word embeddings means that you are using a featuriser or the embedding network to convert words to vectors.
Even though word2vec is already 4 years old, it is still a very influential word embedding approach. Recent approaches on the other hand such as FastText have made word embeddings available in a large number of languages. Embeddings from word2vec or FastText are a significant step forwards compared to bag-of-words approaches. Nevertheless, their usefulness is typically determined by the problem domain.
Imagine you are building a news recommendation service for sales people. The sales people want to receive news on companies that could be interested in the product they are selling. The vocabulary that is used in news articles is typically fairly generic or general, meaning that a vocabulary is used that is often supported by most word embeddings (depending on the corpus they are trained on). In addition, if you have the sales people collect the news articles they read for a couple of weeks, then you immediately have a large labelled corpus at your hands. By being able to reuse word embeddings it is possible that the recommendation engine will perform significantly better.
On the other hand, imagine that you have to perform topic classification on legal contracts. Not just any type of legal contracts, but French legal contracts in the context of competition law. These type of datasets are typically not labelled, or only a limited set of labeled documents are available. The next section will describe why out-of-the-box transfer learning will only get you so far in this case:
I highly advise you to read this excellent blog post on the current state of word embeddings. Taking into account the problems and solutions mentioned in this blog post is key to creating robust NLP systems and word embeddings when working with limited amounts of data.
Gensim, spacy and FastText are three great frameworks that allow you to quickly use word embeddings in your machine learning application. In addition, they also support the training of custom word embeddings. Check out this gensim, this spacy or this FastText tutorial to get to know more!
Deep learning methods have led to significant successes in computer vision. Instead of having to define problem specific features manually, for example, Histogram of Oriented Gradients (HoG) features, histogram features, etc., deep learning allows practitioners to train models that take raw images as input. The original complexity of feature definition has now shifted towards the complexity of defining the network. While architectures are often reused, there is no single strategy in composing network architectures. Typically, deep learning techniques have been invented and applied in research settings on enormous datasets (such as Imagenet or MS Coco). To increase performance on these large datasets, researchers have come up with network architectures with increasing depth and complexity. These architectures result in models with millions of parameters that are (typically) not scalable to small image datasets. Training an architecture such as residential network (ResNet) or VGG net on a dataset with less than 5,000 images will simply lead to significant overfitting. The recent deep learning trend has lead to significant advancements, yet it seems data scientists with only small datasets have been left in the cold.
As it turns out, deep learning networks learn hierarchical feature representations (see this blog post by Distill). This means that the lower level layers learn low level features, such as edges, whereas the higher level layers learn higher level, yet uninterpretable concepts, such as shapes. This idea of hierarchical feature representations also occurs when the network is trained on different datasets, indicating that they can be reused in different problem domains.
Two approaches are used when using transfer learning on computer vision problems.
The API of Keras allows you to load pre-trained networks and keep several of the layers fixed during training. In the next section I will again discuss two use cases, respectively one where transfer learning is useful, and another where it isn't.
Imagine working in wildlife preservation, and you want to classify the different animals that appear on a live camera feed. Especially if you are trying the monitor species that are near extinction, it is possible that you won't be able to gather a lot of labelled data. Given that the pre-trained networks are often trained on wide domain of concepts (ranging from food, to animals and objects), using a pre-trained network as a featuriser or as initialiser is definitely an option.
On the other hand, imagine you need to analyse radiography images for oncologists. These images are not your typical cat-dog images, as they are the output of a scan which was performed on a patient. These images, although converted to RGB images, are typically in greyshades to illustrate the results of the scan. Although a pre-trained network is able to detect shapes and edges from RGB images, they will most likely have difficulty detecting those on radiography images as those are not in the training data of the pre-trained model. In addition, in medical scenario's, the amount of labelled data is typically low. Several techniques exist to leverage (the potentially abundant) unlabelled data, but they typically require more work and finetuning. Typically, these techniques attempt to pre-train the weights of the classification network, by iteratively training each layer to reconstruct the images (using convolutional and deconvolutional layers). A combination of these techniques and pre-trained network is often used to improve convergence.
Both methods in computer vision mentioned above rely on an important assumption: patterns extracted in the original dataset are useful in the context of the new dataset. This usefulness is hard to quantify, yet it is an important assumption to take into account. Seismic, hyperspectral or even medical imagery shows limited similarity with the images in ImageNet. Determining which traffic sign an image contains however, relies on fairly similar patterns. Understanding the computer vision problem domain is crucial to successfully applying computer vision. By knowing the background of models (datasets, techniques, etc.) that are used in transfer learning, you can avoid wasting time during experimentation and focus on finetuning those models that might make the difference.
Machine Learning Courses
Course
Course
Course
blog
Javier Canales Luna
7 min
blog
Joyce Chiu
5 min
blog
Kurtis Pykes
15 min
blog
Vidhi Chugh
15 min
blog
Victor Jotham Ashioya
7 min
Tutorial
Kurtis Pykes


