
Curso
Despliegue y ciclo de vida en MLOps
4 h
12K
Llama Stack es un marco creado para agilizar el desarrollo y despliegue de aplicaciones de IA generativa construidas sobre modelos Llama de Meta. Lo consigue proporcionando una colección de API estandarizadas y componentes para tareas como la inferencia, la seguridad, la gestión de la memoria y las capacidades de los agentes.
He aquí sus objetivos y ventajas:
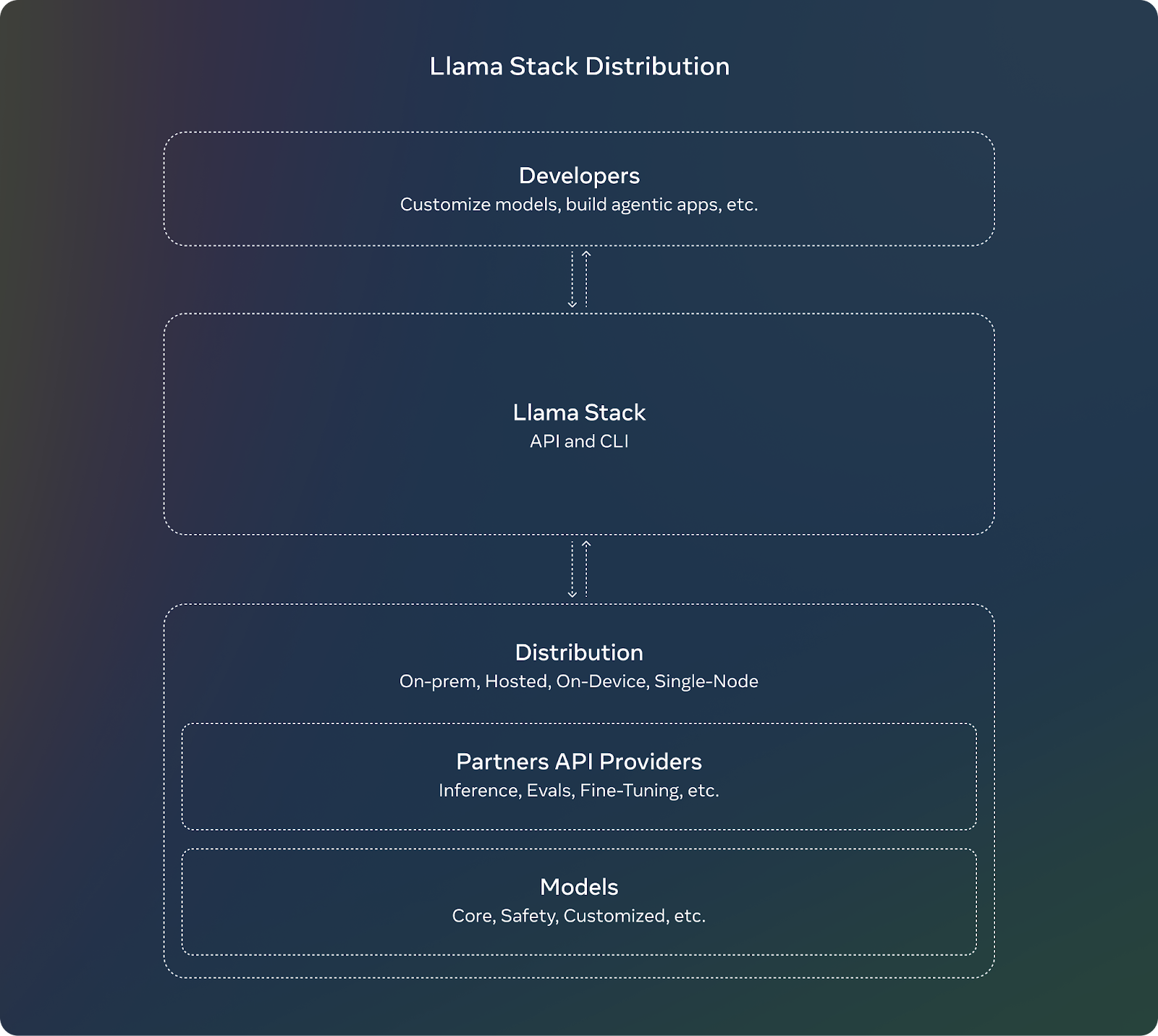
Fuente: Meta AI
Llama Stack viene con varias API, cada una dirigida a un conjunto específico de tareas en la construcción de una aplicación de IA generativa.
La API de inferencia se encarga de generación de texto o indicaciones multimodal Llama a variaciones. Sus características principales son:
La API define varias configuraciones que permiten a los desarrolladores controlar el comportamiento del modelo (por ejemplo, FP8 o BF16 cuantización) en función de los requisitos de su aplicación.
La API de seguridad está pensada para el despliegue responsable de modelos de IA mediante la moderación de contenidos y el filtrado de resultados perjudiciales o potencialmente sesgados. Es configurable para definir niveles de infracción (por ejemplo, INFO, WARN, ERROR) y para devolver mensajes procesables a los usuarios.
La API de Memoria otorga la capacidad de retener y referirse a interacciones pasadas y crear conversaciones más coherentes y conscientes del contexto. La variedad de configuraciones de memoria ofrece a los desarrolladores la posibilidad de elegir los tipos de almacenamiento en función de las necesidades de la aplicación. Sus características principales son:
La API Agentic permite a los LLM utilizar herramientas y funciones externas, permitiéndoles realizar tareas como la búsqueda en la web, la ejecución de código o la recuperación de memoria. La API permite a los desarrolladores configurar agentes con herramientas y objetivos específicos. Admite interacciones multiturno en las que cada turno consta de varios pasos. Sus características principales son:
Éstas son las otras API que ofrece Llama Stack:
Implementaremos un proyecto de ejemplo en Llama Stack para familiarizarnos con la idea general y las capacidades de este framework.
Antes de empezar, ten en cuenta que
Empecemos por configurar la interfaz de línea de comandos (CLI) de Llama.
La Pila Llama proporciona una Interfaz de Línea de Comandos (CLI) para gestionar distribuciones, instalar modelos y configurar entornos. Estos son los pasos de instalación que debemos seguir:
1. Crea y activa un entorno virtual:
conda create -n llama_stack python=3.10
conda activate llama_stack2. Clona el repositorio de Llama Stack: ```bash
git clone <https://github.com/meta-llama/llama-stack.git>
cd llama-pila
3. Install the required dependencies:```bash
pip install -r requirements.txtLos contenedores Docker simplifican el despliegue del servidor Llama Stack y de los proveedores de la API del agente. Hay disponibles imágenes Docker preconstruidas para facilitar la configuración:
docker pull llamastack/llamastack-local-gpu
llama stack build
llama stack configure llamastack-local-gpuEstos comandos extraen la imagen Docker, la construyen y configuran la pila.
Vamos a construir un chatbot básico utilizando las API de Llama Stack. Éstos son los pasos que debemos dar:
Ejecutaremos el servidor en el puerto 5000. Asegúrate de que el servidor está funcionando antes de trabajar con las API:
llama stack run local-gpu --port 5000Tras instalar la Pila Llama, puedes utilizar código cliente para interactuar con sus API. Utiliza la API de Inferencia para generar respuestas basadas en la entrada del usuario:
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="<http://localhost:5000>")
user_input = "Hello! How are you?"
response = client.inference.chat_completion(
model="Llama3.1-8B-Instruct",
messages=[{"role": "user", "content": user_input}],
stream=False
)
print("Bot:", response.text)Nota: Sustituye "Llama3.1-8B-Instruct" por el nombre del modelo real disponible en tu configuración.
Pon en marcha la API de seguridad para moderar las respuestas y garantizar que son adecuadas:
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": response.text}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
print("Unsafe content detected.")
else:
print("Bot:", response.text)Crea la conciencia de contexto del chatbot almacenando y recuperando el historial de conversaciones:
### building a memory bank that can be used to store and retrieve context.
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)Además, podemos combinar las API para construir un chatbot robusto:
Aquí está el código completo después de cubrir todos los pasos:
import uuid
client = LlamaStackClient(base_url="<http://localhost:5000>")
### create a memory bank at the start
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)
def get_bot_response(user_input):
### retrieving conversation history
query_response = client.memory.query_documents(
bank_id=bank.bank_id,
query=[user_input],
params={"max_chunks": 10}
)
history = [chunk.content for chunk in query_response.chunks]
### preparing messages with history
messages = [{"role": "user", "content": user_input}]
if history:
messages.insert(0, {"role": "system", "content": "\\n".join(history)})
### generate response
response = client.inference.chat_completion(
model="llama-2-7b-chat",
messages=messages,
stream=False
)
bot_response = response.text
### safety check
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": bot_response}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
return "I'm sorry, but I can't assist with that request."
### memory storing
documents = [
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=user_input,
mime_type="text/plain"
),
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=bot_response,
mime_type="text/plain"
)
]
client.memory.insert_documents(
bank_id=bank.bank_id,
documents=documents
)
return bot_response
### putting all together
while True:
user_input = input("You: ")
if user_input.lower() == "bye":
break
bot_response = get_bot_response(user_input)
print("Bot:", bot_response)Para ver algunos ejemplos y poner en marcha tu implementación de aplicaciones utilizando Llama Stack, Meta ha proporcionado el archivo llama-stack-apps donde puedes ver algunas aplicaciones de ejemplo. Asegúrate de comprobar y familiarizarte con el marco.
Como proyecto de código abierto, Llama Stack vive de las contribuciones de la comunidad. Las API están evolucionando rápidamente, y el proyecto está abierto a los comentarios y a la participación de los desarrolladores, que ayudarán a dar forma al futuro de la plataforma. Si pruebas Llama Stack, puede ayudar a otros desarrolladores si también compartes tu proyecto como ejemplo, o contribuyes a la documentación.
A lo largo de este artículo, hemos explorado cómo empezar a utilizar Llama Stack mediante instrucciones paso a paso.
A medida que avances en el despliegue de tus aplicaciones de IA, recuerda echar un vistazo al repositorio Llama Stack para conocer las últimas actualizaciones y mejoras.
Para saber más sobre el ecosistema de la llama, consulta los siguientes recursos:
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita


