
Course
MLOps Deployment and Life Cycling
4 hr
12K
Llama Stack is a framework built to streamline the development and deployment of generative AI applications built on top of Meta’s Llama models. It achieves this by providing a collection of standardized APIs and components for tasks such as inference, safety, memory management, and agent capabilities.
Here are its goals and benefits:
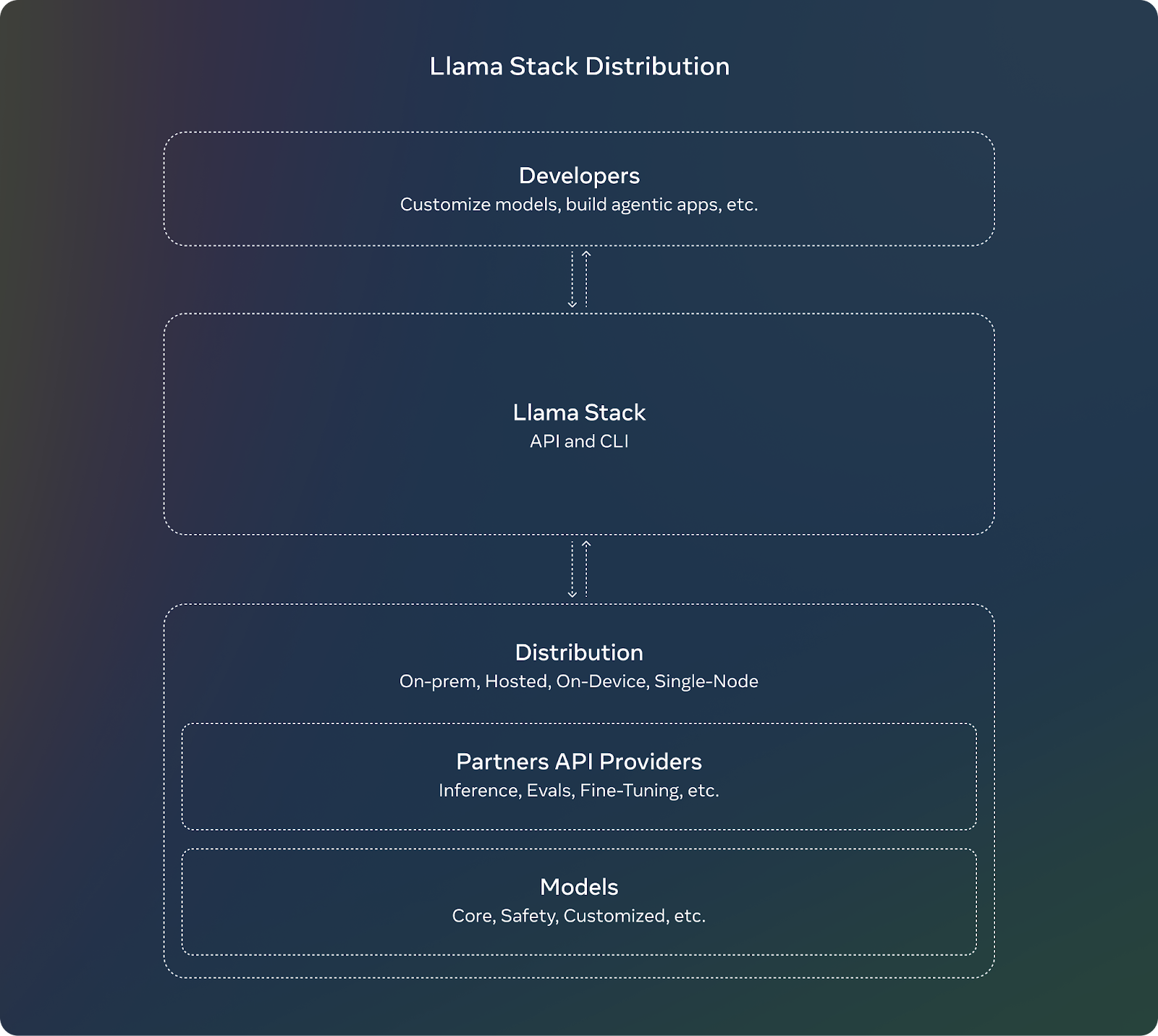
Source: Meta AI
Llama Stack comes with several APIs, each targeting a specific set of tasks in building a generative AI application.
The Inference API handles the generation of text or prompting multi-modal Llama variations. Its key features are:
The API defines various configurations enabling developers to control model behavior (e.g., FP8 or BF16 quantization) based on their application requirements.
The Safety API is built for responsible deployment of AI models through moderating content and filtering harmful or potentially biased outputs. It is configurable to define violation levels (e.g., INFO, WARN, ERROR) and to return actionable messages to users.
The Memory API grants the ability to retain and refer to past interactions and create more coherent conversations that are contextually aware. The variety of memory configurations gives developers the option to choose storage types based on application needs. Its key features are:
The Agentic API enables LLMs to use external tools and functions, allowing them to perform tasks such as web search, code execution, or retrieving memory. The API allows developers to configure agents with specific tools and goals. It supports multi-turn interactions where each turn consists of multiple steps. Its key features are:
Here are the other APIs that Llama Stack offers:
We will implement a sample project on Llama Stack to familiarize ourselves with the general idea and capabilities of this framework.
Before we begin, please be aware that:
Let’s start with setting up the Llama command-line interface (CLI).
The Llama Stack provides a Command-Line Interface (CLI) for managing distributions, installing models, and configuring environments. Here are the installation steps we need to take:
a. Create and activate a virtual environment:
conda create -n llama_stack python=3.10
conda activate llama_stackb. Clone the Llama Stack repository:
git clone <https://github.com/meta-llama/llama-stack.git>
cd llama-stackc. Install the required dependencies:
pip install llama-stack
pip install -r requirements.txtDocker containers simplify the deployment of the Llama Stack server and agent API providers. Pre-built Docker images are available for easy setup:
docker pull llamastack/llamastack-local-gpu
llama stack build
llama stack configure llamastack-local-gpuThese commands pull the Docker image, build it, and configure the stack.
Let's build a basic chatbot using the Llama Stack APIs. Here are the steps we need to take:
We will run the server on port 5000. Ensure the server is running before working with the APIs:
llama stack run local-gpu --port 5000After installing the Llama Stack, you can use client code to interact with its APIs. Use the Inference API to generate responses based on user input:
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="<http://localhost:5000>")
user_input = "Hello! How are you?"
response = client.inference.chat_completion(
model="Llama3.1-8B-Instruct",
messages=[{"role": "user", "content": user_input}],
stream=False
)
print("Bot:", response.text)Note: Replace "Llama3.1-8B-Instruct" with the actual model name available in your setup.
Implement the Safety API to moderate responses and ensure they are appropriate:
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": response.text}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
print("Unsafe content detected.")
else:
print("Bot:", response.text)Create the chatbot's context awareness by storing and retrieving conversation history:
### building a memory bank that can be used to store and retrieve context.
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)We can further combine the APIs to build a robust chatbot:
Here’s the complete code after covering all the steps:
import uuid
client = LlamaStackClient(base_url="<http://localhost:5000>")
### create a memory bank at the start
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)
def get_bot_response(user_input):
### retrieving conversation history
query_response = client.memory.query_documents(
bank_id=bank.bank_id,
query=[user_input],
params={"max_chunks": 10}
)
history = [chunk.content for chunk in query_response.chunks]
### preparing messages with history
messages = [{"role": "user", "content": user_input}]
if history:
messages.insert(0, {"role": "system", "content": "\\n".join(history)})
### generate response
response = client.inference.chat_completion(
model="llama-2-7b-chat",
messages=messages,
stream=False
)
bot_response = response.text
### safety check
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": bot_response}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
return "I'm sorry, but I can't assist with that request."
### memory storing
documents = [
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=user_input,
mime_type="text/plain"
),
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=bot_response,
mime_type="text/plain"
)
]
client.memory.insert_documents(
bank_id=bank.bank_id,
documents=documents
)
return bot_response
### putting all together
while True:
user_input = input("You: ")
if user_input.lower() == "bye":
break
bot_response = get_bot_response(user_input)
print("Bot:", bot_response)To see some examples and jump start your implementation of applications using Llama Stack, Meta has provided the llama-stack-apps repository where you can look at some example applications. Make sure to check out and familiarize yourself with the framework.
As an open-source project, Llama Stack lives off of community contributions. The APIs are evolving rapidly, and the project is open to feedback and participation from developers, helping shape the future of the platform. If you test out Llama Stack, it can help other developers if you also shared your project as an example, or contributed to the documentation.
Throughout this article, we explored how to get started with Llama Stack through step-by-step instructions.
As you move forward in deploying your AI applications, remember to keep an eye on the Llama Stack repository for the latest updates and enhancements.
To learn more about the Llama ecosystem, check out the following resources:
Learn AI with these courses!
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Richie Cotton
8 min
blog
Abid Ali Awan
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Aashi Dutt
Tutorial
Ryan Ong

