
Curso
Implantação e ciclo de vida em MLOps
4 h
12K
O Llama Stack é uma estrutura criada para simplificar o desenvolvimento e a implementação de aplicativos de IA generativa criados com base nos modelos Llama da Meta. modelos Llama da Meta. Para isso, ele fornece uma coleção de APIs e componentes padronizados para tarefas como inferência, segurança, gerenciamento de memória e recursos de agente.
Aqui estão seus objetivos e benefícios:
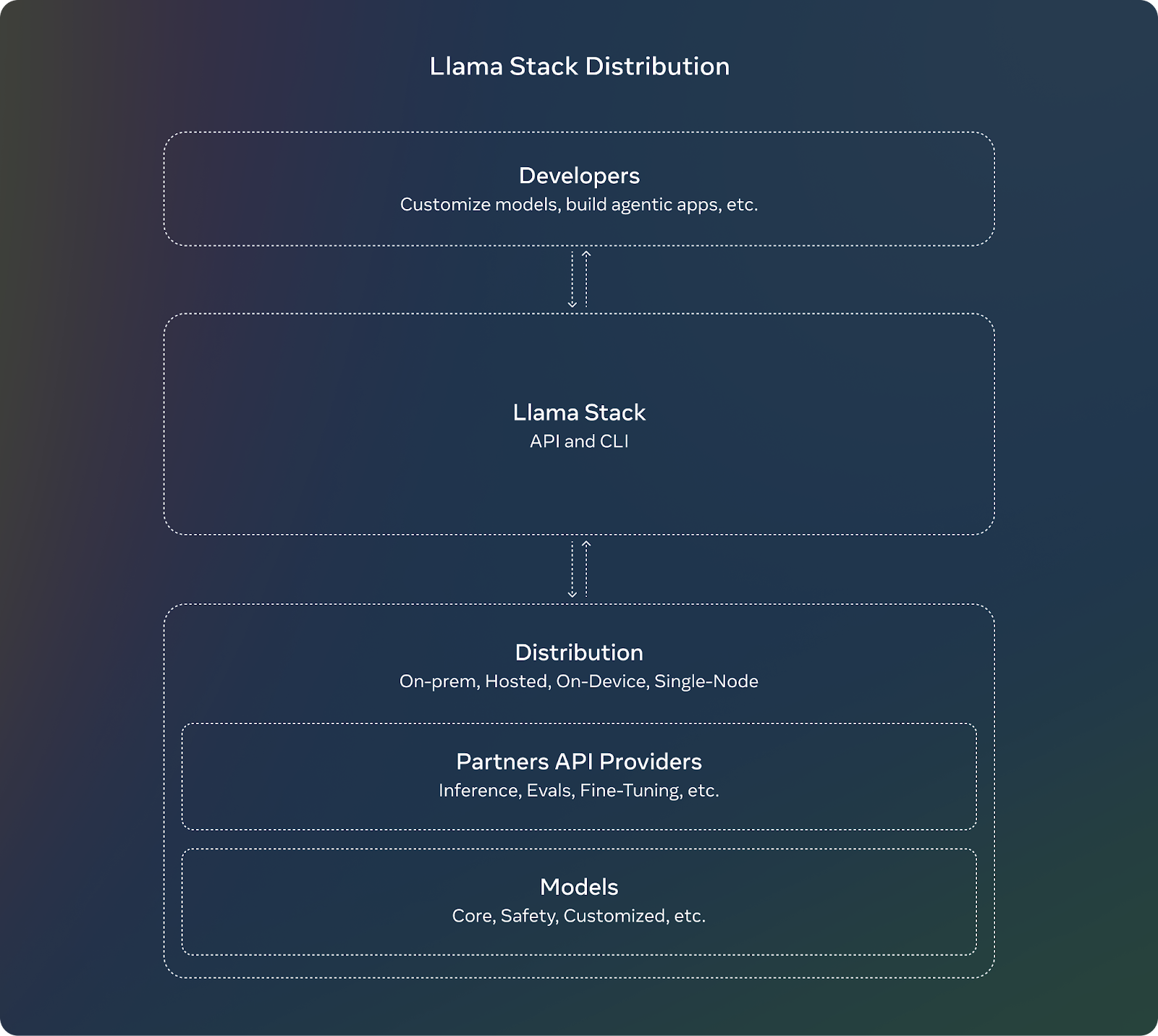
Fonte: Meta AI
O Llama Stack vem com várias APIs, cada uma voltada para um conjunto específico de tarefas na criação de um aplicativo de IA generativa.
A API de inferência lida com a geração de texto ou de solicitações multimodais variações do Llama. Seus principais recursos são:
A API define várias configurações que permitem aos desenvolvedores controlar o comportamento do modelo (por exemplo, FP8 ou BF16 quantização) com base nos requisitos de seus aplicativos.
A API de segurança foi criada para implantação responsável de modelos de IA por meio da moderação de conteúdo e da filtragem de resultados prejudiciais ou potencialmente tendenciosos. Ele é configurável para definir níveis de violação (por exemplo, INFO, WARN, ERROR) e para retornar mensagens acionáveis aos usuários.
A API de memória concede a você a capacidade de reter e consultar interações passadas e criar conversas mais coerentes e contextualmente conscientes. A variedade de configurações de memória oferece aos desenvolvedores a opção de escolher tipos de armazenamento com base nas necessidades dos aplicativos. Seus principais recursos são:
A API Agentic permite que os LLMs usem ferramentas e funções externas, possibilitando a realização de tarefas como pesquisa na Web, execução de código ou recuperação de memória. A API permite que os desenvolvedores configurem agentes com ferramentas e objetivos específicos. Ele oferece suporte a interações de várias voltas, em que cada volta consiste em várias etapas. Seus principais recursos são:
Aqui estão as outras APIs que a Llama Stack oferece:
Implementaremos um projeto de amostra no Llama Stack para que você se familiarize com a ideia geral e os recursos dessa estrutura.
Antes de começarmos, você deve estar ciente de que:
Vamos começar com a configuração da interface de linha de comando (CLI) do Llama.
O Llama Stack oferece uma interface de linha de comando (CLI) para gerenciar distribuições, instalar modelos e configurar ambientes. Aqui estão as etapas de instalação que você precisa realizar:
1. Crie e ative um ambiente virtual:
conda create -n llama_stack python=3.10
conda activate llama_stack2. Clone o repositório do Llama Stack: ```bash
git clone <https://github.com/meta-llama/llama-stack.git>
cd llama-stack
3. Install the required dependencies:```bash
pip install -r requirements.txtDocker simplificam a implantação do servidor Llama Stack e dos provedores de API do agente. Imagens pré-construídas do Docker estão disponíveis para facilitar a configuração:
docker pull llamastack/llamastack-local-gpu
llama stack build
llama stack configure llamastack-local-gpuEsses comandos extraem a imagem do Docker, criam-na e configuram a pilha.
Vamos criar um chatbot básico usando as APIs do Llama Stack. Aqui estão as etapas que precisamos seguir:
Executaremos o servidor na porta 5000. Certifique-se de que o servidor esteja em execução antes de trabalhar com as APIs:
llama stack run local-gpu --port 5000Depois de instalar o Llama Stack, você pode usar o código do cliente para interagir com suas APIs. Use a API de inferência para gerar respostas com base na entrada do usuário:
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="<http://localhost:5000>")
user_input = "Hello! How are you?"
response = client.inference.chat_completion(
model="Llama3.1-8B-Instruct",
messages=[{"role": "user", "content": user_input}],
stream=False
)
print("Bot:", response.text)Observação: Substitua "Llama3.1-8B-Instruct" pelo nome do modelo real disponível em sua configuração.
Implemente a API de segurança para moderar as respostas e garantir que elas sejam apropriadas:
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": response.text}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
print("Unsafe content detected.")
else:
print("Bot:", response.text)Crie o reconhecimento do contexto do chatbot armazenando e recuperando o histórico de conversas:
### building a memory bank that can be used to store and retrieve context.
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)Além disso, podemos combinar as APIs para criar um chatbot robusto:
Aqui está o código completo depois de cobrir todas as etapas:
import uuid
client = LlamaStackClient(base_url="<http://localhost:5000>")
### create a memory bank at the start
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)
def get_bot_response(user_input):
### retrieving conversation history
query_response = client.memory.query_documents(
bank_id=bank.bank_id,
query=[user_input],
params={"max_chunks": 10}
)
history = [chunk.content for chunk in query_response.chunks]
### preparing messages with history
messages = [{"role": "user", "content": user_input}]
if history:
messages.insert(0, {"role": "system", "content": "\\n".join(history)})
### generate response
response = client.inference.chat_completion(
model="llama-2-7b-chat",
messages=messages,
stream=False
)
bot_response = response.text
### safety check
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": bot_response}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
return "I'm sorry, but I can't assist with that request."
### memory storing
documents = [
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=user_input,
mime_type="text/plain"
),
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=bot_response,
mime_type="text/plain"
)
]
client.memory.insert_documents(
bank_id=bank.bank_id,
documents=documents
)
return bot_response
### putting all together
while True:
user_input = input("You: ")
if user_input.lower() == "bye":
break
bot_response = get_bot_response(user_input)
print("Bot:", bot_response)Para que você possa ver alguns exemplos e iniciar a implementação de aplicativos usando o Llama Stack, o Meta forneceu o arquivo llama-stack-apps no qual você pode ver alguns aplicativos de exemplo. Não deixe de conferir e se familiarizar com a estrutura.
Como um projeto de código aberto, o Llama Stack vive das contribuições da comunidade. As APIs estão evoluindo rapidamente e o projeto está aberto ao feedback e à participação dos desenvolvedores, ajudando a moldar o futuro da plataforma. Se você testar o Llama Stack, poderá ajudar outros desenvolvedores se também compartilhar o seu projeto como um exemplo ou contribuir com a documentação.
Ao longo deste artigo, exploramos como você pode começar a usar o Llama Stack por meio de instruções passo a passo.
À medida que você avança na implantação de seus aplicativos de IA, lembre-se de ficar de olho no repositório do Llama Stack para que você receba as atualizações e os aprimoramentos mais recentes.
Para saber mais sobre o ecossistema da lhama, confira os seguintes recursos:
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Josep Ferrer

