
Kurs
MLOps-Bereitstellung und Lebenszyklus
4 Std.
12K
Llama Stack ist ein Framework, das die Entwicklung und den Einsatz von generativen KI-Anwendungen auf der Grundlage von Meta's Llama Modelle. Dies wird durch die Bereitstellung einer Sammlung standardisierter APIs und Komponenten für Aufgaben wie Inferenz, Sicherheit, Speicherverwaltung und Agentenfähigkeiten erreicht.
Hier sind seine Ziele und Vorteile:
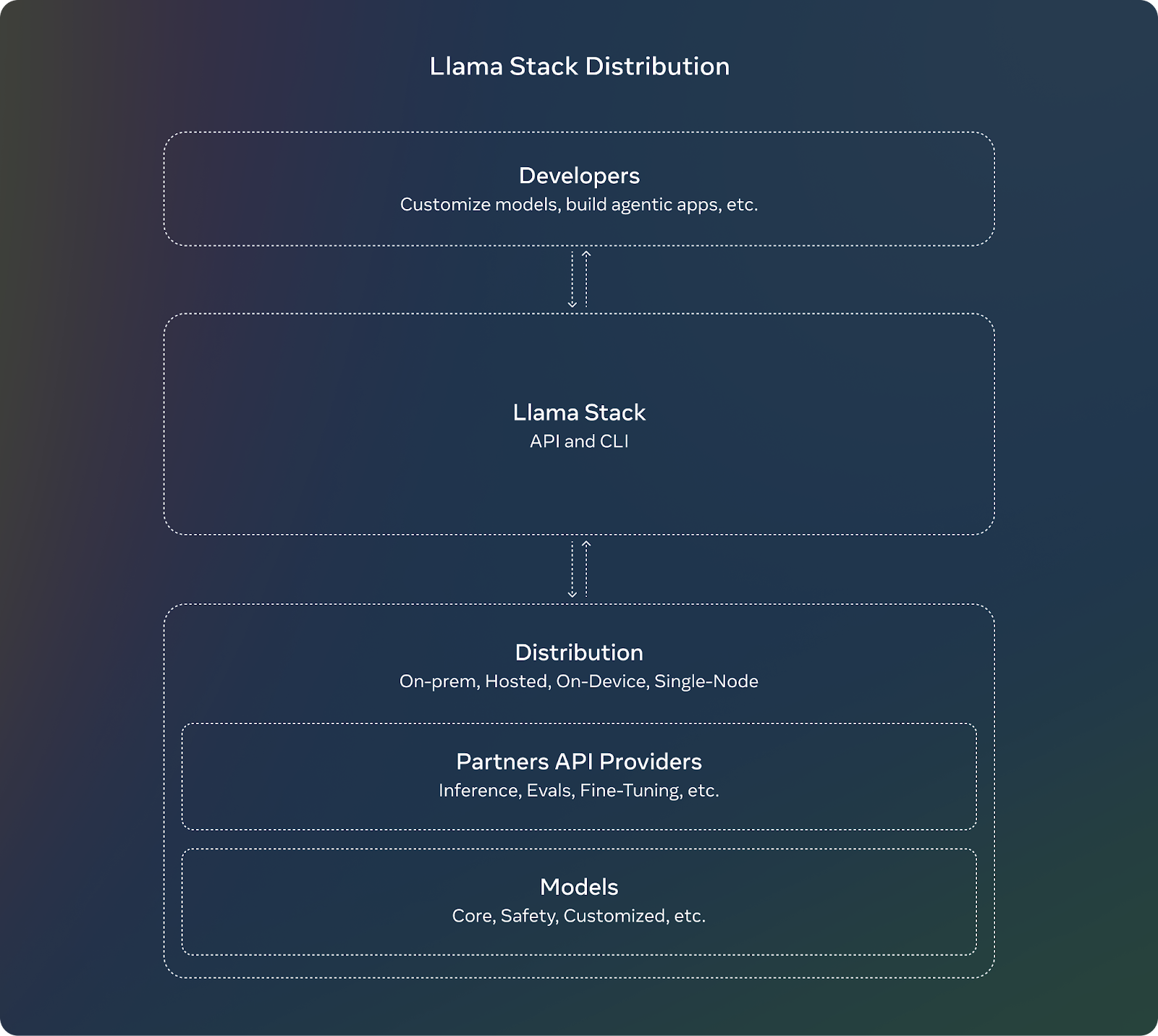
Quelle: Meta AI
Llama Stack wird mit mehreren APIs geliefert, die jeweils auf bestimmte Aufgaben beim Aufbau einer generativen KI-Anwendung abzielen.
Die Inference API übernimmt die Erzeugung von Text oder Eingabeaufforderungen multimodale Llama-Variationen. Seine wichtigsten Merkmale sind:
Die API definiert verschiedene Konfigurationen, mit denen Entwickler das Modellverhalten steuern können (z. B. FP8 oder BF16 Quantisierung) je nach den Anforderungen ihrer Anwendung steuern können.
Die Safety API wurde entwickelt für verantwortungsvollen Einsatz von KI-Modellen durch die Moderation von Inhalten und das Filtern von schädlichen oder potenziell verzerrten Ergebnissen. Sie kann so konfiguriert werden, dass sie Verletzungsstufen (z.B. INFO, WARN, ERROR) festlegt und Meldungen an die Benutzer/innen zurückgibt.
Die Memory API ermöglicht es, vergangene Interaktionen zu speichern und auf sie zurückzugreifen, um kohärentere und kontextbewusste Konversationen zu führen. Die verschiedenen Speicherkonfigurationen geben Entwicklern die Möglichkeit, je nach Anwendungsbedarf verschiedene Speichertypen zu wählen. Seine wichtigsten Merkmale sind:
Die Agenten-API ermöglicht es LLMs, externe Tools und Funktionen zu nutzen, mit denen sie Aufgaben wie Websuche, Codeausführung oder Speicherabruf durchführen können. Die API ermöglicht Entwicklern die Konfiguration von Agenten mit bestimmten Tools und Zielen zu konfigurieren. Es unterstützt Multi-Turn-Interaktionen, bei denen jeder Zug aus mehreren Schritten besteht. Seine wichtigsten Merkmale sind:
Hier sind die anderen APIs, die Llama Stack anbietet:
Wir werden ein Beispielprojekt auf Llama Stack implementieren, um uns mit der allgemeinen Idee und den Möglichkeiten dieses Frameworks vertraut zu machen.
Bevor wir beginnen, solltest du wissen, dass:
Beginnen wir mit der Einrichtung der Llama-Befehlszeilenschnittstelle (CLI).
Der Llama Stack bietet eine Befehlszeilenschnittstelle (CLI) für die Verwaltung von Distributionen, die Installation von Modellen und die Konfiguration von Umgebungen. Hier sind die Installationsschritte, die wir durchführen müssen:
1. Erstelle und aktiviere eine virtuelle Umgebung:
conda create -n llama_stack python=3.10
conda activate llama_stack2. Klone das Llama Stack Repository:```bash
git clone <https://github.com/meta-llama/llama-stack.git>
cd llama-stack
3. Install the required dependencies:```bash
pip install -r requirements.txtDocker Container vereinfachen die Bereitstellung des Llama Stack Servers und der Agenten-API-Anbieter. Vorgefertigte Docker-Images sind für eine einfache Einrichtung verfügbar:
docker pull llamastack/llamastack-local-gpu
llama stack build
llama stack configure llamastack-local-gpuDiese Befehle ziehen das Docker-Image, bauen es und konfigurieren den Stack.
Lass uns einen einfachen Chatbot mit den Llama Stack APIs bauen. Hier sind die Schritte, die wir unternehmen müssen:
Wir werden den Server auf Port 5000 laufen lassen. Stelle sicher, dass der Server läuft, bevor du mit den APIs arbeitest:
llama stack run local-gpu --port 5000Nachdem du den Llama Stack installiert hast, kannst du Client-Code verwenden, um mit seinen APIs zu interagieren. Verwende die Inferenz-API, um Antworten auf der Grundlage von Benutzereingaben zu generieren:
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="<http://localhost:5000>")
user_input = "Hello! How are you?"
response = client.inference.chat_completion(
model="Llama3.1-8B-Instruct",
messages=[{"role": "user", "content": user_input}],
stream=False
)
print("Bot:", response.text)Hinweis: Ersetze "Llama3.1-8B-Instruct" durch den tatsächlichen Modellnamen, der in deiner Einrichtung verfügbar ist.
Implementiere die Sicherheits-API, um Antworten zu moderieren und sicherzustellen, dass sie angemessen sind:
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": response.text}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
print("Unsafe content detected.")
else:
print("Bot:", response.text)Schaffe das Kontextbewusstsein des Chatbots, indem du den Gesprächsverlauf speicherst und abrufst:
### building a memory bank that can be used to store and retrieve context.
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)Wir können die APIs weiter kombinieren, um einen robusten Chatbot zu bauen:
Hier ist der vollständige Code, nachdem du alle Schritte durchgeführt hast:
import uuid
client = LlamaStackClient(base_url="<http://localhost:5000>")
### create a memory bank at the start
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)
def get_bot_response(user_input):
### retrieving conversation history
query_response = client.memory.query_documents(
bank_id=bank.bank_id,
query=[user_input],
params={"max_chunks": 10}
)
history = [chunk.content for chunk in query_response.chunks]
### preparing messages with history
messages = [{"role": "user", "content": user_input}]
if history:
messages.insert(0, {"role": "system", "content": "\\n".join(history)})
### generate response
response = client.inference.chat_completion(
model="llama-2-7b-chat",
messages=messages,
stream=False
)
bot_response = response.text
### safety check
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": bot_response}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
return "I'm sorry, but I can't assist with that request."
### memory storing
documents = [
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=user_input,
mime_type="text/plain"
),
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=bot_response,
mime_type="text/plain"
)
]
client.memory.insert_documents(
bank_id=bank.bank_id,
documents=documents
)
return bot_response
### putting all together
while True:
user_input = input("You: ")
if user_input.lower() == "bye":
break
bot_response = get_bot_response(user_input)
print("Bot:", bot_response)Um einige Beispiele zu sehen und mit der Implementierung von Anwendungen mit Llama Stack zu beginnen, hat Meta die llama-stack-apps Repository zur Verfügung gestellt, in dem du dir einige Beispielanwendungen anschauen kannst. Mach dich unbedingt mit dem Rahmenwerk vertraut.
Als Open-Source-Projekt lebt Llama Stack von den Beiträgen der Community. Die APIs entwickeln sich schnell weiter, und das Projekt ist offen für Feedback und die Beteiligung von Entwicklern, um die Zukunft der Plattform mitzugestalten. Wenn du Llama Stack testest, kann es anderen Entwicklern helfen, wenn du dein Projekt auch als Beispiel teilst oder zur Dokumentation beiträgst.
In diesem Artikel haben wir Schritt für Schritt erklärt, wie du mit Llama Stack loslegen kannst.
Wenn du mit dem Einsatz deiner KI-Anwendungen vorankommst, behalte das Llama Stack Repository für die neuesten Updates und Erweiterungen im Auge zu behalten.
Wenn du mehr über das Ökosystem der Lamas erfahren willst, schau dir die folgenden Ressourcen an:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.