pandas is one of the most popular Python data science packages and is the standard tool for working with tabular data in Python. Luckily, a complete beginner can learn and start programming in pandas within a couple of weeks. Here’s how to get started.
What to know before getting started
What is pandas?
pandas is one of the first Python packages you should learn because it’s easy to use, open source, and will allow you to work with large quantities of data. It allows fast and efficient data manipulation, data aggregation and pivoting, flexible time series functionality, and more.
pandas has a lot of the same functionality as SQL or Excel, and can take in various data types—from CSV and text files to Microsoft Excel files, SQL databases, and more. It has the added benefit of allowing you to convert them to a DataFrame object, which simply represents columns and rows that resemble tabular data in Excel—but in Python.
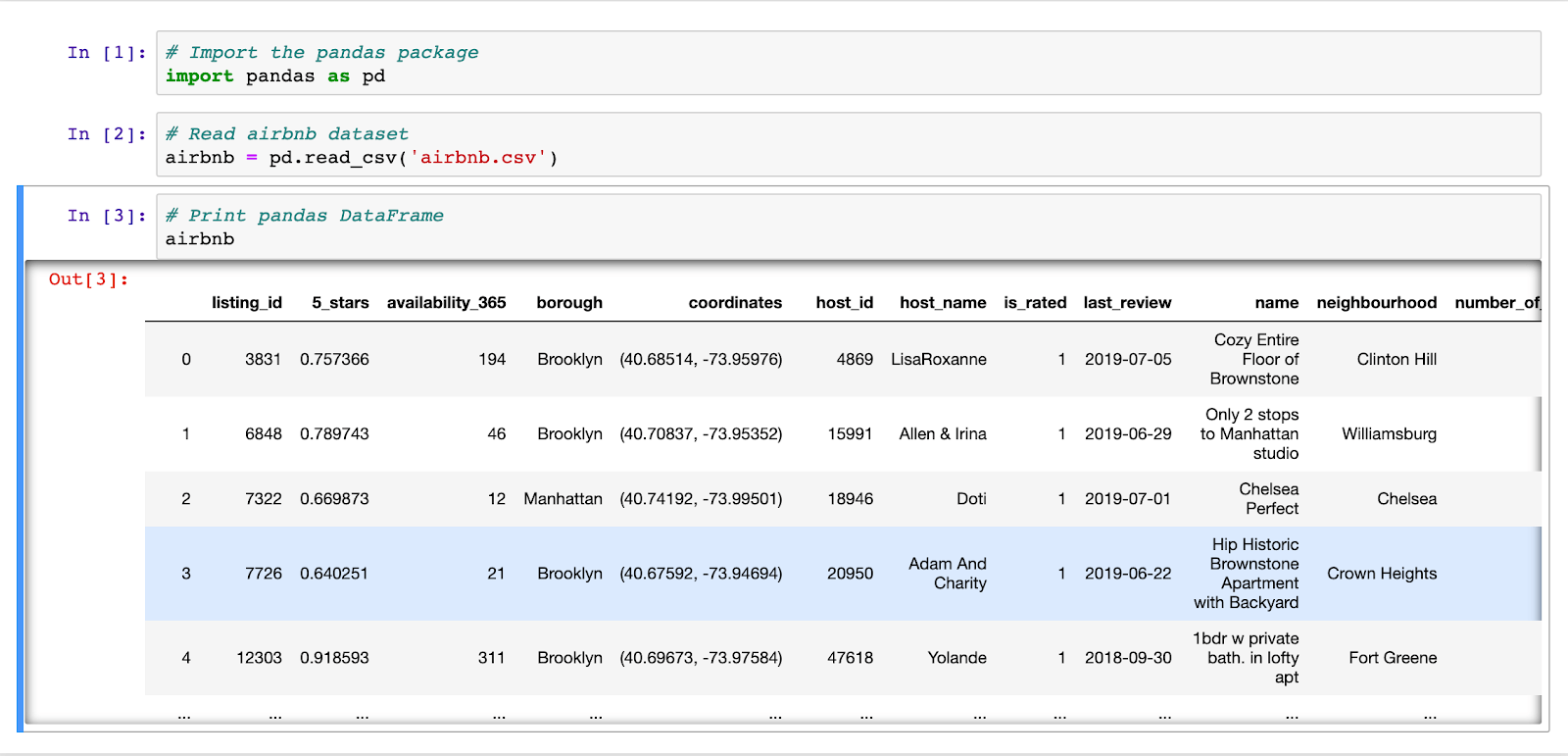
The pandas DataFrame in action
How does pandas fit in the PyData ecosystem?
When analyzing data with Python, pandas is often used in conjunction with other packages and tools. These packages range from machine learning packages for producing predictions on data like scikit-learn, data visualization packages like Matplotlib and seaborn, and tools like Jupyter Notebooks for creating and sharing reports that contain code, visualizations, and text. All of these tools comprise what is usually referred to as the PyData ecosystem. But you don’t need to worry about learning all of these tools at once—start by focusing on pandas.
Six steps for your pandas learning journey
1) Learn basic Python syntax
pandas is a package built for Python, so you need to have a firm grasp of basic Python syntax before you get started with pandas. It’s very easy to get bogged down when learning syntax, as introductory courses often make learning a chore by focusing purely on Python syntax.
As a rule of thumb, you should spend as little time as possible on syntax and learn just enough syntax to get you started with simple tasks with pandas. Here’s a list of pure Python resources to get you started with the basics:
2) Set up your Python environment
Before working with pandas, you need to have a Python environment set up on your machine. This will allow you to apply your newfound skills and experiment with pandas on your own data.
To set up your Python environment for data science, I recommend installing an Anaconda distribution to conveniently install pandas along with relevant data science packages and tools like Jupyter Notebooks.
For a primer on setting up your Python environment with an Anaconda, watch my hands-on training for a step-by-step tutorial. You can also follow beginner guides for installing Anaconda on Windows and Mac OS X.
3) Learn by doing
At DataCamp, we believe that learning by doing is the best way to learn and apply programming skills. Applying your pandas skills with guided projects will help you get out of your comfort zone, learn how to debug and read documentation, and gain confidence working with real data.
Becoming proficient in pandas requires knowing how to import and export data of different types, manipulating and reshaping data, pivoting and aggregating data, deriving simple insights from DataFrames, and more. Here’s a list of resources that cover these topics and more, containing easy-to-implement pandas code in the form of guided projects:
- The pandas website offers a ton of tutorials on getting started with the package. More importantly, it has many community tutorials to get new users started.
- Pandas Cookbook is an excellent book offering a code-rich, project-based approach to working with pandas. It also introduces other packages often used with pandas in the PyData Ecosystem, like seaborn for data visualization.
- DataCamp offers a range of pandas courses ranging from beginner to advanced. The pandas foundations course shows you how to import DataFrames, conduct basic exploratory analysis, and analyze time series—all from your browser.
4) Work on projects with real-world data
Practicing the pandas skills you’ve learned on real-world data is an excellent way to retain your skills and apply them confidently in your daily work.
There’s a variety of ways to get started on your own project. For starters, if your daily work requires you to work with tabular data, start using pandas instead of spreadsheet software like Google Sheets and Microsoft Excel. While this could take more time initially, it will help you sharpen and retain your pandas skills, making you faster and more proficient in the long run.
Kaggle contains a range of real-world datasets and machine learning competitions. While I encourage you to learn machine learning, it’s best suited for more advanced learners, so make sure to initially focus on projects focused on data analysis and exploration with pandas. You can do this by writing data analysis notebooks on Kaggle or blogging platforms like Medium.
5) Master the art of debugging
One of the most overlooked skills any aspiring programmer needs to hone is debugging. Every Python and pandas practitioner, regardless of skill level, faces errors and problems with their code. When you encounter errors in your pandas code, these resources are at your disposal:
- Google is the first place I go when faced with errors with my code. Almost always, the answer to my pandas query will be in the first ten search results.
- Stack Overflow is the largest community of developers where practitioners can seek help with debugging code by asking and answering programming questions. It currently contains around 180,000 questions on pandas. If you want to post a question yourself, make sure to follow their best practices when phrasing questions.
- Documentation will always be your friend, and the pandas documentation is extensive. It covers all the possible functionalities of pandas as well as best practices.
6) Keep expanding your pandas skills
Keep on building and expanding your pandas skills. Many resources cover advanced pandas topics. For example, Ashish Kumar’s Mastering pandas covers techniques to speed up and simplify your pandas workflow. This Real Python blog post covers tips and tricks for advanced users. You can also start learning how other packages in the PyData Ecosystem extend your pandas ability, like seaborn and plotly, for creating interactive plots.
An interactive plot made with Plotly
A great way to expand your pandas skills is by revisiting some of the pandas code you wrote at the beginning of your learning journey. Try to spot opportunities to simplify your code, adopt best practices, and leverage other packages in the PyData ecosystem.
I hope you feel inspired by this blog post and that these resources are useful to you. Mastering pandas is a lifelong learning journey—one that I am still on myself. At DataCamp, pandas is covered across our core curriculum, and we’re continually improving and adding to our content. Lastly, I invite you to join thousands of learners in the DataCamp Slack Community to get support on your pandas journey!
Adel Nehme is a Data Science Evangelist at DataCamp. He was previously a Content Developer where he collaborated with instructors on a range of Python courses and created our course Cleaning Data in Python.


