
Curso
Machine Learning para negocios
2 h
46.2K
En el mundo post-GPT, la demanda de conjuntos de datos de alta calidad nunca ha sido mayor. La IA generativa y los grandes modelos lingüísticos dependen de la disponibilidad de datos sólidos, de alta calidad y en gran cantidad. Sin embargo, la obtención de estos datos a menudo se enfrenta a dificultades, que van desde la preocupación por la privacidad hasta la escasez de datos reales en todo el mundo.
Entra en juego la generación de datos sintéticos: una potente solución que aborda la escasez de datos reales y resuelve los problemas de privacidad. En esta entrada de blog, aprenderemos qué son los datos sintéticos, por qué son esenciales, las técnicas y herramientas para generarlos y cómo puedes empezar.
Los datos sintéticos son información generada artificialmente que imita a los datos del mundo real en estructura y propiedades estadísticas, pero que no corresponde a entidades reales. Se crea algorítmicamente y se utiliza como sustituto de los datos reales en diversas aplicaciones.
Las características mencionadas hacen que los datos sintéticos tengan un valor incalculable para las pruebas de software, el entrenamiento de modelos de IA, el aumento de datos, los modelos financieros y la investigación sanitaria, donde se necesitan conjuntos de datos grandes y diversos, pero los datos reales pueden ser escasos, sensibles o estar restringidos por normativas de privacidad.
Los datos sintéticos generados a partir de simulaciones o algoritmos informáticos proporcionan una alternativa barata a los datos del mundo real y se utilizan cada vez más para crear modelos de IA precisos. Fuente de la imagen: NVIDIA blog
Los tres tipos principales de datos sintéticos son estructurados, no estructurados y secuenciales, cada uno con sus propias características y aplicaciones. Explorémoslos con más detalle.
Los datos estructurados son información organizada en un formato predefinido, que suele encontrarse en bases de datos y hojas de cálculo. Este tipo de datos sintéticos imita el formato y las propiedades estadísticas de los datos estructurados reales. Algunos ejemplos son:
Los métodos de generación de datos sintéticos estructurados suelen implicar modelado estadístico, sistemas basados en reglas o técnicas de aprendizaje automático como los autocodificadores variacionales (VAE) o las redes generativas adversariales (GAN).
Los datos no estructurados carecen de un formato predefinido y son cada vez más importantes en las aplicaciones de aprendizaje automático. Los tipos de datos sintéticos no estructurados incluyen
Los datos secuenciales implican tiempo u orden, por lo que son esenciales para los modelos que necesitan comprender las relaciones temporales. Algunos ejemplos son:
Potencia tu carrera como científico de datos profesional.

Los datos sintéticos ofrecen varias ventajas, lo que los convierte en una opción atractiva para organizaciones e investigadores. Su uso puede abordar diversos retos en la ciencia de datos, el aprendizaje automático y el desarrollo de software. He aquí algunas de las razones para utilizar datos sintéticos:
En muchos campos, recopilar suficientes datos de calidad es un obstáculo importante. Los datos sintéticos pueden colmar estas lagunas, permitiendo un análisis exhaustivo y un entrenamiento sólido de los modelos.
Al utilizar datos sintéticos que no corresponden a personas reales, las organizaciones pueden eludir las preocupaciones sobre la privacidad y el cumplimiento de normativas como el GDPR y la HIPAA.
Los datos sintéticos pueden adaptarse para incluir sucesos raros o condiciones específicas, enriqueciendo los conjuntos de datos y mejorando la precisión de los modelos.
Los datos sintéticos a menudo pueden ser más rentables que recopilar o comprar datos reales.
Existen varios métodos para generar datos sintéticos, cada uno con ventajas y casos de uso. Vamos a repasarlos en esta sección.
Se trata del método más sencillo, que consiste en generar datos mediante un muestreo aleatorio a partir de distribuciones estadísticas.
import pandas as pd
import numpy as np
# Generate 1,000 samples from a normal distribution
heights = np.random.normal(loc=170, scale=10, size=1000)
weights = np.random.normal(loc=70, scale=15, size=1000)
# Create a correlation between height and weight
weights += (heights - 170) * 0.5
df = pd.DataFrame({'Height': heights, 'Weight': weights})
# Add categorical data
genders = np.random.choice(['Male', 'Female'], size=1000)
df['Gender'] = genders
df.head()
df.describe()El código anterior genera un conjunto de datos aleatorios que simulan la altura y el peso utilizando distribuciones normales. Las estaturas se centran en torno a 170 cm con una desviación típica de 10, y los pesos se centran en torno a 70 kg con una desviación típica de 15. Se introduce una relación lineal entre la altura y el peso, de modo que los individuos más altos suelen pesar más. El código también añade una columna Gender con valores asignados aleatoriamente de "Hombre" o "Mujer".
Salida:
Este método es rápido y fácil de aplicar, por lo que resulta útil para pruebas básicas o prototipos. Sin embargo, tiene algunas limitaciones. No capta las relaciones complejas ni los patrones del mundo real, ni tiene en cuenta los matices o limitaciones específicos del dominio.
Los métodos basados en reglas utilizan reglas predefinidas o conocimientos del dominio para crear datos con características específicas. Mira el siguiente ejemplo:
import numpy as np
import pandas as pd
def generate_customer_data(num_records):
data = []
for _ in range(num_records):
age = np.random.randint(18, 80)
# Rule: Income is loosely based on age
base_income = 20000 + (age - 18) * 1000
income = np.random.normal(base_income, base_income * 0.2)
# Rule: Credit score is influenced by age and income
credit_score = min(850, max(300, int(600 + (age/80)*100 + (income/100000)*100 + np.random.normal(0, 50))))
# Rule: Loan amount is based on income and credit score
max_loan = income * (credit_score / 600)
loan_amount = np.random.uniform(0, max_loan)
data.append([age, income, credit_score, loan_amount])
return pd.DataFrame(data, columns=['Age', 'Income', 'CreditScore', 'LoanAmount'])
df = generate_customer_data(1000)
df.head()El código Python anterior genera un conjunto de datos de clientes con 1.000 registros. Para cada cliente, asigna aleatoriamente una edad entre 18 y 80 años. En función de la edad, se calcula una renta, en la que los individuos de más edad suelen tener rentas más altas. A continuación se determina la puntuación crediticia, en la que influyen la edad y los ingresos, asegurándose de que se sitúa entre 300 y 850. También se genera un importe de préstamo, que depende de los ingresos del individuo y de su puntuación crediticia.
Salida:
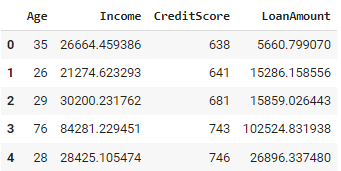
El enfoque utilizado garantiza que los datos generados se adhieren a relaciones y restricciones conocidas, lo que permite incorporar conocimientos específicos del dominio directamente al proceso de generación de datos. Sin embargo, puede resultar complejo cuando se trata de sistemas con muchas reglas interrelacionadas, y definir y mantener dichas reglas puede llevar mucho tiempo para conjuntos de datos grandes o intrincados.
La generación de datos basada en la simulación modela procesos del mundo real para crear conjuntos de datos sintéticos. Consiste en simular acontecimientos o comportamientos a partir de reglas y variables predefinidas, lo que permite estudiar cómo interactúan los distintos factores en los sistemas dinámicos.
Este método se utiliza a menudo para probar escenarios y analizar posibles resultados, proporcionando valiosos conocimientos sobre sistemas complejos como los procesos de atención al cliente, las cadenas de suministro y las operaciones sanitarias. Aquí tienes un ejemplo en Python:
import simpy
import random
import pandas as pd
class Bank(object):
def __init__(self, env, num_tellers):
self.env = env
self.teller = simpy.Resource(env, num_tellers)
def service(self, customer):
service_time = random.expovariate(1/10) # Avg service time of 10 minutes
yield self.env.timeout(service_time)
def customer(env, name, bank, data):
arrival_time = env.now
print(f'{name} arrives at the bank at {arrival_time:.2f}')
with bank.teller.request() as request:
yield request
wait_time = env.now - arrival_time
print(f'{name} waits for {wait_time:.2f}')
yield env.process(bank.service(name))
service_time = env.now - arrival_time
print(f'{name} leaves the bank at {env.now:.2f}')
# Append the customer data to the list
data.append((name, arrival_time, wait_time, service_time))
def run_simulation(env, num_customers, bank, data):
for i in range(num_customers):
env.process(customer(env, f'Customer {i}', bank, data))
yield env.timeout(random.expovariate(1/5)) # New customer every 5 minutes on average
# Set up and run the simulation
env = simpy.Environment()
bank = Bank(env, num_tellers=3)
num_customers = 100
data = [] # This will hold the customer data
env.process(run_simulation(env, num_customers, bank, data))
env.run()
# Create a DataFrame from the collected data
df = pd.DataFrame(data, columns=['Customer', 'ArrivalTime', 'WaitTime', 'ServiceTime'])
print(df.head())
print(df.describe())El código simula un banco utilizando el programa SimPy SimPy. Los clientes llegan a intervalos aleatorios, esperan a ser atendidos por uno de los tres cajeros disponibles y se marchan después de ser atendidos.
La clase Bank define el tiempo de servicio (con una media de 10 minutos), mientras que la función customer() hace un seguimiento de la llegada, el tiempo de espera y la duración del servicio de cada cliente. Los clientes se procesan en la función run_simulation(), que genera nuevas llegadas por término medio cada 5 minutos.
Salida:
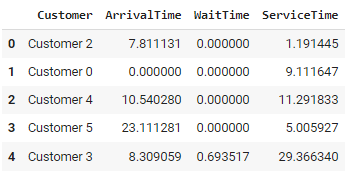
Este enfoque permite modelar sistemas complejos y dinámicos, posibilitando pruebas de escenarios y análisis "hipotéticos". Sin embargo, puede llegar a ser computacionalmente intensivo para simulaciones a gran escala y requiere un conocimiento profundo del sistema modelado para garantizar resultados precisos.
Los modelos generativos como las redes generativas adversariales (GAN) y los autocodificadores variacionales (VAE ) se han hecho populares para crear datos sintéticos de gran realismo. Estos modelos aprenden a captar la distribución subyacente de los datos de entrada y generan nuevas muestras que imitan los datos del mundo real.
Ambos métodos se utilizan ampliamente en tareas como la generación de imágenes y el procesamiento del lenguaje natural, principalmente para crear datos sintéticos para modelos de aprendizaje automático cuando los datos del mundo real son escasos o delicados.
Consulta el curso gratuito sobre Conceptos de IA Generativa en Datacamp para aprender cómo se desarrollan los modelos de IA generativa y cómo afectarán a la sociedad en el futuro.
Existen varias herramientas que facilitan la generación de datos sintéticos para diversos casos de uso, que van desde el modelado estadístico al aprendizaje automático y las simulaciones sanitarias.
Estas herramientas están diseñadas para crear datos que reflejen las características de los conjuntos de datos del mundo real, permitiendo una experimentación y unas pruebas seguras sin exponer información sensible.
SDV es una biblioteca de Python que proporciona un conjunto de modelos para generar datos sintéticos. Admite varios tipos de datos, como series temporales, datos relacionales y datos tabulares. SDV utiliza modelos probabilísticos avanzados como las cópulas gaussianas y métodos de aprendizaje profundo para aprender la estructura de los datos originales y producir versiones sintéticas de alta calidad. Se utiliza mucho en aplicaciones de aprendizaje automático para generar datos de entrenamiento sintéticos cuando los datos reales son limitados o delicados.
Para saber más sobre cómo generar datos sintéticos utilizando la biblioteca SDV en Python, consulta el repositorio oficial de GitHub o prueba sus tutoriales oficiales.
Gretel.AI es una plataforma basada en la nube que ofrece servicios de generación y anonimización de datos sintéticos. Proporciona API fáciles de usar y modelos preconstruidos que pueden generar datos sintéticos realistas basados en una variedad de entradas, incluidos datos estructurados, semiestructurados y no estructurados. Gretel.AI se centra en simplificar el flujo de trabajo para desarrolladores y científicos de datos, facilitando la generación de datos sintéticos con una configuración mínima.
Consulta el inicio rápido de Gretel para empezar a generar datos sintéticos con Gretel.AI
Synthea es una herramienta de código abierto desarrollada específicamente para simulaciones sanitarias. Genera historiales sintéticos de pacientes que reflejan historiales médicos, tratamientos y resultados realistas, siguiendo normas médicas y clínicas. Los investigadores y las instituciones sanitarias utilizan a menudo Synthea para simular poblaciones de pacientes y estudiar las tendencias de la salud pública sin utilizar datos reales de pacientes, lo que lo hace inestimable para el análisis de datos sanitarios.
synthpop es un paquete de R diseñado específicamente para generar versiones sintéticas de conjuntos de datos del mundo real. Funciona utilizando modelos estadísticos para replicar las relaciones y distribuciones encontradas en los datos originales, permitiendo a los usuarios compartir y analizar datos de forma segura sin comprometer la confidencialidad. synthpop es especialmente útil para investigadores e instituciones que necesitan publicar conjuntos de datos protegiendo la privacidad.
Para saber más sobre cómo generar datos sintéticos en R utilizando synthpop, consulta el tutorial Generar conjuntos de datos sintéticos con synthpop en R.
Como ya se ha dicho, la IA generativa desempeña un papel importante en la creación de datos sintéticos, principalmente mediante modelos avanzados que aprenden los patrones y distribuciones subyacentes de los datos del mundo real y generan versiones sintéticas realistas. Exploremos cada una de estas técnicas y sus aplicaciones.
Los GAN son una de las herramientas más potentes para generar datos sintéticos. Constan de dos redes neuronales que compiten entre sí: una generadora y otra discriminadora. El generador crea datos sintéticos, mientras que el discriminador intenta diferenciar entre datos reales y sintéticos. Mediante este proceso contradictorio, el generador mejora su capacidad de crear datos muy realistas. Las GAN se utilizan ampliamente para generar imágenes, vídeos e incluso datos tabulares, y han encontrado aplicaciones en campos como la sanidad, la conducción autónoma y el entretenimiento.
Los VAE son otro modelo generativo popular para la generación de datos sintéticos. Funcionan codificando los datos en un espacio latente comprimido y descodificándolos después a su forma original. Esto permite a las VAE generar nuevos puntos de datos mediante el muestreo del espacio latente, lo que las hace útiles para aplicaciones como la síntesis de imágenes y la detección de anomalías. Aunque las VAE no alcanzan el mismo nivel de realismo que las GAN, son más estables durante el entrenamiento y proporcionan un mejor control sobre la estructura de los datos generados.
Los transformadores, como los modelos GPT, han revolucionado la generación de textos al producir frases y párrafos coherentes y contextualmente precisos. Para los datos sintéticos, los transformadores pueden generar texto de apariencia humana que refleje conjuntos de datos del mundo real, como reseñas de clientes, conversaciones u otros datos textuales. Estos modelos son especialmente útiles a la hora de generar grandes volúmenes de datos sintéticos basados en texto para tareas de procesamiento del lenguaje natural (PLN), pero también tienen la flexibilidad de poder ajustarse con precisión para aplicaciones específicas.
Para conocer el papel que la inteligencia artificial generativa desempeña hoy y desempeñará en el futuro en un entorno empresarial, consulta el curso IA Generativa para la Empresa.
La técnica adecuada de generación de datos sintéticos depende de tu caso de uso, tipo de datos y objetivos. Para conjuntos de datos sencillos con distribuciones estadísticas bien definidas, puede bastar con la generación aleatoria de datos o la generación basada en reglas.
Si tratas con datos complejos e interrelacionados o necesitas preservar la integridad relacional (por ejemplo, en sanidad o finanzas), un enfoque basado en la simulación o modelos generativos como los GAN y los VAE podrían ser más apropiados. Los modelos basados en transformadores pueden proporcionar mejores resultados para la generación de textos o tareas que impliquen datos a gran escala.
A la hora de elegir una técnica, ten en cuenta las compensaciones entre la facilidad de aplicación, el realismo de los datos y los requisitos computacionales.
Para demostrar este ejemplo, he generado una base de datos de pacientes simulada de tres tablas, cada una con exactamente 5.000 registros.
Tabla 1 - Pacientes
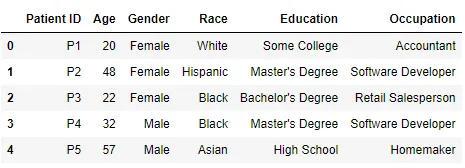
Tabla 2 - Resultados de laboratorio
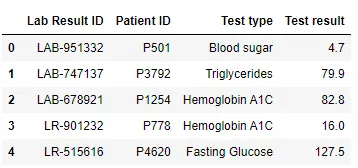
Tabla 3 - Tratamientos
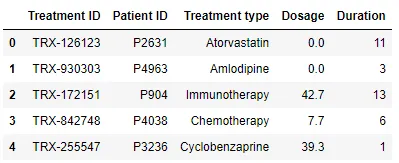
Para poner en práctica este ejemplo, tendrás que registrarte en Gretel.AI y generar una clave API. También tendrás que instalar una biblioteca en Python:
!pip install -U gretel-trainerPara poner en práctica este caso de uso, utilizaremos RelationalData del módulo gretel_trainer.relational. Permite a los usuarios definir y mantener automáticamente relaciones entre varias tablas, garantizando que las dependencias de claves foráneas y la integridad de los datos se conservan en la salida sintética.
Esto es especialmente útil para generar datos sintéticos de alta calidad que reflejen la estructura y las dependencias de las bases de datos del mundo real, facilitando su uso en aplicaciones como el aprendizaje automático, la investigación o el cumplimiento de la normativa sobre privacidad de datos.
Ejemplo de código:
import pandas as pd
from gretel_client import configure_session
from gretel_trainer.relational import RelationalData
configure_session(api_key="your_api_key", cache="yes", validate=True)
csv_dir = "csv/"
tables = [("patients", "Patient ID"), ("lab_results", "Lab Result ID"), ("treatments", "Treatment ID")]
foreign_keys = [("lab_results.Patient ID", "patients.Patient ID"), ("treatments.Patient ID", "patients.Patient ID")]
relational_data = RelationalData()
for table, pk in tables:
relational_data.add_table(name=table, primary_key=pk, data=pd.read_csv(f"{csv_dir}/{table}.csv"))
for fk, ref in foreign_keys:
relational_data.add_foreign_key(foreign_key=fk, referencing=ref)
from gretel_trainer.relational import MultiTable
multitable = MultiTable(
relational_data,
project_display_name="Clinical Trials",
gretel_model="amplify"
)
multitable.train()
multitable.generate(record_size_ratio=1)
synthetic_patients = multitable.synthetic_output_tables['patients']
synthetic_lab_results = multitable.synthetic_output_tables['lab_results']
synthetic_treatments = multitable.synthetic_output_tables['treatments']
Este código utiliza la API de Gretel.AI para generar datos sintéticos para una base de datos relacional. Primero crea una sesión utilizando una clave API y carga tres archivos CSV (patients, lab_results, y treatments), especificando sus claves primarias y definiendo las relaciones de clave foránea.
La clase RelationalData se utiliza para mantener estas relaciones. Tras configurar los datos, se entrena un modelo utilizando la clase MultiTable, que sintetiza todo el conjunto de datos relacionales.
Una vez entrenado el modelo, se utiliza el método generate() para generar datos sintéticos. El parámetro record_size_ratio determina la relación de referencia al tamaño de los datos generados. record_size_ratio=1 significa que el número de registros del conjunto de datos sintético = el conjunto de datos original, es decir, 5.000 registros.
Evaluar la calidad de los datos sintéticos es esencial para garantizar su utilidad y privacidad. Empieza comparando las distribuciones estadísticas entre los datos originales y los sintéticos: métricas como la media, la varianza y la correlación deberían coincidir.
Otro método consiste en utilizar datos sintéticos para entrenar modelos de aprendizaje automático y comparar su rendimiento (por ejemplo, la precisión o la puntuación F1) con los modelos entrenados con datos reales.
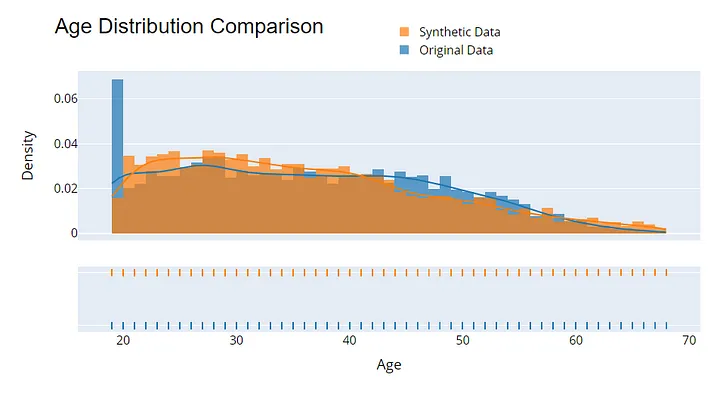
Ejemplo de visualización para evaluar la calidad de los datos sintéticos. Imagen del autor.
La generación de datos sintéticos ha surgido para hacer frente a los retos relacionados con la escasez de datos, los problemas de privacidad y la necesidad de conjuntos de datos diversos y de alta calidad.
Con técnicas que van desde la simple generación de datos aleatorios a modelos generativos avanzados como los GAN y los VAE, los datos sintéticos permiten a las organizaciones innovar y construir mejores modelos de aprendizaje automático, salvaguardando al mismo tiempo la información sensible.
Herramientas como SDV y servicios gestionados como Gretel.AI hacen más accesible la generación de datos sintéticos, incluso para bases de datos relacionales complejas.
A medida que evolucione la generación de datos sintéticos, sus aplicaciones serán cada vez más importantes en el avance de la IA, la sanidad, las finanzas y otros innumerables campos.
¿Quieres profundizar más? Mira la formación Uso de datos sintéticos para el aprendizaje automático y la IA en Python para descubrir qué son los datos sintéticos, cómo protegen la privacidad y cómo se utilizan para acelerar la adopción de la IA en la banca, la sanidad y muchos otros sectores.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.
¡Aprende más sobre el aprendizaje automático y la IA con los siguientes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Abid Ali Awan
10 min
Tutorial
Duong Vu
Tutorial
Moez Ali
Tutorial
Abid Ali Awan


