
Kurs
Maschinelles Lernen für Unternehmen
2 Std.
46.2K
In der Welt nach dem GPT war die Nachfrage nach hochwertigen Datensätzen noch nie so groß wie heute. Generative KI und große Sprachmodelle hängen alle von der Verfügbarkeit robuster, qualitativ hochwertiger und quantitativer Daten ab. Die Beschaffung solcher Daten ist jedoch oft mit Herausforderungen verbunden, die von Bedenken hinsichtlich des Datenschutzes bis hin zu der schieren Knappheit an tatsächlichen Daten weltweit reichen.
Hier kommt die Generierung synthetischer Daten ins Spiel: eine leistungsstarke Lösung, die den Mangel an realen Daten behebt und Datenschutzbedenken ausräumt. In diesem Blogbeitrag erfährst du, was synthetische Daten sind, warum sie so wichtig sind, welche Techniken und Tools es gibt, um sie zu erzeugen, und wie du damit anfangen kannst.
Synthetische Daten sind künstlich erzeugte Informationen, die reale Daten in ihrer Struktur und ihren statistischen Eigenschaften nachahmen, aber nicht den tatsächlichen Entitäten entsprechen. Sie werden algorithmisch erstellt und in verschiedenen Anwendungen als Ersatz für echte Daten verwendet.
Diese Eigenschaften machen synthetische Daten zu einem unschätzbaren Wert für Softwaretests, das Training von KI-Modellen, die Datenerweiterung, die Finanzmodellierung und die Forschung im Gesundheitswesen, wo große, vielfältige Datensätze benötigt werden, reale Daten aber möglicherweise knapp, sensibel oder durch Datenschutzbestimmungen eingeschränkt sind.
Synthetische Daten, die aus Computersimulationen oder Algorithmen generiert werden, sind eine kostengünstige Alternative zu realen Daten und werden zunehmend zur Erstellung genauer KI-Modelle verwendet. Bildquelle: NVIDIA blog
Die drei Haupttypen von synthetischen Daten sind strukturierte, unstrukturierte und sequentielle Daten, die jeweils ihre eigenen Merkmale und Anwendungen haben. Schauen wir sie uns genauer an.
Strukturierte Daten sind Informationen, die in einem vordefinierten Format organisiert sind und normalerweise in Datenbanken und Tabellenkalkulationen zu finden sind. Diese Art von synthetischen Daten ahmt das Format und die statistischen Eigenschaften von echten strukturierten Daten nach. Beispiele dafür sind:
Generierungsmethoden für strukturierte synthetische Daten basieren oft auf statistischer Modellierung, regelbasierten Systemen oder maschinellen Lerntechniken wie Variational Autoencoders (VAEs) oder Generative Adversarial Networks (GANs).
Unstrukturierte Daten haben kein vordefiniertes Format und werden bei Anwendungen für maschinelles Lernen immer wichtiger. Zu den Arten von synthetischen unstrukturierten Daten gehören:
Sequentielle Daten haben etwas mit Zeit oder Ordnung zu tun und sind daher wichtig für Modelle, die zeitliche Beziehungen verstehen müssen. Beispiele dafür sind:
Bringe deine Karriere als professioneller Datenwissenschaftler voran.

Synthetische Daten bieten mehrere Vorteile, die sie zu einer attraktiven Option für Organisationen und Forscher machen. Damit können verschiedene Herausforderungen in den Bereichen Data Science, maschinelles Lernen und Softwareentwicklung bewältigt werden. Hier sind einige Gründe für die Verwendung synthetischer Daten:
In vielen Bereichen ist es eine große Hürde, genügend hochwertige Daten zu sammeln. Synthetische Daten können diese Lücken füllen und ermöglichen eine umfassende Analyse und ein robustes Modelltraining.
Durch die Verwendung synthetischer Daten, die nicht mit tatsächlichen Personen übereinstimmen, können Unternehmen Datenschutzbedenken und die Einhaltung von Vorschriften wie GDPR und HIPAA umgehen.
Synthetische Daten können so angepasst werden, dass sie seltene Ereignisse oder bestimmte Bedingungen enthalten, die Datensätze bereichern und die Modellgenauigkeit verbessern.
Synthetische Daten können oft kostengünstiger sein als das Sammeln oder Kaufen echter Daten.
Es gibt verschiedene Methoden zur Erzeugung synthetischer Daten, die alle ihre Vorteile und Anwendungsfälle haben. In diesem Abschnitt gehen wir sie durch.
Dies ist die einfachste Methode, bei der Daten durch Zufallsstichproben aus statistischen Verteilungen erzeugt werden.
import pandas as pd
import numpy as np
# Generate 1,000 samples from a normal distribution
heights = np.random.normal(loc=170, scale=10, size=1000)
weights = np.random.normal(loc=70, scale=15, size=1000)
# Create a correlation between height and weight
weights += (heights - 170) * 0.5
df = pd.DataFrame({'Height': heights, 'Weight': weights})
# Add categorical data
genders = np.random.choice(['Male', 'Female'], size=1000)
df['Gender'] = genders
df.head()
df.describe()Der obige Code erzeugt einen Zufallsdatensatz, der Größe und Gewicht anhand von Normalverteilungen simuliert. Die Körpergröße liegt in der Mitte bei 170 cm mit einer Standardabweichung von 10 und das Gewicht liegt in der Mitte bei 70 kg mit einer Standardabweichung von 15. Es gibt eine lineare Beziehung zwischen Körpergröße und Gewicht, d.h. größere Menschen wiegen in der Regel mehr. Der Code fügt außerdem eine Spalte Gender mit den zufällig zugewiesenen Werten "männlich" oder "weiblich" hinzu.
Ausgabe:
Diese Methode ist schnell und einfach zu implementieren und eignet sich daher gut für einfache Tests oder Prototypen. Sie hat jedoch einige Einschränkungen. Sie erfasst keine komplexen Beziehungen oder Muster aus der realen Welt und berücksichtigt auch keine spezifischen fachlichen Nuancen oder Beschränkungen.
Regelbasierte Methoden verwenden vordefinierte Regeln oder Fachwissen, um Daten mit bestimmten Eigenschaften zu erstellen. Sieh dir das folgende Beispiel an:
import numpy as np
import pandas as pd
def generate_customer_data(num_records):
data = []
for _ in range(num_records):
age = np.random.randint(18, 80)
# Rule: Income is loosely based on age
base_income = 20000 + (age - 18) * 1000
income = np.random.normal(base_income, base_income * 0.2)
# Rule: Credit score is influenced by age and income
credit_score = min(850, max(300, int(600 + (age/80)*100 + (income/100000)*100 + np.random.normal(0, 50))))
# Rule: Loan amount is based on income and credit score
max_loan = income * (credit_score / 600)
loan_amount = np.random.uniform(0, max_loan)
data.append([age, income, credit_score, loan_amount])
return pd.DataFrame(data, columns=['Age', 'Income', 'CreditScore', 'LoanAmount'])
df = generate_customer_data(1000)
df.head()Der obige Python-Code erzeugt einen Datensatz von Kundendaten mit 1.000 Datensätzen. Jedem Kunden wird nach dem Zufallsprinzip ein Alter zwischen 18 und 80 Jahren zugewiesen. Auf der Grundlage des Alters wird ein Einkommen berechnet, wobei ältere Personen in der Regel ein höheres Einkommen haben. Dann wird die Kreditwürdigkeit ermittelt, die von Alter und Einkommen abhängt, so dass sie zwischen 300 und 850 liegt. Außerdem wird ein Kreditbetrag festgelegt, der vom Einkommen und der Kreditwürdigkeit der Person abhängt.
Ausgabe:
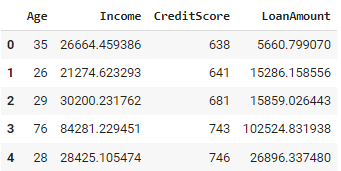
Der verwendete Ansatz stellt sicher, dass die generierten Daten bekannte Beziehungen und Einschränkungen einhalten, wodurch es möglich ist, domänenspezifisches Wissen direkt in den Datengenerierungsprozess einfließen zu lassen. Bei Systemen mit vielen miteinander verknüpften Regeln kann es jedoch komplex werden, und die Definition und Pflege solcher Regeln kann bei großen oder komplizierten Datensätzen zeitaufwändig sein.
Die simulationsbasierte Datengenerierung modelliert reale Prozesse, um synthetische Datensätze zu erstellen. Dabei werden Ereignisse oder Verhaltensweisen auf der Grundlage von vordefinierten Regeln und Variablen simuliert, um zu untersuchen, wie verschiedene Faktoren in dynamischen Systemen zusammenwirken.
Diese Methode wird häufig eingesetzt, um Szenarien zu testen und mögliche Ergebnisse zu analysieren. Sie liefert wertvolle Einblicke in komplexe Systeme wie Kundenserviceprozesse, Lieferketten und Abläufe im Gesundheitswesen. Hier ist ein Beispiel in Python:
import simpy
import random
import pandas as pd
class Bank(object):
def __init__(self, env, num_tellers):
self.env = env
self.teller = simpy.Resource(env, num_tellers)
def service(self, customer):
service_time = random.expovariate(1/10) # Avg service time of 10 minutes
yield self.env.timeout(service_time)
def customer(env, name, bank, data):
arrival_time = env.now
print(f'{name} arrives at the bank at {arrival_time:.2f}')
with bank.teller.request() as request:
yield request
wait_time = env.now - arrival_time
print(f'{name} waits for {wait_time:.2f}')
yield env.process(bank.service(name))
service_time = env.now - arrival_time
print(f'{name} leaves the bank at {env.now:.2f}')
# Append the customer data to the list
data.append((name, arrival_time, wait_time, service_time))
def run_simulation(env, num_customers, bank, data):
for i in range(num_customers):
env.process(customer(env, f'Customer {i}', bank, data))
yield env.timeout(random.expovariate(1/5)) # New customer every 5 minutes on average
# Set up and run the simulation
env = simpy.Environment()
bank = Bank(env, num_tellers=3)
num_customers = 100
data = [] # This will hold the customer data
env.process(run_simulation(env, num_customers, bank, data))
env.run()
# Create a DataFrame from the collected data
df = pd.DataFrame(data, columns=['Customer', 'ArrivalTime', 'WaitTime', 'ServiceTime'])
print(df.head())
print(df.describe())Der Code simuliert eine Bank, indem er die SimPy Bibliothek. Die Kunden kommen in zufälligen Abständen, warten auf die Bedienung durch einen der drei verfügbaren Kassierer und gehen wieder, nachdem sie bedient wurden.
Die Klasse Bank legt die Servicezeit fest (im Durchschnitt 10 Minuten), während die Funktion customer() die Ankunft jedes Kunden, die Wartezeit und die Servicedauer verfolgt. Die Kunden werden in der Funktion run_simulation() bearbeitet, die im Durchschnitt alle 5 Minuten neue Eingänge generiert.
Ausgabe:
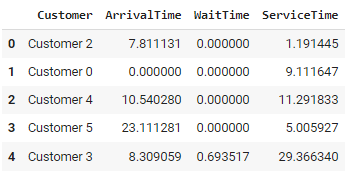
Dieser Ansatz erlaubt die Modellierung komplexer und dynamischer Systeme und ermöglicht Szenario-Tests und "Was-wäre-wenn"-Analysen. Allerdings kann sie bei umfangreichen Simulationen rechenintensiv werden und erfordert ein gründliches Verständnis des modellierten Systems, um genaue Ergebnisse zu erzielen.
Generative Modelle wie generative adversarial networks (GANs ) und variational autoencoders (VAEs) sind beliebt, um sehr realistische synthetische Daten zu erzeugen. Diese Modelle lernen, die zugrundeliegende Verteilung der Eingabedaten zu erfassen und generieren neue Stichproben, die die realen Daten nachahmen.
Beide Methoden werden häufig bei Aufgaben wie der Bilderzeugung und der Verarbeitung natürlicher Sprache eingesetzt, vor allem um synthetische Daten für maschinelle Lernmodelle zu erstellen, wenn reale Daten knapp oder sensibel sind.
Schau dir den kostenlosen Kurs über generative KI-Konzepte auf Datacamp an, um zu erfahren, wie generative KI-Modelle entwickelt werden und wie sie die Gesellschaft in Zukunft beeinflussen werden.
Es gibt verschiedene Tools, die die Erzeugung synthetischer Daten für verschiedene Anwendungsfälle erleichtern, von der statistischen Modellierung über maschinelles Lernen bis hin zu Simulationen im Gesundheitswesen.
Diese Tools sind so konzipiert, dass sie Daten erzeugen, die die Eigenschaften realer Datensätze widerspiegeln und ein sicheres Experimentieren und Testen ermöglichen, ohne sensible Informationen preiszugeben.
SDV ist eine Python-Bibliothek, die eine Reihe von Modellen zur Erzeugung synthetischer Daten bereitstellt. Es unterstützt verschiedene Datentypen, darunter Zeitreihen, relationale Daten und tabellarische Daten. SDV nutzt fortschrittliche probabilistische Modelle wie Gaußsche Copulas und Deep Learning-Methoden, um die Struktur der Originaldaten zu lernen und qualitativ hochwertige synthetische Versionen zu erstellen. Sie wird häufig bei Anwendungen des maschinellen Lernens eingesetzt, um synthetische Trainingsdaten zu erzeugen, wenn die realen Daten begrenzt oder sensibel sind.
Wenn du mehr über die Erzeugung synthetischer Daten mit der SDV-Bibliothek in Python erfahren möchtest, schau im offiziellen GitHub-Repository nach oder probiere die offiziellen Tutorials aus.
Gretel.AI ist eine cloudbasierte Plattform, die synthetische Daten erzeugt und anonymisiert. Es bietet benutzerfreundliche APIs und vorgefertigte Modelle, die realistische synthetische Daten auf der Grundlage einer Vielzahl von Eingaben, einschließlich strukturierter, halbstrukturierter und unstrukturierter Daten, erzeugen können. Gretel.AI konzentriert sich auf die Vereinfachung der Arbeitsabläufe für Entwickler und Datenwissenschaftler und macht es einfacher, synthetische Daten mit minimaler Einrichtung zu erzeugen.
Schau dir Gretels Schnellstart an, um mit der Generierung synthetischer Daten mit Gretel.AI zu beginnen.
Synthea ist ein Open-Source-Tool, das speziell für Simulationen im Gesundheitswesen entwickelt wurde. Es erstellt synthetische Patientenakten, die realistische Krankengeschichten, Behandlungen und Ergebnisse widerspiegeln und medizinischen und klinischen Standards folgen. Forscher und Einrichtungen des Gesundheitswesens nutzen Synthea häufig, um Patientenpopulationen zu simulieren und Trends im Gesundheitswesen zu untersuchen, ohne echte Patientendaten zu verwenden.
synthpop ist ein R-Paket, das speziell dafür entwickelt wurde, synthetische Versionen von realen Datensätzen zu erzeugen. Es nutzt statistische Modelle, um die Beziehungen und Verteilungen in den Originaldaten nachzubilden. So können Nutzerinnen und Nutzer Daten sicher weitergeben und analysieren, ohne die Vertraulichkeit zu gefährden. synthpop ist besonders nützlich für Forscherinnen und Forscher und Institutionen, die Datensätze freigeben und gleichzeitig die Privatsphäre schützen müssen.
Wenn du mehr darüber erfahren möchtest, wie du mit synthpop synthetische Daten in R generierst, schau dir das Tutorial Synthetische Datensätze mit synthpop in R generieren an.
Wie bereits erwähnt, spielt die generative KI eine wichtige Rolle bei der Erstellung synthetischer Daten, vor allem durch fortschrittliche Modelle, die die den realen Daten zugrunde liegenden Muster und Verteilungen lernen und realistische synthetische Versionen erzeugen. Lasst uns jede dieser Techniken und ihre Anwendungen untersuchen.
GANs sind eines der leistungsfähigsten Werkzeuge zur Erzeugung synthetischer Daten. Sie bestehen aus zwei konkurrierenden neuronalen Netzen: einem Generator und einem Diskriminator. Der Generator erzeugt synthetische Daten, während der Diskriminator versucht, zwischen echten und synthetischen Daten zu unterscheiden. Durch diesen kontradiktorischen Prozess verbessert der Generator seine Fähigkeit, sehr realistische Daten zu erzeugen. GANs werden häufig eingesetzt, um Bilder, Videos und sogar Tabellendaten zu generieren, und sie haben Anwendungen in Bereichen wie dem Gesundheitswesen, dem autonomen Fahren und der Unterhaltung gefunden.
VAEs sind ein weiteres beliebtes generatives Modell für die Erzeugung synthetischer Daten. Sie funktionieren, indem sie Daten in einen komprimierten latenten Raum kodieren und dann wieder in ihre ursprüngliche Form dekodieren. Dadurch können VAEs neue Datenpunkte durch Sampling aus dem latenten Raum erzeugen, was sie für Anwendungen wie Bildsynthese und Anomalieerkennung nützlich macht. VAEs erreichen zwar nicht den gleichen Grad an Realismus wie GANs, sind aber beim Training stabiler und bieten eine bessere Kontrolle über die Struktur der erzeugten Daten.
Transformatoren, wie die GPT-Modelle, haben die Texterstellung revolutioniert, indem sie kohärente und kontextuell korrekte Sätze und Absätze produzieren. Für synthetische Daten können Transformatoren menschenähnlichen Text generieren, der reale Datensätze widerspiegelt, wie z. B. Kundenrezensionen, Gespräche oder andere Textdaten. Diese Modelle sind besonders nützlich, wenn es darum geht, große Mengen textbasierter synthetischer Daten für die Verarbeitung natürlicher Sprache (NLP) zu erzeugen, aber sie lassen sich auch flexibel auf bestimmte Anwendungen abstimmen.
Wenn du wissen willst, welche Rolle generative künstliche Intelligenz heute und in Zukunft in der Geschäftswelt spielt, dann besuche den Kurs "Generative AI for Business".
Welche Technik zur Erzeugung synthetischer Daten geeignet ist, hängt von deinem Anwendungsfall, dem Datentyp und deinen Zielen ab. Für einfache Datensätze mit wohldefinierten statistischen Verteilungen kann eine zufällige Datengenerierung oder eine regelbasierte Generierung ausreichend sein.
Wenn du mit komplexen, zusammenhängenden Daten zu tun hast oder die relationale Integrität bewahren musst (z. B. im Gesundheits- oder Finanzwesen), sind ein simulationsbasierter Ansatz oder generative Modelle wie GANs und VAEs vielleicht besser geeignet. Transformatorbasierte Modelle können bessere Ergebnisse bei der Texterstellung oder bei Aufgaben mit großen Datenmengen liefern.
Berücksichtige bei der Auswahl einer Technik den Kompromiss zwischen einfacher Implementierung, Datenrealismus und Rechenaufwand.
Um dieses Beispiel zu demonstrieren, habe ich eine Patientendatenbank mit drei Tabellen erstellt, die jeweils genau 5.000 Datensätze enthalten.
Tabelle 1 - Patienten
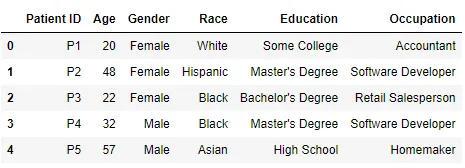
Tabelle 2 - Laborergebnisse
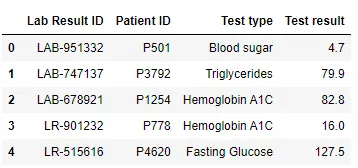
Tabelle 3 - Behandlungen
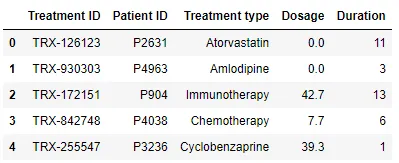
Um dieses Beispiel umzusetzen, musst du dich bei Gretel.AI anmelden und einen API-Schlüssel generieren. Außerdem musst du eine Bibliothek in Python installieren:
!pip install -U gretel-trainerUm diesen Anwendungsfall umzusetzen, verwenden wir RelationalData aus dem Modul gretel_trainer.relational. Sie ermöglicht es den Nutzern, automatisch Beziehungen zwischen mehreren Tabellen zu definieren und zu pflegen, um sicherzustellen, dass Fremdschlüsselabhängigkeiten und Datenintegrität in der synthetischen Ausgabe erhalten bleiben.
Dies ist besonders nützlich, um qualitativ hochwertige synthetische Daten zu erzeugen, die die Struktur und die Abhängigkeiten realer Datenbanken widerspiegeln und so leichter für Anwendungen wie maschinelles Lernen, Forschung oder die Einhaltung von Datenschutzbestimmungen verwendet werden können.
Code-Beispiel:
import pandas as pd
from gretel_client import configure_session
from gretel_trainer.relational import RelationalData
configure_session(api_key="your_api_key", cache="yes", validate=True)
csv_dir = "csv/"
tables = [("patients", "Patient ID"), ("lab_results", "Lab Result ID"), ("treatments", "Treatment ID")]
foreign_keys = [("lab_results.Patient ID", "patients.Patient ID"), ("treatments.Patient ID", "patients.Patient ID")]
relational_data = RelationalData()
for table, pk in tables:
relational_data.add_table(name=table, primary_key=pk, data=pd.read_csv(f"{csv_dir}/{table}.csv"))
for fk, ref in foreign_keys:
relational_data.add_foreign_key(foreign_key=fk, referencing=ref)
from gretel_trainer.relational import MultiTable
multitable = MultiTable(
relational_data,
project_display_name="Clinical Trials",
gretel_model="amplify"
)
multitable.train()
multitable.generate(record_size_ratio=1)
synthetic_patients = multitable.synthetic_output_tables['patients']
synthetic_lab_results = multitable.synthetic_output_tables['lab_results']
synthetic_treatments = multitable.synthetic_output_tables['treatments']
Dieser Code verwendet die Gretel.AI API, um synthetische Daten für eine relationale Datenbank zu erzeugen. Zuerst wird eine Sitzung mit einem API-Schlüssel eingerichtet und drei CSV-Dateien (patients, lab_results und treatments) geladen, deren Primärschlüssel angegeben und Fremdschlüsselbeziehungen definiert werden.
Die Klasse RelationalData wird verwendet, um diese Beziehungen zu pflegen. Nach der Konfiguration der Daten wird ein Modell mit der Klasse MultiTable trainiert, das den gesamten relationalen Datensatz zusammenfasst.
Nachdem das Modell trainiert wurde, wird die Methode generate() verwendet, um synthetische Daten zu erzeugen. Der Parameter record_size_ratio bestimmt das Verhältnis zur Größe der erzeugten Daten. record_size_ratio=1 bedeutet, dass die Anzahl der Datensätze im synthetischen Datensatz = der ursprüngliche Datensatz ist, d.h. 5.000 Datensätze.
Die Bewertung der Qualität synthetischer Daten ist wichtig, um ihren Nutzen und ihre Privatsphäre zu gewährleisten. Beginne mit dem Vergleich der statistischen Verteilungen zwischen den ursprünglichen und den synthetischen Daten - Kenngrößen wie Mittelwert, Varianz und Korrelation sollten weitgehend übereinstimmen.
Eine andere Methode besteht darin, synthetische Daten zu verwenden, um Modelle für maschinelles Lernen zu trainieren und ihre Leistung (z. B. Genauigkeit oder F1-Score) mit Modellen zu vergleichen, die mit echten Daten trainiert wurden.
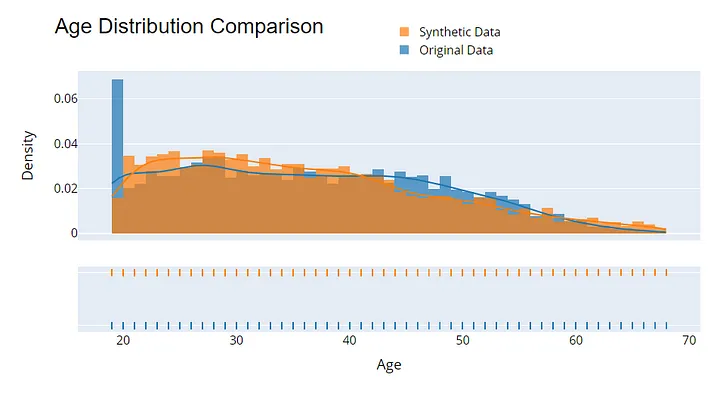
Beispielvisualisierung zur Bewertung der Qualität von synthetischen Daten. Bild vom Autor.
Die Generierung synthetischer Daten ist entstanden, um Herausforderungen wie Datenknappheit, Datenschutzbedenken und den Bedarf an vielfältigen, hochwertigen Datensätzen zu bewältigen.
Mit Techniken, die von der einfachen Generierung von Zufallsdaten bis hin zu fortschrittlichen generativen Modellen wie GANs und VAEs reichen, ermöglichen synthetische Daten den Unternehmen, innovativ zu sein und bessere maschinelle Lernmodelle zu entwickeln, während gleichzeitig sensible Informationen geschützt werden.
Tools wie SDV und Managed Services wie Gretel.AI machen die Generierung synthetischer Daten zugänglicher, selbst für komplexe relationale Datenbanken.
Mit der Weiterentwicklung der synthetischen Datengenerierung werden ihre Anwendungen in den Bereichen KI, Gesundheitswesen, Finanzen und unzähligen anderen Bereichen immer wichtiger.
Willst du tiefer eintauchen? In der Schulung Synthetische Daten für maschinelles Lernen und KI in Python verwenden erfährst du, was synthetische Daten sind, wie sie die Privatsphäre schützen und wie sie eingesetzt werden, um die Einführung von KI im Bankwesen, im Gesundheitswesen und in vielen anderen Branchen zu beschleunigen.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.
Lerne in den folgenden Kursen mehr über maschinelles Lernen und KI!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
