
Cours
Machine Learning pour le business
2 h
46.2K
Dans le monde de l'après-TGP, la demande d'ensembles de données de haute qualité n'a jamais été aussi forte. L'IA générative et les grands modèles de langage dépendent tous de la disponibilité de données robustes, de haute qualité et en grande quantité. Toutefois, l'obtention de ces données se heurte souvent à des difficultés, qui vont des préoccupations liées à la protection de la vie privée à la rareté des données réelles dans le monde.
La génération de données synthétiques est une solution puissante qui permet de pallier la rareté des données réelles et de répondre aux préoccupations en matière de protection de la vie privée. Dans cet article de blog, nous verrons ce que sont les données synthétiques, pourquoi elles sont essentielles, quelles sont les techniques et les outils pour les générer et comment vous pouvez commencer.
Les données synthétiques sont des informations générées artificiellement qui imitent les données du monde réel en termes de structure et de propriétés statistiques, mais qui ne correspondent pas à des entités réelles. Il est créé de manière algorithmique et est utilisé comme substitut aux données réelles dans diverses applications.
Les caractéristiques mentionnées rendent les données synthétiques inestimables pour les tests de logiciels, l'apprentissage de modèles d'IA, l'augmentation des données, la modélisation financière et la recherche dans le domaine de la santé, où des ensembles de données importants et diversifiés sont nécessaires, mais où les données réelles peuvent être rares, sensibles ou restreintes par des réglementations en matière de confidentialité.
Les données synthétiques générées à partir de simulations informatiques ou d'algorithmes constituent une alternative peu coûteuse aux données réelles et sont de plus en plus utilisées pour créer des modèles d'IA précis. Source de l'image : NVIDIA blog
Les trois principaux types de données synthétiques sont les données structurées, non structurées et séquentielles, chacune ayant ses propres caractéristiques et applications. Examinons-les plus en détail.
Les données structurées sont des informations organisées dans un format prédéfini, que l'on trouve généralement dans les bases de données et les feuilles de calcul. Ce type de données synthétiques reproduit le format et les propriétés statistiques des données structurées réelles. En voici quelques exemples :
Les méthodes de génération de données synthétiques structurées font souvent appel à la modélisation statistique, à des systèmes basés sur des règles ou à des techniques d'apprentissage automatique telles que les autoencodeurs variationnels (VAE) ou les réseaux adversaires génératifs (GAN).
Les données non structurées n'ont pas de format prédéfini et sont de plus en plus importantes dans les applications d'apprentissage automatique. Les types de données synthétiques non structurées sont les suivants
Les données séquentielles impliquent le temps ou l'ordre, ce qui les rend essentielles pour les modèles qui doivent comprendre les relations temporelles. En voici quelques exemples :
Boostez votre carrière en tant que data scientist professionnel.

Les données synthétiques offrent plusieurs avantages, ce qui en fait une option intéressante pour les organisations et les chercheurs. Son utilisation permet de relever divers défis dans les domaines de la science des données, de l'apprentissage automatique et du développement de logiciels. Voici quelques raisons d'utiliser des données synthétiques :
Dans de nombreux domaines, la collecte d'un nombre suffisant de données de qualité constitue un obstacle important. Les données synthétiques peuvent combler ces lacunes, ce qui permet une analyse complète et une formation solide des modèles.
En utilisant des données synthétiques qui ne correspondent pas à des individus réels, les organisations peuvent contourner les problèmes de confidentialité et de conformité avec des réglementations telles que GDPR et HIPAA.
Les données synthétiques peuvent être adaptées pour inclure des événements rares ou des conditions spécifiques, ce qui permet d'enrichir les ensembles de données et d'améliorer la précision des modèles.
Les données synthétiques sont souvent plus rentables que la collecte ou l'achat de données réelles.
Il existe plusieurs méthodes pour générer des données synthétiques, chacune présentant des avantages et des cas d'utilisation. Passons-les en revue dans cette section.
Il s'agit de la méthode la plus simple, qui consiste à générer des données par échantillonnage aléatoire à partir de distributions statistiques.
import pandas as pd
import numpy as np
# Generate 1,000 samples from a normal distribution
heights = np.random.normal(loc=170, scale=10, size=1000)
weights = np.random.normal(loc=70, scale=15, size=1000)
# Create a correlation between height and weight
weights += (heights - 170) * 0.5
df = pd.DataFrame({'Height': heights, 'Weight': weights})
# Add categorical data
genders = np.random.choice(['Male', 'Female'], size=1000)
df['Gender'] = genders
df.head()
df.describe()Le code ci-dessus génère un ensemble de données aléatoires simulant la taille et le poids à l'aide de distributions normales. Les tailles sont centrées autour de 170 cm avec un écart-type de 10, et les poids sont centrés autour de 70 kg avec un écart-type de 15. Une relation linéaire est établie entre la taille et le poids, de sorte que les personnes plus grandes pèsent généralement plus. Le code ajoute également une colonne Gender avec des valeurs "Male" ou "Female" attribuées de manière aléatoire.
Sortie :
Cette méthode est rapide et facile à mettre en œuvre, ce qui la rend utile pour les tests de base ou le prototypage. Il présente toutefois certaines limites. Il ne permet pas de saisir les relations complexes ou les modèles du monde réel, ni de prendre en compte les nuances ou les contraintes spécifiques liées au domaine.
Les méthodes fondées sur des règles utilisent des règles prédéfinies ou des connaissances du domaine pour créer des données présentant des caractéristiques spécifiques. Regardez l'exemple suivant :
import numpy as np
import pandas as pd
def generate_customer_data(num_records):
data = []
for _ in range(num_records):
age = np.random.randint(18, 80)
# Rule: Income is loosely based on age
base_income = 20000 + (age - 18) * 1000
income = np.random.normal(base_income, base_income * 0.2)
# Rule: Credit score is influenced by age and income
credit_score = min(850, max(300, int(600 + (age/80)*100 + (income/100000)*100 + np.random.normal(0, 50))))
# Rule: Loan amount is based on income and credit score
max_loan = income * (credit_score / 600)
loan_amount = np.random.uniform(0, max_loan)
data.append([age, income, credit_score, loan_amount])
return pd.DataFrame(data, columns=['Age', 'Income', 'CreditScore', 'LoanAmount'])
df = generate_customer_data(1000)
df.head()Le code Python ci-dessus génère un ensemble de données sur les clients comprenant 1 000 enregistrements. Pour chaque client, elle attribue au hasard un âge compris entre 18 et 80 ans. Un revenu est calculé en fonction de l'âge, les personnes plus âgées ayant généralement des revenus plus élevés. Le pointage de crédit est ensuite déterminé, en fonction de l'âge et des revenus, de manière à ce qu'il se situe entre 300 et 850. Un montant de prêt est également généré, en fonction des revenus et de la solvabilité de la personne.
Sortie :
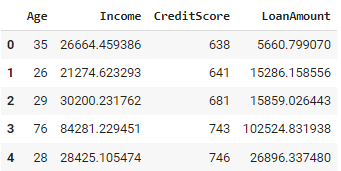
L'approche utilisée garantit que les données générées respectent les relations et les contraintes connues, ce qui permet d'intégrer des connaissances spécifiques au domaine directement dans le processus de génération de données. Cependant, il peut devenir complexe lorsqu'il s'agit de systèmes comportant de nombreuses règles interdépendantes, et la définition et la mise à jour de ces règles peuvent prendre beaucoup de temps pour les ensembles de données volumineux ou complexes.
La génération de données par simulation modélise les processus du monde réel pour créer des ensembles de données synthétiques. Il s'agit de simuler des événements ou des comportements sur la base de règles et de variables prédéfinies, ce qui nous permet d'étudier l'interaction de différents facteurs dans des systèmes dynamiques.
Cette méthode est souvent utilisée pour tester des scénarios et analyser les résultats potentiels, ce qui permet d'obtenir des informations précieuses sur des systèmes complexes tels que les processus de service à la clientèle, les chaînes d'approvisionnement et les opérations de soins de santé. Voici un exemple en Python :
import simpy
import random
import pandas as pd
class Bank(object):
def __init__(self, env, num_tellers):
self.env = env
self.teller = simpy.Resource(env, num_tellers)
def service(self, customer):
service_time = random.expovariate(1/10) # Avg service time of 10 minutes
yield self.env.timeout(service_time)
def customer(env, name, bank, data):
arrival_time = env.now
print(f'{name} arrives at the bank at {arrival_time:.2f}')
with bank.teller.request() as request:
yield request
wait_time = env.now - arrival_time
print(f'{name} waits for {wait_time:.2f}')
yield env.process(bank.service(name))
service_time = env.now - arrival_time
print(f'{name} leaves the bank at {env.now:.2f}')
# Append the customer data to the list
data.append((name, arrival_time, wait_time, service_time))
def run_simulation(env, num_customers, bank, data):
for i in range(num_customers):
env.process(customer(env, f'Customer {i}', bank, data))
yield env.timeout(random.expovariate(1/5)) # New customer every 5 minutes on average
# Set up and run the simulation
env = simpy.Environment()
bank = Bank(env, num_tellers=3)
num_customers = 100
data = [] # This will hold the customer data
env.process(run_simulation(env, num_customers, bank, data))
env.run()
# Create a DataFrame from the collected data
df = pd.DataFrame(data, columns=['Customer', 'ArrivalTime', 'WaitTime', 'ServiceTime'])
print(df.head())
print(df.describe())Le code simule une banque à l'aide de la fonction SimPy. Les clients arrivent à intervalles aléatoires, attendent d'être servis par l'un des trois guichetiers disponibles et repartent après avoir été servis.
La classe Bank définit la durée du service (10 minutes en moyenne), tandis que la fonction customer() suit l'arrivée de chaque client, son temps d'attente et la durée du service. Les clients sont traités dans la fonction run_simulation(), qui génère de nouveaux arrivages en moyenne toutes les 5 minutes.
Sortie :
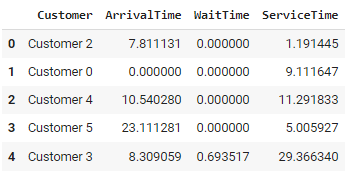
Cette approche permet de modéliser des systèmes complexes et dynamiques, ce qui permet de tester des scénarios et d'effectuer des analyses de type "what-if". Cependant, elle peut devenir très gourmande en ressources informatiques pour les simulations à grande échelle et nécessite une compréhension approfondie du système modélisé pour garantir des résultats précis.
Les modèles génératifs tels que les réseaux adversaires génératifs (GAN) et les autoencodeurs variationnels (VAE) sont devenus populaires pour créer des données synthétiques très réalistes. Ces modèles apprennent à saisir la distribution sous-jacente des données d'entrée et génèrent de nouveaux échantillons qui imitent les données du monde réel.
Ces deux méthodes sont largement utilisées dans des tâches telles que la génération d'images et le traitement du langage naturel, principalement pour créer des données synthétiques pour les modèles d'apprentissage automatique lorsque les données réelles sont rares ou sensibles.
Consultez le cours gratuit sur les concepts d'IA générative sur DataCamp pour apprendre comment les modèles d'IA générative sont développés et comment ils auront un impact sur la société à l'avenir.
Plusieurs outils sont disponibles pour faciliter la génération de données synthétiques pour différents cas d'utilisation, allant de la modélisation statistique à l'apprentissage automatique et aux simulations de soins de santé.
Ces outils sont conçus pour créer des données qui reflètent les caractéristiques des ensembles de données du monde réel, ce qui permet d'expérimenter et de tester en toute sécurité sans exposer d'informations sensibles.
SDV est une bibliothèque Python qui fournit une suite de modèles pour générer des données synthétiques. Il prend en charge différents types de données, notamment les séries chronologiques, les données relationnelles et les données tabulaires. SDV utilise des modèles probabilistes avancés tels que les copules gaussiennes et des méthodes d'apprentissage profond pour apprendre la structure des données originales et produire des versions synthétiques de haute qualité. Il est largement utilisé dans les applications d'apprentissage automatique pour générer des données d'entraînement synthétiques lorsque les données réelles sont limitées ou sensibles.
Pour en savoir plus sur la génération de données synthétiques à l'aide de la bibliothèque SDV en Python, consultez le dépôt GitHub officiel ou essayez leurs tutoriels officiels.
Gretel.AI est une plateforme basée sur le cloud qui offre des services de génération et d'anonymisation de données synthétiques. Il fournit des API conviviales et des modèles préconstruits qui peuvent générer des données synthétiques réalistes basées sur une variété d'entrées, y compris des données structurées, semi-structurées et non structurées. Gretel.AI s'attache à simplifier le flux de travail des développeurs et des scientifiques des données, en facilitant la génération de données synthétiques avec un minimum d'installation.
Consultez le guide de démarrage rapide de Gretel pour commencer à générer des données synthétiques à l'aide de Gretel.AI.
Synthea est un outil open-source spécifiquement développé pour les simulations de soins de santé. Il génère des dossiers de patients synthétiques qui reflètent des antécédents médicaux, des traitements et des résultats réalistes, conformément aux normes médicales et cliniques. Les chercheurs et les établissements de soins de santé utilisent souvent Synthea pour simuler des populations de patients et étudier les tendances en matière de santé publique sans utiliser de données réelles sur les patients, ce qui le rend inestimable pour l'analyse des données sur les soins de santé.
synthpop est un package R spécialement conçu pour générer des versions synthétiques d'ensembles de données du monde réel. Il utilise des modèles statistiques pour reproduire les relations et les distributions trouvées dans les données originales, ce qui permet aux utilisateurs de partager et d'analyser des données en toute sécurité sans compromettre la confidentialité. synthpop est particulièrement utile pour les chercheurs et les institutions qui ont besoin de publier des ensembles de données tout en protégeant la vie privée.
Pour en savoir plus sur la génération de données synthétiques dans R à l'aide de synthpop, consultez le tutoriel Générer des ensembles de données synthétiques avec synthpop dans R.
Comme indiqué précédemment, l'IA générative joue un rôle important dans la création de données synthétiques, principalement grâce à des modèles avancés qui apprennent les modèles et les distributions sous-jacents des données du monde réel et génèrent des versions synthétiques réalistes. Examinons chacune de ces techniques et leurs applications.
Les GAN sont l'un des outils les plus puissants pour générer des données synthétiques. Ils se composent de deux réseaux neuronaux concurrents : un générateur et un discriminateur. Le générateur crée des données synthétiques, tandis que le discriminateur tente de différencier les données réelles des données synthétiques. Grâce à ce processus contradictoire, le générateur améliore sa capacité à créer des données très réalistes. Les GAN sont largement utilisés pour générer des images, des vidéos et même des données tabulaires, et ils ont trouvé des applications dans des domaines tels que les soins de santé, la conduite autonome et le divertissement.
Les VAE sont un autre modèle génératif populaire pour la génération de données synthétiques. Ils fonctionnent en encodant les données dans un espace latent compressé, puis en les décodant sous leur forme originale. Cela permet aux VAE de générer de nouveaux points de données en échantillonnant l'espace latent, ce qui les rend utiles pour des applications telles que la synthèse d'images et la détection d'anomalies. Bien que les VAE n'atteignent pas le même niveau de réalisme que les GAN, ils sont plus stables pendant la formation et permettent un meilleur contrôle de la structure des données générées.
Les transformateurs, comme les modèles GPT, ont révolutionné la génération de textes en produisant des phrases et des paragraphes cohérents et adaptés au contexte. Pour les données synthétiques, les transformateurs peuvent générer un texte à l'apparence humaine qui reflète des ensembles de données du monde réel, tels que des commentaires de clients, des conversations ou d'autres données textuelles. Ces modèles sont particulièrement utiles pour générer de grands volumes de données synthétiques textuelles pour des tâches de traitement du langage naturel (NLP), mais ils ont également la flexibilité d'être affinés pour des applications spécifiques.
Pour découvrir le rôle que l'intelligence artificielle générative joue aujourd'hui et jouera à l'avenir dans un environnement professionnel, consultez le cours Generative AI for Business.
La technique de génération de données synthétiques appropriée dépend de votre cas d'utilisation, du type de données et de vos objectifs. Pour les ensembles de données simples avec des distributions statistiques bien définies, la génération de données aléatoires ou la génération basée sur des règles peuvent être suffisantes.
Si vous traitez des données complexes et interdépendantes ou si vous devez préserver l'intégrité relationnelle (par exemple, dans le domaine de la santé ou de la finance), une approche basée sur la simulation ou des modèles génératifs tels que les GAN et les VAE peuvent être plus appropriés. Les modèles basés sur des transformateurs peuvent fournir de meilleurs résultats pour la génération de textes ou les tâches impliquant des données à grande échelle.
Tenez compte des compromis entre la facilité de mise en œuvre, le réalisme des données et les exigences en matière de calcul lorsque vous choisissez une technique.
Pour illustrer cet exemple, j'ai créé une base de données de patients fictive composée de trois tableaux, chacun contenant exactement 5 000 enregistrements.
Tableau 1 - Patients
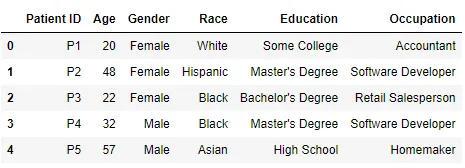
Tableau 2 - Résultats des analyses de laboratoire
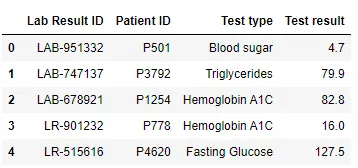
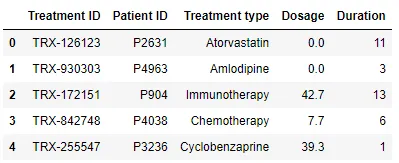
Tableau 3 - Traitements
Pour mettre en œuvre cet exemple, vous devrez vous inscrire sur Gretel.AI et générer une clé API. Vous devrez également installer une bibliothèque en Python :
!pip install -U gretel-trainerPour mettre en œuvre ce cas d'utilisation, nous utiliserons RelationalData du module gretel_trainer.relational. Il permet aux utilisateurs de définir et de maintenir automatiquement les relations entre plusieurs tableaux, en veillant à ce que les dépendances des clés étrangères et l'intégrité des données soient préservées dans le résultat synthétique.
Ceci est particulièrement utile pour générer des données synthétiques de haute qualité qui reflètent la structure et les dépendances des bases de données réelles, ce qui facilite leur utilisation dans des applications telles que l'apprentissage automatique, la recherche ou le respect des réglementations en matière de confidentialité des données.
Exemple de code :
import pandas as pd
from gretel_client import configure_session
from gretel_trainer.relational import RelationalData
configure_session(api_key="your_api_key", cache="yes", validate=True)
csv_dir = "csv/"
tables = [("patients", "Patient ID"), ("lab_results", "Lab Result ID"), ("treatments", "Treatment ID")]
foreign_keys = [("lab_results.Patient ID", "patients.Patient ID"), ("treatments.Patient ID", "patients.Patient ID")]
relational_data = RelationalData()
for table, pk in tables:
relational_data.add_table(name=table, primary_key=pk, data=pd.read_csv(f"{csv_dir}/{table}.csv"))
for fk, ref in foreign_keys:
relational_data.add_foreign_key(foreign_key=fk, referencing=ref)
from gretel_trainer.relational import MultiTable
multitable = MultiTable(
relational_data,
project_display_name="Clinical Trials",
gretel_model="amplify"
)
multitable.train()
multitable.generate(record_size_ratio=1)
synthetic_patients = multitable.synthetic_output_tables['patients']
synthetic_lab_results = multitable.synthetic_output_tables['lab_results']
synthetic_treatments = multitable.synthetic_output_tables['treatments']
Ce code utilise l'API Gretel.AI pour générer des données synthétiques pour une base de données relationnelle. Il établit d'abord une session à l'aide d'une clé API et charge trois fichiers CSV (patients, lab_results, et treatments), en spécifiant leurs clés primaires et en définissant les relations entre les clés étrangères.
La classe RelationalData est utilisée pour maintenir ces relations. Après avoir configuré les données, un modèle est formé à l'aide de la classe MultiTable, qui synthétise l'ensemble des données relationnelles.
Une fois le modèle formé, la méthode generate() est utilisée pour générer des données synthétiques. Le paramètre record_size_ratio détermine le rapport entre la taille des données générées. record_size_ratio=1 signifie que le nombre d'enregistrements de l'ensemble de données synthétiques est égal à celui de l'ensemble de données original, c'est-à-dire 5 000 enregistrements.
L'évaluation de la qualité des données synthétiques est essentielle pour garantir leur utilité et leur confidentialité. Commencez par comparer les distributions statistiques entre les données originales et synthétiques - les mesures telles que la moyenne, la variance et la corrélation doivent être très proches.
Une autre méthode consiste à utiliser des données synthétiques pour former des modèles d'apprentissage automatique et à comparer leurs performances (par exemple, la précision ou le score F1) aux modèles formés sur des données réelles.
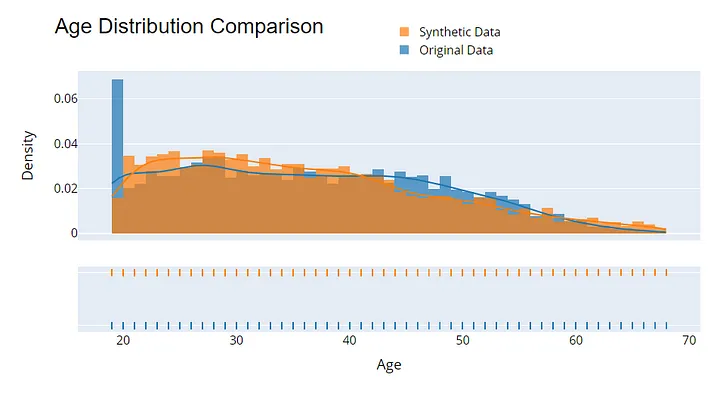
Exemple de visualisation pour évaluer la qualité des données synthétiques. Image par l'auteur.
La génération de données synthétiques est apparue pour répondre aux défis liés à la rareté des données, aux préoccupations en matière de protection de la vie privée et à la nécessité de disposer d'ensembles de données diversifiés et de haute qualité.
Avec des techniques allant de la simple génération de données aléatoires aux modèles génératifs avancés comme les GAN et les VAE, les données synthétiques permettent aux organisations d'innover et de construire de meilleurs modèles d'apprentissage automatique tout en protégeant les informations sensibles.
Des outils comme SDV et des services gérés comme Gretel.AI rendent la génération de données synthétiques plus accessible, même pour les bases de données relationnelles complexes.
Au fur et à mesure que la génération de données synthétiques évolue, ses applications deviendront de plus en plus importantes pour faire progresser l'IA, les soins de santé, la finance et d'innombrables autres domaines.
Vous voulez aller plus loin ? Suivez la formation Utiliser des données synthétiques pour l'apprentissage automatique et l'IA en Python pour découvrir ce que sont les données synthétiques, comment elles protègent la vie privée et comment elles sont utilisées pour accélérer l'adoption de l'IA dans les secteurs de la banque, de la santé et bien d'autres.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.
Apprenez-en plus sur l'apprentissage automatique et l'IA avec les cours suivants !
Cours
Cours
Cours