
Curso
Machine Learning for Business
2 h
46.2K
No mundo pós-GPT, a demanda por conjuntos de dados de alta qualidade nunca foi tão grande. A IA generativa e os grandes modelos de linguagem dependem da disponibilidade de dados robustos, de alta qualidade e em grande quantidade. No entanto, a obtenção de tais dados geralmente enfrenta desafios, que vão desde preocupações com a privacidade até a escassez de dados reais em todo o mundo.
Entre na geração de dados sintéticos: uma solução poderosa que aborda a escassez de dados reais e resolve as preocupações com a privacidade. Nesta postagem do blog, aprenderemos o que são dados sintéticos, por que eles são essenciais, as técnicas e ferramentas para gerá-los e como você pode começar.
Os dados sintéticos são informações geradas artificialmente que imitam os dados do mundo real em termos de estrutura e propriedades estatísticas, mas não correspondem a entidades reais. Ele é criado algoritmicamente e é usado como substituto de dados reais em vários aplicativos.
As características mencionadas tornam os dados sintéticos inestimáveis para testes de software, treinamento de modelos de IA, aumento de dados, modelagem financeira e pesquisa na área da saúde, em que são necessários conjuntos de dados grandes e diversificados, mas os dados reais podem ser escassos, confidenciais ou restritos por normas de privacidade.
Os dados sintéticos gerados por simulações ou algoritmos de computador são uma alternativa econômica aos dados do mundo real e são cada vez mais usados para criar modelos precisos de IA. Fonte da imagem: NVIDIA blog
Os três principais tipos de dados sintéticos são estruturados, não estruturados e sequenciais, cada um com suas próprias características e aplicações. Vamos explorá-los com mais detalhes.
Dados estruturados são informações organizadas em um formato predefinido, normalmente encontradas em bancos de dados e planilhas. Esse tipo de dados sintéticos imita o formato e as propriedades estatísticas dos dados estruturados reais. Os exemplos incluem:
Os métodos de geração de dados sintéticos estruturados geralmente envolvem modelagem estatística, sistemas baseados em regras ou técnicas de aprendizado de máquina, como autoencoders variacionais (VAEs) ou redes adversárias generativas (GANs).
Os dados não estruturados não têm um formato predefinido e são cada vez mais importantes em aplicativos de aprendizado de máquina. Os tipos de dados sintéticos não estruturados incluem:
Os dados sequenciais envolvem tempo ou ordem, o que os torna essenciais para modelos que precisam entender as relações temporais. Os exemplos incluem:
Melhore sua carreira como cientista de dados profissional.

Os dados sintéticos oferecem várias vantagens, o que os torna uma opção atraente para organizações e pesquisadores. Seu uso pode abordar vários desafios em ciência de dados, aprendizado de máquina e desenvolvimento de software. Aqui estão alguns dos motivos para você usar dados sintéticos:
Em muitos campos, a coleta de dados de qualidade suficiente é um obstáculo significativo. Os dados sintéticos podem preencher essas lacunas, permitindo uma análise abrangente e um treinamento robusto do modelo.
Ao usar dados sintéticos que não correspondem a indivíduos reais, as organizações podem evitar preocupações com a privacidade e a conformidade com regulamentos como o GDPR e o HIPAA.
Os dados sintéticos podem ser adaptados para incluir eventos raros ou condições específicas, enriquecendo os conjuntos de dados e melhorando a precisão do modelo.
Muitas vezes, os dados sintéticos podem ser mais econômicos do que a coleta ou a compra de dados reais.
Existem vários métodos para gerar dados sintéticos, cada um com vantagens e casos de uso. Vamos analisá-los nesta seção.
Esse é o método mais simples, que envolve a geração de dados por amostragem aleatória de distribuições estatísticas.
import pandas as pd
import numpy as np
# Generate 1,000 samples from a normal distribution
heights = np.random.normal(loc=170, scale=10, size=1000)
weights = np.random.normal(loc=70, scale=15, size=1000)
# Create a correlation between height and weight
weights += (heights - 170) * 0.5
df = pd.DataFrame({'Height': heights, 'Weight': weights})
# Add categorical data
genders = np.random.choice(['Male', 'Female'], size=1000)
df['Gender'] = genders
df.head()
df.describe()O código acima gera um conjunto de dados aleatórios que simula a altura e o peso usando distribuições normais. As alturas estão centradas em torno de 170 cm, com um desvio padrão de 10, e os pesos estão centrados em torno de 70 kg, com um desvio padrão de 15. É introduzida uma relação linear entre altura e peso, de modo que indivíduos mais altos geralmente pesam mais. O código também adiciona uma coluna Gender com valores atribuídos aleatoriamente como "Male" (Masculino) ou "Female" (Feminino).
Saída:
Esse método é rápido e fácil de implementar, o que o torna útil para testes básicos ou prototipagem. No entanto, ele tem algumas limitações. Ele não captura relações complexas ou padrões do mundo real nem leva em conta nuances ou restrições específicas relacionadas ao domínio.
Os métodos baseados em regras usam regras predefinidas ou conhecimento de domínio para criar dados com características específicas. Dê uma olhada no exemplo a seguir:
import numpy as np
import pandas as pd
def generate_customer_data(num_records):
data = []
for _ in range(num_records):
age = np.random.randint(18, 80)
# Rule: Income is loosely based on age
base_income = 20000 + (age - 18) * 1000
income = np.random.normal(base_income, base_income * 0.2)
# Rule: Credit score is influenced by age and income
credit_score = min(850, max(300, int(600 + (age/80)*100 + (income/100000)*100 + np.random.normal(0, 50))))
# Rule: Loan amount is based on income and credit score
max_loan = income * (credit_score / 600)
loan_amount = np.random.uniform(0, max_loan)
data.append([age, income, credit_score, loan_amount])
return pd.DataFrame(data, columns=['Age', 'Income', 'CreditScore', 'LoanAmount'])
df = generate_customer_data(1000)
df.head()O código Python acima gera um conjunto de dados de clientes com 1.000 registros. Para cada cliente, ele atribui aleatoriamente uma idade entre 18 e 80 anos. Com base na idade, é calculada uma renda, sendo que os indivíduos mais velhos geralmente têm rendas mais altas. A pontuação de crédito é então determinada, influenciada pela idade e pela renda, garantindo que ela fique entre 300 e 850. Também é gerado um valor de empréstimo, que depende da renda e da pontuação de crédito do indivíduo.
Saída:
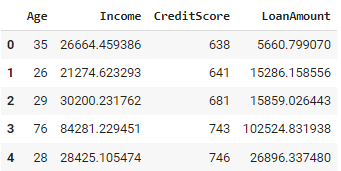
A abordagem usada garante que os dados gerados sigam as relações e restrições conhecidas, possibilitando a incorporação de conhecimento específico do domínio diretamente no processo de geração de dados. No entanto, ele pode se tornar complexo ao lidar com sistemas com muitas regras inter-relacionadas, e a definição e a manutenção dessas regras podem ser demoradas para conjuntos de dados grandes ou complexos.
A geração de dados baseada em simulação modela processos do mundo real para criar conjuntos de dados sintéticos. Envolve a simulação de eventos ou comportamentos com base em regras e variáveis predefinidas, o que nos permite estudar como diferentes fatores interagem em sistemas dinâmicos.
Esse método é frequentemente usado para testar cenários e analisar possíveis resultados, fornecendo informações valiosas sobre sistemas complexos, como processos de atendimento ao cliente, cadeias de suprimentos e operações de saúde. Aqui está um exemplo em Python:
import simpy
import random
import pandas as pd
class Bank(object):
def __init__(self, env, num_tellers):
self.env = env
self.teller = simpy.Resource(env, num_tellers)
def service(self, customer):
service_time = random.expovariate(1/10) # Avg service time of 10 minutes
yield self.env.timeout(service_time)
def customer(env, name, bank, data):
arrival_time = env.now
print(f'{name} arrives at the bank at {arrival_time:.2f}')
with bank.teller.request() as request:
yield request
wait_time = env.now - arrival_time
print(f'{name} waits for {wait_time:.2f}')
yield env.process(bank.service(name))
service_time = env.now - arrival_time
print(f'{name} leaves the bank at {env.now:.2f}')
# Append the customer data to the list
data.append((name, arrival_time, wait_time, service_time))
def run_simulation(env, num_customers, bank, data):
for i in range(num_customers):
env.process(customer(env, f'Customer {i}', bank, data))
yield env.timeout(random.expovariate(1/5)) # New customer every 5 minutes on average
# Set up and run the simulation
env = simpy.Environment()
bank = Bank(env, num_tellers=3)
num_customers = 100
data = [] # This will hold the customer data
env.process(run_simulation(env, num_customers, bank, data))
env.run()
# Create a DataFrame from the collected data
df = pd.DataFrame(data, columns=['Customer', 'ArrivalTime', 'WaitTime', 'ServiceTime'])
print(df.head())
print(df.describe())O código simula um banco usando o SimPy para você. Os clientes chegam em intervalos aleatórios, aguardam o atendimento de um dos três caixas disponíveis e saem depois de serem atendidos.
A classe Bank define o tempo de serviço (em média 10 minutos), enquanto a função customer() rastreia a chegada de cada cliente, o tempo de espera e a duração do serviço. Os clientes são processados na função run_simulation(), que gera novas chegadas, em média, a cada 5 minutos.
Saída:
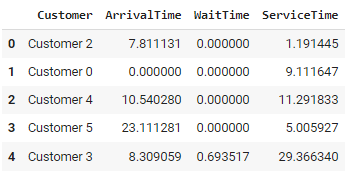
Essa abordagem permite a modelagem de sistemas complexos e dinâmicos, possibilitando testes de cenários e análises "what-if". No entanto, ele pode se tornar intensivo em termos de computação para simulações em grande escala e requer um entendimento completo do sistema modelado para garantir resultados precisos.
Modelos generativos, como redes adversárias generativas (GANs) e autoencoders variacionais (VAEs), tornaram-se populares para a criação de dados sintéticos altamente realistas. Esses modelos aprendem a capturar a distribuição subjacente dos dados de entrada e geram novas amostras que imitam os dados do mundo real.
Ambos os métodos são amplamente usados em tarefas como geração de imagens e processamento de linguagem natural, principalmente para criar dados sintéticos para modelos de aprendizado de máquina quando os dados do mundo real são escassos ou sensíveis.
Confira o curso gratuito sobre conceitos de IA generativa no Datacamp para saber como os modelos de IA generativa são desenvolvidos e como eles afetarão a sociedade no futuro.
Há várias ferramentas disponíveis que facilitam a geração de dados sintéticos para vários casos de uso, desde modelagem estatística até aprendizado de máquina e simulações de saúde.
Essas ferramentas são projetadas para criar dados que espelham as características dos conjuntos de dados do mundo real, permitindo a realização de experimentos e testes seguros sem expor informações confidenciais.
SDV é uma biblioteca Python que fornece um conjunto de modelos para gerar dados sintéticos. Ele oferece suporte a vários tipos de dados, incluindo séries temporais, dados relacionais e dados tabulares. O SDV usa modelos probabilísticos avançados, como cópulas gaussianas e métodos de aprendizagem profunda, para aprender a estrutura dos dados originais e produzir versões sintéticas de alta qualidade. Ele é amplamente usado em aplicativos de aprendizado de máquina para gerar dados de treinamento sintéticos quando os dados reais são limitados ou sensíveis.
Para saber mais sobre como gerar dados sintéticos usando a biblioteca SDV em Python, confira o repositório oficial do GitHub ou experimente os tutoriais oficiais.
A Gretel.AI é uma plataforma baseada em nuvem que oferece serviços de geração e anonimização de dados sintéticos. Ele fornece APIs fáceis de usar e modelos pré-construídos que podem gerar dados sintéticos realistas com base em uma variedade de entradas, incluindo dados estruturados, semiestruturados e não estruturados. O Gretel.AI se concentra em simplificar o fluxo de trabalho para desenvolvedores e cientistas de dados, facilitando a geração de dados sintéticos com o mínimo de configuração.
Confira o guia de início rápido da Gretel para você começar a gerar dados sintéticos usando a Gretel.AI
O Synthea é uma ferramenta de código aberto desenvolvida especificamente para simulações na área da saúde. Ele gera registros sintéticos de pacientes que refletem históricos médicos, tratamentos e resultados realistas, seguindo padrões médicos e clínicos. Pesquisadores e instituições de saúde costumam usar o Synthea para simular populações de pacientes e estudar tendências de saúde pública sem usar dados reais de pacientes, o que o torna inestimável para a análise de dados de saúde.
O synthpop é um pacote R projetado especificamente para gerar versões sintéticas de conjuntos de dados do mundo real. Ele funciona usando modelos estatísticos para replicar as relações e distribuições encontradas nos dados originais, permitindo que os usuários compartilhem e analisem dados com segurança sem comprometer a confidencialidade. O synthpop é particularmente útil para pesquisadores e instituições que precisam divulgar conjuntos de dados e, ao mesmo tempo, proteger a privacidade.
Para saber mais sobre como gerar dados sintéticos em R usando o synthpop, confira o tutorial Generating Synthetic Data Sets with synthpop in R (Gerando conjuntos de dados sintéticos com synthpop em R ).
Conforme mencionado anteriormente, a IA generativa desempenha um papel importante na criação de dados sintéticos, principalmente por meio de modelos avançados que aprendem os padrões e as distribuições subjacentes dos dados do mundo real e geram versões sintéticas realistas. Vamos explorar cada uma dessas técnicas e suas aplicações.
Os GANs são uma das ferramentas mais poderosas para gerar dados sintéticos. Eles consistem em duas redes neurais concorrentes: um gerador e um discriminador. O gerador cria dados sintéticos, enquanto o discriminador tenta diferenciar entre dados reais e sintéticos. Por meio desse processo contraditório, o gerador melhora sua capacidade de criar dados altamente realistas. Os GANs são amplamente usados para gerar imagens, vídeos e até mesmo dados tabulares, e encontraram aplicações em áreas como saúde, direção autônoma e entretenimento.
Os VAEs são outro modelo generativo popular para a geração de dados sintéticos. Eles funcionam codificando dados em um espaço latente comprimido e, em seguida, decodificando-os de volta à sua forma original. Isso permite que os VAEs gerem novos pontos de dados por amostragem do espaço latente, tornando-os úteis para aplicações como síntese de imagens e detecção de anomalias. Embora os VAEs não atinjam o mesmo nível de realismo dos GANs, eles são mais estáveis durante o treinamento e oferecem melhor controle sobre a estrutura dos dados gerados.
Os transformadores, como os modelos GPT, revolucionaram a geração de texto ao produzir frases e parágrafos coerentes e contextualmente precisos. Para dados sintéticos, os transformadores podem gerar texto semelhante ao humano que espelha conjuntos de dados do mundo real, como avaliações de clientes, conversas ou outros dados textuais. Esses modelos são particularmente úteis na geração de grandes volumes de dados sintéticos baseados em texto para tarefas de processamento de linguagem natural (NLP), mas também têm a flexibilidade de serem ajustados para aplicações específicas.
Para saber o papel que a inteligência artificial generativa desempenha hoje e desempenhará no futuro em um ambiente de negócios, confira o curso Generative AI for Business.
A técnica apropriada de geração de dados sintéticos depende do caso de uso, do tipo de dados e dos objetivos que você tem. Para conjuntos de dados simples com distribuições estatísticas bem definidas, a geração de dados aleatórios ou a geração baseada em regras pode ser suficiente.
Se você estiver lidando com dados complexos e inter-relacionados ou precisar preservar a integridade relacional (por exemplo, na área de saúde ou finanças), uma abordagem baseada em simulação ou modelos generativos, como GANs e VAEs, pode ser mais adequada. Os modelos baseados em transformadores podem fornecer melhores resultados para geração de texto ou tarefas que envolvam dados em grande escala.
Considere as vantagens e desvantagens entre a facilidade de implementação, o realismo dos dados e os requisitos computacionais ao escolher uma técnica.
Para demonstrar esse exemplo, gerei um banco de dados simulado de pacientes com três tabelas, cada uma com exatamente 5.000 registros.
Tabela 1 - Pacientes
Tabela 2 - Resultados de laboratório
Tabela 3 - Tratamentos
Para implementar esse exemplo, você terá que se inscrever no Gretel.AI e gerar uma chave de API. Você também terá que instalar uma biblioteca em Python:
!pip install -U gretel-trainerPara implementar esse caso de uso, usaremos o site RelationalData do módulo gretel_trainer.relational. Ele permite que os usuários definam e mantenham automaticamente as relações entre várias tabelas, garantindo que as dependências de chaves estrangeiras e a integridade dos dados sejam preservadas na saída sintética.
Isso é particularmente útil para a geração de dados sintéticos de alta qualidade que espelham a estrutura e as dependências de bancos de dados do mundo real, facilitando o uso em aplicativos como aprendizado de máquina, pesquisa ou conformidade com as normas de privacidade de dados.
Exemplo de código:
import pandas as pd
from gretel_client import configure_session
from gretel_trainer.relational import RelationalData
configure_session(api_key="your_api_key", cache="yes", validate=True)
csv_dir = "csv/"
tables = [("patients", "Patient ID"), ("lab_results", "Lab Result ID"), ("treatments", "Treatment ID")]
foreign_keys = [("lab_results.Patient ID", "patients.Patient ID"), ("treatments.Patient ID", "patients.Patient ID")]
relational_data = RelationalData()
for table, pk in tables:
relational_data.add_table(name=table, primary_key=pk, data=pd.read_csv(f"{csv_dir}/{table}.csv"))
for fk, ref in foreign_keys:
relational_data.add_foreign_key(foreign_key=fk, referencing=ref)
from gretel_trainer.relational import MultiTable
multitable = MultiTable(
relational_data,
project_display_name="Clinical Trials",
gretel_model="amplify"
)
multitable.train()
multitable.generate(record_size_ratio=1)
synthetic_patients = multitable.synthetic_output_tables['patients']
synthetic_lab_results = multitable.synthetic_output_tables['lab_results']
synthetic_treatments = multitable.synthetic_output_tables['treatments']
Esse código usa a API Gretel.AI para gerar dados sintéticos para um banco de dados relacional. Primeiro, ele configura uma sessão usando uma chave de API e carrega três arquivos CSV (patients, lab_results e treatments), especificando suas chaves primárias e definindo relacionamentos de chave estrangeira.
A classe RelationalData é usada para manter esses relacionamentos. Depois de configurar os dados, um modelo é treinado usando a classe MultiTable, que sintetiza todo o conjunto de dados relacionais.
Depois que o modelo é treinado, o método generate() é usado para gerar dados sintéticos. O parâmetro record_size_ratio determina a relação de referência ao tamanho dos dados gerados. record_size_ratio=1 significa que o número de registros no conjunto de dados sintético = conjunto de dados original, ou seja, 5.000 registros.
A avaliação da qualidade dos dados sintéticos é essencial para garantir sua utilidade e privacidade. Comece comparando as distribuições estatísticas entre os dados originais e sintéticos - métricas como média, variância e correlação devem ser muito semelhantes.
Outro método é usar dados sintéticos para treinar modelos de aprendizado de máquina e comparar seu desempenho (por exemplo, precisão ou pontuação F1) com modelos treinados em dados reais.
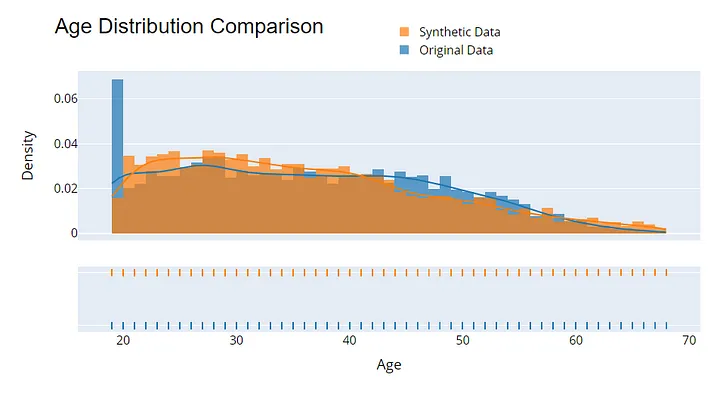
Exemplo de visualização para avaliar a qualidade dos dados sintéticos. Imagem do autor.
A geração de dados sintéticos surgiu para enfrentar os desafios relacionados à escassez de dados, às preocupações com a privacidade e à necessidade de conjuntos de dados diversificados e de alta qualidade.
Com técnicas que vão desde a simples geração de dados aleatórios até modelos generativos avançados, como GANs e VAEs, os dados sintéticos permitem que as organizações inovem e criem melhores modelos de aprendizado de máquina, ao mesmo tempo em que protegem informações confidenciais.
Ferramentas como o SDV e serviços gerenciados como o Gretel.AI tornam a geração de dados sintéticos mais acessível, mesmo para bancos de dados relacionais complexos.
À medida que a geração de dados sintéticos evolui, suas aplicações serão cada vez mais importantes para o avanço da IA, da saúde, das finanças e de inúmeros outros campos.
Você quer se aprofundar mais? Assista ao treinamento Using Synthetic Data for Machine Learning & AI in Python para descobrir o que são dados sintéticos, como eles protegem a privacidade e como estão sendo usados para acelerar a adoção da IA nos setores bancário, de saúde e muitos outros.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.
Saiba mais sobre aprendizado de máquina e IA com os cursos a seguir!
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Bekhruz Tuychiev
15 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Vidhi Chugh
