
Course
Machine Learning for Business
2 hr
46.2K
In the post-GPT world, the demand for high-quality datasets has never been greater. Generative AI and large language models all hinge on the availability of robust, high-quality, and high-quantity data. However, obtaining such data is often faced with challenges, ranging from privacy concerns to the sheer scarcity of actual data worldwide.
Enter synthetic data generation: a powerful solution that addresses the scarcity of actual data and settles privacy concerns. In this blog post, we will learn what synthetic data is, why it's essential, the techniques and tools for generating it, and how you can get started.
Synthetic data is artificially generated information that mimics real-world data in structure and statistical properties but doesn't correspond to actual entities. It's created algorithmically and is used as a stand-in for real data in various applications.
The mentioned characteristics make synthetic data invaluable for software testing, AI model training, data augmentation, financial modeling, and healthcare research, where large, diverse datasets are needed, but real data may be scarce, sensitive, or restricted by privacy regulations.
Synthetic data generated from computer simulations or algorithms provides an inexpensive alternative to real-world data and is increasingly used to create accurate AI models. Image source: NVIDIA blog
The three main types of synthetic data are structured, unstructured, and sequential, each with its own characteristics and applications. Let’s explore them in more detail.
Structured data is information organized in a predefined format, typically found in databases and spreadsheets. This type of synthetic data mimics the format and statistical properties of real structured data. Examples include:
Generation methods for structured synthetic data often involve statistical modeling, rule-based systems, or machine learning techniques like variational autoencoders (VAEs) or generative adversarial networks (GANs).
Unstructured data lacks a predefined format and is increasingly important in machine learning applications. Types of synthetic unstructured data include:
Sequential data involves time or order, making it essential for models that need to understand temporal relationships. Examples include:
Supercharge your career as a professional data scientist.

Synthetic data offers several advantages, making it an attractive option for organizations and researchers. Its use can address various challenges in data science, machine learning, and software development. Here are some of the reasons to use synthetic data:
In many fields, collecting enough quality data is a significant hurdle. Synthetic data can fill these gaps, allowing for comprehensive analysis and robust model training.
By using synthetic data that doesn't correspond to actual individuals, organizations can sidestep privacy concerns and compliance with regulations like GDPR and HIPAA.
Synthetic data can be tailored to include rare events or specific conditions, enriching datasets and improving model accuracy.
Synthetic data can often be more cost-effective than collecting or purchasing real data.
Several methods exist for generating synthetic data, each with advantages and use cases. Let’s review them in this section.
This is the simplest method, involving generating data by randomly sampling from statistical distributions.
import pandas as pd
import numpy as np
# Generate 1,000 samples from a normal distribution
heights = np.random.normal(loc=170, scale=10, size=1000)
weights = np.random.normal(loc=70, scale=15, size=1000)
# Create a correlation between height and weight
weights += (heights - 170) * 0.5
df = pd.DataFrame({'Height': heights, 'Weight': weights})
# Add categorical data
genders = np.random.choice(['Male', 'Female'], size=1000)
df['Gender'] = genders
df.head()
df.describe()The above code generates a random dataset simulating height and weight using normal distributions. The heights are centered around 170 cm with a standard deviation of 10, and the weights are centered around 70 kg with a standard deviation of 15. A linear relationship is introduced between height and weight, so taller individuals generally weigh more. The code also adds a Gender column with randomly assigned values of “Male” or “Female.”
Output:
This method is quick and easy to implement, making it useful for basic testing or prototyping. However, it has some limitations. It doesn't capture complex relationships or real-world patterns or account for specific domain-related nuances or constraints.
Rule-based methods use predefined rules or domain knowledge to create data with specific characteristics. Take a look at the following example:
import numpy as np
import pandas as pd
def generate_customer_data(num_records):
data = []
for _ in range(num_records):
age = np.random.randint(18, 80)
# Rule: Income is loosely based on age
base_income = 20000 + (age - 18) * 1000
income = np.random.normal(base_income, base_income * 0.2)
# Rule: Credit score is influenced by age and income
credit_score = min(850, max(300, int(600 + (age/80)*100 + (income/100000)*100 + np.random.normal(0, 50))))
# Rule: Loan amount is based on income and credit score
max_loan = income * (credit_score / 600)
loan_amount = np.random.uniform(0, max_loan)
data.append([age, income, credit_score, loan_amount])
return pd.DataFrame(data, columns=['Age', 'Income', 'CreditScore', 'LoanAmount'])
df = generate_customer_data(1000)
df.head()The Python code above generates a dataset of customer data with 1,000 records. For each customer, it randomly assigns an age between 18 and 80. Based on age, an income is calculated, where older individuals generally have higher incomes. The credit score is then determined, influenced by age and income, ensuring it falls between 300 and 850. A loan amount is also generated, dependent on the individual's income and credit score.
Output:
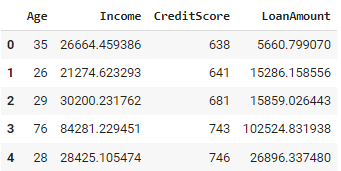
The used approach ensures that the generated data adheres to known relationships and constraints, making it possible to incorporate domain-specific knowledge directly into the data generation process. However, it can become complex when dealing with systems with many interrelated rules, and defining and maintaining such rules can be time-consuming for large or intricate datasets.
Simulation-based data generation models real-world processes to create synthetic datasets. It involves simulating events or behaviors based on predefined rules and variables, allowing us to study how different factors interact in dynamic systems.
This method is often used to test scenarios and analyze potential outcomes, providing valuable insights into complex systems like customer service processes, supply chains, and healthcare operations. Here’s an example in Python:
import simpy
import random
import pandas as pd
class Bank(object):
def __init__(self, env, num_tellers):
self.env = env
self.teller = simpy.Resource(env, num_tellers)
def service(self, customer):
service_time = random.expovariate(1/10) # Avg service time of 10 minutes
yield self.env.timeout(service_time)
def customer(env, name, bank, data):
arrival_time = env.now
print(f'{name} arrives at the bank at {arrival_time:.2f}')
with bank.teller.request() as request:
yield request
wait_time = env.now - arrival_time
print(f'{name} waits for {wait_time:.2f}')
yield env.process(bank.service(name))
service_time = env.now - arrival_time
print(f'{name} leaves the bank at {env.now:.2f}')
# Append the customer data to the list
data.append((name, arrival_time, wait_time, service_time))
def run_simulation(env, num_customers, bank, data):
for i in range(num_customers):
env.process(customer(env, f'Customer {i}', bank, data))
yield env.timeout(random.expovariate(1/5)) # New customer every 5 minutes on average
# Set up and run the simulation
env = simpy.Environment()
bank = Bank(env, num_tellers=3)
num_customers = 100
data = [] # This will hold the customer data
env.process(run_simulation(env, num_customers, bank, data))
env.run()
# Create a DataFrame from the collected data
df = pd.DataFrame(data, columns=['Customer', 'ArrivalTime', 'WaitTime', 'ServiceTime'])
print(df.head())
print(df.describe())The code simulates a bank using the SimPy library. Customers arrive at random intervals, wait for service from one of the three available tellers, and then leave after being served.
The Bank class defines the service time (averaging 10 minutes), while the customer() function tracks each customer’s arrival, waiting time, and service duration. Customers are processed in the run_simulation() function, which generates new arrivals on average every 5 minutes.
Output:
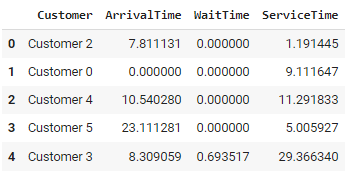
This approach allows for modeling complex and dynamic systems, enabling scenario testing and "what-if" analyses. However, it can become computationally intensive for large-scale simulations and requires a thorough understanding of the modeled system to ensure accurate results.
Generative models like generative adversarial networks (GANs) and variational autoencoders (VAEs) have become popular for creating highly realistic synthetic data. These models learn to capture the underlying distribution of the input data and generate new samples that mimic real-world data.
Both methods are widely used in tasks like image generation and natural language processing, primarily for creating synthetic data for machine learning models when real-world data is scarce or sensitive.
Check out the free course on Generative AI Concepts on Datacamp to learn how generative AI models are developed and how they will impact society in the future.
Several tools are available that make it easier to generate synthetic data for various use cases, ranging from statistical modeling to machine learning and healthcare simulations.
These tools are designed to create data that mirrors the characteristics of real-world datasets, allowing for safe experimentation and testing without exposing sensitive information.
SDV is a Python library that provides a suite of models for generating synthetic data. It supports various data types, including time series, relational data, and tabular data. SDV uses advanced probabilistic models like Gaussian copulas and deep learning methods to learn the structure of the original data and produce high-quality synthetic versions. It’s widely used in machine learning applications for generating synthetic training data when real data is limited or sensitive.
To learn more about generating synthetic data using the SDV library in Python, check out the official GitHub repository or try their official tutorials.
Gretel.AI is a cloud-based platform that offers synthetic data generation and anonymization services. It provides user-friendly APIs and pre-built models that can generate realistic synthetic data based on a variety of inputs, including structured, semi-structured, and unstructured data. Gretel.AI focuses on simplifying the workflow for developers and data scientists, making it easier to generate synthetic data with minimal setup.
Check out Gretel’s quick start to get started with synthetic data generation using Gretel.AI
Synthea is an open-source tool specifically developed for healthcare simulations. It generates synthetic patient records that reflect realistic medical histories, treatments, and outcomes, following medical and clinical standards. Researchers and healthcare institutions often use Synthea to simulate patient populations and study public health trends without using real patient data, making it invaluable for healthcare data analysis.
synthpop is an R package specifically designed to generate synthetic versions of real-world datasets. It works by using statistical models to replicate the relationships and distributions found in the original data, allowing users to safely share and analyze data without compromising confidentiality. synthpop is particularly useful for researchers and institutions that need to release datasets while protecting privacy.
To learn more about generating synthetic data in R using synthpop, check out the Generating Synthetic Data Sets with synthpop in R tutorial.
As previously mentioned, generative AI plays a significant role in creating synthetic data, mainly through advanced models that learn real-world data's underlying patterns and distributions and generate realistic synthetic versions. Let’s explore each of these techniques and their applications.
GANs are one of the most powerful tools for generating synthetic data. They consist of two competing neural networks: a generator and a discriminator. The generator creates synthetic data, while the discriminator attempts to differentiate between real and synthetic data. Through this adversarial process, the generator improves its ability to create highly realistic data. GANs are widely used to generate images, videos, and even tabular data, and they have found applications in fields such as healthcare, autonomous driving, and entertainment.
VAEs are another popular generative model for synthetic data generation. They work by encoding data into a compressed latent space and then decoding it back to its original form. This allows VAEs to generate new data points by sampling from the latent space, making them useful for applications like image synthesis and anomaly detection. While VAEs don’t achieve the same level of realism as GANs, they are more stable during training and provide better control over the structure of the generated data.
Transformers, like GPT models, have revolutionized text generation by producing coherent and contextually accurate sentences and paragraphs. For synthetic data, transformers can generate human-like text that mirrors real-world datasets, such as customer reviews, conversations, or other textual data. These models are particularly useful when generating large volumes of text-based synthetic data for natural language processing (NLP) tasks, but they also have the flexibility to be fine-tuned for specific applications.
To learn the role generative artificial intelligence plays today and will play in the future in a business environment, check out the Generative AI for Business course.
The appropriate synthetic data generation technique depends on your use case, data type, and goals. For simple datasets with well-defined statistical distributions, random data generation or rule-based generation can be sufficient.
If you're dealing with complex, interrelated data or need to preserve relational integrity (e.g., in healthcare or finance), a simulation-based approach or generative models like GANs and VAEs might be more appropriate. Transformer-based models can provide better results for text generation or tasks involving large-scale data.
Consider the trade-offs between ease of implementation, data realism, and computational requirements when choosing a technique.
To demonstrate this example, I have generated a mock patient database of three tables, each with exactly 5,000 records.
Table 1 - Patients
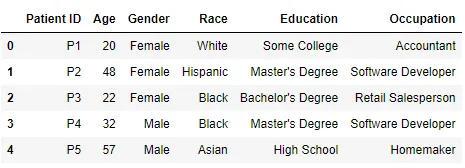
Table 2 - Lab Results
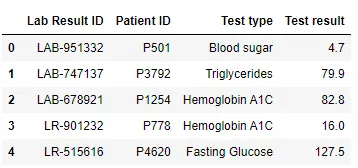
Table 3 - Treatments
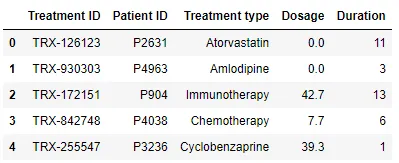
To implement this example, you will have to sign up on Gretel.AI and generate an API key. You will also have to install a library in Python:
!pip install -U gretel-trainerTo implement this use case, we will use RelationalData from the gretel_trainer.relational module. It allows users to automatically define and maintain relationships between multiple tables, ensuring that foreign key dependencies and data integrity are preserved in the synthetic output.
This is particularly useful for generating high-quality synthetic data that mirrors the structure and dependencies of real-world databases, making it easier to use in applications like machine learning, research, or compliance with data privacy regulations.
Code Example:
import pandas as pd
from gretel_client import configure_session
from gretel_trainer.relational import RelationalData
configure_session(api_key="your_api_key", cache="yes", validate=True)
csv_dir = "csv/"
tables = [("patients", "Patient ID"), ("lab_results", "Lab Result ID"), ("treatments", "Treatment ID")]
foreign_keys = [("lab_results.Patient ID", "patients.Patient ID"), ("treatments.Patient ID", "patients.Patient ID")]
relational_data = RelationalData()
for table, pk in tables:
relational_data.add_table(name=table, primary_key=pk, data=pd.read_csv(f"{csv_dir}/{table}.csv"))
for fk, ref in foreign_keys:
relational_data.add_foreign_key(foreign_key=fk, referencing=ref)
from gretel_trainer.relational import MultiTable
multitable = MultiTable(
relational_data,
project_display_name="Clinical Trials",
gretel_model="amplify"
)
multitable.train()
multitable.generate(record_size_ratio=1)
synthetic_patients = multitable.synthetic_output_tables['patients']
synthetic_lab_results = multitable.synthetic_output_tables['lab_results']
synthetic_treatments = multitable.synthetic_output_tables['treatments']
This code uses the Gretel.AI API to generate synthetic data for a relational database. It first sets up a session using an API key and loads three CSV files (patients, lab_results, and treatments), specifying their primary keys and defining foreign key relationships.
The RelationalData class is used to maintain these relationships. After configuring the data, a model is trained using the MultiTable class, which synthesizes the entire relational dataset.
After the model is trained, the generate() method is used to generate synthetic data. The record_size_ratio parameter determines the ratio reference to size of the generated data. record_size_ratio=1 means the number of records in synthetic dataset = original dataset i.e. 5,000 records.
Evaluating the quality of synthetic data is essential to ensure its utility and privacy. Start by comparing statistical distributions between the original and synthetic data—metrics like mean, variance, and correlation should closely match.
Another method is to use synthetic data to train machine learning models and compare their performance (e.g., accuracy or F1 score) to models trained on real data.
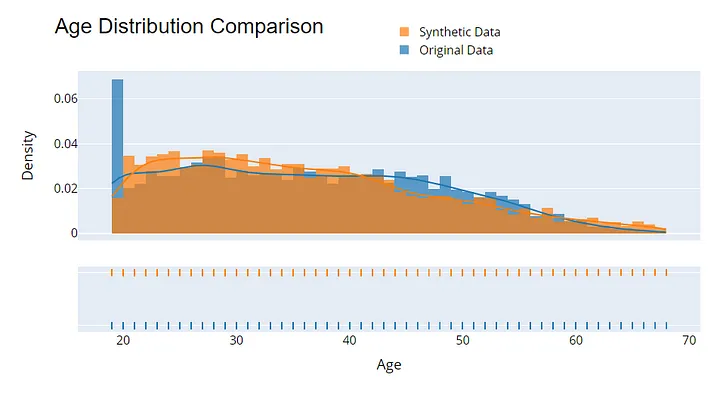
Example visualization to assess the quality of synthetic data. Image by Author.
Synthetic data generation has emerged to address challenges related to data scarcity, privacy concerns, and the need for diverse, high-quality datasets.
With techniques ranging from simple random data generation to advanced generative models like GANs and VAEs, synthetic data enables organizations to innovate and build better machine learning models while safeguarding sensitive information.
Tools like SDV and managed services like Gretel.AI make generating synthetic data more accessible, even for complex relational databases.
As synthetic data generation evolves, its applications will be increasingly important in advancing AI, healthcare, finance, and countless other fields.
Want to dive deeper? Watch the Using Synthetic Data for Machine Learning & AI in Python training to discover what synthetic data is, how it protects privacy, and how it's being used to accelerate AI adoption in banking, healthcare, and many other industries.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.
Learn more about machine learning and AI with the following courses!
Course
Course
Course
blog
Abid Ali Awan
6 min
blog
Kurtis Pykes
10 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
code-along
Alexandra Ebert
code-along
George Boorman




