
Track
AI Fundamentals
10 hr
The attention mechanism sits at the heart of transformer models. All popular model architectures, like GPT, LLaMA, and Mixture of Experts (MoE), rely on it to connect tokens and build meaning.
But attention is expensive. Its computation involves large matrix multiplications and, more importantly, massive data movement between GPU memory and compute units. As sequence lengths grow, memory bandwidth becomes the real bottleneck.
Optimizing attention, therefore, has an outsized impact on LLM performance, and that is exactly where Flash Attention comes in. In this article, I will walk you through what Flash Attention is, how it works, and how to use it with PyTorch and Hugging Face Transformers.
If you are looking for a way to get started with LLMs, I recommend taking our introductory course on LLM concepts.
Flash Attention is an optimized transformer attention mechanism, making it dramatically faster and more memory-efficient on GPUs.
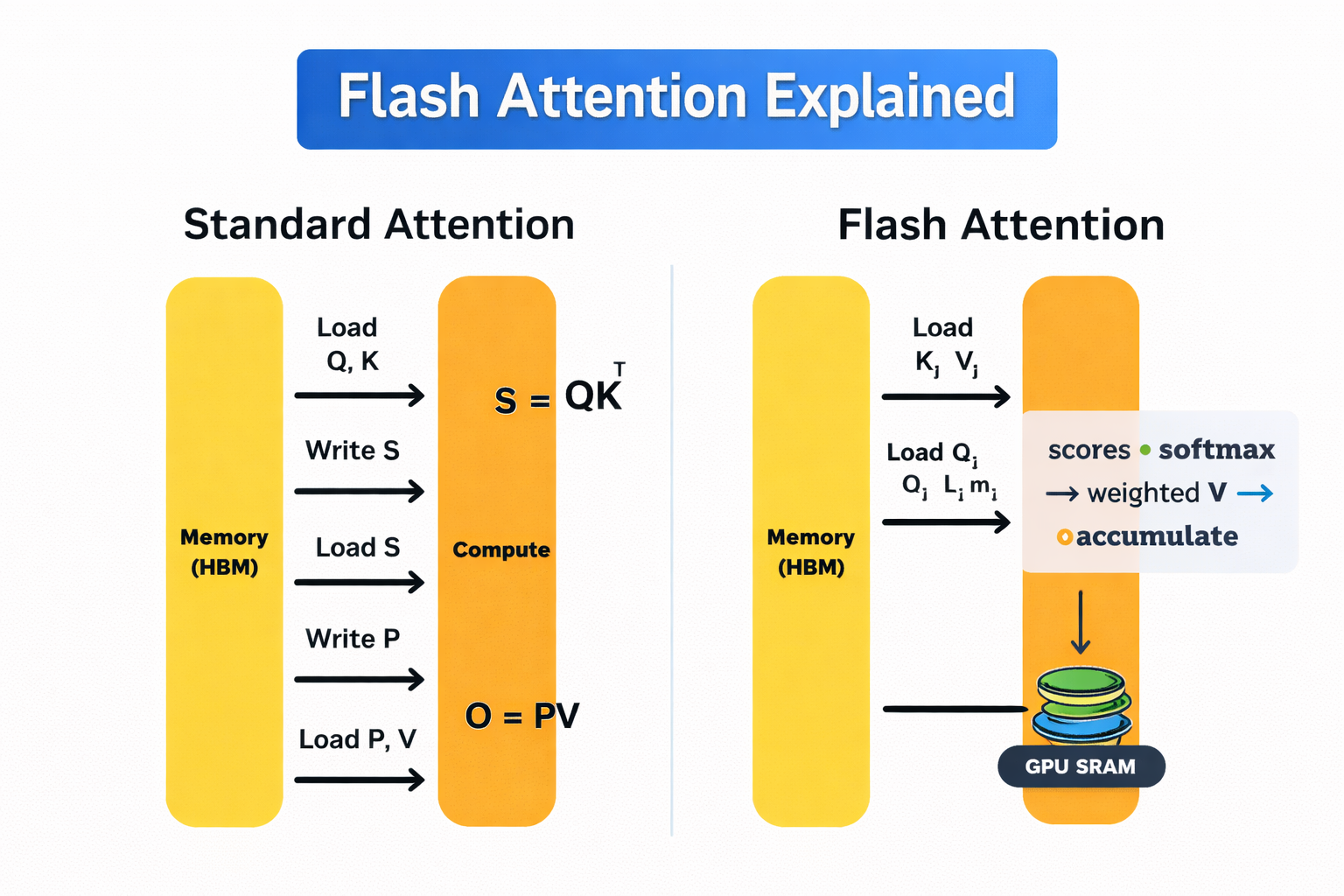
Standard attention vs Flash attention
GPUs have two main memory types. High-bandwidth memory (HBM) is large but relatively slow. On-chip SRAM is extremely fast but very limited in size.
Standard self-attention constantly shuttles data between these two. That back-and-forth is expensive, and it becomes a significant cost as the sequence length grows.
Flash Attention avoids this by computing attention in small tiles that fit entirely within fast SRAM. Each tile is processed end to end, with softmax applied incrementally, so intermediate results do not need to be written back to HBM. Therefore, the full attention matrix is never stored in memory.
Unlike sparse or linear attention methods, Flash Attention is not an approximation. It produces the exact same mathematical output as standard self-attention, just executed in a more memory-efficient way.
Flash Attention achieves its efficiency by redesigning how it computes attention on the GPU. It follows a simple mechanism: do as much work as possible in fast on-chip memory and avoid unnecessary movement to slow memory.
A helpful way to think about this is a kitchen analogy. The GPU’s on-chip SRAM is like a small, fast kitchen counter. It is where you actually prepare and cook. GPU high-bandwidth memory (HBM) is like a large grocery store down the street. It can store everything you need, but going back and forth takes time.
Put simply, standard attention keeps running to the grocery store after every step. In contrast, Flash Attention plans the cooking so everything fits on the counter while you cook. Let’s understand this in more detail:
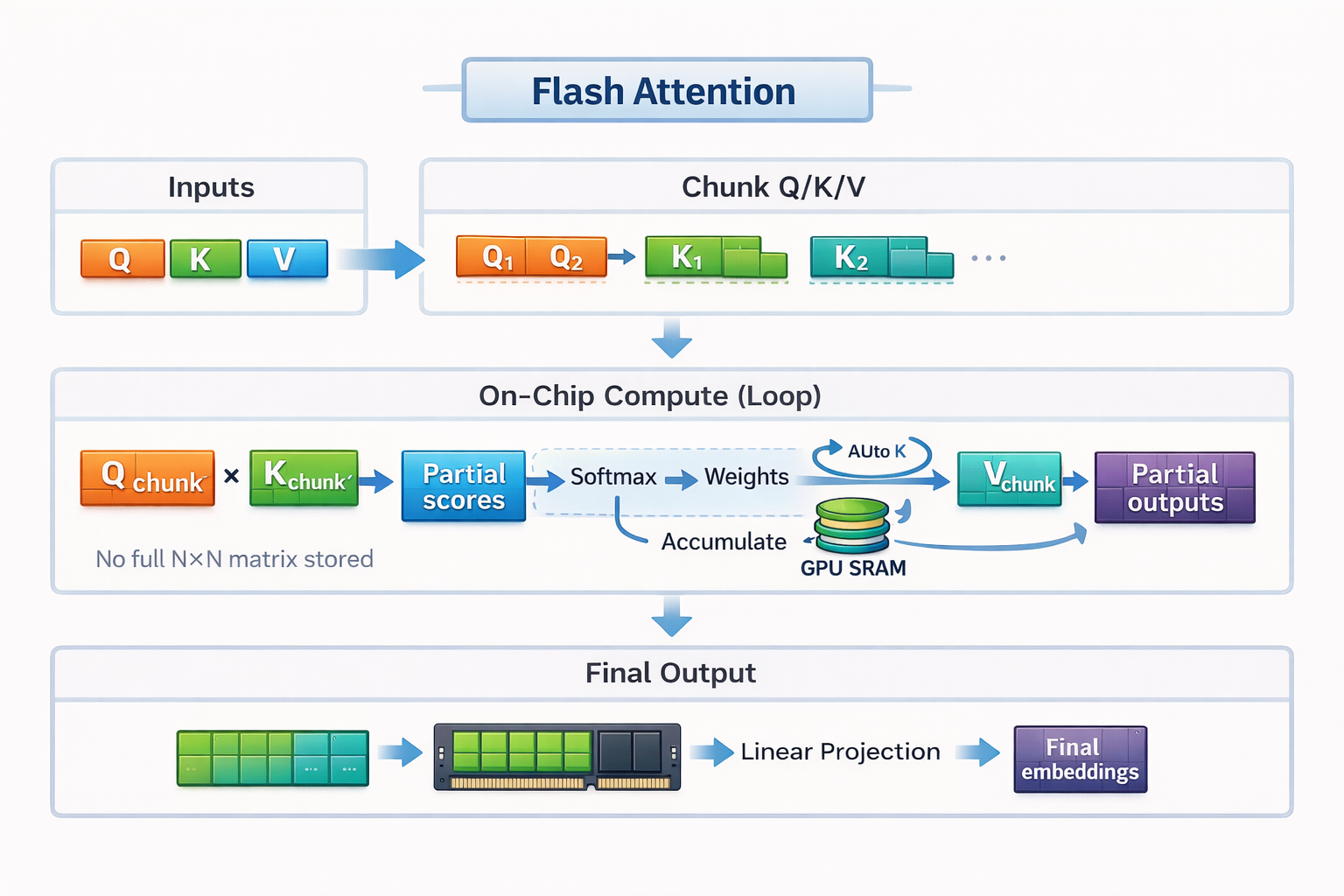
Flash Attention working mechanism
Flash Attention relies on two key ideas: tiling and recomputation.
To stay within our cooking example, tiling is how Flash Attention fits attention computation onto the small counter.
Instead of loading the entire sequence and building a full attention matrix, Flash Attention splits the inputs into small blocks, or tiles. Each tile fits entirely within the GPU’s fast SRAM. Flash Attention computes attention one tile at a time, from start to finish, before moving on to the next tile.
From the kitchen analogy, you cannot fit ingredients for an entire banquet on a small counter. So you prep and cook in small batches. You chop a few vegetables, cook them, clear the space, and then move on to the next batch. By working this way, you avoid constantly running back and forth to the grocery store.
This block-by-block execution lets Flash Attention keep data local, fast, and efficient, without ever materializing the full attention matrix in slow memory.
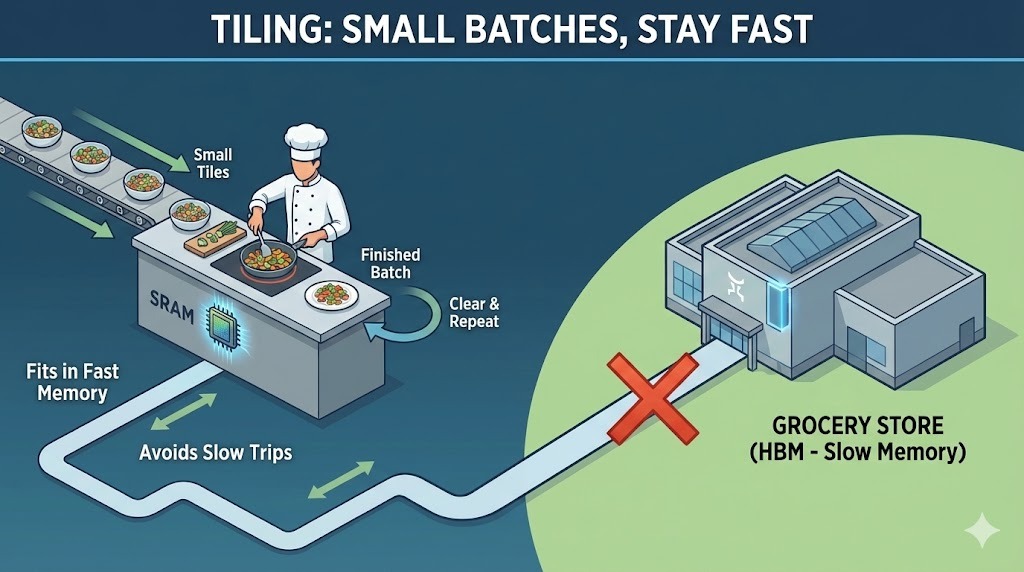
Tiling in Flash Attention
During training, standard attention stores large intermediate results so they can be reused during the backward pass. That storage comes at a high memory cost. Flash Attention takes a different approach. Instead of storing these intermediates, it recomputes small parts of the attention scores whenever they are needed.
Back in the kitchen, this is like chopping onions. You could walk to the grocery store to save your chopped onions and then walk back later to retrieve them. Or you could discard them and simply re-chop a fresh onion when it is time to cook. Surprisingly, the second option is faster because it avoids frequent/longer movements.
On modern GPUs, recomputation follows the same logic because extra computation is cheap compared to memory movements. By recomputing small values instead of storing and loading them, Flash Attention significantly reduces memory traffic while keeping training efficient.
Together, tiling and recomputation allow Flash Attention to keep attention computation on the counter, minimize trips to the grocery store, and fully use the strengths of modern GPU hardware.
Flash Attention 2 (FA2), released in 2023, is a major upgrade over the first generation. It keeps the same core idea of IO-aware, exact attention, but improves efficiency across several dimensions that matter in real-world workloads.
The first version of Flash Attention parallelized computation across the batch size and attention heads. That worked well for training setups with large batches. But it was less ideal for inference, where batch sizes are often small and sequence lengths are long.
FA2 adds parallelism across the sequence length dimension itself. This allows more parts of the attention computation to run simultaneously, even when the batch size is small. By spreading work across tokens in the sequence, v2 keeps more of the GPU’s compute units busy simultaneously.
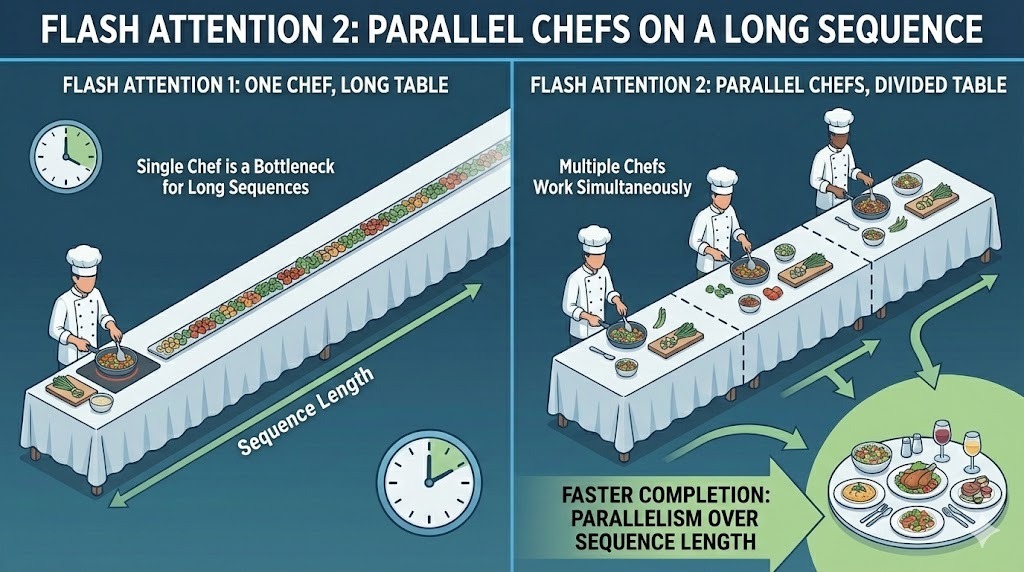
Parallelism across batches in Flash Attention 2
The practical benefit is higher throughput and better hardware utilization in common inference scenarios, where long prompts and small batches are the norm.
GPUs are extremely good at matrix multiplication. Specialized hardware called Tensor Cores can execute general matrix multiplication (GEMM) operations at very high speed.
The problem is that attention is not just matrix multiplication: it involves operations like scaling, masking, and softmax, which run on standard GPU cores and are much slower by comparison.
FA2 reduced this imbalance. It restructures the computation to minimize non-matrix floating point operations, especially those involved in rescaling attention scores. Most of the runtime is spent inside large, efficient matrix operations that Tensor Cores can accelerate.
Flash Attention v1 was optimized around head dimensions of 64 or 128, which matched models like BERT and GPT-3. As model architectures evolved, head dimensions grew larger to support bigger embedding sizes and higher model capacity.
FA2 expanded support to head dimensions up to 256. This made it compatible with newer architectures that rely on wider attention heads.
Flash Attention 3 (FA3) is the current industry standard powering state-of-the-art models like GPT-5.2. It builds on the same IO-aware, exact attention foundation as earlier versions, but it is architected specifically for NVIDIA H100 (Hopper) GPUs.
The key shift is that FA3 is designed to exploit Hopper’s new asynchronous hardware features, allowing memory movement and computation to overlap far more aggressively than before.
In earlier versions, all GPU threads, known as warps, followed the same execution path. FA3 changes this model through warp specialization. It assigns one of two distinct roles to each warp:
This separation allows data transfer and computation to happen at the same time. While producer warps fetch the next tiles of data, consumer warps stay busy computing on the current tiles, significantly improving the latency
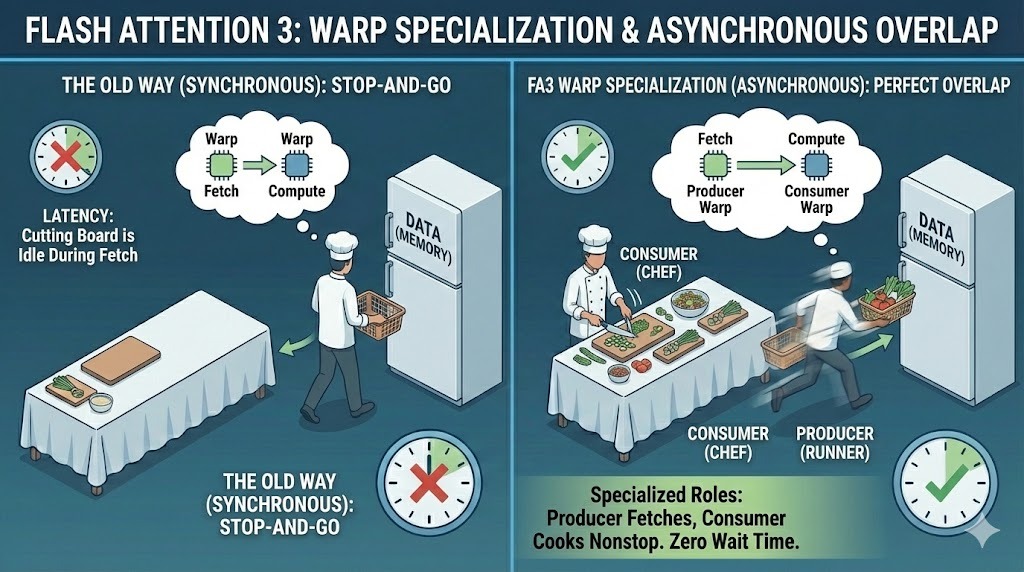
Warp specialization in Flash Attention 3
Flash Attention 3 also introduces native support for FP8, or 8-bit floating point precision. Earlier versions primarily relied on FP16 or BF16, which already reduced memory usage compared to FP32, but still consumed significant bandwidth.
FP8 cuts the memory footprint roughly in half again. This reduction directly translates into higher throughput and lower memory pressure. On Hopper GPUs, FP8 is hardware-accelerated, which means FA3 can process more attention operations per second without sacrificing accuracy at the model level.
This capability is a major reason large models like Gemini 3 can handle massive context windows while serving millions of users efficiently.
A final piece of the FA3 design is its use of the H100’s Tensor Memory Accelerator, or TMA. The TMA is specialized hardware that handles memory copies asynchronously, without occupying the main compute cores.
Flash Attention 3 uses TMA to move tiles of data in the background while computation continues uninterrupted. By tightly overlapping memory movement with math, FA3 is able to extract close to 75 percent of the hardware’s theoretical peak performance.
Flash Attention 4 (FA4) represents the next experimental step in attention optimization. It is designed for NVIDIA’s upcoming Blackwell B200 GPUs and explores what becomes possible when attention kernels are built for an entirely new class of hardware.
As model sizes continue to grow and training runs move toward the trillion-parameter scale, even Flash Attention 3 will eventually hit limits. FA4 is an early attempt to remove those limits by pushing hardware utilization further than any previous attention kernel.
At this stage, Flash Attention 4 is a research and pre-production technology. It shows strong promise, but it is not yet used in deployed or production-grade models.
One of the major milestones of Flash Attention 4 is performance. It is the first attention kernel designed to exceed 1 PFLOPS, or one quadrillion floating-point operations per second, on a single GPU.
It targets a future where training trillion-parameter models would take impractical amounts of time to finish. At that scale, even small inefficiencies compound into massive delays. FA4 aims to make those future training runs feasible by extracting extreme performance from a single chip.
To reach that performance, FA4 pushes asynchrony much further than previous versions. It extends the producer-consumer model into highly complex, multi-stage pipelines where data movement, computation, and synchronization all operate independently.
Instead of a relatively simple overlap between loading and computing, FA4 manages deeply asynchronous execution across multiple stages. Different parts of the kernel progress at different speeds, coordinated by hardware-level scheduling rather than a single synchronized flow.
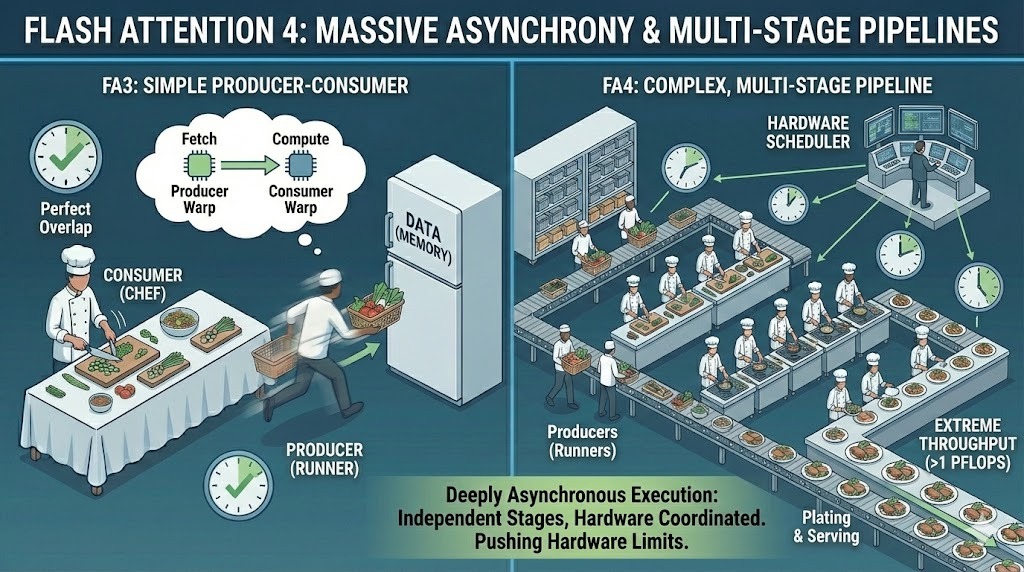
Massive asynchrony in Flash Attention 4
This complexity is also why FA4 remains experimental. Managing accuracy, stability, and integration at this level is challenging. The community still needs more work before teams can reliably use it inside large production models.
Let’s see how Flash Attention compares to the standard attention mechanism in a few key domains.
Benchmarks consistently show that all Flash Attention versions outperform standard self-attention, with gains increasing as sequence length grows.
The original Flash Attention paper reports roughly 2 to 4× speedups over optimized standard attention. Flash Attention 2 improves on this further by increasing parallelism and better saturating the GPU, often delivering another ~2× improvement in practice.
Flash Attention 3 pushes performance even further on Hopper GPUs, especially with FP8, achieving much higher hardware utilization than standard attention can reach.
Standard attention explicitly materializes the full N × N attention matrix, which leads to quadratic memory growth with respect to sequence length. As N grows, memory usage explodes, quickly overwhelming GPU memory. Flash Attention avoids storing this matrix entirely.
By computing attention in tiles and keeping intermediate results in fast on-chip memory, it reduces memory usage to linear in sequence length for fixed head dimensions. This shift from quadratic to linear memory scaling removes the largest structural bottleneck in standard attention.
That memory reduction directly enables longer context windows. With standard attention, models often hit out-of-memory errors once sequences reach a few thousand tokens.
Flash Attention makes 4k and 8k token contexts practical on a single GPU, and even unlocks much longer windows, such as 16k or 32k tokens, on that one device when combined with other memory-saving techniques.
Don’t get confused here: The massive million-token windows achieved in some current frontier models like Gemini 3 are achieved by splitting the sequence across large clusters of GPUs, as they far exceed the memory capacity of any single device.
Using Flash Attention today is much simpler than it used to be. In most cases, you do not need to write custom CUDA kernels or change your model architecture. The support is already built into the popular tools today.
Since PyTorch 2.0, Flash Attention is available directly through torch.nn.functional.scaled_dot_product_attention. When you call this function, PyTorch automatically selects the fastest available attention backend for your hardware.
On supported GPUs, that backend is Flash Attention. From the user’s perspective, it often looks like standard attention code, but under the hood PyTorch dispatches an optimized Flash Attention kernel.
If you are using Hugging Face Transformers, enabling Flash Attention is usually a one-line change. Setting attn_implementation="flash_attention_2" in the model configuration tells the library to use Flash Attention 2 wherever possible.
For many transformer models, this is enough to get both speed and memory improvements without touching the rest of the training or inference code.
Flash Attention 2 targets modern NVIDIA GPUs and runs best on Ampere, Ada, and Hopper architectures, including the A100, RTX 3090, RTX 4090, and H100. These GPUs provide the memory bandwidth and architectural features needed to fully benefit from the tiling and parallelism in FA2.
It is also worth noting that the original Flash Attention v1 supports older GPUs as well. Turing-based cards like the T4 and RTX 2080 can still use Flash Attention v1, although the newer versions require more recent hardware to unlock their full performance gains.
In practice, if you are already using PyTorch 2.x or Hugging Face Transformers on a modern NVIDIA GPU, Flash Attention is often just a configuration switch away.
Standard attention hit a hard wall because quadratic memory growth made long sequences slow, expensive, or simply impossible due to out-of-memory failures. Flash Attention changed that by redesigning how attention is executed.
By reducing memory usage from quadratic to linear with respect to sequence length, Flash Attention makes long-context modeling practical. Context windows that once overwhelmed GPUs at a few thousand tokens now scale to 4k, 8k, and even 32k-plus tokens on the same hardware.
If you are working with transformers at scale and not using Flash Attention, you are almost certainly leaving performance on the table.
Eager to build own models that can use Flash Attention? Take our course on transformer models with PyTorch!
AI Courses
Track
Course
Course
blog
Yesha Shastri
8 min
blog
François Aubry
8 min
Tutorial
Vaibhav Mehra
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Vaibhav Mehra


