
Cours
Concepts d'IA générative
2 h
105.1K
L'un des principaux avantages des méthodes de gradient de politique est leur capacité à gérer des espaces d'action complexes, là où les approches traditionnelles basées sur la valeur rencontrent des difficultés.
Les méthodes basées sur la valeur, telles que l'apprentissage Q, fonctionnent en estimant la fonction de valeur pour toutes les actions possibles. Cela devient difficile lorsque l'espace d'action de l'environnement est soit continu, soit discret, mais étendu.
Les méthodes de gradient de politique paramètrent la politique et estiment le gradient des récompenses cumulées en fonction desparamètres de la politique. Ils utilisent ce gradient pour optimiser directement la politique en mettant à jour ses paramètres. Ils peuvent donc traiter efficacement des espaces d'action à haute dimension ou continus. Les gradients de politique sont également à la base des méthodes d'apprentissage par renforcement utilisant la rétroaction humaine (RLHF).
En paramétrant la politique et en ajustant ses paramètres sur la base des gradients, les gradients de politique peuvent traiter efficacement des actions continues et à haute dimension. Cette approche directe permet une meilleure généralisation et une exploration plus souple, ce qui la rend bien adaptée à des tâches telles que le contrôle robotique et d'autres environnements complexes.
Compte tenu d'un ensemble d'observations :
Dans le cadre d'une politique stochastique, la même observation peut conduire à choisir des actions différentes selon les itérations. Cela favorise l'exploration de l'espace d'action et empêche la politique de rester bloquée dans des optima locaux. C'est pourquoi les politiques stochastiques sont utiles dans les environnements où l'exploration est essentielle pour découvrir le chemin qui mène au rendement maximal.
Dans les méthodes fondées sur la politique, les résultats de la politique sont convertis en une distribution de probabilités, chaque action possible étant assortie d'une probabilité. L'agent choisit une action en échantillonnant cette distribution, ce qui permet de mettre en œuvre une politique stochastique. Ainsi, les méthodes de gradient de politique combinent l'exploration et l'exploitation, ce qui est utile dans les environnements présentant des structures de récompense complexes.
Avant de plonger dans la dérivation, il est important d'établir la notation mathématique et les concepts clés utilisés tout au long de la preuve.
Comme mentionné dans une section précédente, le théorème du gradient de politique stipule que la dérivée du rendement attendu est l'espérance du produit du rendement et de la dérivée du logarithme de la politique.
Avant de dériver le théorème du gradient de politique, nous introduisons la notation :
Nous montrons comment dériver et prouver le théorème du gradient de la politique à partir des premiers principes, en commençant par l'expansion de la fonction objective et en utilisant l'astuce de la dérivée logarithmique.
La fonction objective de la méthode du gradient de politique est le rendement
J accumulée en suivant la trajectoire basée sur la politique π exprimée en termes de paramètres θ. Cette fonction objective est donnée comme suit :
![]()
Dans l'équation ci-dessus :
Différenciation (par rapport à θ) les deux côtés de l'équation ci-dessus donne :
![]()
L'espérance (sur la droite) peut être exprimée comme une intégrale sur le produit de :
Ainsi, la partie droite de l'équation 2 est reformulée comme suit :
![]()
Le gradient d'une intégrale est égal à l'intégrale du gradient. Ainsi, dans l'expression ci-dessus, nous pouvons apporter le gradient ∇θ sous le signe de l'intégrale. Ainsi, la droite devient :
![]()
L'équation 2 peut donc être réécrite comme suit :
![]()
Nous allons maintenant examiner de plus près P(τ|θ), la probabilité que l'agent suive la trajectoire τ compte tenu des paramètres de politique θ (et donc de la politique πθ). Une trajectoire est constituée d'un ensemble d'étapes. Ainsi :
![]()
Ainsi, à partir d'un état initial s0la probabilité que l'agent suive la trajectoire τ sur la base de la politique πθ est donnée comme suit :
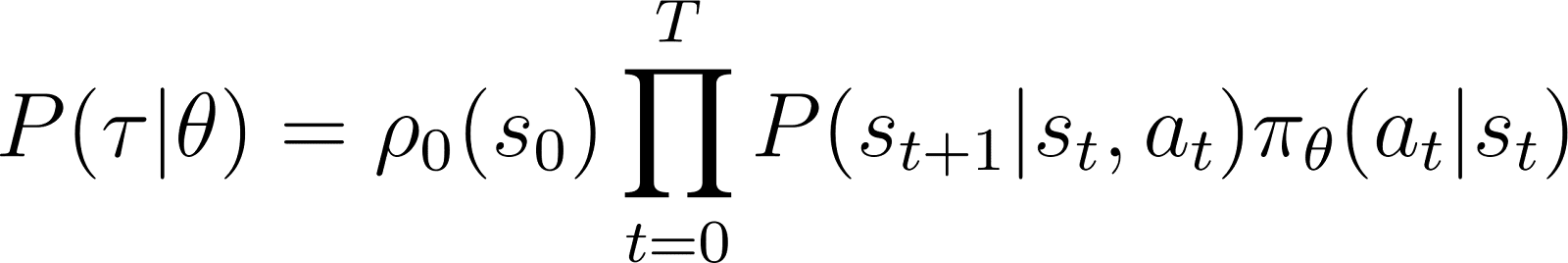
Pour simplifier les choses, nous voulons exprimer le produit dans la ligne droite ci-dessus sous la forme d'une somme. Nous prenons donc le logarithme des deux côtés de l'équation ci-dessus :
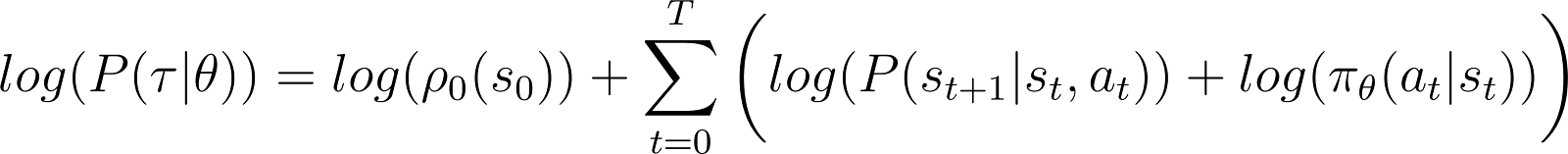
Nous prenons maintenant la dérivée (par rapport à θ) de la probabilité logarithmique dans l'équation ci-dessus.
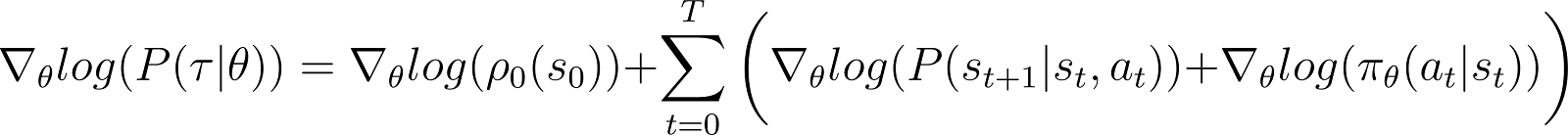
Sur la droite (RHS) de l'équation ci-dessus :
En supprimant les termes zéro de l'équation, nous obtenons l'équation 5 :
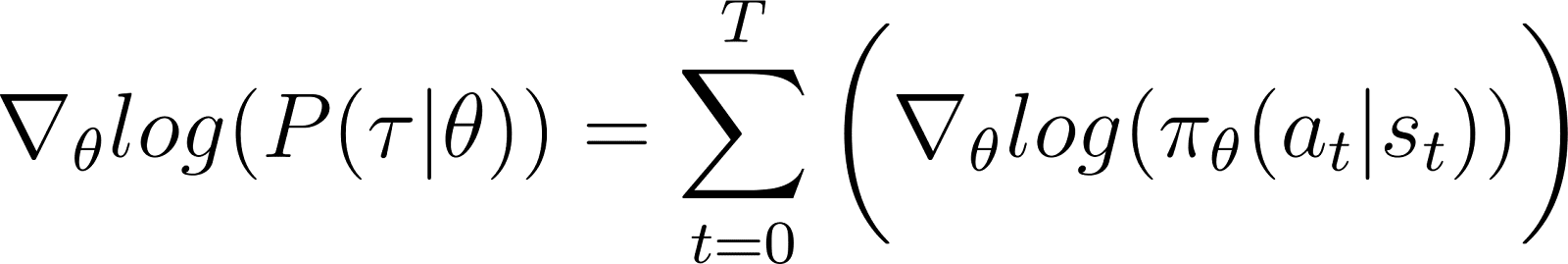
Rappelons que l'équation 2 indique que :
![]()
L'équation 5 évalue le logarithme de la première partie de la droite de l'équation 2. Nous devons relier la dérivée d'un terme à son logarithme. Pour ce faire, nous utilisons la règle de la chaîne et l'astuce de la dérivée logarithmique.
Nous faisons un détour et utilisons les règles du calcul pour obtenir un résultat qui nous permettra de simplifier l'équation précédente et de la rendre compatible avec les méthodes de calcul.
En calcul, la dérivée d'un logarithme peut être exprimée comme suit :
![]()
Ainsi, en réarrangeant l'équation ci-dessus, la dérivée de x peut être exprimée en termes de dérivée du logarithme de x :
![]()
C'est ce qu'on appelle parfois l'astuce du log-dérivé.
Selon la règle de la chaîne, étant donné z(y) en tant que fonction de yoù y est une fonction de θ, y(θ)la dérivée de z par rapport à θ est donnée comme suit :
![]()
Dans ce cas, y(θ) représente P(θ) et z(y) représente le log(y). Ainsi,
![]()
Le calcul nous apprend que d(log(y)) / dy = 1/y. Utilisez ceci dans la première expression de la droite ci-dessus.
![]()
Déplacements y vers la LHS et utilisez la notation et utilisez la notation
![]()
y représente P(θ). L'équation ci-dessus est donc équivalente à :
![]()
Le résultat ci-dessus donne la première expression de la droite de l'équation 2 (voir ci-dessous).
![]()
En utilisant le résultat dans la partie droite de l'équation 2, nous obtenons :
![]()
Nous réarrangeons les termes sous l'intégrale RHS comme suit :
![]()
Observez que l'expression ci-dessus contient l'expansion intégrale d'une espérance : ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Ainsi, la droite ci-dessus peut être exprimée comme l'espérance :
![]()
Nous remplaçons la dérivée de la probabilité logarithmique par l'expression de la récompense attendue :
![]()
Dans l'équation ci-dessus, remplacez la valeur de ∇logP(θ) de l'équation 5 pour obtenir :
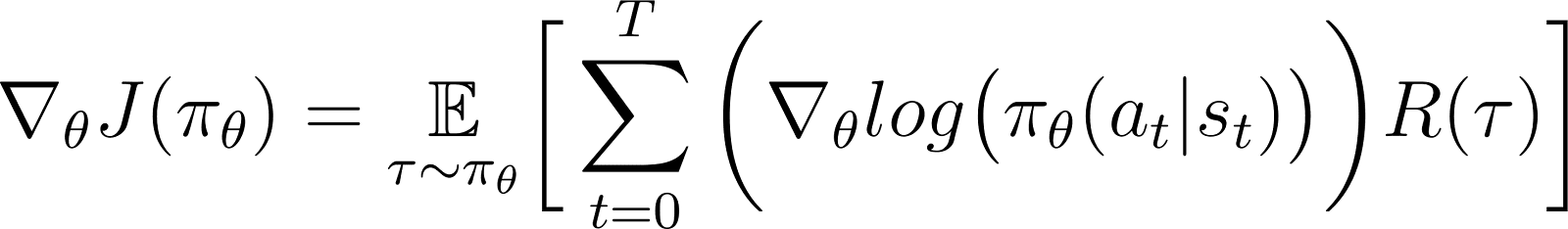
C'est l'expression du gradient de la fonction de récompense selon le théorème du gradient de la politique.
Les méthodes de gradient de politique convertissent les résultats de la politique en une distribution de probabilité. L'agent échantillonne cette distribution pour choisir une action. Les méthodes de gradient de politique ajustent les paramètres de la politique. Cela conduit à mettre à jour cette distribution de probabilité à chaque itération. La distribution de probabilités actualisée a une plus grande probabilité de choisir des actions qui conduisent à des récompenses plus élevées.
L'algorithme du gradient de la politique calcule le gradient du rendement attendu en fonction des paramètres de la politique. En déplaçant les paramètres de la politique dans la direction de ce gradient, l'agent augmente la probabilité de choisir des actions qui se traduisent par des récompenses plus élevées au cours de la formation.
Essentiellement, les actions qui ont conduit à de meilleurs résultats sont plus susceptibles d'être choisies à l'avenir, ce qui améliore progressivement la politique visant à maximiser les récompenses à long terme.
Apprenez-en plus sur l'IA grâce à ces cours !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach