
Kurs
Konzeptuelle Einführung in generative KI
2 Std.
105.1K
Ein entscheidender Vorteil der Gradientenmethoden ist, dass sie mit komplexen Handlungsräumen umgehen können, in denen traditionelle wertorientierte Ansätze Schwierigkeiten haben.
Wertbasierte Methoden, wie das Q-Learning, arbeiten mit der Schätzung der Wertfunktion für alle möglichen Aktionen. Das wird schwierig, wenn der Aktionsraum der Umwelt entweder kontinuierlich oder diskret, aber groß ist.
Policy-Gradienten-Methoden parametrisieren die Politik und schätzen den Gradienten der kumulativen Belohnungen in Bezug auf diePolitikparameter. Sie nutzen diesen Gradienten, um die Strategie direkt zu optimieren, indem sie ihre Parameter aktualisieren. Daher können sie effizient mit hochdimensionalen oder kontinuierlichen Aktionsräumen umgehen. Policy-Gradienten sind auch die Grundlage für Reinforcement Learning using Human Feedback (RLHF) Methoden.
Durch die Parametrisierung der Politik und die Anpassung ihrer Parameter auf Basis von Gradienten können Politikgradienten effizient mit kontinuierlichen und hochdimensionalen Aktionen umgehen. Dieser direkte Ansatz ermöglicht eine bessere Verallgemeinerung und flexiblere Erkundung, was ihn für Aufgaben wie die Steuerung von Robotern und andere komplexe Umgebungen geeignet macht.
Gegeben eine Reihe von Beobachtungen:
Wenn du eine stochastische Politik verfolgst, kann dieselbe Beobachtung dazu führen, dass du in verschiedenen Iterationen unterschiedliche Aktionen wählst. Dies fördert die Erkundung des Aktionsraums und verhindert, dass die Politik in lokalen Optima stecken bleibt. Aus diesem Grund sind stochastische Strategien in Umgebungen nützlich, in denen die Erkundung von entscheidender Bedeutung ist, um den Weg zu finden, der zur maximalen Rendite führt.
Bei richtlinienbasierten Methoden werden die Ergebnisse der Richtlinien in eine Wahrscheinlichkeitsverteilung umgewandelt, wobei jeder möglichen Aktion eine Wahrscheinlichkeit zugeordnet wird. Der Agent wählt eine Aktion, indem er eine Stichprobe aus dieser Verteilung nimmt, wodurch es möglich ist, eine stochastische Politik umzusetzen. Policy-Gradient-Methoden kombinieren also Exploration mit Exploitation, was in Umgebungen mit komplexen Belohnungsstrukturen nützlich ist.
Bevor du dich mit der Herleitung beschäftigst, ist es wichtig, die mathematische Notation und die Schlüsselkonzepte, die im gesamten Beweis verwendet werden, festzulegen.
Wie in einem früheren Abschnitt erwähnt, besagt das Policy-Gradient-Theorem, dass die Ableitung der erwarteten Rendite die Erwartung des Produkts aus der Rendite und der Ableitung des Logarithmus der Policy ist.
Bevor wir das Theorem des politischen Gradienten ableiten, führen wir die Notation ein:
Wir zeigen, wie man das Gradiententheorem aus ersten Prinzipien ableitet und beweist, indem wir mit der Erweiterung der Zielfunktion beginnen und den Trick der logarithmischen Ableitung anwenden.
Die Zielfunktion bei der Policy-Gradient-Methode ist die Rendite
J, die sich durch das Verfolgen der Flugbahn auf der Grundlage der Politik π , ausgedrückt durch die Parameter θ, ergeben. Diese Zielfunktion wird wie folgt angegeben:
![]()
In der obigen Gleichung:
Differenzieren (in Bezug auf θ) beider Seiten der obigen Gleichung ergibt:
![]()
Der Erwartungswert (auf der rechten Seite) kann als Integral über das Produkt von ausgedrückt werden:
Die rechte Seite von Gleichung 2 wird also wie folgt umformuliert:
![]()
Die Steigung eines Integrals ist gleich dem Integral der Steigung. Im obigen Ausdruck können wir also den Gradienten ∇θ unter das Vorzeichen des Integrals stellen. Die RHS wird also:
![]()
Gleichung 2 kann also wie folgt umgeschrieben werden:
![]()
Wir werfen nun einen genaueren Blick auf P(τ|θ), die Wahrscheinlichkeit, dass der Agent bei gegebenen Politikparametern θ (und damit bei der Politik πθ) der Trajektorie τ folgt. Eine Flugbahn besteht aus einer Reihe von Schritten. So:
![]()
Ausgehend von einem Anfangszustand s0die Wahrscheinlichkeit, dass der Agent der Trajektorie τ basierend auf der Politik πθ ist gegeben als:
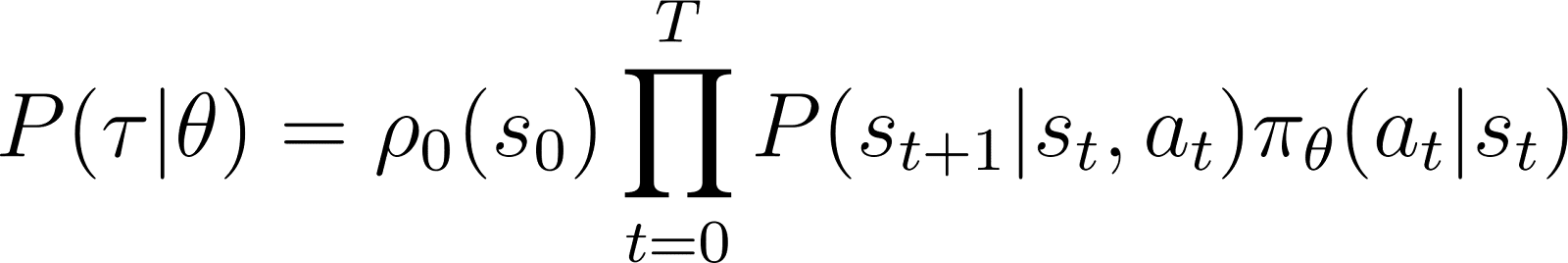
Um die Sache zu vereinfachen, wollen wir das Produkt in der rechten Spalte als Summe ausdrücken. Wir nehmen also den Logarithmus auf beiden Seiten der obigen Gleichung:
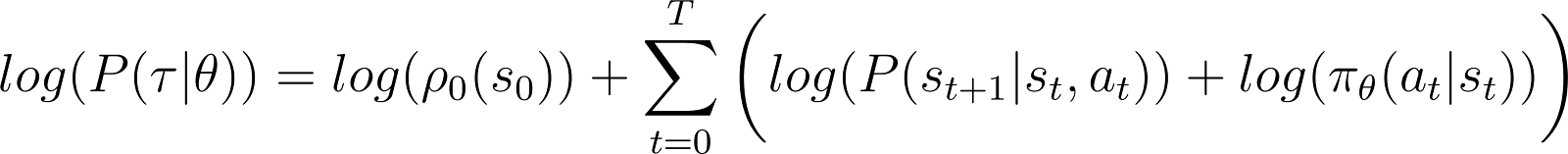
Wir nehmen nun die Ableitung (nach θ) der logarithmischen Wahrscheinlichkeit in der obigen Gleichung.
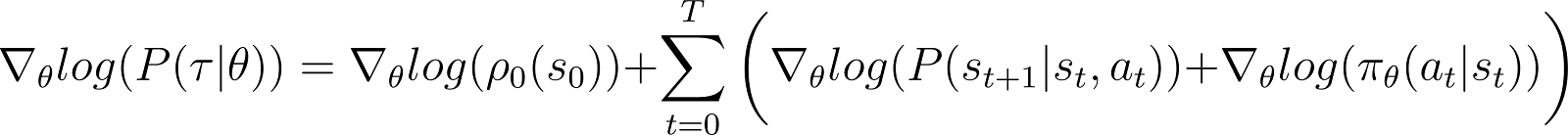
Auf der rechten Seite der obigen Gleichung:
Wenn wir die oben genannten Nullterme aus der Gleichung entfernen, bleibt (Gleichung 5) übrig:
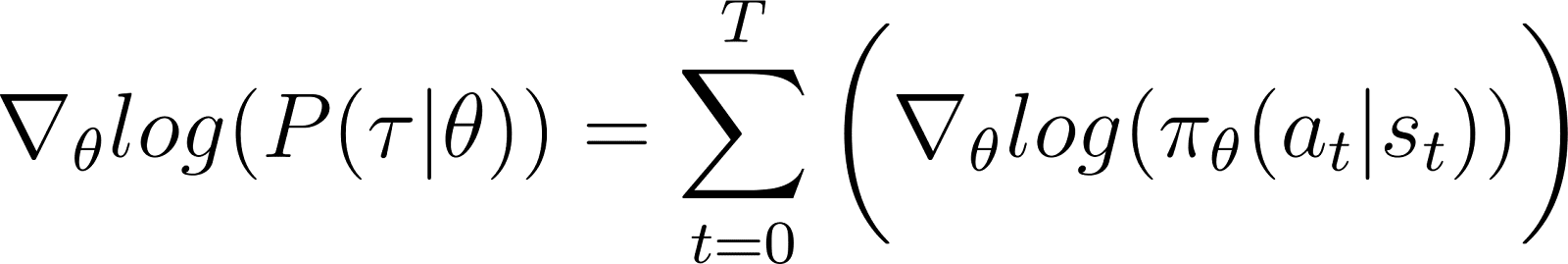
Erinnere dich an Gleichung 2, dass:
![]()
Gleichung 5 wertet den Logarithmus des ersten Teils der rechten Seite von Gleichung 2 aus. Wir müssen die Ableitung eines Terms mit seinem Logarithmus in Beziehung setzen. Dazu verwenden wir die Kettenregel und den Trick mit der logarithmischen Ableitung.
Wir machen einen Umweg und nutzen die Regeln der Infinitesimalrechnung, um ein Ergebnis herzuleiten, mit dem wir die vorherige Gleichung vereinfachen und für Berechnungsmethoden nutzbar machen wollen.
In der Infinitesimalrechnung kann die Ableitung eines Logarithmus wie folgt ausgedrückt werden:
![]()
Durch Umstellen der obigen Gleichung ergibt sich also die Ableitung von x durch die Ableitung des Logarithmus von x ausgedrückt werden:
![]()
Dies wird manchmal auch als Trick mit der logarithmischen Ableitung bezeichnet.
Nach der Kettenregel gilt für z(y) als eine Funktion von y, wobei y selbst eine Funktion von θ ist, y(θ), die Ableitung von z in Bezug auf θ ist gegeben als:
![]()
In diesem Fall, y(θ) steht für P(θ) und z(y) steht für log(y). Thus,
![]()
Aus der Infinitesimalrechnung wissen wir, dass d(log(y)) / dy = 1/y. Verwende dies im ersten Ausdruck der rechten Seite oben.
![]()
verschieben y auf die linke Seite und verwende die Notation:
![]()
y steht für P(θ). Die obige Gleichung ist also gleichbedeutend mit:
![]()
Das obige Ergebnis ergibt den ersten Ausdruck der rechten Seite von Gleichung 2 (siehe unten).
![]()
Mit dem Ergebnis auf der rechten Seite von Gleichung 2 erhalten wir:
![]()
Wir ordnen die Terme unter dem RHS-Integral wie folgt um:
![]()
Beachte, dass der obige Ausdruck die Integralentwicklung eines Erwartungswertes enthält: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Die rechte Hand kann also als Erwartung ausgedrückt werden:
![]()
Wir setzen die Ableitung der logarithmischen Wahrscheinlichkeit in den Ausdruck für die erwartete Belohnung ein:
![]()
Setze in die obige Gleichung den Wert von ∇logP(θ) aus Gleichung 5 ein, um zu erhalten:
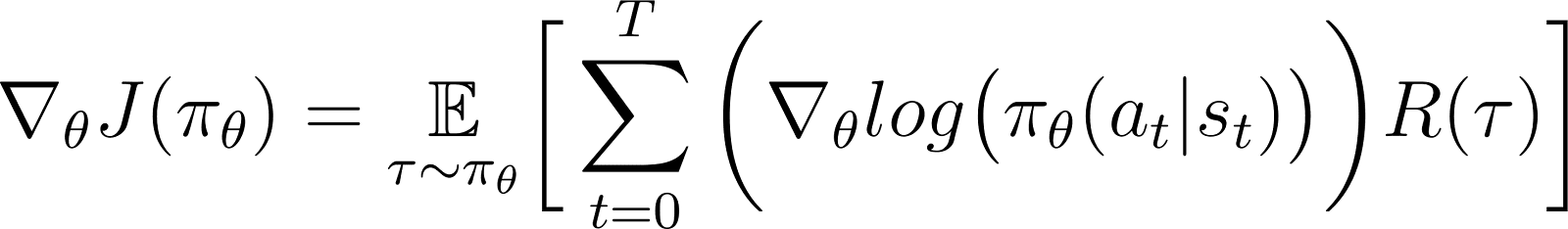
Dies ist der Ausdruck für den Gradienten der Belohnungsfunktion nach dem Policy-Gradient-Theorem.
Policy-Gradienten-Methoden wandeln den Output der Policy in eine Wahrscheinlichkeitsverteilung um. Der Agent nimmt eine Stichprobe dieser Verteilung, um eine Aktion auszuwählen. Policy-Gradienten-Methoden passen die Policy-Parameter an. Das führt dazu, dass diese Wahrscheinlichkeitsverteilung in jeder Iteration aktualisiert wird. Die aktualisierte Wahrscheinlichkeitsverteilung hat eine höhere Wahrscheinlichkeit, Aktionen zu wählen, die zu höheren Belohnungen führen.
Der Policy-Gradient-Algorithmus berechnet den Gradienten der erwarteten Rendite in Abhängigkeit von den Policy-Parametern. Indem er die Parameter der Strategie in Richtung dieses Gradienten verschiebt, erhöht der Agent die Wahrscheinlichkeit, dass er Aktionen wählt, die im Training zu höheren Belohnungen führen.
Das bedeutet, dass Handlungen, die zu besseren Ergebnissen führen, in Zukunft mit größerer Wahrscheinlichkeit gewählt werden, wodurch die Politik schrittweise verbessert wird, um den langfristigen Nutzen zu maximieren.
Lerne mehr über KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
