
Course
Generative AI Concepts
2 hr
105.1K
One key advantage of policy gradient methods is their ability to handle complex action spaces, where traditional value-based approaches struggle.
Value-based methods, such as Q-learning, work by estimating the value function for all possible actions. This becomes difficult when the environment’s action space is either continuous or discrete but large.
Policy gradient methods parametrize the policy and estimate the gradient of the cumulative rewards with respect to the policy parameters. They use this gradient to directly optimize the policy by updating its parameters. Hence, they can efficiently handle high-dimensional or continuous action spaces. Policy gradients are also the basis of Reinforcement Learning using Human Feedback (RLHF) methods.
By parameterizing the policy and adjusting its parameters based on gradients, policy gradients can efficiently handle continuous and high-dimensional actions. This direct approach enables better generalization and more flexible exploration, making it well-suited for tasks like robotic control and other complex environments.
Given a set of observations:
When following a stochastic policy, the same observation can lead to choosing different actions in different iterations. This promotes exploration of the action space and prevents the policy from getting stuck in local optima. Because of this, stochastic policies are useful in environments where exploration is essential to discovering the path that leads to the maximum returns.
In policy-based methods, the policy output is converted into a probability distribution, with each possible action assigned a probability. The agent chooses an action by sampling this distribution, making it possible to implement a stochastic policy. Thus, policy gradient methods combine exploration with exploitation, useful in environments with complex reward structures.
Before diving into the derivation, it’s important to establish the mathematical notation and key concepts used throughout the proof.
As mentioned in a previous section, the policy gradient theorem states that the derivative of the expected return is the expectation of the product of the return and the derivative of the logarithm of the policy.
Before deriving the policy gradient theorem, we introduce the notation:
We show how to derive and prove the policy gradient theorem from first principles, starting with the expansion of the objective function and using the log-derivative trick.
The objective function in the policy gradient method is the return
J accumulated by following the trajectory based on the policy π expressed in terms of parameters θ. This objective function is given as:
![]()
In the above equation:
Differentiating (with respect to θ) both sides of the above equation gives:
![]()
The expectation (on the RHS) can be expressed as an integral over the product of:
Thus, the RHS of Equation 2 is restated as:
![]()
The gradient of an integral is equal to the integral of the gradient. So, in the above expression, we can bring the gradient ∇θ under the integral sign. So, the RHS becomes:
![]()
Thus, Equation 2 can be re-written as:
![]()
We now take a closer look at P(τ|θ), the probability of the agent following trajectory τ given policy parameters θ (and hence policy πθ). A trajectory consists of a set of steps. Thus:
![]()
Thus, starting from an initial state s0, the probability of the agent following trajectory τ based on policy πθ is given as:
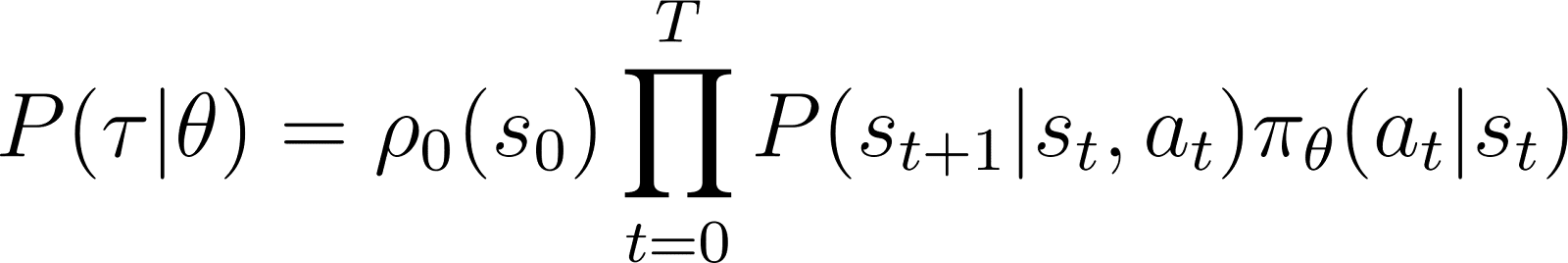
To make things simpler, we want to express the product in the RHS above as a sum. So, we take the logarithm on both sides of the above equation:
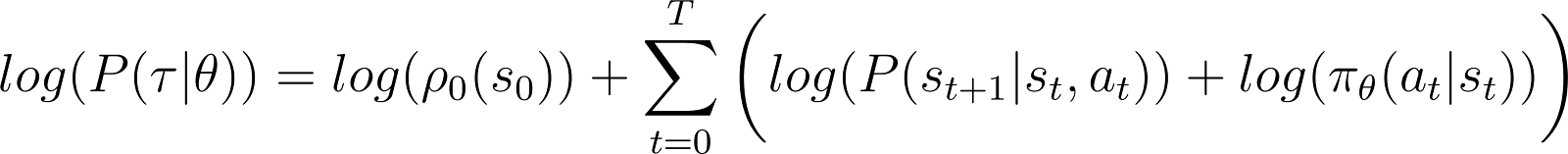
We now take the derivative (with respect to θ) of the log probability in the above equation.
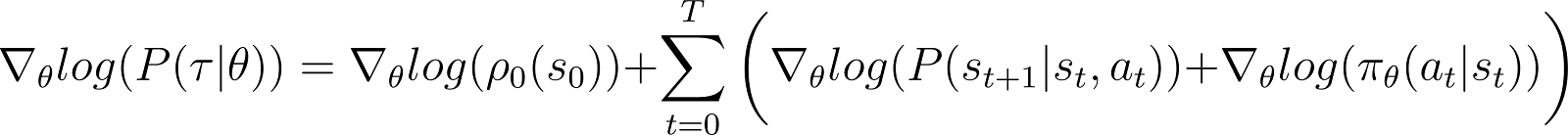
On the RHS of the above equation:
Removing the above zero-terms from the equation, we are left with (Equation 5):
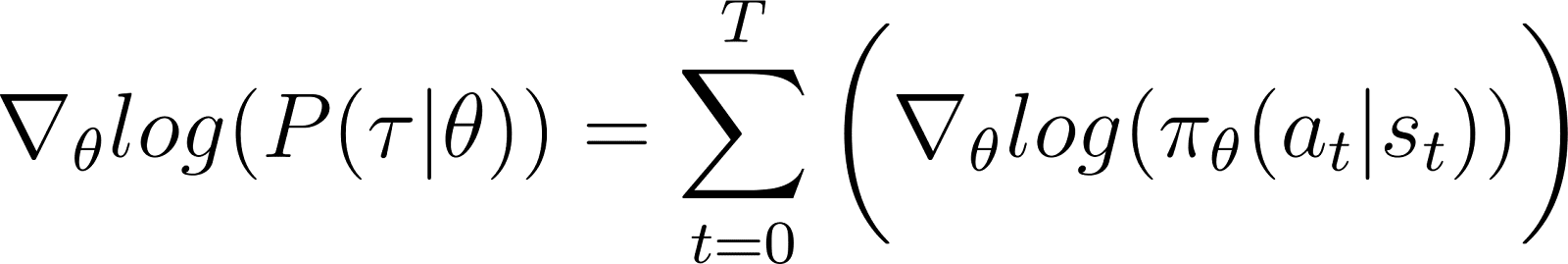
Recall from Equation 2 that:
![]()
Equation 5 evaluates the log of the first part of the RHS of Equation 2. We need to relate the derivative of a term with its logarithm. We do this using the chain rule and the log-derivative trick.
We take a detour and use the rules of calculus to derive a result, which we will use to simplify the previous equation and render it suitable for computational methods.
In calculus, the derivative of a logarithm can be expressed as:
![]()
Thus, by re-arranging the above equation, the derivative of x can be expressed in terms of the derivative of the logarithm of x:
![]()
This is sometimes called the log-derivative trick.
According to the chain rule, given z(y) as a function of y, where y itself is a function of θ, y(θ), the derivate of z with respect to θ is given as:
![]()
In this case, y(θ) stands for P(θ) and z(y) stands for log(y). Thus,
![]()
We know from calculus that d(log(y)) / dy = 1/y. Use this in the first expression of the RHS above.
![]()
Move y to the LHS and use the notation:
![]()
y stands for P(θ). So the above equation is equivalent to:
![]()
The above result gives the first expression of the RHS of Equation 2 (shown below).
![]()
Using the result in the RHS of Equation 2, we get:
![]()
We rearrange the terms under the RHS integral as below:
![]()
Observe that the above expression contains the integral expansion of an expectation: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Thus, the RHS above can be expressed as the expectation:
![]()
We substitute the derivative of the log probability in the expression of the expected reward:
![]()
In the above equation, substitute the value of ∇logP(θ) from Equation 5 to get:
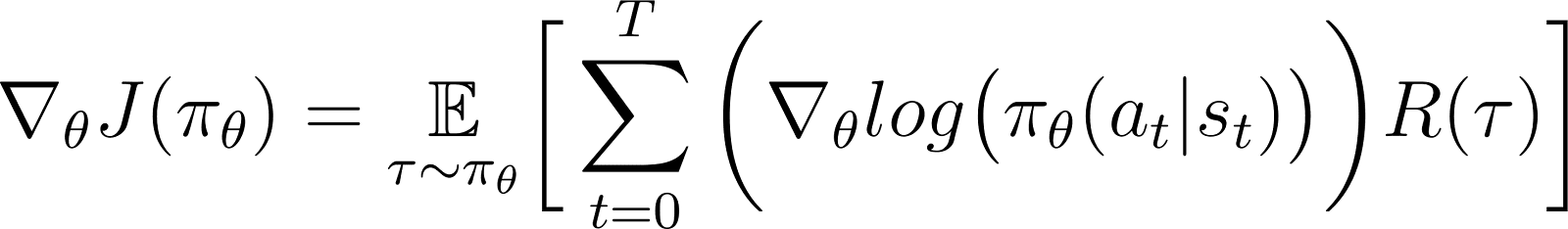
This is the expression for the gradient of the reward function according to the policy gradient theorem.
Policy gradient methods convert the policy’s output to a probability distribution. The agent samples this distribution to pick an action. Policy gradient methods adjust the policy parameters. This leads to updating this probability distribution in each iteration. The updated probability distribution has a higher likelihood of choosing actions that lead to higher rewards.
The policy gradient algorithm computes the gradient of the expected return with respect to the policy parameters. By moving the policy parameters in the direction of this gradient, the agent increases the probability of choosing actions that result in higher rewards during training.
Essentially, actions that led to better outcomes become more likely to be chosen in the future, gradually improving the policy to maximize long-term rewards.
Learn more about AI with these courses!
Course
Course
Course
Tutorial
Arun Nanda
Tutorial
Arun Nanda
Tutorial
Bex Tuychiev
Tutorial
Arun Nanda
Tutorial
Bex Tuychiev
Tutorial
Bex Tuychiev
