
Curso
Conceptos de la IA generativa
2 h
105.5K
Una ventaja clave de los métodos de gradiente político es su capacidad para manejar espacios de acción complejos, donde los enfoques tradicionales basados en valores tienen dificultades.
Los métodos basados en el valor, como el aprendizaje Q, funcionan estimando la función de valor para todas las acciones posibles. Esto resulta difícil cuando el espacio de acción del entorno es continuo o discreto pero grande.
Los métodos de gradiente de la política parametrizan la política y estiman el gradiente de las recompensas acumuladas con respecto alos parámetros de la política. Utilizan este gradiente para optimizar directamente la política actualizando sus parámetros. Por lo tanto, pueden manejar eficazmente espacios de acción de alta dimensión o continuos. Los gradientes de política también son la base de los métodos de Aprendizaje por Refuerzo mediante Retroalimentación Humana (RLHF).
Al parametrizar la política y ajustar sus parámetros basándose en gradientes, los gradientes de la política pueden manejar eficazmente acciones continuas y de alta dimensión. Este enfoque directo permite una mejor generalización y una exploración más flexible, por lo que es muy adecuado para tareas como el control robótico y otros entornos complejos.
Dado un conjunto de observaciones:
Cuando se sigue una política estocástica, la misma observación puede llevar a elegir acciones diferentes en iteraciones distintas. Esto favorece la exploración del espacio de acción y evita que la política se estanque en óptimos locales. Por ello, las políticas estocásticas son útiles en entornos en los que la exploración es esencial para descubrir el camino que conduce a los máximos rendimientos.
En los métodos basados en políticas, el resultado de la política se convierte en una distribución de probabilidad, asignando una probabilidad a cada acción posible. El agente elige una acción muestreando esta distribución, lo que permite aplicar una política estocástica. Así, los métodos de gradiente político combinan la exploración con la explotación, lo que resulta útil en entornos con estructuras de recompensa complejas.
Antes de entrar en la derivación, es importante establecer la notación matemática y los conceptos clave utilizados a lo largo de la demostración.
Como se ha mencionado en un apartado anterior, el teorema del gradiente de la política afirma que la derivada del rendimiento esperado es la expectativa del producto del rendimiento y la derivada del logaritmo de la política.
Antes de derivar el teorema del gradiente de la política, introducimos la notación:
Mostramos cómo deducir y demostrar el teorema del gradiente de la política a partir de los primeros principios, empezando por la expansión de la función objetivo y utilizando el truco de la derivada logarítmica.
La función objetivo en el método del gradiente de la política es el rendimiento
J acumulada siguiendo la trayectoria basada en la política π expresada en términos de parámetros θ. Esta función objetivo viene dada como
![]()
En la ecuación anterior:
Diferenciando (con respecto a θ) ambos lados de la ecuación anterior da:
![]()
La expectativa (en el lado derecho) puede expresarse como una integral sobre el producto de:
Así pues, el lado derecho de la ecuación 2 se replantea como:
![]()
El gradiente de una integral es igual a la integral del gradiente. Así, en la expresión anterior, podemos llevar el gradiente ∇θ bajo el signo de la integral. Por tanto, la RHS se convierte en:
![]()
Así, la ecuación 2 puede reescribirse como:
![]()
Ahora examinamos más detenidamente P(τ|θ), la probabilidad de que el agente siga la trayectoria τ dados los parámetros de la política θ (y, por tanto, la política πθ). Una trayectoria consiste en un conjunto de pasos. Así:
![]()
Así, partiendo de un estado inicial s0la probabilidad de que el agente siga la trayectoria τ según la política πθ viene dada como
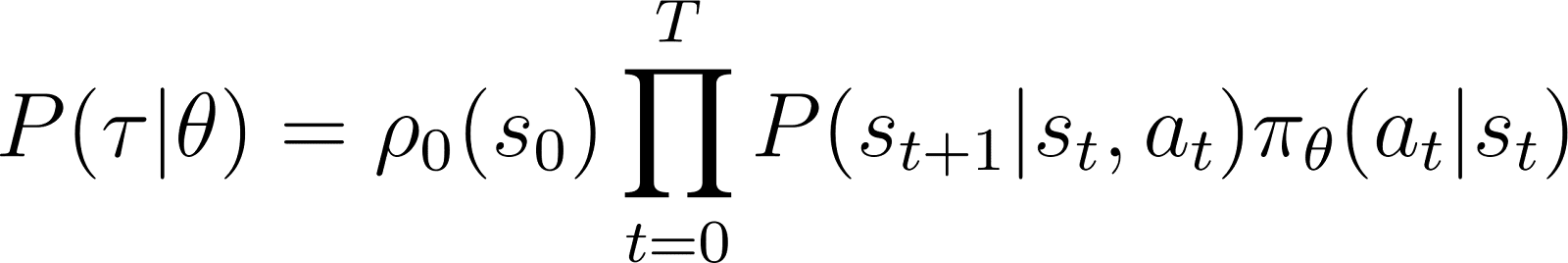
Para simplificar las cosas, queremos expresar el producto en el RHS anterior como una suma. Por tanto, tomamos el logaritmo de ambos lados de la ecuación anterior:
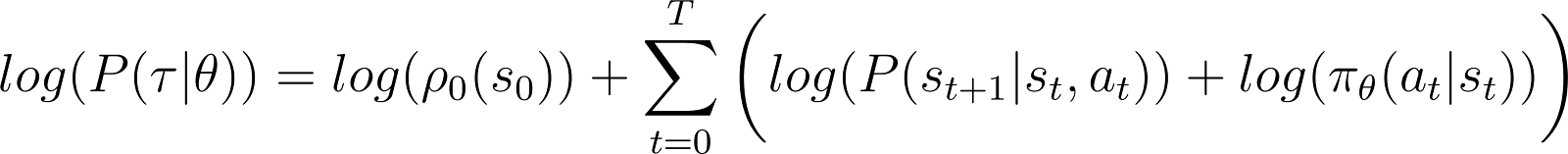
Tomamos ahora la derivada (respecto a θ) de la probabilidad logarítmica en la ecuación anterior.
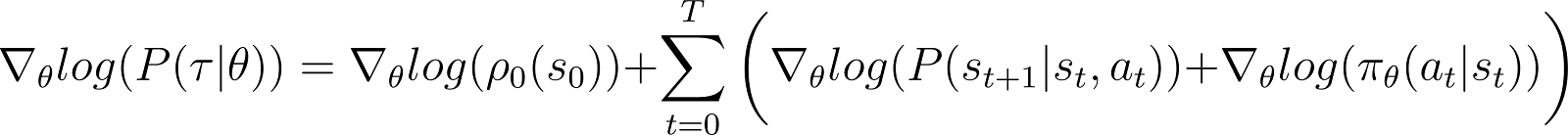
En el lado derecho de la ecuación anterior:
Eliminando los términos cero anteriores de la ecuación, nos queda (Ecuación 5):
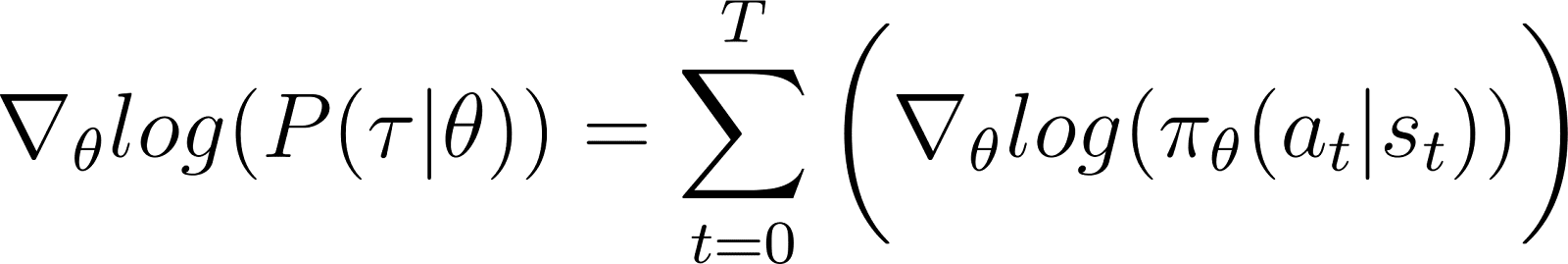
Recuerda de la ecuación 2 que
![]()
La ecuación 5 evalúa el logaritmo de la primera parte del lado derecho de la ecuación 2. Necesitamos relacionar la derivada de un término con su logaritmo. Para ello utilizamos la regla de la cadena y el truco de la derivada logarítmica.
Damos un rodeo y utilizamos las reglas del cálculo para deducir un resultado, que utilizaremos para simplificar la ecuación anterior y hacerla apta para los métodos computacionales.
En cálculo, la derivada de un logaritmo puede expresarse como:
![]()
Así, reordenando la ecuación anterior, la derivada de x puede expresarse en términos de la derivada del logaritmo de x:
![]()
Esto se llama a veces el truco del logaritmo-derivado.
Según la regla de la cadena, dada z(y) en función de ydonde y es una función de θ, y(θ)la derivada de z con respecto a θ viene dada como
![]()
En este caso y(θ) representa P(θ) y z(y) representa log(y). Así,
![]()
Sabemos por cálculo que d(log(y)) / dy = 1/y. Utilízalo en la primera expresión de la RHS anterior.
![]()
Mueve y al LHS y utiliza la notación:
![]()
y representa P(θ). Por tanto, la ecuación anterior equivale a
![]()
El resultado anterior da la primera expresión del lado derecho de la ecuación 2 (mostrada a continuación).
![]()
Utilizando el resultado del lado derecho de la ecuación 2, obtenemos:
![]()
Reordenamos los términos bajo la integral RHS como se indica a continuación:
![]()
Observa que la expresión anterior contiene la expansión integral de una expectativa: ∫P(θ)∇logP(θ) = E[∇logP(θ)].
Por lo tanto, el RHS anterior puede expresarse como la expectativa:
![]()
Sustituimos la derivada de la probabilidad logarítmica en la expresión de la recompensa esperada:
![]()
En la ecuación anterior, sustituye el valor de ∇logP(θ) de la Ecuación 5 para obtener
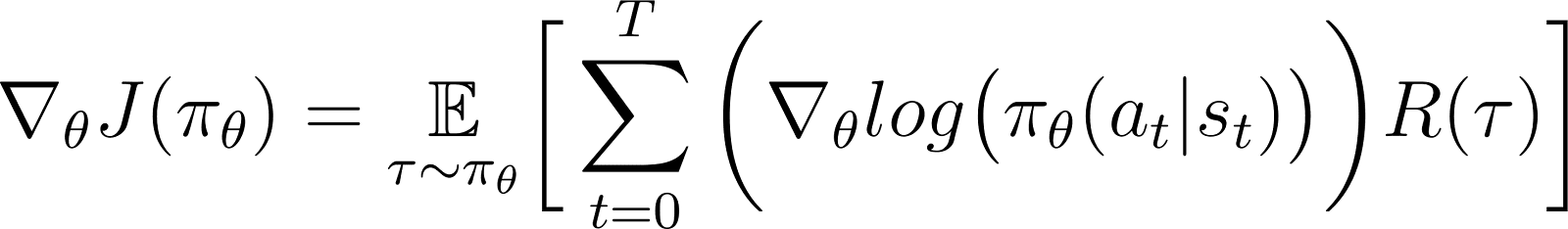
Esta es la expresión del gradiente de la función de recompensa según el teorema del gradiente de la política.
Los métodos de gradiente de la política convierten el resultado de la política en una distribución de probabilidad. El agente muestrea esta distribución para elegir una acción. Los métodos de gradiente de la política ajustan los parámetros de la política. Esto lleva a actualizar esta distribución de probabilidad en cada iteración. La distribución de probabilidad actualizada tiene una mayor probabilidad de elegir acciones que conducen a mayores recompensas.
El algoritmo del gradiente de la política calcula el gradiente del rendimiento esperado con respecto a los parámetros de la política. Moviendo los parámetros de la política en la dirección de este gradiente, el agente aumenta la probabilidad de elegir acciones que den lugar a mayores recompensas durante el entrenamiento.
Esencialmente, las acciones que condujeron a mejores resultados tienen más probabilidades de ser elegidas en el futuro, mejorando gradualmente la política para maximizar las recompensas a largo plazo.
Aprende más sobre IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial
Avinash Navlani
Tutorial
Zoumana Keita

