
Curso
Conceitos de IA Generativa
2 h
105.5K
Uma das principais vantagens dos métodos de gradiente de política é sua capacidade de lidar com espaços de ação complexos, onde as abordagens tradicionais baseadas em valores têm dificuldades.
Os métodos baseados em valor, como o Q-learning, funcionam estimando a função de valor para todas as ações possíveis. Isso se torna difícil quando o espaço de ação do ambiente é contínuo ou discreto, mas grande.
Os métodos de gradiente de política parametrizam a política e estimam o gradiente das recompensas cumulativas com relação aosparâmetros da política. Eles usam esse gradiente para otimizar diretamente a política, atualizando seus parâmetros. Portanto, eles podem lidar com eficiência com espaços de ação contínuos ou de alta dimensão. Os gradientes de política também são a base dos métodos de aprendizagem por reforço usando feedback humano (RLHF).
Ao parametrizar a política e ajustar seus parâmetros com base em gradientes, os gradientes de política podem lidar com eficiência com ações contínuas e de alta dimensão. Essa abordagem direta permite uma melhor generalização e uma exploração mais flexível, tornando-a adequada para tarefas como controle robótico e outros ambientes complexos.
Dado um conjunto de observações:
Ao seguir uma política estocástica, a mesma observação pode levar à escolha de diferentes ações em diferentes iterações. Isso promove a exploração do espaço de ação e evita que a política fique presa em ótimos locais. Por esse motivo, as políticas estocásticas são úteis em ambientes em que a exploração é essencial para descobrir o caminho que leva ao retorno máximo.
Nos métodos baseados em políticas, o resultado da política é convertido em uma distribuição de probabilidade, com uma probabilidade atribuída a cada ação possível. O agente escolhe uma ação por amostragem dessa distribuição, o que possibilita a implementação de uma política estocástica. Assim, os métodos de gradiente de política combinam a exploração com o aproveitamento, o que é útil em ambientes com estruturas de recompensa complexas.
Antes de mergulhar na derivação, é importante estabelecer a notação matemática e os principais conceitos usados na prova.
Conforme mencionado na seção anterior, o teorema do gradiente de política afirma que a derivada do retorno esperado é a expectativa do produto do retorno e a derivada do logaritmo da política.
Antes de derivar o teorema do gradiente de política, apresentamos a notação:
Mostramos como derivar e provar o teorema do gradiente de política a partir dos primeiros princípios, começando com a expansão da função objetiva e usando o truque do derivado logarítmico.
A função objetiva no método de gradiente de política é o retorno
J acumulado ao seguir a trajetória com base na política π expressa em termos de parâmetros θ. Essa função objetiva é dada como:
![]()
Na equação acima:
Diferenciando (com relação a θ) ambos os lados da equação acima, você obtém:
![]()
A expectativa (no RHS) pode ser expressa como uma integral sobre o produto de:
Assim, o RHS da Equação 2 é reformulado como:
![]()
O gradiente de uma integral é igual à integral do gradiente. Portanto, na expressão acima, podemos trazer o gradiente ∇θ sob o sinal de integral. Portanto, o RHS se torna:
![]()
Assim, a Equação 2 pode ser reescrita como:
![]()
Agora, vamos dar uma olhada mais de perto em P(τ|θ), a probabilidade de o agente seguir a trajetória τ com base nos parâmetros de política θ (e, portanto, na política πθ). Uma trajetória consiste em um conjunto de etapas. Assim:
![]()
Assim, partindo de um estado inicial s0a probabilidade de o agente seguir a trajetória τ com base na política πθ é dada como:
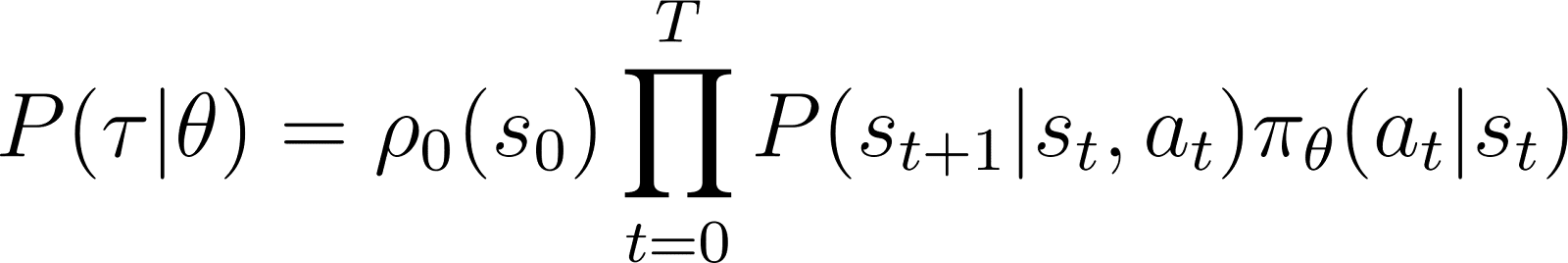
Para simplificar as coisas, queremos expressar o produto no RHS acima como uma soma. Portanto, tomamos o logaritmo de ambos os lados da equação acima:
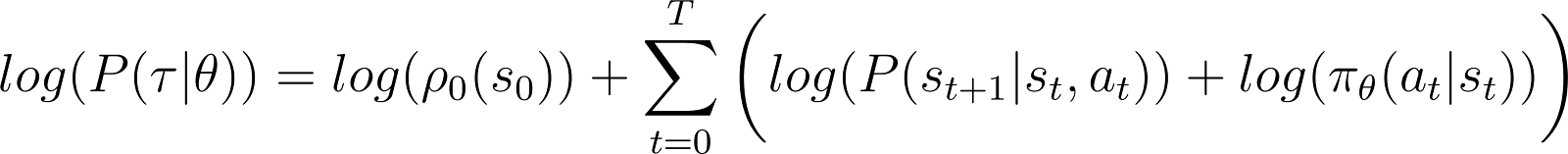
Agora, tomamos a derivada (com relação a θ) da probabilidade de log na equação acima.
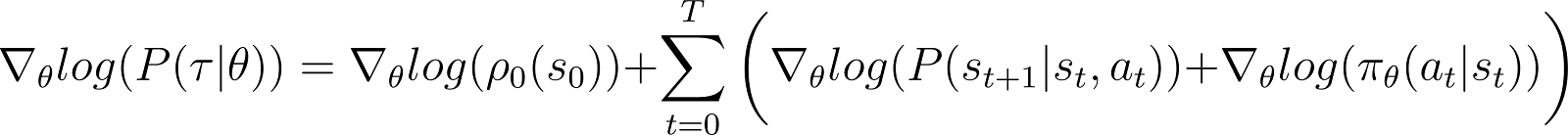
No RHS da equação acima:
Removendo os termos zero acima da equação, ficamos com a (Equação 5):
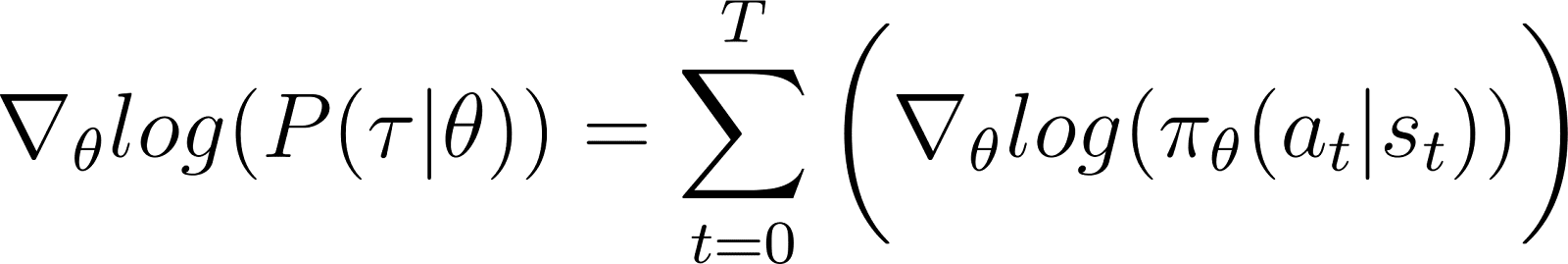
Lembre-se de que, na Equação 2, você sabe que:
![]()
A Equação 5 avalia o logaritmo da primeira parte do RHS da Equação 2. Precisamos relacionar a derivada de um termo com seu logaritmo. Fazemos isso usando a regra da cadeia e o truque da derivada do logaritmo.
Fazemos um desvio e usamos as regras de cálculo para obter um resultado, que usaremos para simplificar a equação anterior e torná-la adequada para métodos computacionais.
No cálculo, a derivada de um logaritmo pode ser expressa como:
![]()
Assim, ao reorganizar a equação acima, a derivada de x pode ser expressa em termos da derivada do logaritmo de x:
![]()
Isso às vezes é chamado de truque da derivada do logaritmo.
De acordo com a regra da cadeia, dado z(y) como uma função de yonde y é uma função de θ, y(θ), a derivada de z em relação a θ é dada como:
![]()
Nesse caso, y(θ) representa P(θ) e z(y) representa log(y). Assim,
![]()
Você sabe, pelo cálculo, que d(log(y)) / dy = 1/y. Use isso na primeira expressão do RHS acima.
![]()
Mover y para o LHS e use a notação notação:
![]()
y representa P(θ). Portanto, a equação acima é equivalente a:
![]()
O resultado acima fornece a primeira expressão do RHS da Equação 2 (mostrada abaixo).
![]()
Usando o resultado no RHS da Equação 2, obtemos:
![]()
Reorganizamos os termos sob a integral RHS conforme abaixo:
![]()
Observe que a expressão acima contém a expansão integral de uma expectativa: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Assim, o RHS acima pode ser expresso como a expectativa:
![]()
Substituímos a derivada da probabilidade logarítmica na expressão da recompensa esperada:
![]()
Na equação acima, substitua o valor de ∇logP(θ) da Equação 5 para obter:
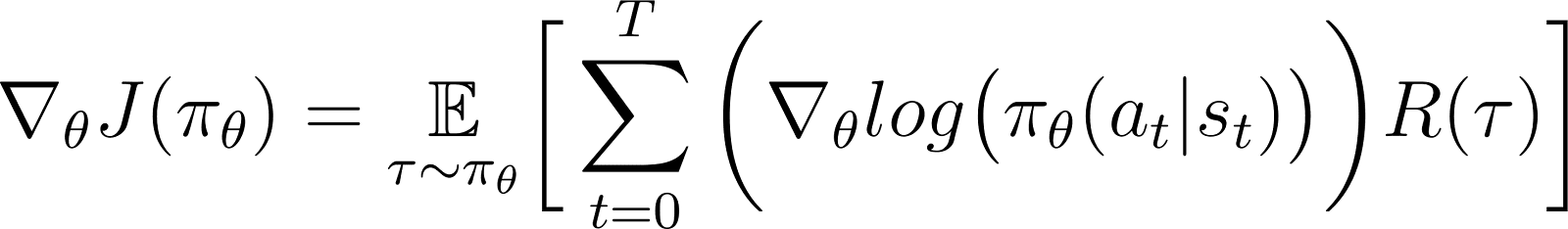
Essa é a expressão para o gradiente da função de recompensa de acordo com o teorema do gradiente de política.
Os métodos de gradiente de política convertem o resultado da política em uma distribuição de probabilidade. O agente coleta amostras dessa distribuição para escolher uma ação. Os métodos de gradiente de política ajustam os parâmetros da política. Isso leva à atualização dessa distribuição de probabilidade em cada iteração. A distribuição de probabilidade atualizada tem uma probabilidade maior de escolher ações que levam a recompensas maiores.
O algoritmo de gradiente de política calcula o gradiente do retorno esperado em relação aos parâmetros da política. Ao mover os parâmetros da política na direção desse gradiente, o agente aumenta a probabilidade de escolher ações que resultem em recompensas mais altas durante o treinamento.
Essencialmente, as ações que levaram a melhores resultados têm maior probabilidade de serem escolhidas no futuro, melhorando gradualmente a política para maximizar as recompensas de longo prazo.
Saiba mais sobre IA com estes cursos!
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Bex Tuychiev
Tutorial
DataCamp Team
Tutorial
Zoumana Keita

