
Kurs
FastAPI ile Üretime AI Dağıtımı
4 sa
4.8K
Günümüzde en yaygın ajan mimarisi, bir LLM'nin araçları döngü içinde çağırmasına dayanır; bu yaklaşım basit ve etkilidir ancak nihayetinde sınırlıdır. Düz ilerleyen görevlerde işe yarasa da planlama, bağlam yönetimi ve daha uzun zaman ufuklarında kesintisiz yürütme gerektiren karmaşık, çok adımlı zorluklar karşısında yetersiz kalır.
LangChain’in Deep Agents mimarisi; ayrıntılı sistem istemleri, planlama araçları, alt ajanlar ve dosya sistemlerini birleştirerek karmaşık araştırma, kodlama ve analitik görevlerin üstesinden gelebilen yapay zekâ ajanları oluşturur. Claude Code, Deep Research ve Manus gibi uygulamalar bu yaklaşımın etkinliğini kanıtladı; artık deepagents Python paketi bu mimariyi herkes için erişilebilir kılıyor.
Bu eğitimde, adım adım şunları nasıl yapacağımı açıklayacağım:
Deep Agents; kalıcı muhakeme, araç kullanımı ve bellek gerektiren karmaşık, çok adımlı görevleri ele almak için tasarlanmış gelişmiş bir ajan mimarisidir. Kısa döngülerde çalışan ya da basit araç çağrıları yapan geleneksel ajanların aksine, Deep Agents eylemlerini planlar, değişen bağlamı yönetir, alt görevleri uzman alt ajanlara devreder ve uzun etkileşimler boyunca durumu korur. Bu mimari hâlihazırda Claude Code, Deep Research ve Manus gibi gerçek dünya uygulamalarını güçlendiriyor.
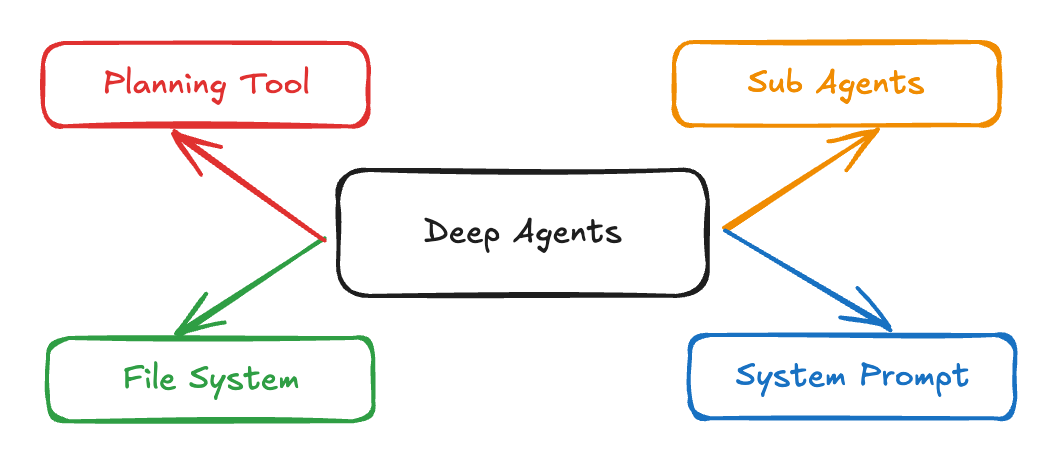
Kaynak: LangChain
Bunlar Deep Agents’ın temel özellikleridir:
Deep Agents, geleneksel ajanların sınırlamalarını dört temel bileşenle aşar:
Basit talimat istemlerinden farklı olarak, Deep Agents aşağıdaki gibi kapsamlı sistem istemleri kullanır:
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""İstem; planlamayı, araştırmayı ve yetki devrini dokümantasyonla bütünleştirir ve karmaşık görevleri parçalamak için birkaç örnekli (few-shot) örnekler kullanır.
Planlama aracı genellikle, ajanın düşüncelerini düzenlemesine yardımcı olan basit bir “no-op”tan ibarettir:
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"Bu basit araç, ajanın plana uygun hareket etmesini ve yürütme boyunca planı görünür tutmasını sağlayan önemli bir bağlam mühendisliği sunar.
Deep Agents, odaklı görevler için uzmanlaşmış alt ajanlar başlatabilir. Her alt ajan kendi istemi, açıklaması ve araç setiyle tasarlanır; bu da görevlerin ayrışmasını ve derin, göreve özgü optimizasyonu mümkün kılar. İş akışınızda alt ajanları şöyle tanımlayabilirsiniz:
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]Bu yaklaşım bağlam izolasyonu sağlar; yani her alt ajan kendi bağlamını korur ve ana ajanın belleğini kirletmez. Uzmanlaşmış görevleri yalıtarak şunları mümkün kılarsınız:
Deep Agents, sanal bir dosya sistemi kullanarak durumu korur ve paylaşır. Yalnızca konuşma geçmişine güvenmek yerine, bu yerleşik araçlar ajanların bir iş akışı boyunca bilgileri düzenlemesine olanak tanır:
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]Bu sanal dosya sistemi çeşitli avantajlar sunar:
deepagents ile Bir İş Başvurusu Asistanı OluşturmaKullanıcı için uygun iş ilanlarını otomatik olarak bulan ve özelleştirilmiş ön yazılar üreten bir iş başvurusu asistanı oluşturmanın pratik bir örneğini adım adım göstereceğim.
Asistanımız şunları yapacak:
Temel kurulum ve yüklemeyle başlayalım:
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiKurulum tamamlandıktan sonra ortam değişkenlerimizi ayarlıyoruz:
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxBu demo için hem bir OpenAI API anahtarına (GPT-4o mini modeli için) hem de bir Tavily API anahtarına (web arama işlevi için) ihtiyacınız olacak. Tavily, ajana doğrudan web’den en güncel iş ilanlarını sağlar; OpenAI’nin modeli ise tüm dil anlama, akıl yürütme, planlama ve içerik üretimini gerçekleştirir.
Not: Yeni Tavily kullanıcıları 1.000 ücretsiz API kredisi alır. Anahtarınızı almak için sadece https://app.tavily.com adresinden kaydolun.
Son olarak gerekli kütüphaneleri içe aktarıp Streamlit arayüzünü kuracağız:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentBu adım, derin ajan uygulamamız için gerekli tüm bağımlılıkları içe aktarır. Web arayüzü için streamlit, veri işleme için pandas, LLM entegrasyonu için langchain_openai ve ajan çerçevemiz için deepagents kullanıyoruz.
Sonraki adımda, kullanıcı etkileşimleri arasında verileri kalıcı kılmak için Streamlit’in oturum durumunu (session state) başlatıyoruz. Böylece kullanıcılar arayüzle etkileşime geçerken uygulama yüklenen dosyaları, sonuçları ve hata durumlarını hatırlar:
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""Bu kurulum, oturum boyunca iş sonuçlarını, oluşturulan ön yazıları ve olası hata iletilerini depolamamıza olanak tanıyarak akıcı bir kullanıcı deneyimi sağlar.
Özgeçmiş yükleme, iş unvanı, konum ve isteğe bağlı beceriler için girdi alanlarını düzenlemek amacıyla Streamlit sütunlarını kullanıyoruz:
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)Daha iyi bir yerleşim için arayüz sütunlara bölünmüştür. Kullanıcılar özgeçmişlerini birden çok formatta yükleyebilir, hedef iş unvanını ve konumunu belirtebilir ve başvurularında vurgulamak istedikleri belirli becerileri öne çıkarabilir.
Sırada, farklı özgeçmiş formatlarını ele almak ve bunlardan metin çıkarmak için sağlam bir dosya işleme uyguluyoruz.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()Bu yardımcı işlevler, farklı dosya formatlarından (PDF, DOCX, TXT) metin çıkarmanın karmaşıklığını ele alır ve markdown çıktıyı indirme için yeniden DOCX formatına dönüştürür. Her işlev şu şekilde çalışır:
extract_text() işlevi, yüklenen dosya türünü (TXT, PDF veya DOCX) otomatik olarak algılar ve uygun kütüphaneyi kullanarak içeriği çıkarır; böylece kullanıcıların dosya formatını dert etmesine gerek kalmaz.md_to_docx() işlevi, (ajan tarafından üretilen ön yazılar gibi) markdown biçimli metni alır ve indirmeye hazır, temiz ve iyi yapılandırılmış bir Word belgesine dönüştürür.Bu sayede uygulama, farklı özgeçmiş girdilerini esnek biçimde işleyebilir ve orijinal dosya formatından bağımsız olarak profesyonel çıktılar üretebilir.
Sonraki adımda, ajanın yanıtından iş verilerini çıkarmak için sağlam bir ayrıştırma uyguluyoruz.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Yukarıdaki işlevleri kısaca anlayalım:
extract_jobs_from_text() işlevi, ajanın yapılandırılmış çıktısından (<JOBS>...</JOBS> etiketleri içinde) bir JSON iş dizisini çıkarmak için bir düzenli ifade kullanır. JSON içinde çift tırnak yerine tek tırnak döndürmek gibi küçük model hatalarını ele almak için geriye dönük ayrıştırma da eklenmiştir.normalize_jobs() işlevi, her iş sözlüğünü standartlaştırır ve temizler; örneğin büyük/küçük harfe duyarsız anahtarlar, zorunlu alanlar, boşluk kırpma ve çıktıyı ilk 5 kayda sınırlandırma gibi.Araştırma yeteneğinin kalbi Tavily tarafından sağlanır. Bu nedenle, derin ajanın güncel iş ilanlarını bulmak için kullanacağı bir web arama aracını tanımlıyoruz:
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)internet_search() işlevi @tool ile süslenmiştir; bu sayede ajanın ve alt ajanların erişimine açılır. Ardından Tavily API’sini çağırır ve dinamik iş sorguları ile araştırmalar için ideal olan ilgili, güncel arama sonuçlarını döndürür.
Not: Bu şekilde daha fazla araç (belge özetleme, kod çalıştırma veya veri zenginleştirme gibi) ekleyerek derin ajanın yeteneklerini daha da genişletebilirsiniz.
Şimdi, ana ajanı ve hedefe yönelik talimatlara sahip alt ajanlarını şu şekilde yapılandırarak her şeyi bir araya getiriyoruz:
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)Bu adım, uzmanlaşmış alt ajanlar aracılığıyla Deep Agents’ın gücünü gösterir. Ana talimatlar genel yönlendirme sağlar; her alt ajan ise belirli görevler için odaklı istemlere sahiptir:
INSTRUCTIONS, JOB_SEARCH_PROMPT ve COVER_LETTER_PROMPT, ana sistem istemini ve her alt ajan için uzmanlaşmış talimatları tanımlar. Bu, ajanın istenen formatta iyi yapılandırılmış iş sonuçları ve özelleştirilmiş ön yazılar üretmesini sağlar.build_agent() işlevi, OpenAI API anahtarını kontrol eder, dil modelini kurar ve hem iş arama hem de ön yazı alt ajanlarıyla derin ajanı oluşturur. Bu modüler kurulum, her alt ajanın iş akışının kendi bölümüne odaklanmasına olanak tanır.make_task_prompt() işlevi, kullanıcının özgeçmişini, becerilerini, iş unvanını ve konumunu birleştiren tek bir istem üretir. Bu, ajana arama ve taslak oluşturma sürecine başlamak için gereken tüm bağlamı verir.Birlikte, bu işlevler iş akışına yapı ve uzmanlaşma katar.
Bu adım, kullanıcı girdilerini ele alan ve derin ajanı yöneten çekirdek uygulama mantığıdır:
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")Yukarıdaki kod, kullanıcı eylemlerini işler, derin ajanı başlatır ve sonuçları şu şekilde gösterir:
Son olarak, sonuçları kullanıcı dostu bir formatta sunuyoruz:
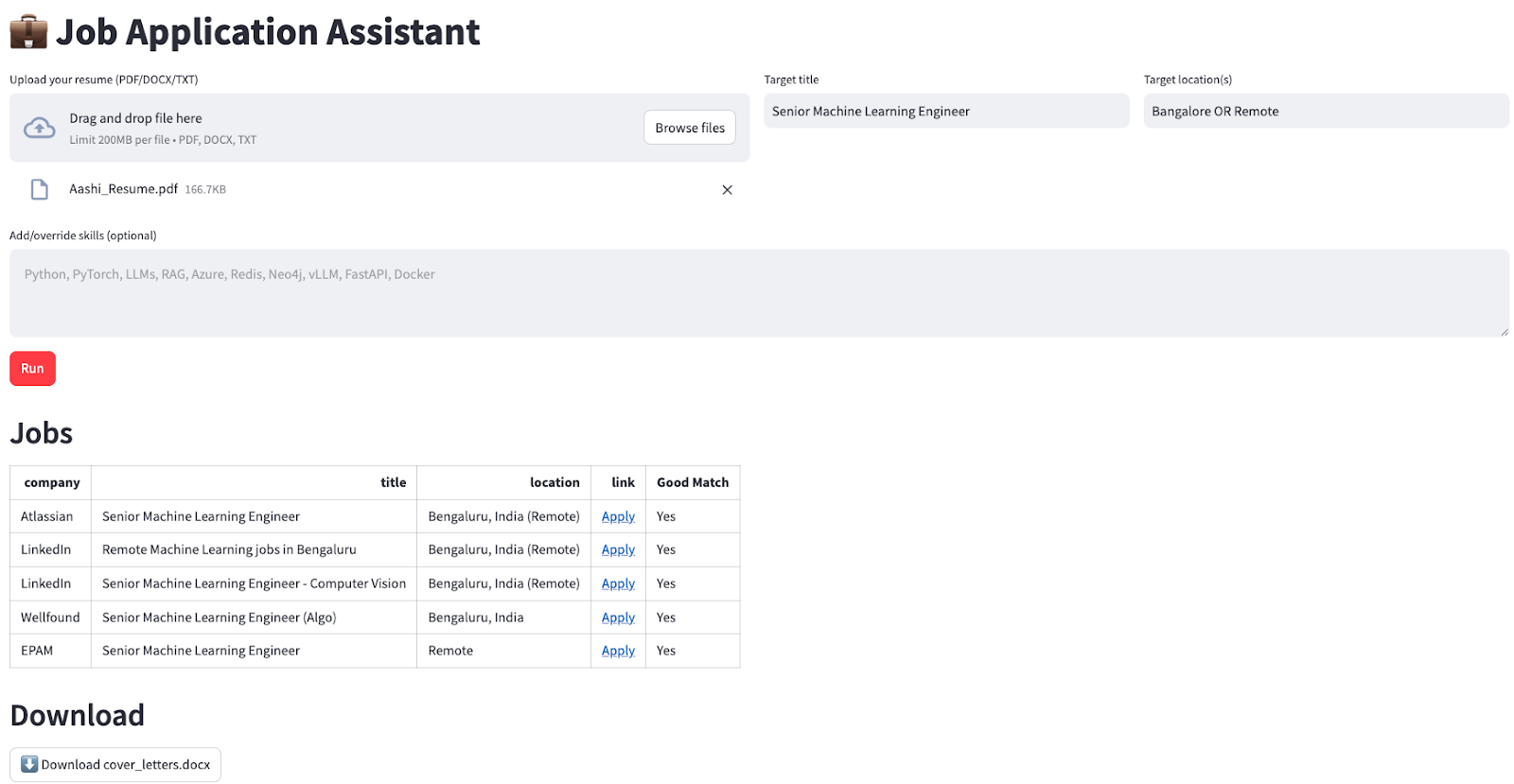
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
st.caption("Cover letters not produced yet.")Ajan tamamladıktan sonra sonuçları cilalı bir düzenle sunarız; yani:
Bu, çok adımlı bir yapay zekâ iş akışını tek tıklamalık bir deneyime dönüştürür.
Uygulamayı başlatmak için yalnızca şunu çalıştırın:
streamlit app.pyBu kurslarla yapay zekâyı öğrenin!
Kurs
Kurs
Kurs