
Track
AI Fundamentals
10 hr
OpenAI's GPT-4o integrates audio, vision, and text capabilities into a single, powerful language model.
This development marks a significant move towards more natural and intuitive human-computer interaction.
In this tutorial, I’ll provide step-by-step guidance on using GPT-4o through the OpenAI API.
Even though OpenAI recently released the o3 model—its most capable reasoning model—GPT-4o and GPT-4o mini remain the best options for applications that require quick responses, image handling, or function calling. If your project demands advanced reasoning, be sure to check out this OpenAI O1 API tutorial, which walks you through the process of using a reasoning model via API.
GPT-4o, short for "omni," represents a significant advancement in AI. Unlike GPT-4, which only handles text, GPT-4o is a multimodal model that processes and generates text, audio, and visual data.

By embracing audio and visual data alongside text, GPT-4o breaks free from the constraints of traditional text-only models, creating more natural and intuitive interactions.
GPT-4o has a faster response time, is 50% cheaper than GPT-4 Turbo, and is better at audio and vision understanding than existing models.
If you want to get a more detailed overview of GPT-4o, check out this article on What Is OpenAI’s GPT-4o.
In addition to interacting with GPT-4o through the ChatGPT interface, developers can interact with GPT-4o through the OpenAI API, enabling them to integrate GPT-4o's capabilities into their applications and systems.
The GPT-4o API opens up a vast array of potential use cases by using its multimodal capabilities:
Modality | Use Cases | Description |
Text | Text Generation, Text Summarization, Data Analysis & Coding | Content creation, concise summaries, code explanations, and coding assistance. |
Audio | Audio Transcription, Real-Time Translation, Audio Generation | Convert audio to text, translate in real-time, create virtual assistants or language learning. |
Vision | Image Captioning, Image Analysis & Logic, Accessibility for Visually Impaired | Describe images, analyze visual information, provide accessibility for visually impaired. |
Multi | Multimodal Interactions, Roleplay Scenarios | Seamlessly combine modalities, create immersive experiences. |
Let's now explore how to use GPT-4o through the OpenAI API.
Before using the GPT-4o API, we must sign up for an OpenAI account and obtain an API key. We can create an account on OpenAI API website.
Once we have an account, we can navigate to the API keys page:
We can now generate an API key. We need to keep it safe, as we won't be able to view it again. But we can always generate a new one if we lose it or need one for a different project.
To interact with the GPT-4o API programmatically, we'll need to install the OpenAI Python library. We can do this by running the following command:
Once installed, we can import the necessary modules into our Python script:
from openai import OpenAIBefore we can make API requests, we'll need to authenticate with our API key:
# Set the API keyclient = OpenAI(api_key="your_api_key_here")Replace "your_api_key_here" with your actual API key.
After completing the client connection, we can start generating text using GPT-4o:
MODEL = "gpt-4o"completion = client.chat.completions.create( model=MODEL, messages=[ {"role": "system", "content": "You are a helpful assistant that helps me with my math homework!"}, {"role": "user", "content": "Hello! Could you solve 20 x 5?"} ])print("Assistant: " + completion.choices[0].message.content)This code snippet uses the chat completions API with the GPT-4o model, which accepts math-related questions as input and generates a response:

Audio transcription and summarisation have become essential tools in various applications, from improving accessibility to enhancing productivity. With the GPT-4o API, we can efficiently handle tasks such as transcribing and summarizing audio content.
While GPT-4o has the potential to handle audio directly, the direct audio input feature isn't yet available through the API. For now, we can use a two-step process with the GPT-4o API to transcribe and then summarize audio content.
To transcribe an audio file using GPT-4o, we must provide the audio data to the API. Here's an example:
# Transcribe the audioaudio_path = "path/to/audio.mp3"transcription = client.audio.transcriptions.create( model="whisper-1", file=open(audio_path, "rb"),)Replace "path/to/audio.mp3" with the actual path to your audio file. This example uses the whisper-1 model for transcription.
response = client.chat.completions.create( model=MODEL, messages=[ { "role": "system", "content": """You are generating a transcript summary. Create a summary of the provided transcription. Respond in Markdown.""" }, { "role": "user", "content": [ {"type": "text", "text": f"The audio transcription is: {transcription.text}"} ], } ], temperature=0,)print(response.choices[0].message.content)Visual data analysis is crucial in various domains, from healthcare to security and beyond. With the GPT-4o API, you can seamlessly analyze images, engage in conversations about visual content, and extract valuable information from images.
To analyze an image using GPT-4o, we must first provide the image data to the API. We can do this by either encoding a local image as a base64 string or providing a URL to an online image:
import base64IMAGE_PATH = "image_path"# Open the image file and encode it as a base64 stringdef encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode("utf-8")base64_image = encode_image(IMAGE_PATH) "url": "<https://images.saymedia-content.com/.image/c_limit%2Ccs_srgb%2Cq_auto:eco%2Cw_538/MTczOTQ5NDQyMzQ3NTc0NTc5/compound-shapes-how-to-find-the-area-of-a-l-shape.webp>"Once we have processed the image input, we can pass the image data to the API for analysis.
Let’s try to analyze an image to determine the area of a shape. Let’s first use the image below:
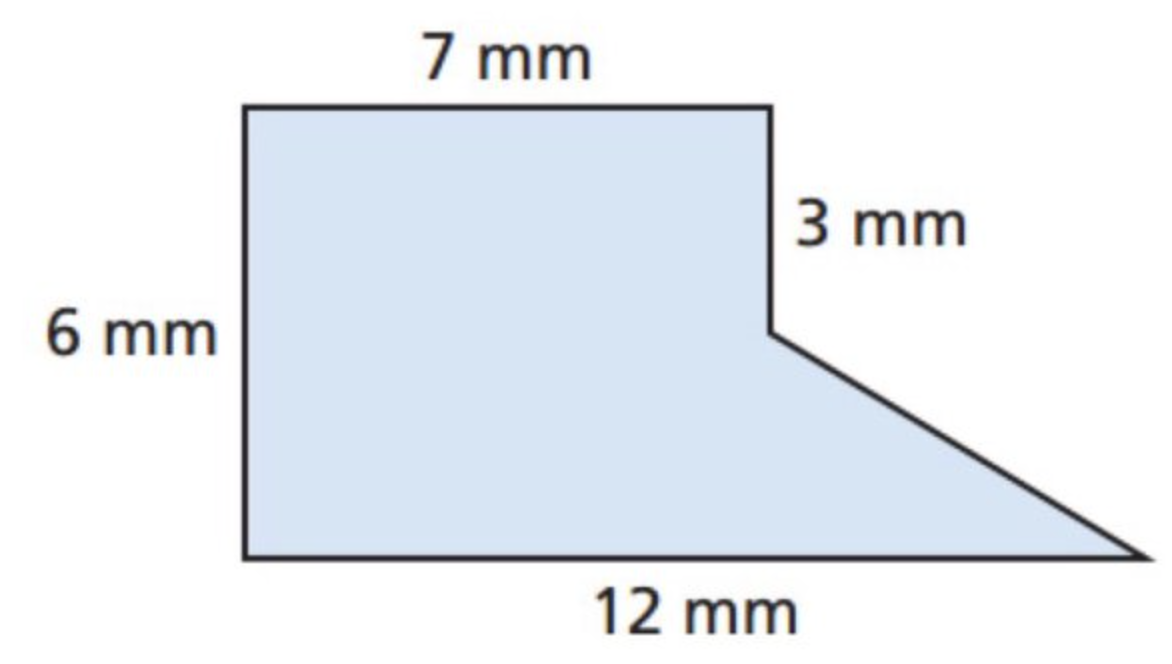
We’ll now ask GPT-4o to ask the area of this shape—notice we’re using a base64 image input below:
response = client.chat.completions.create( model=MODEL, messages=[ { "role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!" }, { "role": "user", "content": [ {"type": "text", "text": "What's the area of the shape in this image?"}, { "type": "image_url", "image_url": { "url": f"data:image/png;base64,{base64_image}" } } ] } ], temperature=0.0,)print(response.choices[0].message.content)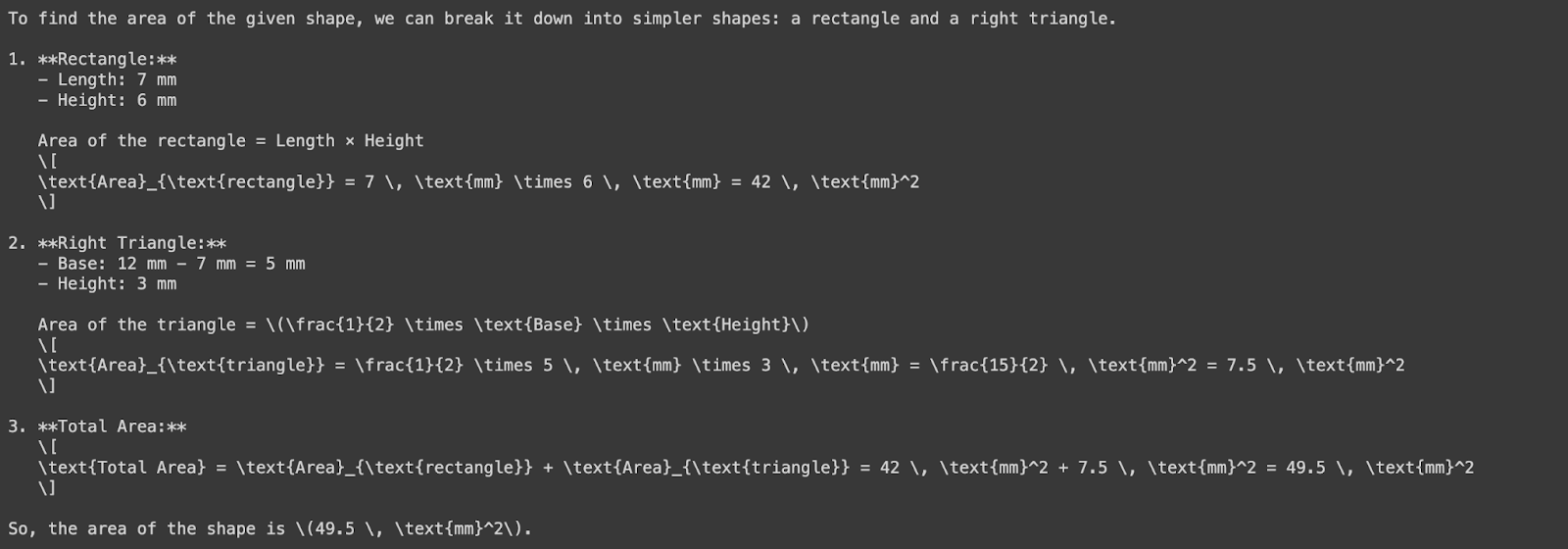
Let’s now consider this shape:
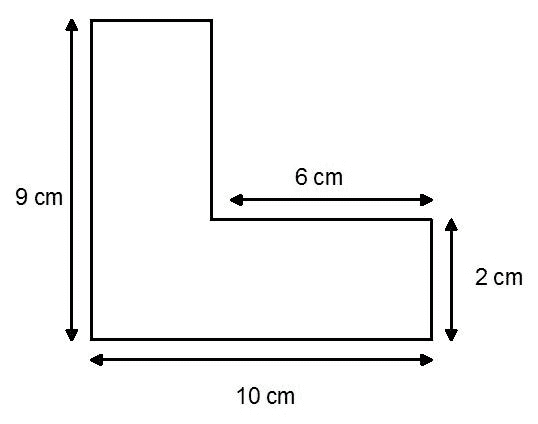
We’ll pass the image URL to GPT-4o to find the area of the shape:
response = client.chat.completions.create( model=MODEL, messages=[ { "role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!" }, { "role": "user", "content": [ {"type": "text", "text": "What's the area of the shape in the image?"}, { "type": "image_url", "image_url": { "url": "https://images.saymedia-content.com/.image/c_limit%2Ccs_srgb%2Cq_auto:eco%2Cw_538/MTczOTQ5NDQyMzQ3NTc0NTc5/compound-shapes-how-to-find-the-area-of-a-l-shape.webp" } } ] } ], temperature=0.0,)print(response.choices[0].message.content)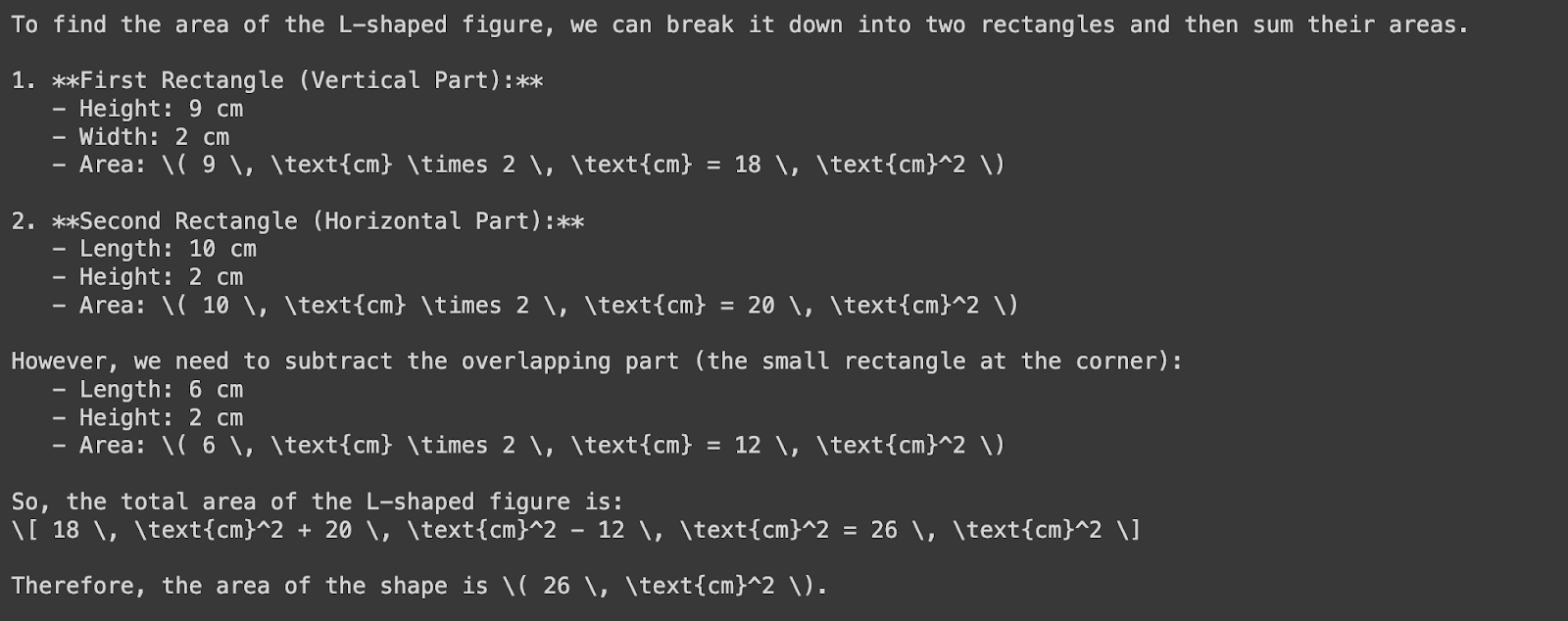
Notice that GPT-4o incorrectly measured the width of the vertical rectangle—it should be four centimeters, not two. This discrepancy arises from the misalignment between the measurement labels and the rectangle's actual proportions. If anything, this highlights once again the importance of human supervision and validation.
As of July 2025, the pay-as-you-go pricing for GPT-4o is:
Input Tokens: $5.00 per million tokens
Cached Input Tokens: $2.50 per million tokens
Output Tokens: $20.00 per million tokens
For applications requiring high-volume API calls, OpenAI offers GPT-4o Mini, a streamlined version of GPT-4o:
Input Tokens: $0.60 per million tokens
Cached Input Tokens: $0.30 per million tokens
Output Tokens: $2.40 per million tokens
OpenAI’s Batch API offers a 50% discount on both input and output token costs for GPT-4o:
Input Tokens: $2.50 per million tokens
Output Tokens: $10.00 per million tokens
This is ideal for processing large volumes of data asynchronously.
When working with the GPT-4o API, it's important to remember a few key considerations to ensure optimal performance, cost-effectiveness, and alignment with each specific use case. Here are three crucial factors to consider:
The OpenAI API follows a pay-per-use model, where costs are incurred based on the number of tokens processed.
Although GPT-4o is cheaper than GPT-4 Turbo, planning our usage accordingly is crucial to estimating and managing costs.
To minimize costs, you can consider techniques like batching and optimizing prompts to reduce the number of API calls and tokens processed.
Even though GPT-4o offers impressive performance and low latency, it’s still a large language model, which means that processing requests can be computationally intensive, leading to relatively high latency.
We need to optimize our code and use techniques like caching and asynchronous processing to mitigate latency issues.
Additionally, we can explore using OpenAI's dedicated instances or fine-tuning the model to our specific use case, which can improve performance and reduce latency.
GPT-4o is a powerful general model with a wide range of capabilities, but we need to ensure that our specific use case aligns with the model's strengths.
Before relying solely on GPT-4o, we must carefully evaluate our use case and consider whether the model's capabilities suit our needs.
If necessary, we could fine-tune smaller models or explore other models that may be better suited for our particular task.
GPT-4o's multimodal capabilities address the limitations of earlier models that struggled to integrate and process different types of data seamlessly.
By leveraging the GPT-4o API, developers can build innovative solutions that seamlessly integrate text, audio, and visual data.
If you want to get more practice with GPT-4o, I recommend this code-along on creating AI assistants with GPT-4o. Similarly, if you want to learn more about working with APIs, I recommend these resources:
Learn AI with these courses!
Track
Track
Course
Tutorial
François Aubry
Tutorial
Richie Cotton
Tutorial
Zoumana Keita
code-along
Richie Cotton
code-along
Zoumana Keita
code-along
Richie Cotton


