
Track
AI Fundamentals
10 hr
Image by Author
In the fast-growing field of artificial intelligence, Large Language Models have emerged as the main characters of the latest breakthroughs in the field.
Text generation has become a groundbreaking capability, transforming how machines understand and produce human-like text. This popularity is why multiple tools were launched to smooth and facilitate the process of working with LLMs.
The rapid proliferation of Large Language Models (LLMs), with new ones emerging almost weekly, has sparked a parallel growth in hosting options to accommodate this technology. Within the wide universe of tools available for this purpose, Hugging Face's Text Generation Inference (TGI) is particularly noteworthy, as it allows us to run a LLM as a service in our local machine.
To put it simply, it allows us to have an end-point to call our model.
This guide will explore why Hugging Face TGI is a game-changer and how you can leverage it to create sophisticated AI models capable of generating text that's increasingly indistinguishable from that produced by humans.
Hugging Face Text Generation Inference, also known as TGI, is a framework written in Rust and Python for deploying and serving Large Language Models. It is a production-ready toolkit for deploying and serving LLMs.
Hugging Face develops and distributes it under the HFOILv1.0 license, permitting commercial use provided it serves as an auxiliary tool within the product or service offered rather than the main focus. The main challenges it addresses are:
Image by Author.
Hugging Face optimized some of the LLMs’ architectures so that they run faster with TGI. This includes popular models like LLaMA, Falcon7B, and Mistral. The full list can be found in their documentation.
Hugging Face has transformed into the go-to spot for crafting AI with natural language abilities. It's a hub where all the open-source heavyweight models hang out, making it a powerhouse for NLP innovation. Until now, most of these models were too heavy to be used directly locally; there was always a dependency on cloud-based services.
However, considering the latest advancements with quantization tricks like QLoRa and GPTQ, some LLMs have become manageable on our everyday gadgets - like our local computers.
The Hugging Face TGI is specifically designed to provide us with LLMs as a service on our local machines. The main reason behind this is the hustle of booting up a LLM.
To skip the downtime, it's smarter to keep the model ready in the background, primed for quickfire responses. Otherwise, you're stuck in a loop of lengthy waits every time you prompt it. Just imagine having an endpoint with a collection of the finest language models at your beck and call, ready to weave words at your whim.
What caught my eye about TGI was its no-fuss approach. Right now, TGI is prepped to work with a bunch of streamlined model architectures, making it a breeze to deploy them in a snap.
And it's not just talk; TGI is already the engine behind several live projects. Some examples are:

Image by Author. Logos of Hugging Chat (Left) and OpenAssistant (Right)
There's a significant catch, however. TGI is not yet compatible with ARM-based GPU Macs, including the M1 series and later models.
First, we need to set up our Hugging Face TGI end-point.
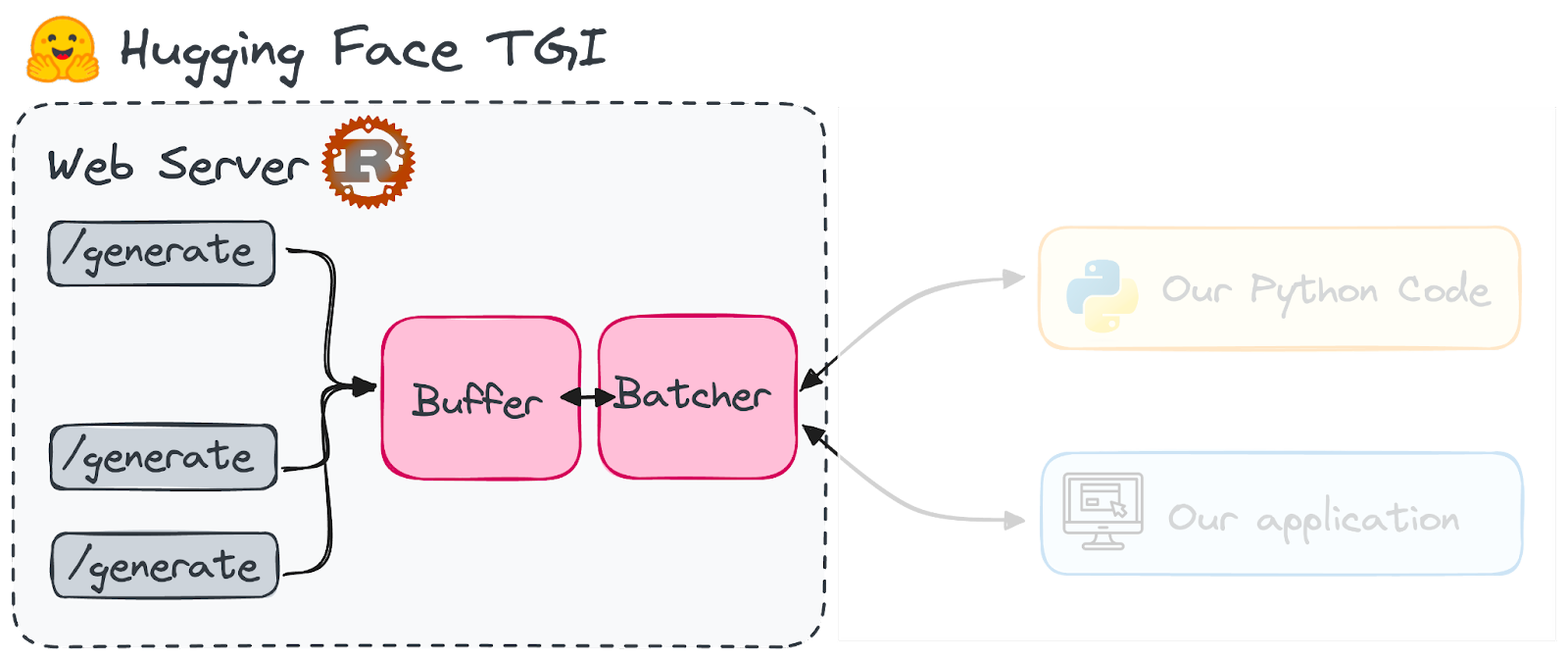
Image by Author.
To install and launch locally Hugging Face TGI, first you need to install Rust and then create a Python virtual environment with at least Python 3.9, e.g. using conda:
#Installing Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
#Creating a python virtual environment
conda create -n text-generation-inference python=3.9
conda activate text-generation-inferenceAdditionally, Protoc installation is necessary. Hugging Face suggests using version 21.12 for optimal compatibility. Note that you'll require sudo privileges to proceed with this installation.
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
sudo unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
sudo unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIPI will first present how to install it from scratch, which I think is not straightforward. If you run into issues during the process, you can skip this first part and directly run a Docker image instead, which is more straightforward. Both scenarios will be addressed.
With all the prerequisites in place, we're ready to set up TGI. Begin by cloning the GitHub repository:
git clone https://github.com/huggingface/text-generation-inference.gitThen, switch to the TGI location on your local computer and install it with the following commands:
cd text-generation-inference/
BUILD_EXTENSIONS=False make installNow let’s see how to use TGI, both with and without Docker. I will be using the Falcon-7B model, which is available under the Apache 2.0 license.
The installation created a new command, “text-generation-launcher” that will start the TGI server. To activate an end-point with the Falcon-7B model, we just need to execute the following command:
text-generation-launcher --model-id tiiuae/falcon-7b-instruct --num-shard 1 --port 8080 --quantize bitsandbytesWhere each input parameter is:
Make sure you have Docker installed on your computer and it’s already running. If you have no experience with Docker, you can follow this Docker for Data Science Tutorial that will give you the most basic notions.
Remember, TGI is not compatible with MX-processor Mac models. You can check all available TGI images in the corresponding TGI packages GitHub repository. If your device is compatible, Docker should find the corresponding image for you.
The parameters closely mirror those used with the text-generation-launcher. If you're operating with just a single GPU, substitute "all" for "0".
volume=$PWD/data
sudo docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:0.9 --model-id tiiuae/falcon-7b-instruct --num-shard 1 --quantize bitsandbytesMake sure that the Docker image remains active for the duration you intend to use the server.
You have multiple options for integrating the Text Generation Inference (TGI) server into your applications. Once it's up and running, you can interact with it by making a POST request to the /generate endpoint to retrieve results.
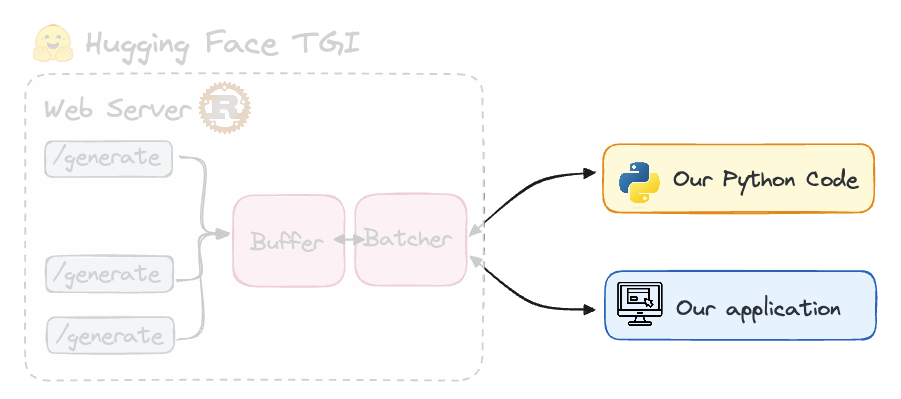
Image by Author.
If you prefer TGI to stream tokens continuously, use the endpoint instead, as we will see in the coming section. These requests can be made using your tool of choice, including curl, Python, or TypeScript. To query the model served by TGI with a Python script, you will have to install the following text-generation library. It is as easy as executing the following pip command:
pip install text-generationOnce you start the TGI server, instantiate InferenceClient() with the URL to the endpoint serving the model. You can then call text_generation() to hit the endpoint through Python.
from text_generation import Client
client = Client("http://127.0.0.1:8080")
client.text_generation(prompt="Your prompt here!")To enable streaming with the InferenceClient, you simply need to set stream=True. This will allow you to receive tokens in real time as they are generated on the server. Here’s how you can use streaming:
for token in client.text_generation("Your prompt here!", max_new_tokens=12, stream=True):
print(token)Remember you will be working with the model you deployed in your endpoint, in our case, Falcon-7B. By using TGI, we create a live endpoint that allows us to retrieve responses from the LLM of our choice.
Consequently, when using Python, we can directly send prompts to the LLM via the client hosted on our local device, accessible through port 8080. So the corresponding Python script would look something like this:
from text_generation import Client
client = Client("http://127.0.0.1:8080")
print(client.generate("Translate the following sentence into spanish: 'What does Large Language Model mean?'", max_new_tokens=500).generated_text)And we will obtain a response from the model without the need to installing it in our environment. Instead of using Python, we can query the LLM with CURL, as you can observe in the following example:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"Code in Javascript a function to remove all spaces in a string and then print the string twice.","parameters":{"max_new_tokens":500}}' \
-H 'Content-Type: application/json'After playing a bit with TGI, it showcases an impressive speed. Using Falcon-7B (with a token limit of 500) it takes a few seconds. However, when employing the typical inference approach (using the transformers library) it takes around 30 seconds.
From version 1.4.0 onwards, TGI has introduced an API that is compatible with OpenAI's Chat Completion API. This new Messages API enables a smooth transition for customers and users from OpenAI models to open-source LLMs. The API is designed for direct integration with OpenAI's client libraries or with third-party tools such as LangChain or LlamaIndex.
TGI's support for Messages ensures that its Inference Endpoints are fully compatible with the OpenAI Chat Completion API. This compatibility allows users to easily replace any existing scripts that use OpenAI models with open LLMs hosted on TGI endpoints without any hassle.
This upgrade facilitates an effortless switch, granting immediate access to the extensive advantages of open-source models, including:
An example of how to integrate TGI in the OpenAI chat completion protocol is attached as follows:
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI(
base_url="<ENDPOINT_URL>" + "/v1/", # replace with your endpoint url
api_key="<HF_API_TOKEN>", # replace with your token
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Why is open-source software important?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
print(message.choices[0].delta.content, end="")As you can observe, the openai library can be used to point out our ENDPOINT and our Hugging Face password. To understand this integration further, you can check the Hugging Face TGI documentation.
Before crashing into HuggingFace TGI, you should already be familiar with Large Language Models. Familiarise yourself with key concepts like tokenization, attention mechanisms, and the Transformer architecture. These foundations are crucial for customizing models and refining text generation outputs.
Learn to prepare and optimize models for your specific needs. This includes selecting the right model, customizing tokenizers, and employing techniques to enhance performance without sacrificing quality.
Ensure you understand how HuggingFace works and how to use its HuggingFace Hub for NLP development. A good introductory tutorial to do so is An Introduction to Using Transformers and Hugging Face.
Fine-tuning is a concept you should be aware of as well, as most of the time, models need to be optimized for specific goals. You can learn how to fine-tune a model with the An Introductory Guide to Fine-Tuning LLMs
Explore various strategies for text generation, such as greedy search, beam search, and top-k sampling. Each strategy has its pros and cons, impacting the coherence, creativity, and relevance of the generated text.
Hugging Face's TGI toolkit empowers anyone to explore AI text generation. It offers an easy-to-use toolkit to deploy and host LLMs for advanced NLP applications that require human-like text.
While self-hosting large language models offers data privacy and cost control, it requires powerful hardware. However, the latest advancements in the field allow for small models to be directly used on our local machines.
If you want to keep getting better in the LLM field, I strongly encourage you to perform some more advanced tutorials. You can start with DataCamp’s LLM Concepts course, which covers many of the key training methodologies and the latest research.
Some other good resources to follow are:
Start Your AI Journey Today!
Track
Course
Course
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
code-along
Jacob Marquez
code-along
Alara Dirik
code-along
Priyanka Asnani





