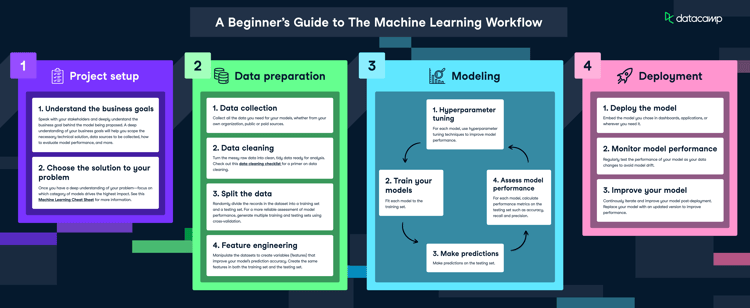
Course
Designing Machine Learning Workflows in Python
4 hr
12.6K
MLOps is an important part of machine learning because it helps to automate the training and deployment of machine learning models. This automation can help to speed up the process of developing and deploying machine learning models and help ensure that models are deployed correctly. MLOps can also help to monitor the performance of machine learning models and identify issues proactively that may need to be addressed in production.
The landscape of MLOps in 2022 consists of various tools and services that will help organizations automate the building, training, and deploying of machine learning models. These tools and services are designed to work together to make the process of MLOps more efficient and easier to manage. MLflow is one such important tool that we will explore in this blog post.
MLflow is an open-source platform for the end-to-end machine learning lifecycle. It lets data scientists track their experiments, reproduce runs, and serve their models as endpoints. In this article, we will take a deep dive into what MLflow is and how you can leverage this amazing open-source platform for tracking and deploying your machine learning experiments.
If you want a closer look at MLOps, check out our Machine Learning, Pipelines, Deployment, and MLOps Tutorial.
MLFlow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides a central place for tracking experiments, sharing code and models, and deploying models to production. MLflow also includes several built-in algorithms and packages for popular ML toolkits. It has four primary functions:
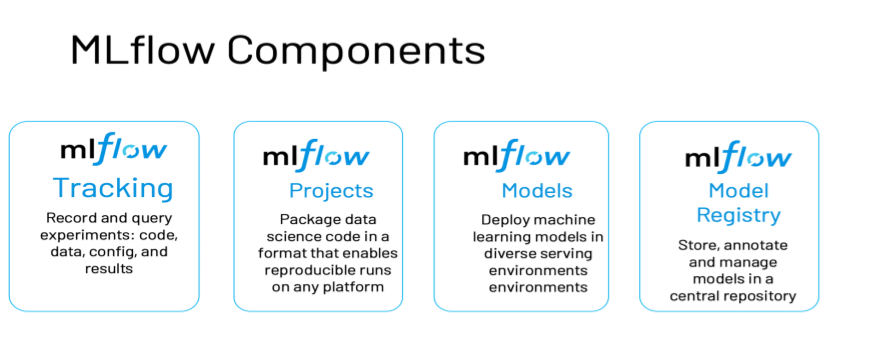
Image Source: https://www.databricks.com/wp-content/uploads/2021/02/mlflow-components2.png
MLflow is not tied to any one library. Since all functions can be accessed by a REST API and a command line interface, you can use it with any machine learning library and in any programming language. A Python API, an R API, and a Java API are all incorporated into the project for your convenience.
When you run machine learning code, the MLflow Tracking component provides an API and a graphical user interface (UI) for logging the parameters, code versions, metrics, and output files. Afterward, you can visualize the results of the logging. You can also log and query experiments using Python, REST, R API, and Java API APIs thanks to MLflow Tracking.
MLflow Tracking is organized around the concept of runs. Each run records the key information and metadata such as start and end time, source file, parameters, artifacts, metrics, tags, etc.
You can record runs using MLflow Python, R, or Java APIs from any location, regardless of where your code is being executed. You could, for instance, record them in a standalone program, on a remote cloud machine, or in an interactive notebook.
Similarly, you can organize individual runs into experiments, which are collections of runs grouped together for a particular purpose. The command-line interface (CLI), the mlflow.create experiment() method or the REST API are a few options used to initiate the creation of an experiment. Users can create experiments using the MLflow UI as well.
If you need them, you can save recordings of MLflow runs locally to files, upload them to a database compatible with SQLAlchemy, or upload them remotely to a tracking server. The MLflow Python API logs run locally to files in the mlruns directory of the location where your program ran. This behavior is the default. After that, you can view the logged runs by launching the mlflow ui application.
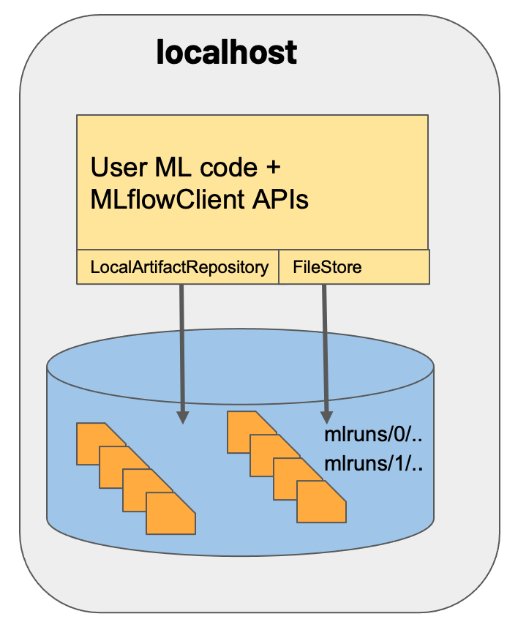
Image Source: https://mlflow.org/docs/latest/_images/scenario_1.png
MLflow Projects are a way to structure your machine learning code in a reusable and reproducible way. You can use projects with any machine learning library and development environment. Each project is composed of a directory containing an MLproject file, which describes the project environment and parameters, and a set of files containing machine learning code.
MLflow now supports the following types of project environments:
By adding an MLProject file, which is simply a YAML file, you can get more granular control over the MLflow project. The below is the example MLProject file:
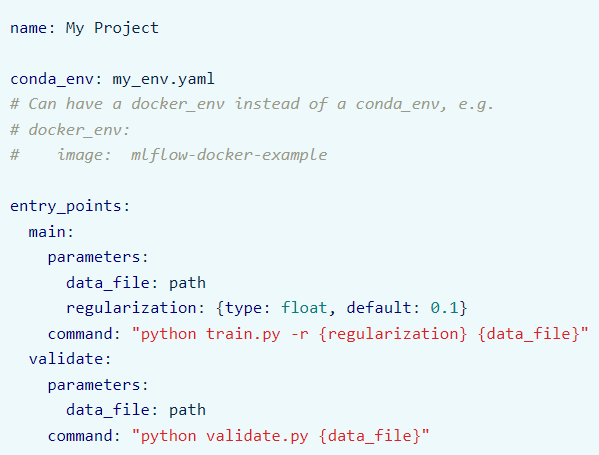
Source: https://mlflow.org/docs/latest/projects.html#overview
When the project doesn’t contain an MLproject file, there are some default conventions that MLflow will assume, such as:
An MLflow Model is a standardized format for packaging machine learning models that can then be utilized in a variety of tools further down the pipeline. This could include real-time serving over a REST API or a batch inference process. MLflow Model is one of the key components of MLflow. It specifies a protocol that enables the saving of a model in a number of distinct "flavors," each of which can be comprehended by a unique set of downstream tools.
Each MLflow Model is actually a directory that stores arbitrary files together with an MLmodel file that sits at the base of the directory and can define several flavors in which the model can be viewed. These files are referred to collectively as the MLflow Model.
The core idea behind the power of MLflow Models is their usage of flavors, which serve as a standard for deployment tools to comprehend the model. This allows developers to create tools that can interact with models from any ML library without having to integrate each tool with each library. One "standard" flavor supported by all of MLflow's built-in deployment tools is "Python Function," which outlines how to run the model as a Python function.
An example of an MLflow Models directory using Scikit-learn flavor:
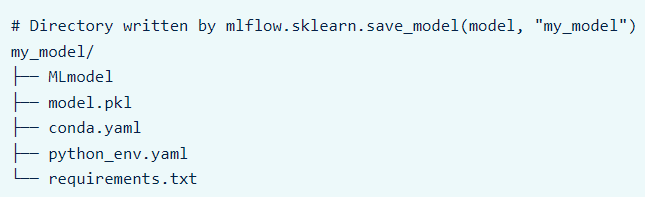
Image Source: https://mlflow.org/docs/latest/models.html
MLflow supports the following libraries (as model flavors) out of the box:
The MLflow Model Registry is a central repository for storing and versioning ML models. It provides a way to track the lineage of models, compare models, and deploy models.
The MLflow Model Registry component is a set of APIs and a user interface to collaboratively manage an MLflow Model's entire lifecycle.
Accessing the model registry through the user interface (UI) or the application programming interface (API) requires the use of a database-backed backend store if you want to use Model Registry.
Registering model using MLflow UI:
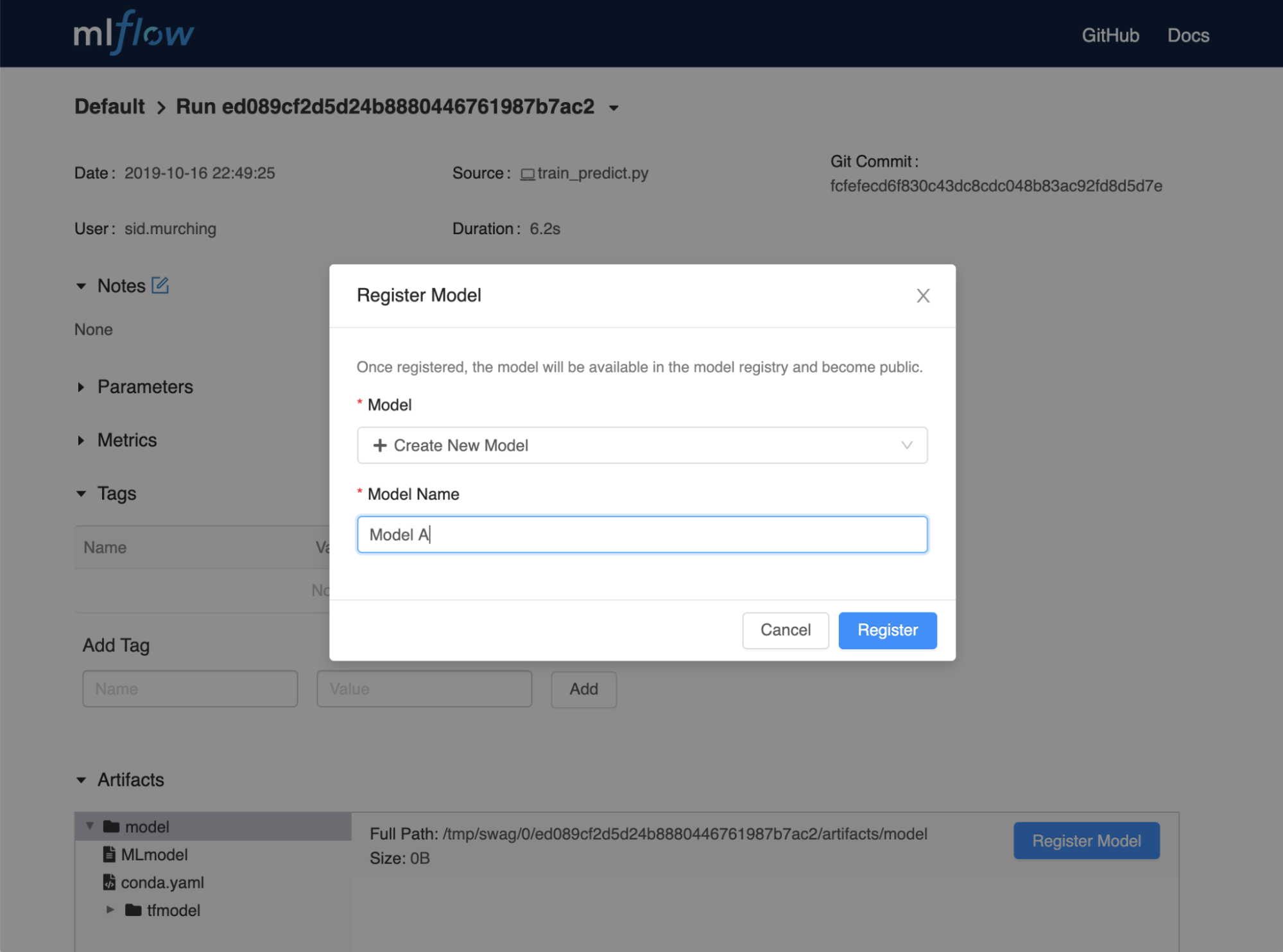
Image Source: https://mlflow.org/docs/latest/model-registry.html#concepts
MLflow Pipelines is a new capability and is still in experimental mode.
The development and productionization of machine learning applications are made easier and more standardized by using MLflow Pipelines, an opinionated framework for structuring MLOps workflows. Data scientists now have more time to devote to creating high-quality models thanks to MLflow Pipelines, which makes it simple for them to adhere to industry standards when building production-ready machine learning deliverables.
MLflow Pipelines also make it possible for machine learning engineers and DevOps teams to embed these models into apps and release them to production in a seamless manner.
MLflow Pipelines offers production-quality pipeline templates for typical machine learning issue types, such as regression and classification, and MLOps operations, such as batch scoring. Pipelines are structured as git repositories with YAML-based configuration files and Python code. This offers developers a declarative approach to the construction of ML applications, which decreases the amount of boilerplate code.
MLflow Pipelines also implement a cache-aware executor for pipeline steps. This ensures that steps are only carried out when there has been a change in the corresponding code or configuration. Because of this, data scientists, machine learning engineers, and DevOps teams can iterate very quickly within their own specialized fields. In addition, executing pipelines and examining their output can be done via APIs and a command line interface (CLI) provided by MLflow.
|
Deploying machine learning models in production seems easy with modern tools, but often ends in disappointment as the model performs worse in production than in development. If you want to learn how to design machine learning workflows in Python that stand the test of time, check out our Designing Machine Learning Workflows in Python course. |
Now that you understand what MLflow is, let’s address a very common question in the field; what is the difference between MLflow and Kubeflow?
First, what is Kubeflow?
Kubeflow is an open-source project that contains a curated set of tools and frameworks. The primary goal of Kubeflow is to make it easy to develop, deploy, and manage portable, scalable machine learning workflows.
Kubeflow is built on top of Kubernetes, an open-source platform for running and orchestrating containers. Kubernetes is constructed to run consistently across different environments, which is key to how Kubeflow operates.
To learn more about Kubeflow, read our detailed tutorial on Kubeflow.
When comparing MLflow and Kubeflow, the only similarity between these two projects is that they are both open-source but serve completely different needs. Kubeflow is an open-source container orchestration system to develop, deploy, and manage machine learning applications on Kubernetes. On the other hand, MLflow is a Python library for experiment tracking and model versioning/deployment, regardless of the orchestration environment.
Using MLflow is extremely easy. It takes only a few lines of code to integrate MLflow logging in your existing code. But first, you have to install MLflow using pip.
# install mlflow
pip install mlflow
Let’s create a simple Python script to train a logistic regression model and log the metric and model using MLflow. This is an official example from MLflow, reproduced from here.
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
OUTPUT:
>>> Score: 0.6666666666666666
>>> Model saved in run 9def2bd1c55b4f0985aa5c050b8f71cd
You can start the MLflow UI by typing `mlflow ui` on the command line terminal in the same directory your python file is in.
mlflow ui
Then navigate to https://localhost:5000, and you will see this page:
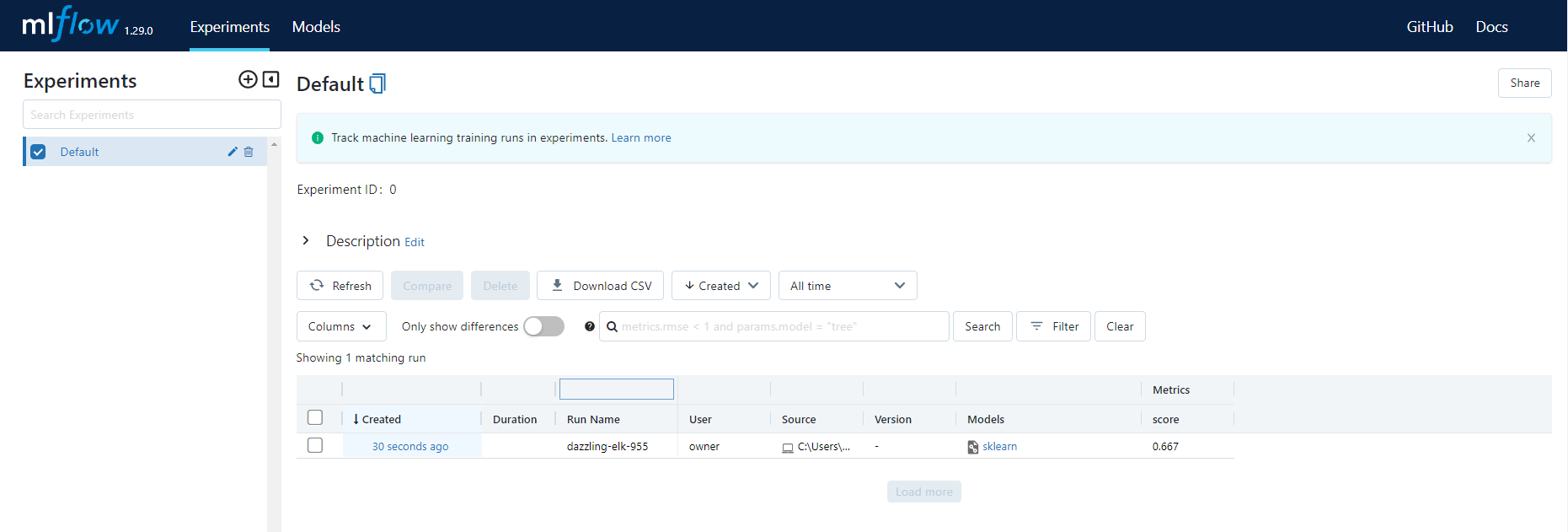
You can see we only have one record, i.e., the model we trained and logged in the script above. Click on the name, and you will see a detailed page:
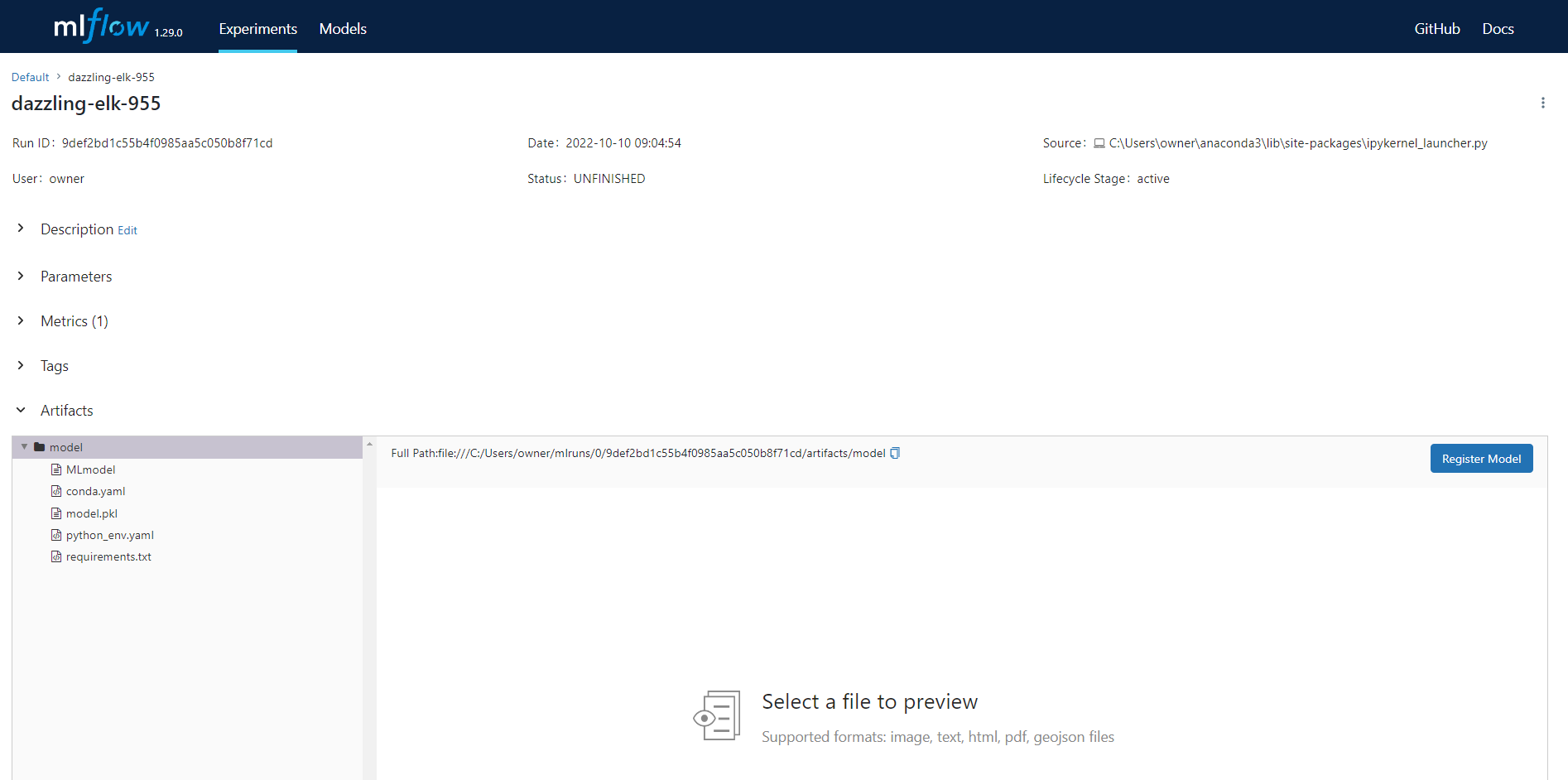
|
UPSKILL YOURSELF NOW! ENROLL TODAY in Machine Learning Scientist with Python Master the essential skills to land a job as a machine learning scientist. You'll augment your Python programming skill set with the toolbox to perform supervised, unsupervised, and deep learning. You will learn:
|
MLflow is an open-source platform and a great tool for managing the end-to-end machine learning lifecycle. It was created by Databricks, the company behind the popular Apache Spark platform, and is designed to work with any machine learning library, algorithm, or language.
MLflow offers a number of benefits for machine learning developers and data scientists. It provides a central place to track experiments and manage machine learning projects. This can be a valuable tool for collaboration, as it allows different team members to see what others are doing and compare results.
MLflow can automate the machine learning workflow, from data preprocessing to model training to deployment. This can save time and effort and make it easier to reproduce results.
Overall, MLflow is a valuable tool for managing machine learning projects. It can help you track experiments, automate the workflow, and optimize models. If you are working on machine learning projects, you should definitely check out MLflow.
|
If you want to upskill and understand the fundamentals of Machine Learning and its application in the business world, check out our Machine Learning for Business course on DataCamp. |
Machine Learning Courses
Course
Course
blog
DataCamp Team
2 min
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
code-along
Weston Bassler
code-along
Folkert Stijnman