Course
Introduction to Importing Data in Python
3 hr
336.8K
In Part I of this tutorial the focus was determining the number of games that a Major-League Baseball (MLB) team won that season, based on the team’s statistics and other variables from that season.
In the second part of this project, you’ll test out a logistic regression model and a random forest model from Scikit-Learn (sklearn) to predict which players will be voted into the Hall of Fame, based on the player’s career statistics and awards. Each row will consist of a single player and data related to their career. There are four main position subgroups in baseball: Infielders, Outfielders, Pitchers, and Catchers. The focus of this project will be on Infielders and Outfielders.

The National Baseball Hall of Fame and Museum is located in Cooperstown, New York and was dedicated in 1939. A baseball player can be elected to the Hall of Fame if they meet the following criteria:
A player who does not get elected to the Hall of Fame can be added by the Veterans Committee or a Special Committee appointed by the Commissioner of Major League Baseball, but this project will focus only on players who were voted into the Hall of Fame. Fundamentally, what you want to know is:
“Can you build a machine learning model that can accurately predict if an MLB baseball player will be voted into the Hall of Fame?”.
In the first part of this project, you loaded the data from an SQLite database. This time, you’ll load the data from CSV files. Sean Lahman compiled this data on his website.
You will need to read in the data from the following CSV files into pandas DataFrames:
Master.csv will tell you more about the player names, Date Of Birth (DOB), and biographical info;Fielding.csv contains the fielding statistics, whileBatting.csv contains the Batting statistics;AwardsPlayers.csv, in which you’ll find data on the awards won by baseball players;AllstarFull.csv file wil give you all the All-Star appearances;HallOfFame.csv; andAppearances.csv, which contains details on the positions at which a player appeared.Don’t worry if some concepts aren’t clear yet, you’ll get more information as you go through the tutorial!
First, download the CSV files by clicking here. Ideally, put all of the data into one specific folder which will contain all the files for this project. Next, open up your terminal or start the Jupyter Notebook Application and you can start working!
Load pandas and rename to pd, then read in each of the CSV files. You’ll only include certain columns, and you can review the available columns here.
# Import data to DataFramesimport pandas as pd# Read in the CSV filesmaster_df = pd.read_csv('Master.csv',usecols=['playerID','nameFirst','nameLast','bats','throws','debut','finalGame'])fielding_df = pd.read_csv('Fielding.csv',usecols=['playerID','yearID','stint','teamID','lgID','POS','G','GS','InnOuts','PO','A','E','DP'])batting_df = pd.read_csv('Batting.csv')awards_df = pd.read_csv('AwardsPlayers.csv', usecols=['playerID','awardID','yearID'])allstar_df = pd.read_csv('AllstarFull.csv', usecols=['playerID','yearID'])hof_df = pd.read_csv('HallOfFame.csv',usecols=['playerID','yearid','votedBy','needed_note','inducted','category'])appearances_df = pd.read_csv('Appearances.csv')Note that for this tutorial, the data will be loaded in for you!
Now that you have imported the data, you can start cleaning and preprocessing it. Because you’re working with 7 CSV files, it’s best to start by looking at them one by one: in the following sections, you’ll go over the separate DataFrames and this in the following order: batting_df, fielding_df, awards_df, allstar_df, hof_df, appearances_df, and master_df.
batting_dfFirst, you’ll be working on the batting_df DataFrame. Print out the first few rows with the help of the head() function:
Tip because you pulled in all columns from this data table, it’s wise to use the columns attribute to also pull up the columns of the batting_df DataFrame to see what you’re dealing with. Also, feel free to use any other Pandas functions to inspect your data thoroughly!
When you inspect the results, you’ll notice three things about the batting_df and its columns:
playerID, for the Player ID code.yearID, which lists the year;teamID identifies the team for which a player plays;lgID identifies the league;batting_df, there are a lot of statistics on the players; Here are some examples:G for the number of games,ABfor the number at bats;R to indicate the number of runs;H for the number of hits;HR for the number of Homeruns;RBI for the Runs Batted In;SO or Strikeouts.To do this, you’ll be creating dictionaries for each player within a dictionary. Each player’s stats will be aggregated to their dictionary, and then the main dictionary can be converted to a DataFrame.
To start, create a dictionary for player’s stats and one for years played. Aggregate each player’s statistics from batting_df into player_stats and data on which years they played into years_played:
# Initialize dictionaries for player stats and years playedplayer_stats = {}years_played = {}# Create dictionaries for player stats and years played from `batting_df`for i, row in batting_df.iterrows(): playerID = row['playerID'] if playerID in player_stats: player_stats[playerID]['G'] = player_stats[playerID]['G'] + row['G'] player_stats[playerID]['AB'] = player_stats[playerID]['AB'] + row['AB'] player_stats[playerID]['R'] = player_stats[playerID]['R'] + row['R'] player_stats[playerID]['H'] = player_stats[playerID]['H'] + row['H'] player_stats[playerID]['2B'] = player_stats[playerID]['2B'] + row['2B'] player_stats[playerID]['3B'] = player_stats[playerID]['3B'] + row['3B'] player_stats[playerID]['HR'] = player_stats[playerID]['HR'] + row['HR'] player_stats[playerID]['RBI'] = player_stats[playerID]['RBI'] + row['RBI'] player_stats[playerID]['SB'] = player_stats[playerID]['SB'] + row['SB'] player_stats[playerID]['BB'] = player_stats[playerID]['BB'] + row['BB'] player_stats[playerID]['SO'] = player_stats[playerID]['SO'] + row['SO'] player_stats[playerID]['IBB'] = player_stats[playerID]['IBB'] + row['IBB'] player_stats[playerID]['HBP'] = player_stats[playerID]['HBP'] + row['HBP'] player_stats[playerID]['SH'] = player_stats[playerID]['SH'] + row['SH'] player_stats[playerID]['SF'] = player_stats[playerID]['SF'] + row['SF'] years_played[playerID].append(row['yearID']) else: player_stats[playerID] = {} player_stats[playerID]['G'] = row['G'] player_stats[playerID]['AB'] = row['AB'] player_stats[playerID]['R'] = row['R'] player_stats[playerID]['H'] = row['H'] player_stats[playerID]['2B'] = row['2B'] player_stats[playerID]['3B'] = row['3B'] player_stats[playerID]['HR'] = row['HR'] player_stats[playerID]['RBI'] = row['RBI'] player_stats[playerID]['SB'] = row['SB'] player_stats[playerID]['BB'] = row['BB'] player_stats[playerID]['SO'] = row['SO'] player_stats[playerID]['IBB'] = row['IBB'] player_stats[playerID]['HBP'] = row['HBP'] player_stats[playerID]['SH'] = row['SH'] player_stats[playerID]['SF'] = row['SF'] years_played[playerID] = [] years_played[playerID].append(row['yearID'])Now, iterate through the years_played dictionary and add the number of years played by each player into the player_stats dictionary:
# Iterate through `years_played` and add the number of years played to `player_stats`for k, v in years_played.items(): player_stats[k]['Years_Played'] = len(list(set(v)))fielding_dfNext up is the fielding_df. The data from this table contains more player statistics and is therefore very similar to the batting_df. As you aggregated each player’s statistics in the player_stats dictionary above, it’s a good idea to also aggregate the statistics from fielding_df into the player_stats dictionary.
More specifically, you’ll need to add new keys to each player’s dictionary within the player_stats dictionary as you iterate through fielding_df. First, make sure to create a fielder_list to identify which players have had their fielding keys entered so the stats can be added properly:
# Initialize `fielder_list`fielder_list = []# Add fielding stats to `player_stats` from `fielding_df`for i, row in fielding_df.iterrows(): playerID = row['playerID'] Gf = row['G'] GSf = row['GS'] POf = row['PO'] Af = row['A'] Ef = row['E'] DPf = row['DP'] if playerID in player_stats and playerID in fielder_list: player_stats[playerID]['Gf'] = player_stats[playerID]['Gf'] + Gf player_stats[playerID]['GSf'] = player_stats[playerID]['GSf'] + GSf player_stats[playerID]['POf'] = player_stats[playerID]['POf'] + POf player_stats[playerID]['Af'] = player_stats[playerID]['Af'] + Af player_stats[playerID]['Ef'] = player_stats[playerID]['Ef'] + Ef player_stats[playerID]['DPf'] = player_stats[playerID]['DPf'] + DPf else: fielder_list.append(playerID) player_stats[playerID]['Gf'] = Gf player_stats[playerID]['GSf'] = GSf player_stats[playerID]['POf'] = POf player_stats[playerID]['Af'] = Af player_stats[playerID]['Ef'] = Ef player_stats[playerID]['DPf'] = DPfawards_dfNext up is the awards_df DataFrame: throughout a player’s career, there are many different awards they may receive for excellent achievement. The awards_df contains all the data on the awards won by players.
A good way to inspect your data here is to print out the unique awards within awards_df using the unique() method. Alternatively, you can also experiment with the head(), tail(), info(), … functions to get to know the data in this DataFrame better.
Tip: from the first code chunk, you know that you only read in three columns from the original data table: playerID, awardID, and yearID.
As you can see, there are quite a few options in awards_df… Do you know all these awards?
As mentioned in Part I of this tutorial, knowledge of the data you’re working with is very important. For example, the best awards to include are the Most Valuable Player, Rookie of the Year, Gold Glove, Silver Slugger, and World Series MVP awards and I determined that entirely based on my experience following MLB Baseball.
It obviously could be determined which of these awards is most correlated with being voted into the Hall of Fame, but that would require much more coding.
Now you need to add a count for each award into each player’s dictionary within the player_stats dictionary: first, filter the awards_df for each of the awards listed above, creating five new series. Then create a list called awards_list and include each of the five series in the list. As you did above with fielding_df, create a list to identify which keys have been added to the dictionaries within player_stats for each of the five awards series. Now create a list called lists and include each of the five lists. You’re now ready to loop through awards_list, and iterate through each of the awards series counting how many of each award each player has:
# Create DataFrames for each awardmvp = awards_df[awards_df['awardID'] == 'Most Valuable Player']roy = awards_df[awards_df['awardID'] == 'Rookie of the Year']gg = awards_df[awards_df['awardID'] == 'Gold Glove']ss = awards_df[awards_df['awardID'] == 'Silver Slugger']ws_mvp = awards_df[awards_df['awardID'] == 'World Series MVP']# Include each DataFrame in `awards_list`awards_list = [mvp,roy,gg,ss,ws_mvp]# Initialize lists for each of the above DataFramesmvp_list = []roy_list = []gg_list = []ss_list = []ws_mvp_list = []# Include each of the above lists in `lists`lists = [mvp_list,roy_list,gg_list,ss_list,ws_mvp_list]# Add a count for each award for each player in `player_stats`for index, v in enumerate(awards_list): for i, row in v.iterrows(): playerID = row['playerID'] award = row['awardID'] if playerID in player_stats and playerID in lists[index]: player_stats[playerID][award] += 1 else: lists[index].append(playerID) player_stats[playerID][award] = 1allstar_dfThe allstar_df DataFrame contains information on which players made appearances in Allstar games. The Allstar game is an exhibition game played each year at mid-season. Major League Baseball consists of two leagues: the American league and the National league. The top 25 players from each league are selected to represent their league in the Allstar game.
As you did previously, iterate through allstar_df and add a count of Allstar game appearances to each dictionary within player_stats.
# Initialize `allstar_list`allstar_list = []# Add a count for each Allstar game appearance for each player in `player_stats`for i, row in allstar_df.iterrows(): playerID = row['playerID'] if playerID in player_stats and playerID in allstar_list: player_stats[playerID]['AS_games'] += 1 else: allstar_list.append(playerID) player_stats[playerID]['AS_games'] = 1hof_dfNext up is the hof_df DataFrame, which contains information on which players, managers, and executives have been nominated or inducted into the Hall of Fame, and by what method.
Adding this type of information to your player_stats might be valuable! To do this, filter hof_df first to include only players who were inducted into the Hall of Fame. Then iterate through hof_df indicating which players in player_stats have been inducted into the Hall of Fame as well as how they were inducted:
# filter `hof_df` to include only instances where a player was inducted into the Hall of Famehof_df = hof_df[(hof_df['inducted'] == 'Y') & (hof_df['category'] == 'Player')]# Indicate which players in `player_stats` were inducted into the Hall of Famefor i, row in hof_df.iterrows(): playerID = row['playerID'] if playerID in player_stats: player_stats[playerID]['HoF'] = 1 player_stats[playerID]['votedBy'] = row['votedBy']player_statsYou’ve now compiled data from batting_df, fielding_df, awards_df, allstar_df, and hof_df into the player_stats dictionary. You have a bit more work to do with the appearances_df DataFrame, but now is a good time to convert the player_stats dictionary into a DataFrame.
Use the pandas from_dict() method to convert the dictionary to a DataFrame called stats_df:
# Convert `player_stats` into a DataFramestats_df = pd.DataFrame.from_dict(player_stats, orient='index')The stats_df DataFrame is using each player’s unique player ID as the index. Add a column to stats_df called playerID derived from the index. Then join stats_df with master_df using an inner join.
Remember that an inner join selects all rows from both tables as long as there is a match between the columns. In this case, you use an inner join because you want to match the information of stats_df with the master_df data: you want to keep on working with the rows that are common to both DataFrames.
appearances_dfThe last DataFrame that you loaded in and need to look at before you can start creating new features for your data is appearances_df. This DataFrame contains information on how many appearances each player had at each position for each year.
Print out the first few rows using the head() method:
Tip: use the IPython Console to inspect your data with other functions such as info(), tail(), the attributes columns and index, … You’ll see that the appearances_df has 21 columns, which in some cases are pretty straightforward (think of the ID columns that you already saw in other DataFrames), but in other cases, you see that they have somewhat cryptic names, such as G_3b, G_dh, and so on.
Now is a good time to take a look at the information that the the README page gives you:
G_all Total games playedGS Games startedG_batting Games in which player battedG_defense Games in which player appeared on defenseG_p Games as pitcherG_c Games as catcherG_1b Games as firstbasemanG_2b Games as secondbasemanG_3b Games as thirdbasemanG_ss Games as shortstopG_lf Games as leftfielderG_cf Games as centerfielderG_rf Games as right fielderG_of Games as outfielderG_dh Games as designated hitterG_ph Games as pinch hitterG_pr Games as pinch runnerIn an instant, you see that there is a lot of information in appearances_df that needs to be extracted. You also see that you need to aggregate each players number of appearances to find the total number of career appearances at each position.
As you may recall from the first part of this tutorial, as MLB progressed, different eras emerged where the amount of runs per game increased or decreased significantly. This means that when a player played has a large influence on that player’s career statistics. The Hall of Fame (HoF) voters take this into account when voting players in, so your model needs that information too.
To gather this information, create a dictionary called pos_dict. Loop through appearances_df and add a dictionary for each player as you did above with the player_stats dictionary. Aggregate each player’s appearances at each position for each season they played using the position as a key and the appearances count as the value. You’ll also need to aggregate the number of games each player played in each era using the era as a key and the games played count as the value.
# Initialize a dictionarypos_dict = {}# Iterate through `appearances_df`# Add a count for the number of appearances for each player at each position# Also add a count for the number of games played for each player in each era.for i, row in appearances_df.iterrows(): ID = row['playerID'] year = row['yearID'] if ID in pos_dict: pos_dict[ID]['G_all'] = pos_dict[ID]['G_all'] + row['G_all'] pos_dict[ID]['G_p'] = pos_dict[ID]['G_p'] + row['G_p'] pos_dict[ID]['G_c'] = pos_dict[ID]['G_c'] + row['G_c'] pos_dict[ID]['G_1b'] = pos_dict[ID]['G_1b'] + row['G_1b'] pos_dict[ID]['G_2b'] = pos_dict[ID]['G_2b'] + row['G_2b'] pos_dict[ID]['G_3b'] = pos_dict[ID]['G_3b'] + row['G_3b'] pos_dict[ID]['G_ss'] = pos_dict[ID]['G_ss'] + row['G_ss'] pos_dict[ID]['G_lf'] = pos_dict[ID]['G_lf'] + row['G_lf'] pos_dict[ID]['G_cf'] = pos_dict[ID]['G_cf'] + row['G_cf'] pos_dict[ID]['G_rf'] = pos_dict[ID]['G_rf'] + row['G_rf'] pos_dict[ID]['G_of'] = pos_dict[ID]['G_of'] + row['G_of'] pos_dict[ID]['G_dh'] = pos_dict[ID]['G_dh'] + row['G_dh'] if year < 1920: pos_dict[ID]['pre1920'] = pos_dict[ID]['pre1920'] + row['G_all'] elif year >= 1920 and year <= 1941: pos_dict[ID]['1920-41'] = pos_dict[ID]['1920-41'] + row['G_all'] elif year >= 1942 and year <= 1945: pos_dict[ID]['1942-45'] = pos_dict[ID]['1942-45'] + row['G_all'] elif year >= 1946 and year <= 1962: pos_dict[ID]['1946-62'] = pos_dict[ID]['1946-62'] + row['G_all'] elif year >= 1963 and year <= 1976: pos_dict[ID]['1963-76'] = pos_dict[ID]['1963-76'] + row['G_all'] elif year >= 1977 and year <= 1992: pos_dict[ID]['1977-92'] = pos_dict[ID]['1977-92'] + row['G_all'] elif year >= 1993 and year <= 2009: pos_dict[ID]['1993-2009'] = pos_dict[ID]['1993-2009'] + row['G_all'] elif year > 2009: pos_dict[ID]['post2009'] = pos_dict[ID]['post2009'] + row['G_all'] else: pos_dict[ID] = {} pos_dict[ID]['G_all'] = row['G_all'] pos_dict[ID]['G_p'] = row['G_p'] pos_dict[ID]['G_c'] = row['G_c'] pos_dict[ID]['G_1b'] = row['G_1b'] pos_dict[ID]['G_2b'] = row['G_2b'] pos_dict[ID]['G_3b'] = row['G_3b'] pos_dict[ID]['G_ss'] = row['G_ss'] pos_dict[ID]['G_lf'] = row['G_lf'] pos_dict[ID]['G_cf'] = row['G_cf'] pos_dict[ID]['G_rf'] = row['G_rf'] pos_dict[ID]['G_of'] = row['G_of'] pos_dict[ID]['G_dh'] = row['G_dh'] pos_dict[ID]['pre1920'] = 0 pos_dict[ID]['1920-41'] = 0 pos_dict[ID]['1942-45'] = 0 pos_dict[ID]['1946-62'] = 0 pos_dict[ID]['1963-76'] = 0 pos_dict[ID]['1977-92'] = 0 pos_dict[ID]['1993-2009'] = 0 pos_dict[ID]['post2009'] = 0 if year < 1920: pos_dict[ID]['pre1920'] = row['G_all'] elif year >= 1920 and year <= 1941: pos_dict[ID]['1920-41'] = row['G_all'] elif year >= 1942 and year <= 1945: pos_dict[ID]['1942-45'] = row['G_all'] elif year >= 1946 and year <= 1962: pos_dict[ID]['1946-62'] = row['G_all'] elif year >= 1963 and year <= 1976: pos_dict[ID]['1963-76'] = row['G_all'] elif year >= 1977 and year <= 1992: pos_dict[ID]['1977-92'] = row['G_all'] elif year >= 1993 and year <= 2009: pos_dict[ID]['1993-2009'] = row['G_all'] elif year > 2009: pos_dict[ID]['post2009'] = row['G_all']Now that you’re dictionary is complete, you can convert pos_dict into a DataFrame with the help of the from_dict() function:
# Convert the `pos_dict` to a DataFramepos_df = pd.DataFrame.from_dict(pos_dict, orient='index')Also, print the columns and inspect the data some further:
Next you want to determine the percentage of times each player played at each position and within each era.
First, create a list called pos_col_list from the columns of pos_df and remove the string ‘G_all’. Then create new columns in pos_df for the percentage each player played at each position and within each era by looping through pos_col_list and dividing the games played at each position or era by the total games played by that player. Finally, print out the first few rows of pos_df:
As mentioned earlier, this project is focused on infielders and outfielders since each position is judged differently when determining HoF worthiness. Infielders and outfielders are judged similarly, while pitchers and catchers are judged based on much different playing statistics predominately based on defense. This is beyond the scope of this project as it would require much more data cleaning and feature engineering.
Since many players played at multiple different positions in the earlier years of MLB, eliminate the pitchers and catchers by filtering out players who played more than 10% of their games at either of those positions.
master_dfRemember that you performed an inner join on the master_df and the stats_df, composed of information gathered from batting_df, fielding_df, awards_df, allstar_df and hof_df, to get a more uniform data set of your players’ statistics and the player master data, which was composed of player names, date of birth and biographical information.
Now, you want to join the uniform master_df with pos_df; Be careful! You need to use a right join here because you only want to keep players who are in pos_df:
Now filter master_df to only include players who were voted into the Hall of Fame or didn’t make it at all.
Some players make it into the Hall by selection from the Veterans Committee, or by a specially appointed committee. These players are typically selected for reasons other than purely their statistics which your model may find difficult to quantify, so it’s best to leave them out of the data set.
The bats and throws columns need to be converted to numeric: you can easily do this by creating a function to convert each R to a 1 and each L to a 0. Use the apply() method to create numeric columns called bats_R and throws_R:
The debut and finalGame columns are currently strings. You’ll need to parse out the years from these columns. First, import datetime. Next, convert the debut and finalGame columns to a datetime object using pd.to_datetime(). Then parse out the year using dt.strftime(‘%Y’) and convert to numeric with pd.to_numeric().
There are currently some unnecessary columns in master_df. Use the drop() method on master_df and create a new DataFrame called df. Now is a good time to print the columns in df and display the count of null values for each column.
In the first part of this tutorial, you were dealing with team statistics and the null values were likely due to missing data. A team is never going to make it through an entire season without a double play, for example.
With players, it is much more likely that null values are zeros.
That’s why you’re going to create a list of the numeric columns and loop through the list, filling the null values with zeros using the fillna() method. Then use the dropna() method to eliminate any remaining null values.
Congratulations! You have finally gathered a totally uniform view on your players: you have the player statistics and the master data in one place, the df DataFrame.
Now that the data has been cleaned up, you can add new features. The important baseball statistics that are missing from our data are batting average, on-base percentage, slugging percentage, and on-base plus slugging percentage.
Add each of these statistics by using the following formulas:
There are a few anomalies in your data that need to be resolved, which you might know if you have some knowledge on MLB history:
The first two involve players who had Hall of Fame worthy statistics, but were banned from baseball for life. For example, Shoeless Joe Jackson (playerID == jacksjo01) was an incredible player but got caught up in the 1919 Black Sox scandal when multiple players from the Chicago White Sox accepted money from Mobsters and intentionally lost. Even though he played extremely well in that series, he was banned for life.
In addition, you have Pete Rose (playerID == rosepe01), the all-time hits leader. Nicknamed Charlie Hussle, he was the everyman who had an incredible career playing for the Cincinnati Reds. Shortly after he retired as a player he became the Manager of the Reds and got caught betting on baseball games including betting on his own team to win. He was also banned for life. It’s best to remove these two players from the dataset.
Out of respect for Jackie Robinson (playerID == robinja02) and the incredible impact he had on the game of baseball, instead of removing him, create a function to identify him as the first African American to play in the Major Leagues.
Now it’s time to visualize some of the data to gain a better understanding. Filter df to only include Hall of Fame players and print the length.
You have 70 Hall of Famers left in the data set. Plot out distributions for Hits, Home Runs, Years Played, and All-Star Game Appearances for these Hall of Famers.
# Import the `pyplot` module from `matplotlib`import matplotlib.pyplot as plt# Initialize the figure and add subplotsfig = plt.figure(figsize=(15, 12))ax1 = fig.add_subplot(2,2,1)ax2 = fig.add_subplot(2,2,2)ax3 = fig.add_subplot(2,2,3)ax4 = fig.add_subplot(2,2,4)# Create distribution plots for Hits, Home Runs, Years Played and All Star Gamesax1.hist(df_hof['H'])ax1.set_title('Distribution of Hits')ax1.set_ylabel('HoF Careers')ax2.hist(df_hof['HR'])ax2.set_title('Distribution of Home Runs')ax3.hist(df_hof['Years_Played'])ax3.set_title('Distribution of Years Played')ax3.set_ylabel('HoF Careers')ax4.hist(df_hof['AS_games'])ax4.set_title('Distribution of All Star Game Appearances')# Show the plotplt.show()Note that if you’re working in a Jupyter notebook, you can easily make use of the %matplotlib inline magic to plot these distribution plots!

Next, create a scatter plot for Hits vs. Batting Average and one for Home Runs vs. Batting Average. First, filter df to only include players who played 10 or more seasons which is the minimum for Hall of Fame eligibility.
# Filter `df` for players with 10 or more years of experiencedf_10 = df[(df['Years_Played'] >= 10) & (df['HoF'] == 0)]# Initialize the figure and add subplotsfig = plt.figure(figsize=(14, 7))ax1 = fig.add_subplot(1,2,1)ax2 = fig.add_subplot(1,2,2)# Create Scatter plots for Hits vs. Average and Home Runs vs. Averageax1.scatter(df_hof['H'], df_hof['AVE'], c='r', label='HoF Player')ax1.scatter(df_10['H'], df_10['AVE'], c='b', label='Non HoF Player')ax1.set_title('Career Hits vs. Career Batting Average')ax1.set_xlabel('Career Hits')ax1.set_ylabel('Career Average')ax2.scatter(df_hof['HR'], df_hof['AVE'], c='r', label='HoF Player')ax2.scatter(df_10['HR'], df_10['AVE'], c='b', label='Non HoF Player')ax2.set_title('Career Home Runs vs. Career Batting Average')ax2.set_xlabel('Career Home Runs')ax2.legend(loc='lower right', scatterpoints=1)# Show the plotplt.show()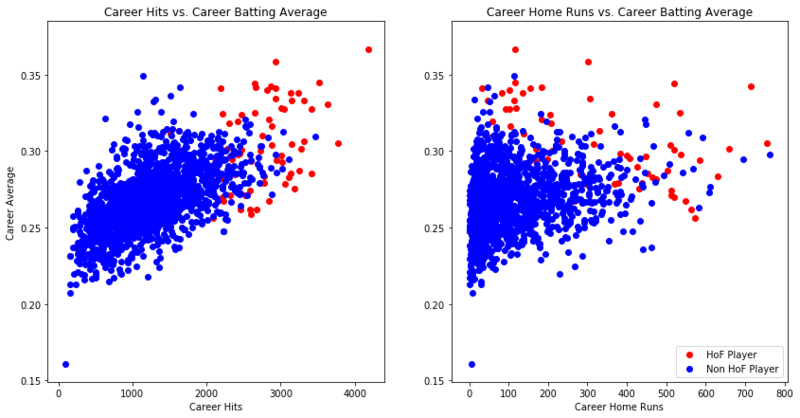
When you created new features, you may have also created new null values. Print out the count of null values for each column.
As you can see, there are not many null values, so you can easily drop the rows that have null values in them.
In the first part of this tutorial series, the data was split into testing and training sets by taking a random slice of the data for each. This time you’ll be using cross-validation to train and test the models. Since a player must wait 5 years to become eligible for the HoF ballot, and can remain on the ballot for as many as 10 years then there are still eligible players who played their final season in the last 15 years.
Make sure to separate out the players who played their most recent season in the last 15 years so you can use this as “new” data once you have a model that’s trained and tested.
Add a column to df for years since last season (YSLS) by subtracting the finalYear column from 2016. Next, create a new DataFrame called df_hitters by filtering df for players whose last season was more than 15 years ago and create one called df_eligible for players whose last season was 15 or less years ago.
Now you need to select the columns to include in the model. First, print out the columns.
Make a list with the columns to include in the model and create a new DataFrame called data from df_hitters using the list of columns. Include playerID, nameFirst, and nameLast in the list, as you’ll want those columns when you display the results of your predictions with the new data.
You’ll need to drop those three columns for any data used in the model.
Print out how many rows are in data and how many of those rows are Hall of Famers.
There are 6,239 rows and 61 of those are Hall of Famers for your model to identify. Create your target Series from the HoF column of data and your features DataFrame by dropping the identification columns and the target column with the help of drop().
Now that you have isolated your target and features, it’s time to build your model!
As was indicated earlier, the question you’re trying to answer is:
“Can you build a machine learning model that can accurately predict if an MLB baseball player will be voted into the Hall of Fame?”
The error metric for Part II is simple. How accurate are your predictions?
How many “True Positives” have you predicted where the player was predicted to be in the HoF and they are a HoF member. How many “False Positives” have you predicted where the player was predicted to be in the HoF and they are not a HoF member. Lastly, How many “False Negatives” where the player was predicted to not be in the HoF when the player was actually a HoF member.
The first model you’ll try is a Logistic Regression model. You’ll be using the Kfold cross-validation technique and you can learn more here.
Import cross_val_predict, and KFold from sklearn.cross_validation and LogisticRegression from sklearn.linear_model. Create a logistic regression model lr and be sure to set the class_weight perameter to ‘balanced’ because there are significantly more non-HoF members in the data.
Create an instance of the KFold class (kf) and finally, make predictions (predictions_lr) with cross_val_predict() using your model lr, features, target, and setting the cv parameter to kf.
To determine accuracy, you need to compare your predictions to the target. Import numpy as np and convert predictions_lr and target to NumPy arrays.
Create a filter for each of the four possible prediction scenarios:
Then determine the count by applying the filter to your predictions. Now you can determine your accuracy rate using the following formulas:
Print out the count for each except True Negatives and each of your accuracy rates.
That first model was fairly accurate, selecting 54 of 61 Hall of Famers, but it had a relatively high false negative count at 36.
Next up is a Random Forest model. Import RandomForestClassifier from sklearn.ensemble. For this model, instead of setting class_weight to balanced, you’ll set it to penalty which is a dictionary you need to create with key 0 set to 100 and key 1 set to 1.
Create your model rf and set the parameters as follows: random_state= 1, n_estimators= 12, max_depth= 11, min_samples_leaf= 1, and class_weight= penalty.
Finally, make your predictions (predictions_rf) using cross_val_predict() the same as the previous model and again, convert your predictions to a NumPy array.
As you did with the previous model, determine your True Positive, False Negative, and False Positive counts and rates.
The Random Forest model was slightly less accurate predicting 50 of 61 Hall of Famers, but with a very low false negative count of only 2.
The Random Forest model seems to perform better overall, so that’s the one you’ll use to make predictions with the “new” data you set aside.
Create a new DataFrame (new_data) from df_eligible using the num_cols_hitters list. Now create another DataFrame (new_features) by dropping the identification columns and the target column with drop().
Now you can use the fit() method to fit the rf model using the features and target you used earlier. Next, you can predict the probability that a player in the “new” data will be voted into the Hall of Fame. Use the predict_proba() method on the rf model using new_features.
Finally, convert probabilities to a pandas DataFrame called hof_predictions. Sort hof_predictions in descending order.
Now, print out each of the first 50 rows from hof_predictions along with the names and important statistics found in new_data. These are the 50 players your model has predicted to be the most likely to be voted into the Hall of Fame, along with the estimated probability and the players career statistics.
As it stands, the model appears to do a really good job of making predictions, with a few exceptions:
This concludes the second part of our tutorial series on Scikit-Learn and sports analytics. You imported the data from CSV files, cleaned and aggregated it. You generated new features in the data and got a better understanding by visualizing it. You learned how to create a Logistic Regression model and a Random Forest model. You also learned how to use K-Fold Cross Validation to train and test your model, how to check the accuracy of your classification models, and you made predictions using new data.
If you enjoyed this project, try to build your own model for predicting which Pitchers will be voted into the Hall of Fame.
Good Luck!
Learn more about Python
Course
Course
Course
Tutorial
Daniel Poston
Tutorial
Adam Shafi
Tutorial
Avinash Navlani
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Samuel Shaibu


