
Tracks
AI 基础知识
10小时
Mythos 5 represents a step up from Mythos Preview across every major capability area Anthropic has tested. The gains are most visible in long-horizon autonomous work, especially in scientific domains of scientific reasoning and vision tasks. Here's what that looks like in practice.
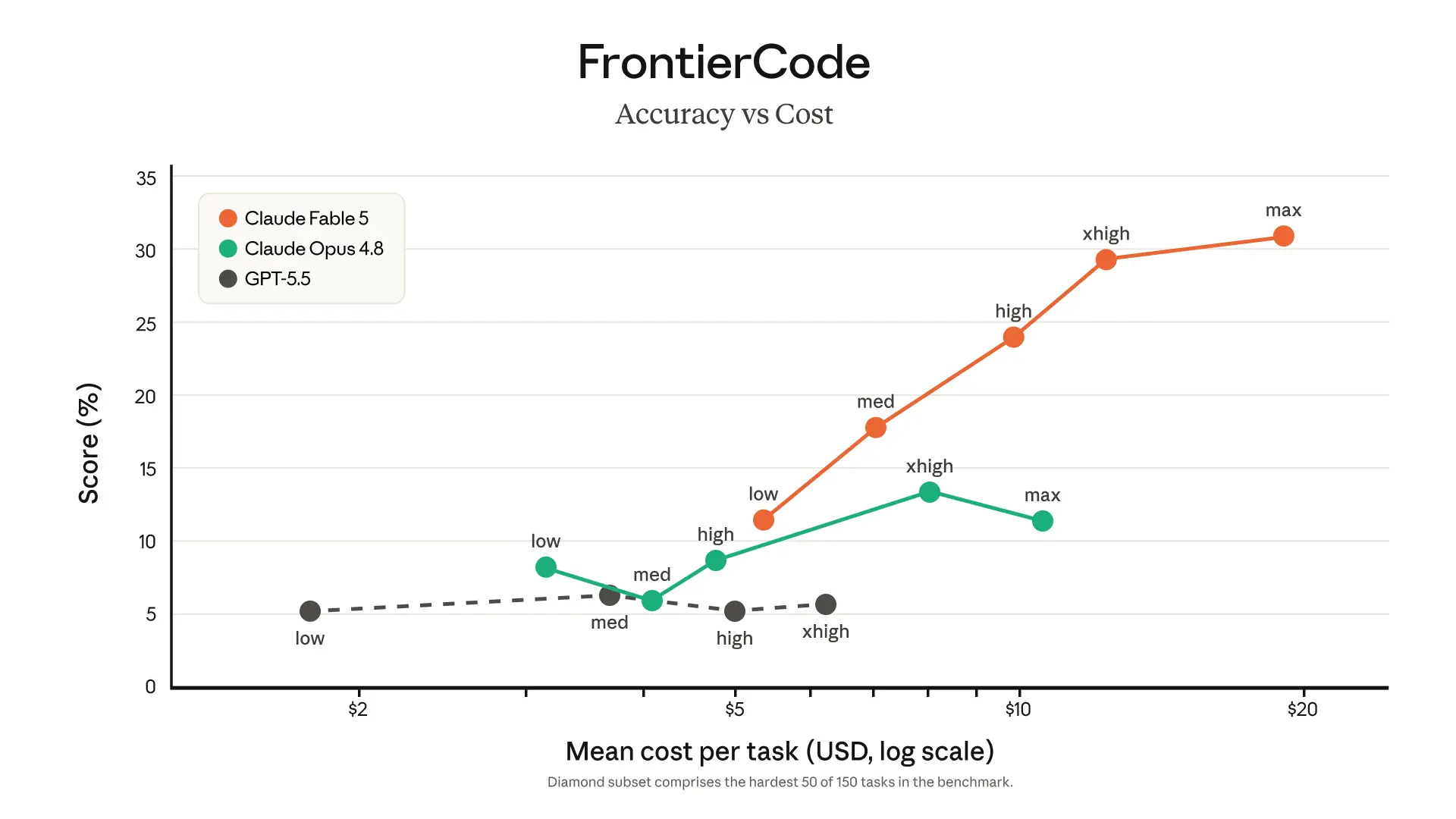
Mythos 5 can work autonomously on large codebases for longer than any previous Claude model. Stripe reported the model compressed months of engineering work into days, completing a codebase-wide migration across a 50-million-line Ruby codebase in a single day. On FrontierCode (Diamond), it scores highest among frontier models even at medium effort.
For security work, Mythos 5 extends the capabilities that made Mythos Preview valuable to Project Glasswing partners. Those partners used Mythos Preview to identify over 10,000 high and critical security flaws across production systems.
Anthropic's internal protein design team used Mythos 5 to accelerate drug design by roughly ten times. In a controlled comparison, Mythos 5 matched or beat skilled human operators across 14 protein targets for the full pipeline:
Nine yielded strong drug design candidates currently under investigation.
Mythos 5 is Anthropic's first model to consistently produce novel scientific hypotheses rather than summarize existing literature. In blinded comparisons, Anthropic's scientists preferred its molecular biology hypotheses roughly 80% of the time, and several have been advanced to experimental evaluation. One hypothesis about a novel E. coli protein mechanism was independently corroborated by a lab working on the same problem.
Mythos 5 conducted novel genomics research over more than a week of largely autonomous work, assembling single-cell data for millions of cells across 138 animal species and training a custom ML model to identify equivalent cell types across distantly related organisms. The trained model outperformed a recent Science-published model despite being 100 times smaller.
Mythos 5 scores 93.2% on CharXiv Reasoning with tools and can extract precise numbers from detailed scientific figures or rebuild a web app from screenshots alone. On long-context tasks, giving Mythos 5 file-based memory improved its performance three times more than the same setup improved Opus 4.8, and it reached the final act of Slay the Spire three times more often.
Mythos 5 leads or ties on nearly every benchmark Anthropic tested, with gains over Opus 4.8 that are consistent across categories rather than concentrated in one area. The comparison table pits it against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
| Category | Benchmark | Claude Mythos 5 / Fable 5 | Claude Mythos Preview | Claude Opus 4.8 | GPT 5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Agentic coding | SWE-Bench Pro | 80.3% | 77.8% | 69.2% | 58.6% | 54.2% |
| Agentic coding | FrontierCode (Diamond) | 29.3% (xhigh) | — | 13.4% (xhigh) | 5.7% (xhigh) | — |
| Knowledge work | GDPval-AA | 1932 | — | 1890 | 1769 | 1314 |
| Knowledge work vision | GDP.pdf | 29.8% (no tools) | — | 22.5% (no tools) | 24.9% (no tools) | 16.7% (no tools) |
| Spatial reasoning | Blueprint-Bench 2 | 38.6% | — | 14.5% | 36.2% | 26.5% |
| Tool use | AutomationBench | 17.4% | — | 15.5% | 12.9% | 9.6% |
| Computer use | OSWorld-Verified | 85.0% | 85.4% | 83.4% | 78.7% | 76.2% |
| Legal | Legal Agent Benchmark | 13.3% | — | 10.4% | 2.1% | 0.0% |
| Multidisciplinary reasoning | Humanity's Last Exam (no tools) | 59.0%* | 56.8% | 49.8% | 41.4% | 44.4% |
| Multidisciplinary reasoning | Humanity's Last Exam (with tools) | 64.5%* | 64.7% | 57.9% | 52.2% | 51.4% |
| Biology | BioMysteryBench (hard) | 46.1%* | 29.6% | 40.0% | — | — |
| Biology | BioMysteryBench (human solved) | 83.9%* | 82.6% | 80.4% | — | — |
| Agentic coding | Terminal-Bench 2.1 | 88.0%* | — | 82.7% | 83.4% (Codex CLI) | 70.7% (Gemini CLI) |
| Cybersecurity | ExploitBench (Cap%) | 78.0%* | 69.0% | 40.0% | 34.0% | — |
| Health | HealthBench Professional | 66.0%* | 64.7% | 56.9% | 51.8% | — |
Anthropic reports Mythos 5 and Fable 5 scores together, noting they fall within 1–3 percentage points in most cases. Benchmarks marked with an asterisk (*) show a larger gap because Fable 5's safety classifiers route sensitive queries to Opus 4.8; on those benchmarks, Fable 5 performs closer to the Opus class.
On SWE-Bench Pro, Mythos 5 scores 80.3%, compared to 77.8% for Mythos Preview, 69.2% for Opus 4.8, 58.6% for GPT 5.5, and 54.2% for Gemini 3.1 Pro. The 11-point gap over Opus 4.8 is substantial on a benchmark designed to resist ground-truth leakage.
For high-quality and maintainable agentic code rather than raw task completion, measured by FrontierCode (Diamond), the separation is even sharper. Mythos 5 scores 29.3% at the xhigh effort level, compared to 13.4% for Opus 4.8 and 5.7% for GPT 5.5.
For terminal work, Mythos 5 takes the crown back to Anthropic from OpenAI: Mythos 5 scores 88.0%* on Terminal-Bench 2.1, compared to 82.7% for Opus 4.8, 83.4% for GPT 5.5 (Codex CLI), and 70.7% for Gemini 3.1 Pro (with Gemini CLI).
GDPval-AA measures knowledge work performance on a numerical scale. Mythos 5 scores 1932, compared to 1890 for Opus 4.8, 1769 for GPT 5.5, and 1314 for Gemini 3.1 Pro.
This gap is elevated for knowledge work on PDF documents without tool access. Mythos 5 scores 29.8% on GDPpdf, compared to 22.5% for Opus 4.8, 24.9% for GPT 5.5, and 16.7% for Gemini 3.1 Pro.
Humanity's Last Exam (HLE) tests graduate-level reasoning across science, mathematics, and humanities. Mythos 5 scores 59.0%* without tools and 64.5%* with tools. Mythos Preview scores 56.8% and 64.7% respectively—essentially tied with tools but trailing by 2 points without. The distance to Opus 4.8 is already significant (49.8% without, 57.9% with), but even bigger to the flagship competitor models (GPT 5.5: 41.4% and 52.2%, Gemini 3.1 Pro: 44.4% and 51.4%).
The gap between Mythos 5 and the rest of the field is clearest in the no-tools condition, where it leads Opus 4.8 by over 9 points. These are starred scores, meaning Fable 5 performs somewhat lower due to its safety classifiers.
On OSWorld-Verified, which tests the model's ability to complete tasks on a real computer interface, Mythos 5 scores 85.0%. Mythos Preview edges ahead at 85.4%, making this the only benchmark where Mythos Preview leads. Opus 4.8 comes quite close (83.4%), with the competitors falling behind a bit. GPT 5.5 scores 78.7%, and Gemini 3.1 Pro scores 76.2%.
AutomationBench measures tool use capabilities. Mythos 5 scores 17.4%, compared to 15.5% for Opus 4.8, 12.9% for GPT 5.5, and 9.6% for Gemini 3.1 Pro. The low absolute numbers across the board suggest tool use remains a hard problem for all frontier models.
Spatial reasoning is one area where Mythos 5's lead is the biggest. It scores 38.6% in Blueprint-Bench 2, more than double that of Opus 4.8's 14.5%. GPT 5.5 is closer at 36.2%, and Gemini 3.1 Pro scores 26.5%.
Those were the two areas that arguably received the most attention in the release notes, and the results show us why.
ExploitBench measures the fraction of exploits the model can successfully reproduce (Cap%). Mythos 5 scores 78.0%*, which is even a significant improvement from Mythos Preview (69.0%), and a dramatic increase compared to Opus 4.8's 40.0% for Opus 4.8 and 34.0% for GPT 5.5.
The 38-point gap over Opus 4.8 is the largest single-benchmark lead in the comparison table, and it explains why the cyber safeguards exist for Fable 5. Anthropic's external red-teaming found no universal jailbreaks on long-form agentic tasks, though the UK AISI made progress toward one in an initial testing window.
BioMysteryBench tests biological reasoning at two difficulty levels. On the hard subset, Mythos 5 scores 46.1%*, compared to 29.6% for Mythos Preview and 40.0% for Opus 4.8. On the human-solved subset, Mythos 5 scores 83.9%*, Mythos Preview scores 82.6%, and Opus 4.8 scores 80.4%. GPT 5.5 and Gemini 3.1 Pro do not have reported scores on either subset.
As with ExploitBench, Fable 5's scores are closer to Opus 4.8 due to biology-related safety classifiers.
Claude Mythos 5 demonstrates notable strength in two high-stakes professional domains where accuracy and reasoning quality carry real-world consequences: medicine and law.
In HealthBench Professional, Mythos 5 scores 66.0%*, just over Mythos Preview's 64.7%. Opus 4.8 scores 56.9%, and GPT 5.5 scores 51.8%.
On the Legal Agent Benchmark, Mythos 5 scores 13.3%, compared to 10.4% for Opus 4.8, and only 2.1% for GPT 5.5. The absolute scores are low, but the separation between Mythos 5 and GPT 5.5 or Gemini is stark. Legal reasoning remains a challenging frontier for all models.
Claude Mythos 5 is priced at $10 per million input tokens and $50 per million output tokens. This is less than half the price of Claude Mythos Preview ($25/$125), which makes the upgrade straightforward for existing Glasswing partners. Developers can access the model via the Claude API using the model ID claude-mythos-5.
Access is currently restricted to two groups:
Anthropic plans to expand both programs over time.
A broader trusted access program is planned for cybersecurity organizations to apply more systematically, in consultation with the US Government. Anthropic has not announced a timeline for general availability. For most developers, Claude Fable 5 is the practical option today, with the same underlying model and access via standard subscription and API plans.
One operational detail worth flagging: Anthropic has introduced a 30-day data retention policy for all Mythos-class model traffic. The data is not used for training and is deleted after 30 days in almost all cases, but it is retained for safety monitoring. If you're building on Mythos 5 with sensitive data, review Anthropic's support documentation on this policy before deploying.
Claude Mythos 5 is Anthropic's clearest statement yet that the company is serious about deploying frontier AI in high-stakes professional contexts, and the results back it up.
The SWE-bench Pro gap (80.3% vs 69.2%), the Terminal-Bench 2.1 gap (88.0% vs 82.7%), and the ExploitBench gap (78.0% vs 40.0%) all point to a model that handles the hardest tasks more reliably than anything else available.
The restricted access model is a reasonable approach given the dual-use risks, and the ExploitBench scores make a compelling case that the most capable offensive security tools shouldn't be publicly available. The harder question is whether Anthropic can expand the trusted access program fast enough to be useful to the broader security and biomedical research communities before competitors close the gap.
For organizations that qualify, the upgrade from Mythos Preview is straightforward at less than half the price.
Top AI Courses
Tracks
Courses
Courses
blogs
Josef Waples
10分钟
blogs
Josef Waples
9分钟
blogs
Matt Crabtree
10分钟
blogs
Josef Waples
10分钟
blogs
Tom Farnschläder
10分钟
blogs
Matt Crabtree
9分钟
