Course
Marketing Analytics: Predicting Customer Churn in Python
4 hr
18.4K
Have you ever purchased items on an online shopping platform, only to find yourself flooded with advertisements of similar products every time you browse the web? This is an application of data science in marketing.
A majority of the world’s data has been generated in the past two years alone, and companies now have the ability to collect and store customer data at a larger scale than ever before. Every time users interact with an organization’s website, social media page, or POS system, new data points are created.
This data is then used to build insights around user behavior and send them curated advertisements, personalized product recommendations, and special promotions.
Most of us interact with marketing data science applications in our daily lives and unconsciously make decisions based on them.
In this article, we will walk through 5 ways to use data science in marketing. Then, we’ll explore a personal project you can add to your data science portfolio for each use case. Finally, we will touch on why you should become a marketing data scientist and how to land a job as one.
Companies like Netflix, Spotify, and Amazon use recommendation systems to provide users with personalized content suggestions based on their interaction with the platform.
For instance, if you watch a movie on Netflix and give it a positive rating, the next time you open the app, you will be recommended movies of the same genre, content, and cast members.
This is a simple example of how we interact with recommendation engines in our day-to-day life.
Recommendation systems get more powerful over time as users continue to interact with them.
For instance, if you are new to Spotify, your initial music suggestions will be generic. The app will recommend a wide range of genres that appeal to the mainstream audience since the algorithm does not have sufficient data to know your preferences.
As you spend more time on the platform, the recommendation engine will learn more about your likes and dislikes, and your music suggestions will be curated to your taste. The algorithm can even predict the type of music you might enjoy during different seasons or at different times of the day.
Recommendation systems can be broadly classified into two types - content-based recommendation systems and collaborative filtering based recommendation systems.

Image by author
Content-based recommendation systems come up with suggestions solely based on the product’s content.
For example, if you enjoyed reading novels from the Percy Jackson series, you might be recommended Heroes of Olympus, which is written by the same author and is of a similar genre.
However, one disadvantage of an algorithm like this is that you will not be recommended books that are different from the ones you have already read. If you liked Percy Jackson, then you will only be recommended adventure and fantasy books even if you might potentially enjoy a non-fiction or suspense novel.
You can overcome this drawback of content-based recommendation systems using a collaborative-filtering-based recommendation system, which we’ll explain later in this article.
If you are a beginner with little to no experience in building recommendation systems, the Kaggle Movie Dataset is a great place to start. This dataset contains metadata for 45,000 movies, including their posters, release dates, genres, and revenues.
You can code along to the Recommender Systems in Python tutorial on Datacamp to build a content-based recommendation system using movie details available in the dataset.
If you want more direction on building a movie recommendation system, register for a live code-along training session on Datacamp. This is a guided workshop conducted by an expert who will teach you how to create recommender systems in R in 1.5 hours, and you can ask the instructor questions for clarification if you face any challenges along the way.
Collaborative-filtering based models are used to generate suggestions based on past user behavior. They can be further classified into user-based and item-based collaborative filtering.
As the name suggests, user-based collaborative filtering groups together customers with similar behavior.
This algorithm then provides product recommendations based on shared preferences of these customer segments, as displayed in the diagram below:
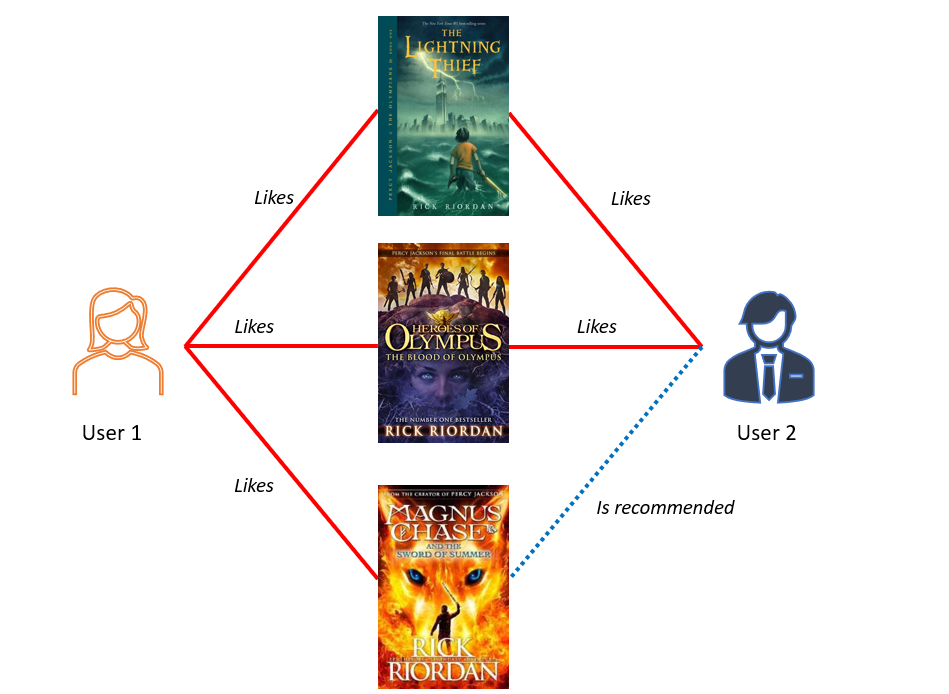
Image by author
On the other hand, item-based collaborative filtering groups similar items together based on user preferences, as shown in this image:
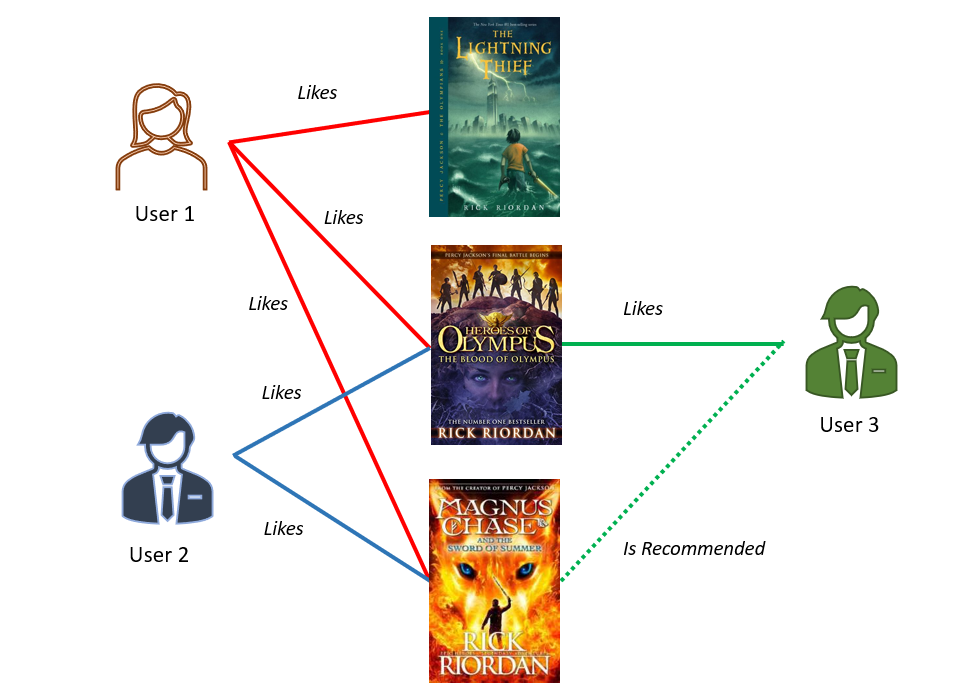
Image by author
To learn more about the different types of recommendation systems and how to implement them, take the Build Recommendation Engines in Python course by Datacamp.
You can build a collaborative-filtering based recommendation system using the Book Recommender System Dataset on Kaggle. This dataset contains only three variables - a user ID, the book’s ISBN code, and a user rating for each book.
This recommendation system tutorial can help you get started with the project if you are unfamiliar with how collaborative filtering works.
Image from KDNuggets
Sentiment analysis, also known as opinion mining, is the process of determining the underlying emotion behind a piece of text, and is another popular application of data science in marketing.
Here is an example of how sentiment analysis adds business value to organizations:
A bank in South Africa was witnessing higher than usual customer attrition rates. Many users started to leave for competitor institutions and no longer wanted to do business with them. The bank tried to identify the issue with the help of sentiment analysis.
They collected over 2 million data points on social media to analyze what customers were saying about them and trained a sentiment analysis model on this data.
Based on this analysis, the institution realized that most negative comments came from users who were unhappy that the bank had insufficient tellers during lunch hour, leading to long waiting times.
The bank then remedied the situation by having more tellers during high volume hours, which led to a decrease in user attrition.
The example above captures just how useful sentiment analysis can be in helping companies improve their product offering and outgrow their competitors. Other applications of sentiment analysis include product analysis, market research, and user review mining.
To learn more about sentiment analysis models and how to build them from scratch, take the Sentiment Analysis in Python course on Datacamp.
You can start by creating a Movie Review Sentiment Analysis model using a dataset present within the NLTK library. NLTK is a Python package that provides a diverse set of algorithms for Natural Language Processing.
In this project, you can use a movie review dataset that is built into the library, which can be imported using a single line of code. You then need to build an algorithm that classifies movie review data into positive and negative sentiment.
Code along to the Python Sentiment Analysis tutorial on Datacamp if you need guidance to get started.
Image from DeepNote
Customer churn is a phenomenon that takes place when a user stops doing business with an entity. For instance, if you are a Netflix user and decide to end your subscription on the platform, you are a customer who has churned.
It is more expensive for companies to replace a churned customer than it is for them to retain an existing one. Due to this, many organizations hire data scientists to identify users who are about to churn so that they can prevent this from taking place.
Here is an example of how a customer churn prediction model can help companies retain users:
You are subscribed to an Internet Service Provider and have lately been experiencing slow connection speeds. You lodged a few complaints and tried reaching out to the customer support team, but the problem persisted. Due to this, you even switched the router on and off and reconnected to the network multiple times.
Finally, you decided to switch to a competitor brand since your user experience with this ISP was poor.
The ISP’s data science team collects customer behavioral data, tracks user activity when they are connected to the network, and gathers complaint information. After consolidating all this data, the team realizes that you are at a high risk of churning.
They immediately alert the marketing and product teams that you will likely stop doing business with them.
The company’s marketing team then reaches out to you with personalized promotions and discounted WiFi plans and even offers to upgrade your existing subscription for free. After upgrading, you realize that connection speeds are a lot faster, and your overall experience with the ISP is more pleasant. You then decide to continue subscribing to them instead of switching to a competitor brand.
The example above captures how useful customer churn models can be in retaining an organization’s existing users. This application adds direct business value to companies and is often used by subscription-based platforms like Netflix and Spotify that depend on user renewal as their main revenue source.
You can use the Telecom Customer Churn dataset on DataCamp to create your first churn prediction project.
This dataset contains information on users who are subscribed to an Iranian telcom company, such as their age, usage behavior, subscription length, and complaints. Use this data to predict whether a customer is likely to churn.
If you aren’t sure where to start, code along to the Customer Churn Rate Prediction tutorial to build this model. You can also check out our course on Predicting Customer Churn in Python.
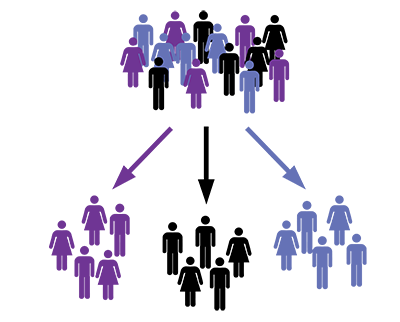
Image from Madlytics
Customer segmentation is the process of dividing users into different customer sub-groups based on shared characteristics. Each segment is then targeted with a different set of promotions and product offerings based on their behavior.
Here is an example of how customer segmentation can add business value to organizations:
An e-commerce company builds a customer segmentation model to target different users with personalized promotions.
If a user browses the platform often but only purchases when there is a discount, they are classified as a “Promotion Hunter.” All customers in this segment are immediately sent an email notification every time there is an ongoing discount since they are likely to make more purchases during this time.
On the other hand, some users shop for specific items and are willing to make the purchase regardless of the price since they value quality over affordability. These customers are targeted differently, and the company’s marketing team only advertises high-end items to this group based on products they have already displayed an interest in.
This way, customers with high purchasing power are shown more expensive products that cater to their interests, encouraging them to spend more. Users who value affordability are enticed with cheaper products during promotion periods.
The example above is simple but displays how customer segmentation allows companies to maximize the amount of profit they make from each user.
One of the most common applications of customer segmentation models is to build ad groups in marketing campaigns.
Facebook, for instance, collects its user’s demographic and behavioral data and allows companies to run advertisements that target custom audience groups based on this information. Users can be segmented based on specific traits such as their location, age, gender, brands they like, and people they are affiliated with.
Customer segmentation is typically achieved by building unsupervised machine learning models such as K-Means clustering.
If you want to learn more about customer segmentation and how to build algorithms like K-Means clustering, take our Customer Segmentation in Python course.
You can use Datacamp’s E-Commerce Dataset to build a customer segmentation portfolio project.
This dataset consists of order details made on an e-commerce platform based in the UK.
Customer purchase information such as the items they ordered, product price, and invoice date is recorded, and you can use this data to segment users based on their activity on the platform.
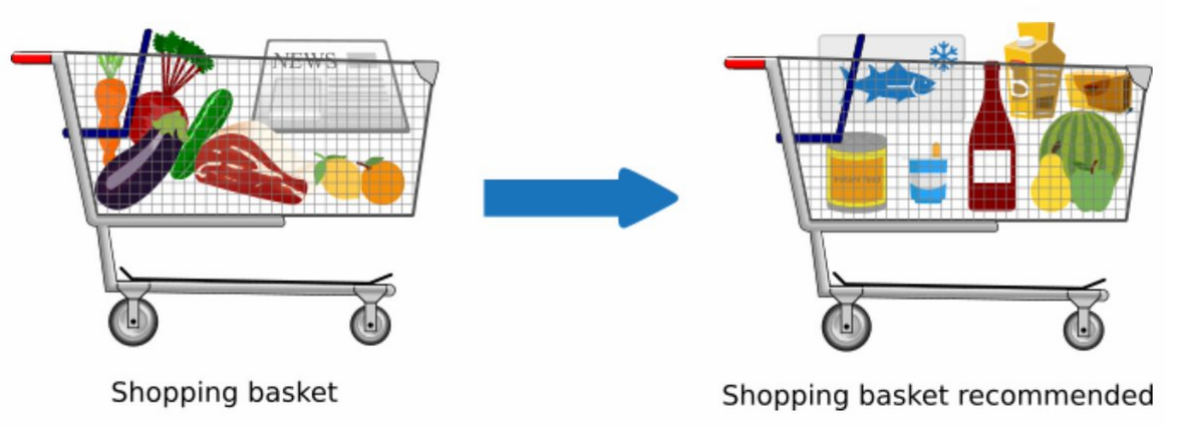
Image from Analytics Vidhya
Market basket analysis, also referred to as association mining, is a technique used to analyze items that are frequently bought together. This is done by processing historical purchase data to identify product combinations that are often seen together in transactions.
The findings from this analysis can be used by retailers to improve store design and encourage customers to purchase more items in a single transaction.
For instance, a person who buys baby formula is also likely to purchase diapers, so stores generally place these items near each other to make them easily accessible to users.
However, purchase patterns are not always as obvious. Depending on the region, cultural influence, and demographic factors, customers tend to buy items together that do not belong to the same category. Many of these correlations cannot be uncovered by the human eye, which is why organizations rely on data science techniques like market basket analysis.
Here is an example of how market basket analysis can identify associations that go undiscovered by people:
The most commonly cited example of market basket analysis is the “beer and diapers” case study. According to this study, a Midwest grocery chain used data mining techniques to identify items that were frequently purchased together.
Their analysis showed that customers typically purchased beer and diapers together on Friday evenings. This correlation might seem purely coincidental, but here is a scenario that could have caused it:
A young dad stops by the grocery store on a Friday night to buy a few beers after a long week in the office. His wife is aware of this and asks him to purchase diapers for their newborn as well. This behavior turns into a habit, and working dads start to buy beer and diapers together before returning home on Fridays.
After this discovery, the store starts to place beer and diapers on the same aisle and immediately witnesses an increase in sales.
This story was first reported back in the mid-90s and its authenticity has been questioned over the years. Fictional or not, this use case serves as a reminder of how powerful statistics can be in uncovering hidden correlations that escape the human eye.
Market basket analysis is not limited to physical retail stores. E-commerce platforms also display highly correlated products on the same page, ensuring that they are in the users’ line of sight.
If you shop online for black jeans, for instance, you may see matching shoes featured at the bottom of the page, encouraging you to buy a bundle of products instead of a single item. Again, this leads to a direct increase in the company’s sales since customers end up buying more products than they came for.
To learn more about market basket analysis and how to perform it using machine learning techniques, take the Market Basket Analysis in Python learning track. If you would prefer to use R, take the Market Basket Analysis in R course.
To get started with market basket analysis, you can use the same E-Commerce Dataset as mentioned in the customer segmentation section above. Keep in mind that this is a truncated version of a dataset available on the UCI Machine Learning Repository and only contains 2,500 rows. You can download the larger dataset if you would like to have more data to work with.
As explained in the previous section, the E-Commerce Dataset contains customer transaction data such as invoice numbers and purchased products. You can use this information to identify items that customers often buy together in the same transaction.
You can use the Market Basket Analysis in R tutorial for guidance in implementing this project. If Python is your language of preference, then we have a course on Market Basket Analysis in Python.
Data science has a wide variety of applications in the marketing field, many of which we discussed above. These use cases add direct value to organizations by improving sales, solving customers’ pain points, and encouraging purchasers to consume more.
In the past, when organizations did not have access to large amounts of customer data, marketing experts would perform many of the above applications themselves. Sentiment analysis and market research were conducted by sending out surveys. Marketers sent targeted advertisements to users based on their understanding of customer behavior, and this was more of an intuitive process rather than a data-driven one.
Nowadays, as there is a massive spike in the volume of data collected and stored by organizations, companies have started to take a data-driven approach to marketing.
However, it is not sufficient for companies to hire data scientists to work on marketing use cases.
While data scientists can deal with complex datasets, build highly accurate predictive models, and perform statistical analysis, these skills alone are insufficient to derive valuable insight from data. They lack domain knowledge in marketing and are often unable to relate the data at hand to business problems.
On the other hand, marketing experts understand customer behavior, know how to formulate problem statements, and can guide marketing decisions. They lack the technical expertise to deal with large datasets.
A data scientist specializing in the marketing domain possesses the combined skill set of both roles, which are invaluable to organizations. These individuals can bridge the gap between the fields of data science and marketing and can make data-driven decisions that are profitable to companies.
To become a marketing data scientist, you must have strong technical and analytical capabilities, marketing domain knowledge, and soft skills:
Keep in mind that the above requirements will differ based on the organization and team you join. For example, a team that focuses on showcasing product recommendations to users will not work on optimizing ads, nor will they perform tasks like attribution modeling.
If you do not possess marketing domain knowledge and want to learn how to conduct an A/B test, visualize marketing metrics, and analyze conversions, take the Introduction to Pandas for Marketing course on Datacamp.
For a clearer picture of what companies are looking for in a marketing data scientist, here are Uber’s requirements for the role:

If you do not have experience in the field of marketing data science, the best way to showcase your skills in the domain is to create projects that solve real-world business problems.
We’ve listed relevant projects for every application explained in this article, and it is a good idea to display some of them on your resume to show hiring managers that you can drive business value using data science techniques.
Finally, if you want to bridge the existing gap in your knowledge and learn how to apply data science approaches to marketing, you can take Datacamp’s Machine Learning for Marketing in Python course, or its R equivalent.
Marketing Courses
Course
Course
Course
blog
Austin Chia
blog
Javier Canales Luna
14 min
blog
Elena Kosourova
15 min
blog
DataCamp Team
8 min
blog
Shawn Plummer
9 min
blog
Elena Kosourova
10 min




