
From powering self-driving cars to conquering the game of Go, organizations have dominated headlines by making previously impossible tasks possible with data science. It is therefore easy to overlook the hidden data science revolution, which is that companies are increasingly making what is currently possible widespread. In other words, more companies are striving for stronger organizational data fluency. An organization’s path to data fluency depends on five key pillars, according to Ramnath Vaidyanathan, the VP of Product Research at DataCamp: Infrastructure, People, Tools, Organization and Processes (IPTOP). In a webinar last month, he shared a data fluency framework that any organization can use to advance in data maturity from data reactive to data scaling, data progressive, and data fluent.
To Move from Data Reactivity, Build a Data Culture
A data reactive company is at the lowest rung of the data maturity ladder. Such a company rarely accesses, uses, and presents data, contributing to the absence of a data culture. It uses disparate legacy tools to collect data in silos and perform ad-hoc data processes. Further, it does not invest in a data upskilling strategy to build data talent internally and in data infrastructure. A company can progress in its organizational data literacy from data reactive to data scaling by building its data culture and data infrastructure. To inseminate such a data culture, the company should strongly consider pursuing low-hanging fruits that allow stakeholders to see the value of data literacy. These include proof-of-concept dashboards and analytics projects like customer churn modelling. The company can also begin developing its data architecture and data collection processes.
Depart from Data Scaling with the Proper Infrastructure and Organizational Model
Unlike a data reactive company, a data scaling company has some form of data strategy and culture. But its shortcomings are still apparent. It has very few employees with the necessary skills and access to analyze, report, and present data confidently, resulting in a weak data culture. Moreover, it lacks centralized data storage and teams, resulting in highly siloed datasets and data processes.
Considering these shortcomings, a data scaling company must improve its organizational data literacy. To do so, it must enable data access by working on its data infrastructure and by building centralized data storage. Such data infrastructure allows high-quality data to be stored in the cloud and easily accessed by all stakeholders. With appropriate data storage and access, employees are empowered to develop data quality standards. For example, DataCamp stores its data in Amazon Redshift, a cloud-based centralized data warehouse, and manages data pipelines using Apache Airflow. This marks a departure from siloed data that is difficult to reconcile and paves the way to a single source of truth.
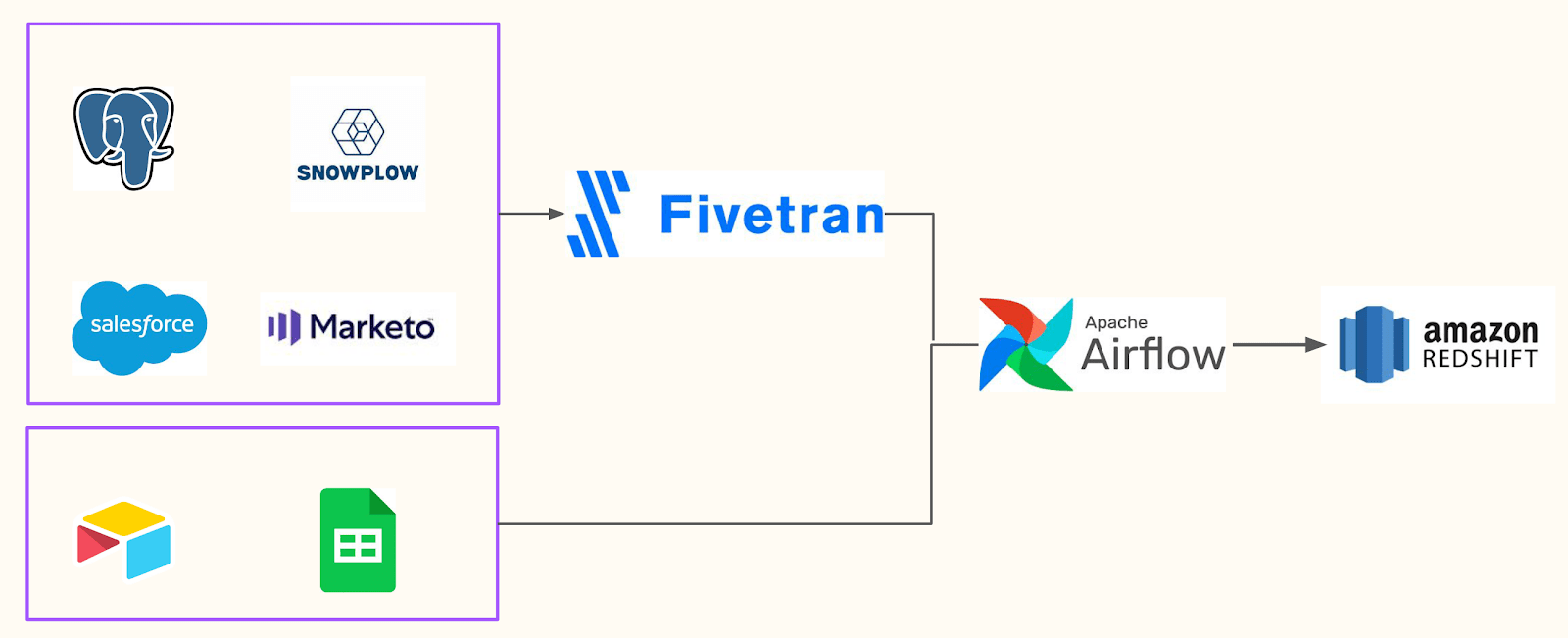
A simplified view of DataCamp’s centralized data storage
A data scaling company must also develop a clear organizational model for data scientists as part of its data maturation. Some companies choose to develop a centralized model characterized by a data science team, which acts as a center of excellence, that handles requests from various functions like finance, marketing and engineering. Others decide to adopt a decentralized model, where data scientists are embedded within functions and handle the data needs of that function exclusively. A company should adopt the model that best fits its data and business needs.
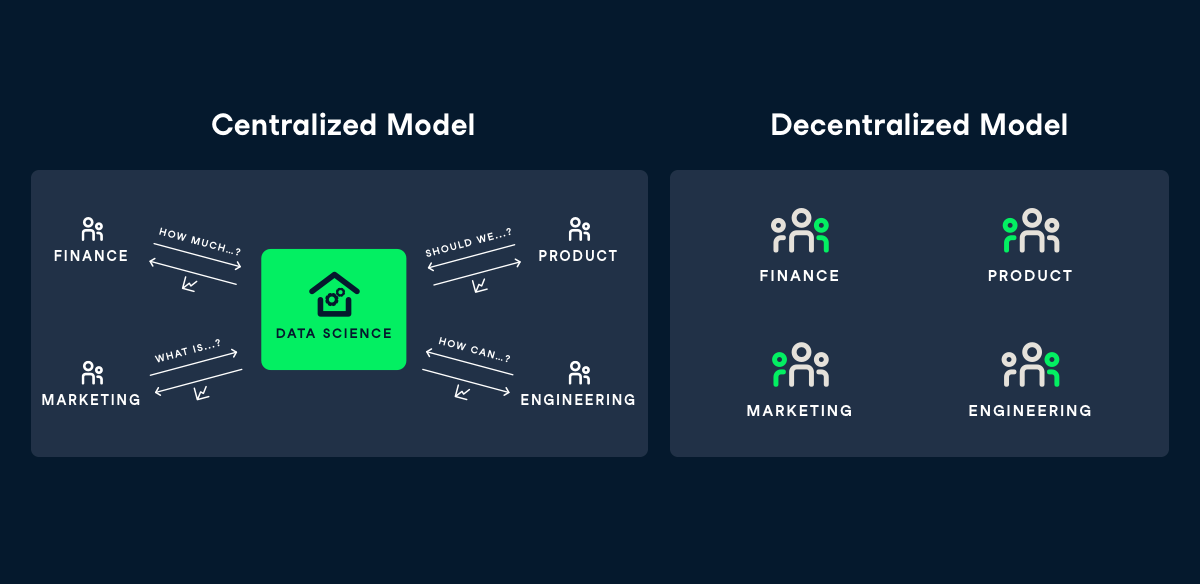
Transition from Data Progressive with Data Tools and Processes
The next milestone in the company’s path of data fluency is the state of data progressive. In a data progressive company, every team has at least one data fluent employee who can analyze, report, and present their data. However, there is still room for improvement in terms of data quality and discoverability as a result of its maturing data infrastructure. Also, while the company’s employees have some level of data literacy, its data is almost exclusively used for reporting and is therefore underutilized. The value of data is further suppressed by the lack of data democratization contributed by the difficulty in accessing data tools and data processes.
To advance from the state of data progressiveness to data fluency, an organization should consider developing its data infrastructure, people, tools, organization, and processes simultaneously in accordance with the IPTOP data fluency framework.
To transition to data fluency, a company can reinforce its data culture by developing and investing in appropriate upskilling strategies for its people. This involves continuous data education that caters to the different data personas and the business goals of the company. For instance, AT&T's intensive talent overhaul saw it investing $1B to upskill 140,000 employees over 10 years. Companies stand to benefit from a stronger data culture by incentivizing data-driven behaviors and rewarding data evangelists who actively promote the company’s data culture.
A company can also build internal data products that operationalize data processes as part of its data literacy program. These data products can be used to improve data quality standards and monitor business goals. For instance, DataCamp has internal frameworks that allow stakeholders to create presentation-ready visualizations of business metrics with minimal code.
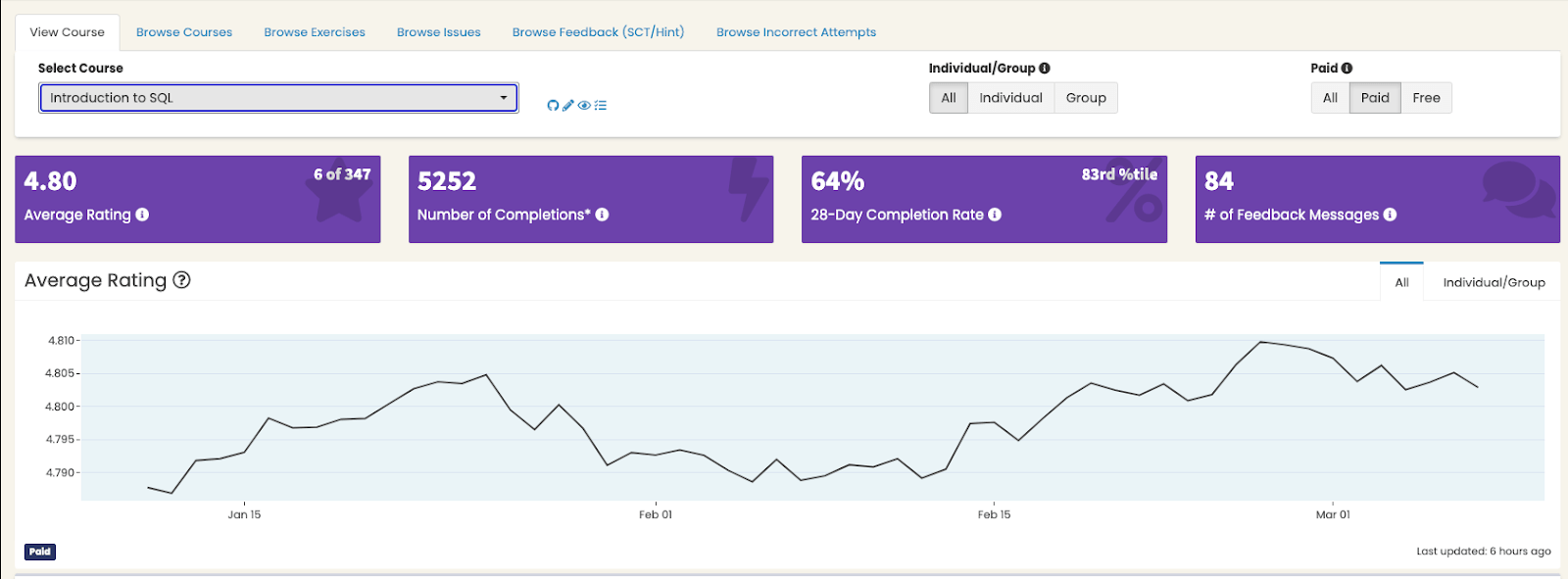
DataCamp dashboards developed easily with internal frameworks
As a company progresses in organizational data literacy, it tends to move toward a hybrid model, where data scientists belong not only in the centralized data team but also in a functional team. This allows the data science team to build and share data tools that align with functional business goals.
Achieving data fluency requires organizations to make data an integral part of their processes. Such processes reduce the friction of extracting value from data and democratize data within the organization. For instance, AirBnb’s Data Quality Initiative defines and enforces the quality of datasets across the company, which in turn builds stakeholder trust in the data and strengthens the data culture. Netflix makes it seamless for stakeholders to create effective notebooks by customizing notebook templates to different target personas.
Become Data Fluent with the IPTOP Framework
Finally, data fluency is a company’s ideal state of data maturity. In a data-fluent company, every employee has the skills to access and understand the data they need to do their jobs. They are empowered by reliable data infrastructure and tools that make data-driven decision-making seamless. Better yet, the company has data processes and organization models that enable cross-departmental collaboration to scale efficiently.
Clearly, an organization’s path to data fluency is not linear. It requires a clear data strategy and a strong data literacy framework. The chart below summarizes the steps an organization should take to move its data literacy from data reactive to data fluent using the IPTOP framework.
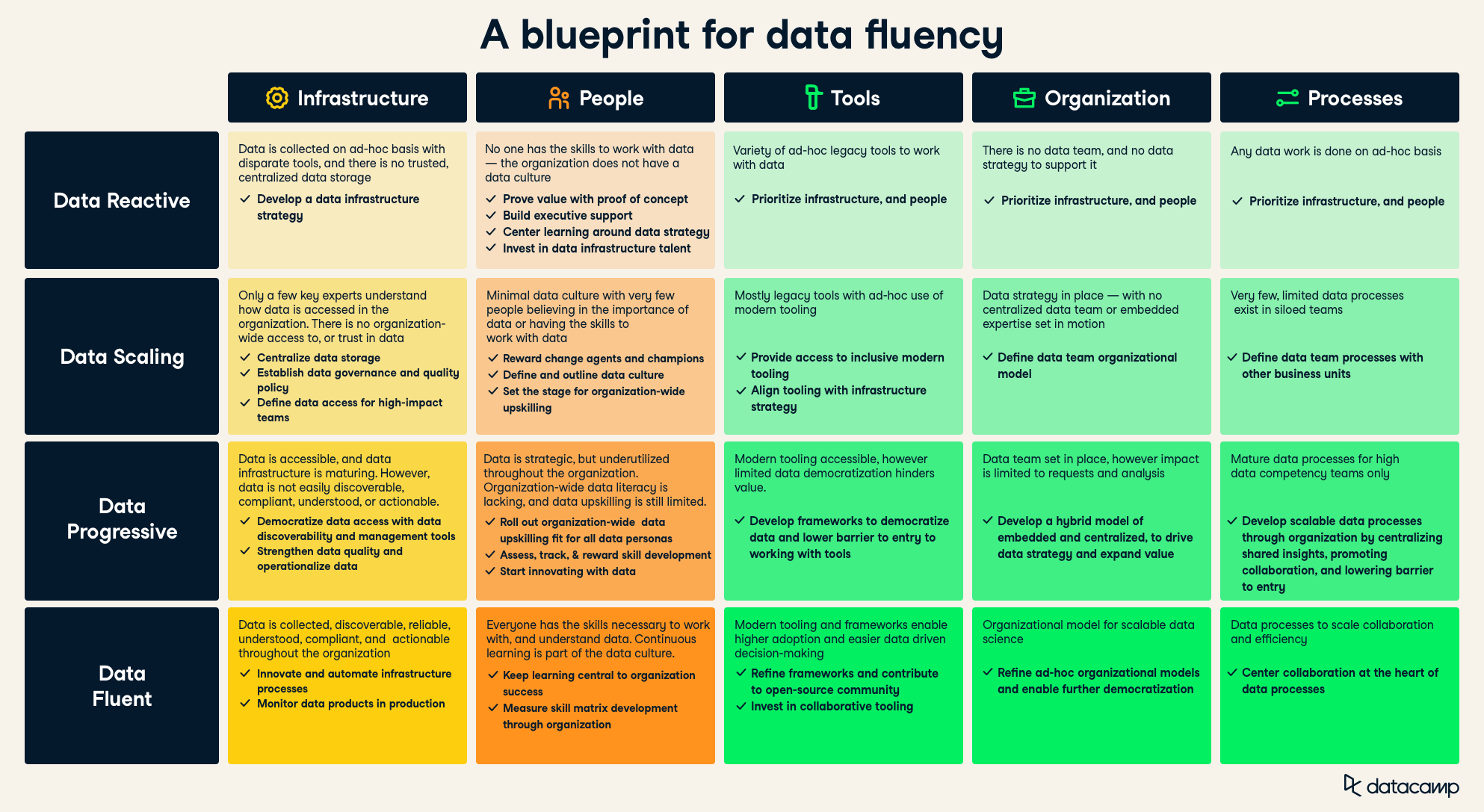
For more on the path to scaling data maturity, tune into our webinar or take the data maturity assessment.