The most successful organizations today rely heavily on data to make decisions. Many of these data-fluent organizations generate millions of rows of data every day that are used and analyzed by a wide range of teams. One of the key challenges to equipping teams with the ability to access and work with data is ensuring that data is collected, trusted, reliable, actionable, and discoverable.
To navigate these complex data landscapes, many organizations have developed and open-sourced in-house technologies, called data discovery tools.
In a recent webinar, Ramnath Vaidyanathan, VP of Product Research at DataCamp describes how organizations can go from data reactive, where no one has the skills or access to work with data, to data fluent, where everyone has access and skills to work with data and make data-driven decisions. Organizations can increase their data maturity through investments in the IPTOP framework: infrastructure, people, tools, organization, and processes. As organizations scale access to data through investments in data infrastructure, they will need to provide easy data discoverability with data discovery tools.
Data is not useful if people cannot access it, if they don’t understand the context of the data collected, and if they cannot find what they need. This is why data discovery tools are really critical. Ramnath Vaidyanathan, VP of Product Research at DataCamp
How data-fluent companies use data discovery tools
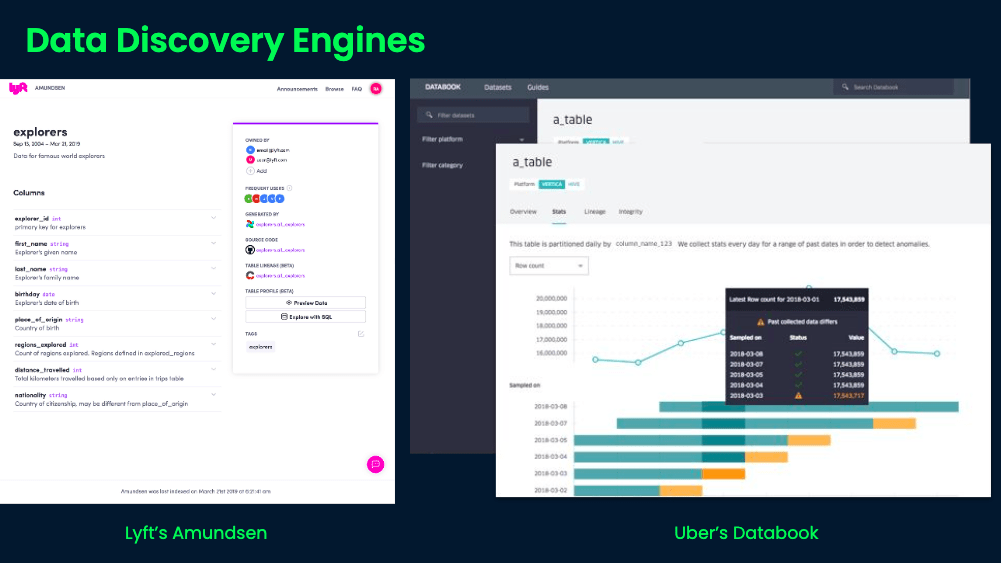
Many data-driven companies have implemented data discovery tools in their data infrastructure. Let’s examine the motivations and drivers behind notable data discovery tools like Uber Databook and Lyft Amundsen.
Data discovery challenges to consider
A key data discovery challenge is productivity and compliance. Lyft outlined that it faced these challenges as the size of its data grew exponentially and was projected to continue to grow at a similar rate for at least the next 10 years. When developing Amundsen, they noted that about 25% of an analyst’s time was spent on data discovery. They also saw increasingly more stringent compliance demands in the countries they serviced.
Uber expressed similar concerns as it began to expand beyond its primary function as a ride-sharing app to services like Uber Eats, Uber Freight, and Jump Bikes. When developing Databook, Uber had over 15 million trips a day and 18,000 employees across different teams. Another challenge was that its data existed in many different forms including Hive, Presto, and Vertica. Analysts needed to be able to efficiently access and understand the various data sources in order to achieve data fluency.
Facebook built its Nemo data discovery platform to address the need for high-quality, trustworthy data as data size and complexity increased across roles and geographic locations. Due to the privacy concerns associated with the data they analyze, Facebook also faced significant compliance concerns that had to be addressed when offering tables to specific analysts.
John Bodley from Airbnb said in a talk at a 2017 conference, “As Airbnb grows, so do the challenges around the volume, complexity, and obscurity of data.” This means that employees often found data to be “siloed, inaccessible, and lacking context.” As a result, employees were making duplicate tables and did not use data if they didn’t trust it. Airbnb developed Dataportal to help make the data discovery process significantly more efficient by removing these barriers to productive data analysis.
These challenges are widespread, industry-agnostic, and apply to any organization looking to scale data-driven decision making. The need for easily discoverable data will become paramount as organizations look to become data fluent.
The four key goals of data discovery tools
Now that we understand data discovery challenges, let’s look at how various data discovery tools address them. Uber breaks down the goals of a successful data discovery platform into four components:
- Extensibility: The ability to easily add metadata, storage, and entities to tables
- Accessibility: The ability to programmatically access all metadata
- Scalability: The ability to support a lot of concurrent read requests
- Power: The ability to support read and write requests across multiple data centers
Attaining these data discovery goals increase as organizations mature their data competencies. As the scale of their data increases, each of these components becomes increasingly more important.
Lyft and Airbnb provide detailed metadata
Lyft’s engineering team argues that “metadata is the holy grail of future applications.” They break metadata down into two subcategories. The first is a describing set of data made up of application context (i.e., what humans need to know about the data to operate with it), behavior (i.e., who owns a particular dataset and its common usage patterns), and change (i.e., how the dataset is changing over time). The second component is the data being described which is any data stored in the organization in any format such as data stores, dashboards, datastreams, and more.
When developing Dataportal, Airbnb’s data discovery platform, metadata was an integral part of the platform’s added value to the data pipeline. Before Dataportal was introduced, many employees did not trust the data they were using due to a lack of context and metadata. Airbnb argues that “the understanding of the entire data ecosystem, from the production of an event log to its consumption in visualization, provides more value than the sum of its parts.”
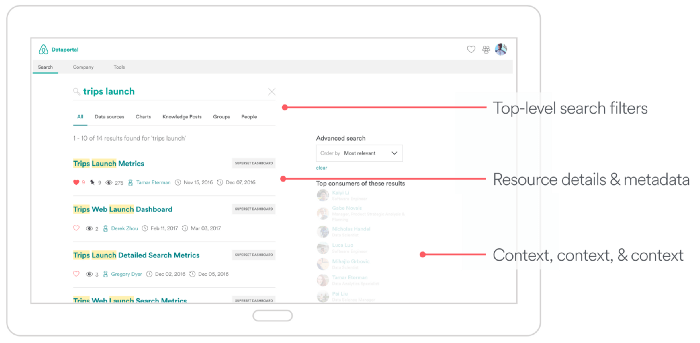
Source: Airbnb
Ensure high-quality search results with data discovery
Once this context is provided, data discovery requires effective search. No matter how trustworthy and easy-to-understand each table is, data discovery platforms are only useful if analysts can find the data they need quickly.
Lyft Amundsen’s landing page allows users to search for tables using natural language queries and provides visibility into the most popular tables used in the organization for quick access. Furthermore, analysts have the option to leave feedback on the table to tune future search results.
Facebook’s data discovery solution, Nemo, allows analysts to filter on usage, privacy restrictions, and recency of data while also leveraging Facebook’s competency in natural language processing by allowing users to type questions into the search bar to get relevant tables.
Uber Databook allows similar search filtering capabilities by allowing analysts to filter on dimensions such as name, owner, column, and nested columns. Uber leverages Elasticsearch to deliver search results quickly and effectively.
Arriving at data democratization through data discovery
Scaling data fluency and data discoverability go hand in hand, as analysts need to have easy access to data to make data-informed decisions.

Organizations with low data maturity should focus on building up data skills and culture and scaling data infrastructure. However, as organizations progress in their data maturity journey and expand data access, enabling extensible and scalable data discovery will be integral to becoming a data-driven organization. For an in-depth discussion on all the levers to grow organizational data maturity, watch our webinar on the path to data fluency or take the data maturity assessment.
