In the past several months, the data science and AI worlds have been abuzz with the arrival of GPT-3, OpenAI’s newest language model. For many, the model represents a significant leap in the ability of one algorithm to reason with human language across a variety of tasks.
Developers testing GPT-3 have provided many intriguing use cases. Examples of automatic code generation based on plain English prompt, answering medical questions, and legal language translation have ignited the imaginations of many data scientists thinking about the next generation of AI-powered software.
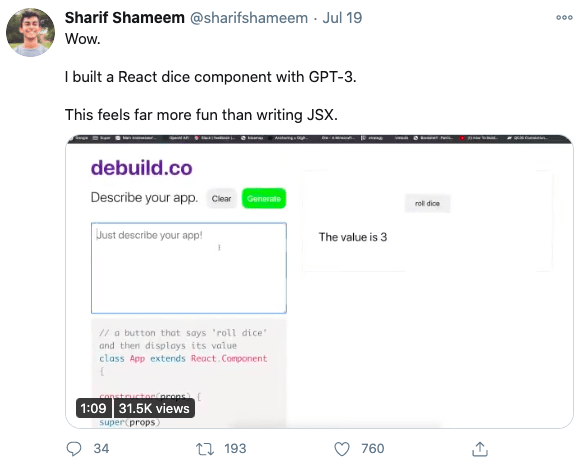
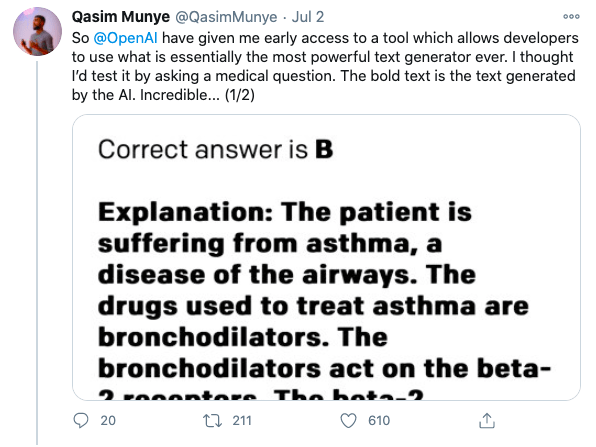
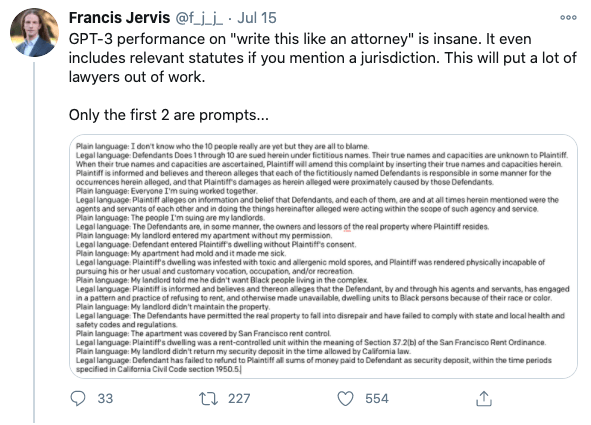
While much of the value of machine learning at an organizational level is in low-hanging fruit like predicting churn, simple sales forecasts, and customer segmentation—it’s useful to consider what the commercialization of GPT-3 means for the future. It has the potential to transform how we think about and operationalize artificial intelligence.
Defining artificial intelligence, machine learning, and deep learning
The business world and media are overloaded with buzz terms like artificial intelligence (AI), machine learning (ML), and deep learning (DL). Let’s quickly define these terms before delving into how GPT-3 works.
Andrew Ng, co-founder of Google Brain and former Chief Scientist at Baidu, describes artificial intelligence as a “huge set of tools for making computers behave intelligently.” This encompasses explicitly programmed software like calculators, as well as ML applications like recommendation systems and self-driving cars.
Machine learning is the “field of study that gives computers the ability to learn without being explicitly programmed,” according to Arthur Samuel, pioneer in artificial intelligence and computer gaming. There are generally two types of machine learning algorithms. The first is supervised learning, where algorithms learn the patterns between existing data (inputs) and labels (outputs) and predict the output on unseen data, like whether a new customer will churn based on historical churn data. The second is unsupervised learning, where algorithms discover general patterns in the data and cluster different data points that are similar to each other, as in segmenting customers based on common patterns of behavior.
Deep learning is a form of machine learning based on multi-layered artificial neural networks, which are loosely inspired by biological neural networks in the brain. They can be both supervised and unsupervised and are largely responsible for the last decade’s high-profile ML use cases, like image recognition and sentiment analysis. Deep learning models vary in architecture, ranging from simple to complex based on the number of layers and nodes in the neural network architecture. The more complex a model is, the more parameters it has. If you want to learn more about how deep learning models are built, check out DataCamp’s deep learning skill track.
For a more in-depth exploration of these topics, read our e-book, The Definitive Guide to Machine Learning for Business Leaders.
How GPT-3 works
So where does GPT-3 intersect with artificial intelligence, machine learning, and deep learning? The acronym GPT refers to “generative pre-trained transformer”—an unsupervised deep learning algorithm that is usually pre-trained on a large amount of unlabeled text. It’s fine-tuned and trained on a large task-specific labeled dataset (e.g., translation of English to French), and is then tasked with inferring the most likely set of outputs (French translation) given a specific set of inputs (English words). You can think of this as a highly sophisticated form of autocomplete for a variety of different language tasks.
GPT-3 is the third iteration of this model, and while it does not innovate on the architecture of its predecessors, it’s pre-trained on extremely large datasets comprising a large portion of the internet, including the Common Crawl dataset, and includes many more layers in its network architecture. This makes GPT-3 the most complex language model ever conceived, with 175 billion parameters in its network architecture. This is ten times more parameters than the most complex model prior to GPT-3’s release, Turing-NLG by Microsoft, and 117 times more complex than GPT-2.
Most importantly, GPT-3 benefits from few-shot learning, where the pre-trained model doesn’t have to be fine-tuned with large labeled training data for a specific language task. It’s instead just given a task description—translate English words to French—and a few examples of inputs mapped to outputs. Coupled with an easy to use plug-and-play interface, GPT-3 largely eliminates barriers to entry and allows non-experts to produce meaningful results on different language tasks.

Why GPT-3 is important
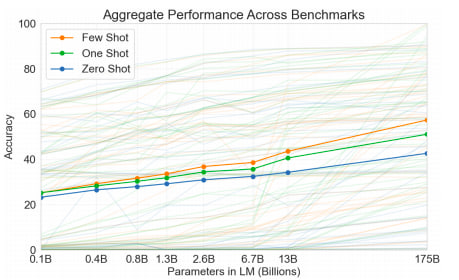
With just a few examples and task descriptions, GPT-3 rivals fine-tuned language models that have been trained on task-specific training data for a variety of language tasks. GPT-3 also exhibits some form of success on tasks that require reasoning, like arithmetic, which are not necessarily language tasks. For example, GPT-3 exhibited 100% accuracy on two-digit addition and subtraction after it was fed a few examples of addition and subtraction. Less complex models with fewer parameters have not been able to break the 60% accuracy ceiling on these tasks. While GPT-3 falters on more complex forms of arithmetic, this implies that more complex models may have the ability to generalize outside of the domain they were trained on.
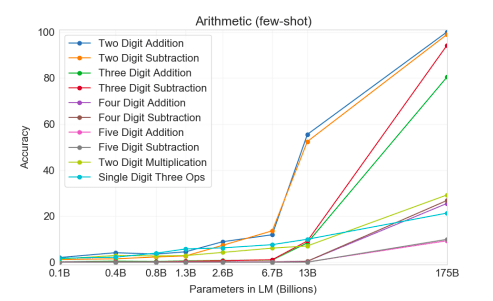
Interestingly, this suggests further gains can be achieved from purely increasing the dataset and model sizes. Currently, it doesn’t seem that the model’s aggregate performance across different tasks is plateauing at 175B parameters. Assuming the same increase in parameter scaling from GPT-2 to GPT-3, one can only wonder how model performance would scale if GPT-4 had 117 times more parameters than GPT-3.
While it’s currently being calibrated in a private beta release, packaging GPT-3 in a plug-and-play API means it may be utilized at scale as soon as it’s out of private beta. As AI Researcher Shreya Shankar pointed out, an important challenge will be serving this API efficiently and easily for organizations to use.
What this means for the future
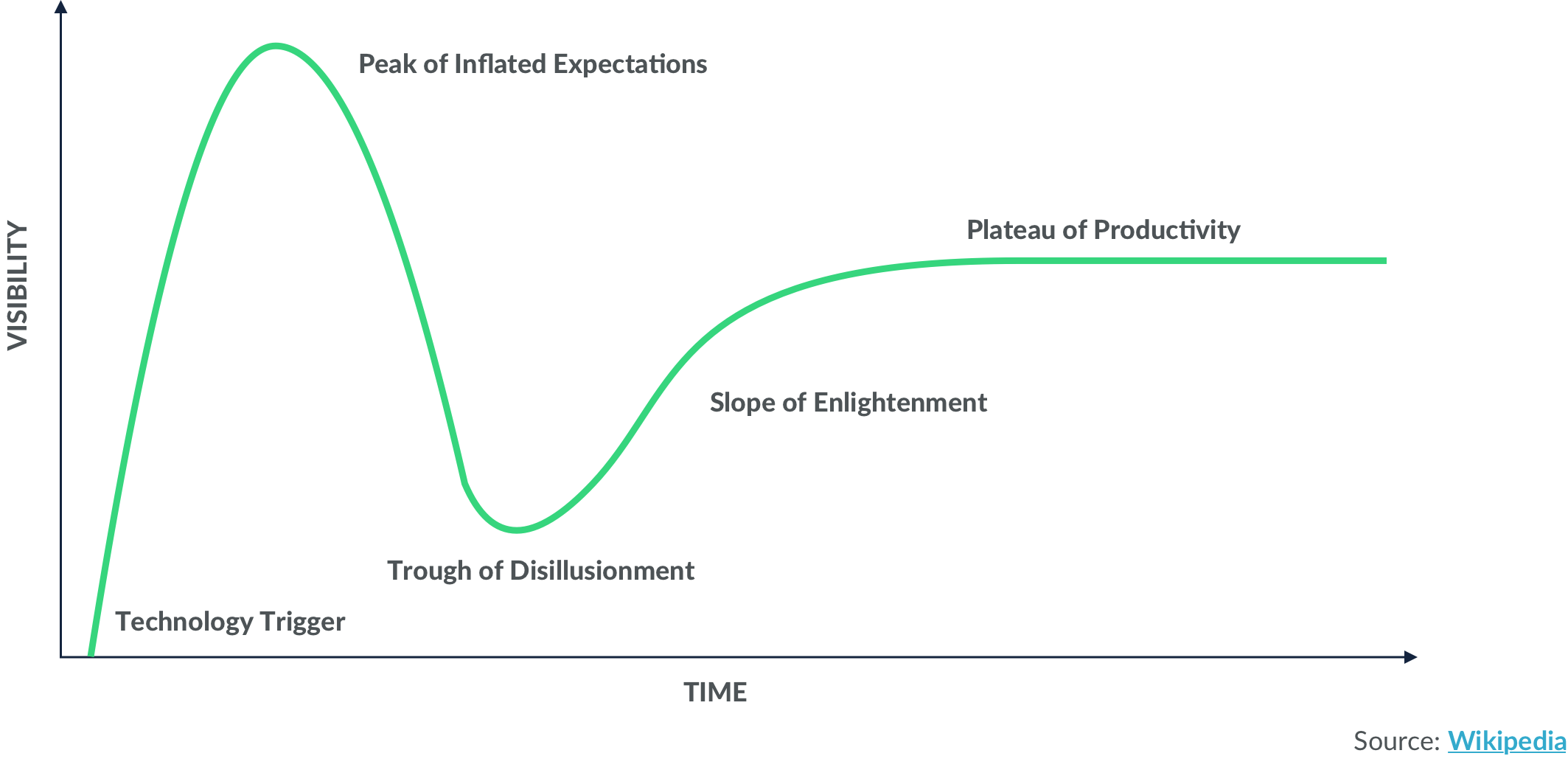
New technologies often follow Gartner’s hype cycle—in fact, OpenAI CEO Sam Altman has already sounded the hype alarm bells about GPT-3.
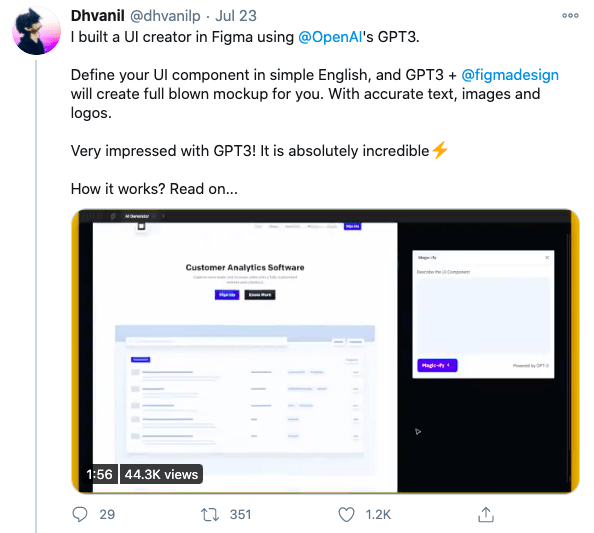
However, the use cases coming out of GPT-3 developers shed light on the type of AI-powered applications we can expect in the medium to long term. Potential applications include tools that will help designers prototype easily, streamline data analysis, enable more robust research, automate content generation for content marketers, and more.
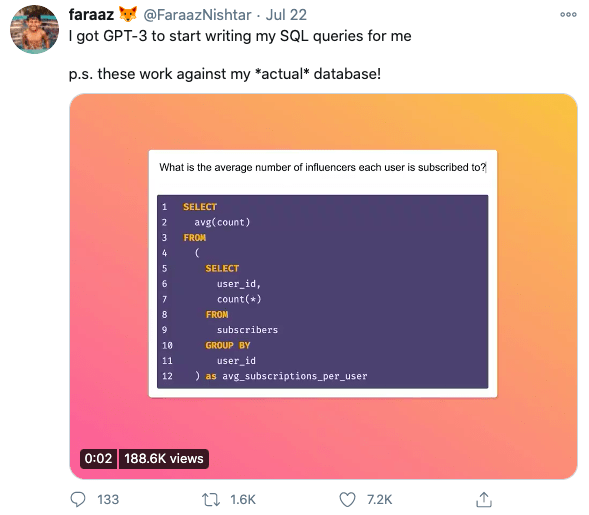
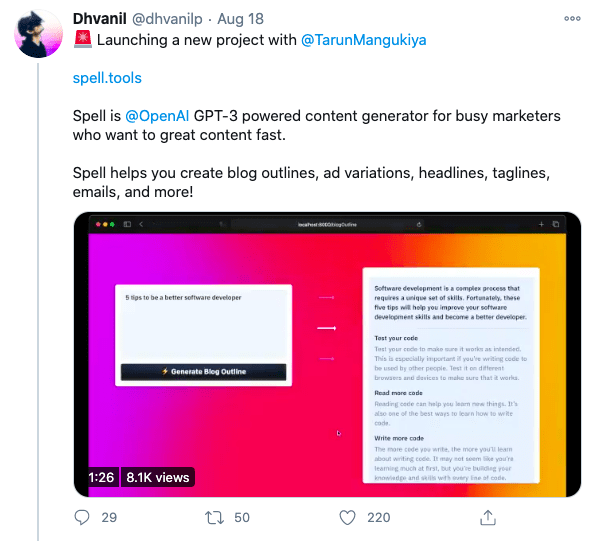
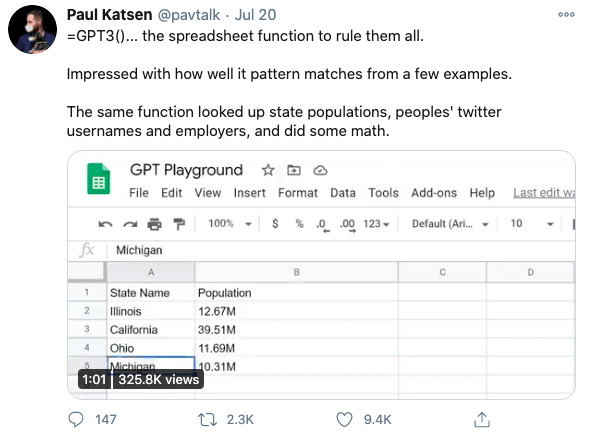
Additionally, packaging the model in an easy plug-and-play interface could change the dynamics of how AI is instrumentalized across the organization. For example, this could disincentivize organizations from developing their own in-house models, and allow less technical experts to build solutions using GPT-3.
Finally, when thinking about deploying AI systems at scale, you must be aware of the capacity to spread harm through bias. As many researchers noted while testing out GPT-3, it’s relatively easy to generate harmful outputs that reinforce stereotypes and biases based on neutral inputs.
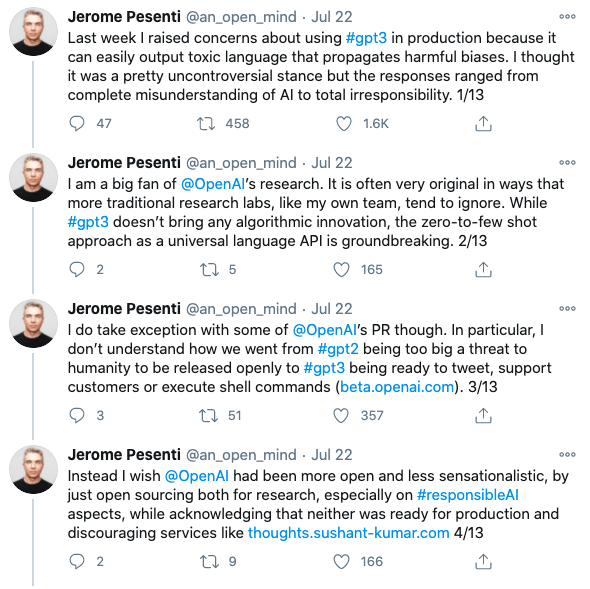
Like any machine learning algorithm being deployed at scale, GPT-3 requires serious scrutiny and monitoring over potential harm.



