

Course
Data Science for Business
2 hr
115.2K
Enhance your team's data literacy and decision-making capabilities with DataCamp for Business. Access diverse courses, hands-on projects, and centralized insights for teams of 2 or more.

Data literacy is the ability to read, write, analyze, communicate, and reason with data. It’s a skill that allows individuals and organizations to make better, data-driven decisions.
As with other key competencies, it’s not a one-size-fits-all concept; multiple facets make up data literacy. It is more than just data analysis; instead, it involves understanding what data means and how to present those findings, including the ability to:
As an individual skillset, the term data literacy suggests a binary. However, this is far from the case. It’s a spectrum that ranges from the ability to make data-driven decisions and tell data stories to more advanced data science, data engineering, and machine learning skills.
From an organizational perspective, leaders should think of data literacy in terms of a scale of fluency. An organization with high degrees of data literacy encompasses a wide range of data skills within its workforce.
Data literacy, the ability to navigate and interpret the vast digital information landscape, is fast becoming an essential life skill and a valuable asset in the job market. In our State of Data & AI Literacy Report, we asked leaders in the UK and the USA how they view the value of data literacy within their organization and how important it is a skillset for individuals to develop.
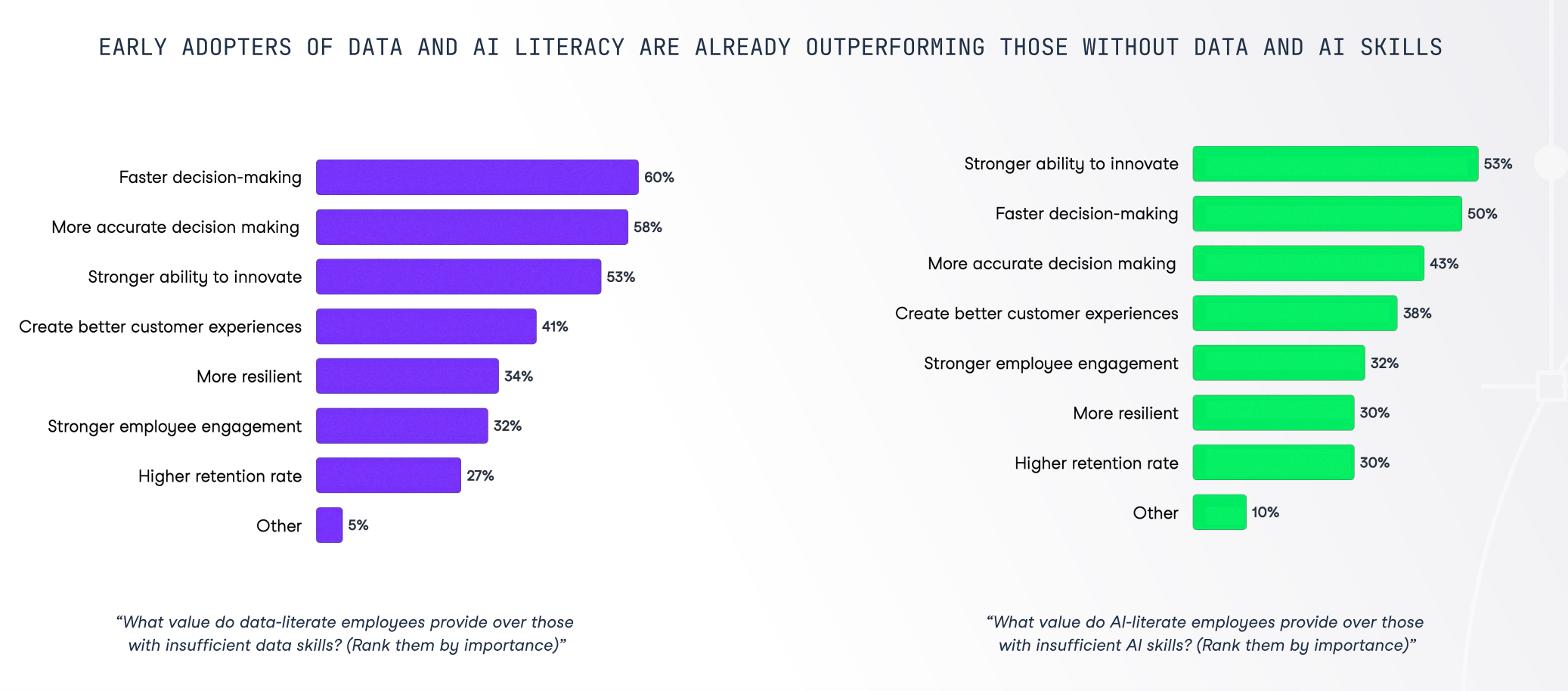
The need for data and AI literacy - The State of Data Literacy Report
Our report confirms the importance business and data leaders attach to a data-literate workforce. The report indicates that 40% of leaders in the US and UK view decreased productivity as the primary risk of insufficient data skills, with inaccurate decision-making (39%), slower decision-making (37%), and hindered innovation (31%) also posing substantial risks.
Leaders are proactive in mitigating these risks, with 79% prepared to offer higher salaries to candidates with strong data literacy skills. Among them, 21% are ready to propose a salary increase of 10-15%, and over a quarter would consider a 30% salary premium. These figures reaffirm the premium value attached to data literacy in the contemporary business landscape.
More broadly, data literacy can help build a more engaged population. Over the past two years, we’ve seen the rise of awe-inspiring AI tools like ChatGPT and Sora AI that generate human-like text and images.
Unfortunately, while the beneficial use cases for these tools are endless, they can also be used to accelerate and power misinformation. This sentiment is echoed by Anjali Samani, Director of Data Science & Data Intelligence at Salesforce.
She believes that, in a time of fake news, deepfakes, and post-truth politics, data literacy is more important than ever.
Everyone should become data literate. Everyone should teach kids how to be data literate and ask important questions about the data and the world around them. In the past, you could say seeing is believing. But with deepfakes and AI-powered misinformation, we can no longer say that. If you're not asking the right questions about the data and the technologies we see, you could be doing yourself and future generations a disservice.
Anjali Samani, Director of Data Science & Decision Intelligence at Salesforce
Data literacy is about creating comfort and confidence in utilizing data within the organization, and it doesn’t mean everyone has to become super technical or be something they are not, but it means everyone is able to drive results with data
Jordan Morrow, Author of Be Data Literate
Data culture is not just an option; it is mission critical.
Sudaman Thoppan Mohanchandralal, Founder of Nautilus Principle, and Former Chief Data Officer at Allianz Benelux
AI literacy is also becoming increasingly important for individual and organisation - we have a separate guide on AI literacy here.
While every organization should look at data literacy in the context of its organizational culture and mission, we can start off with a framework of data literacy skills every organization should look to develop in its people.
Specifically, these skills can be divided according to the definition of data literacy, of reading, writing, analyzing, communicating, and reasoning with data.
You can check out the framework by reading our State of Data Literacy 2024 report. Alternatively, you can also download an editable version of the framework.
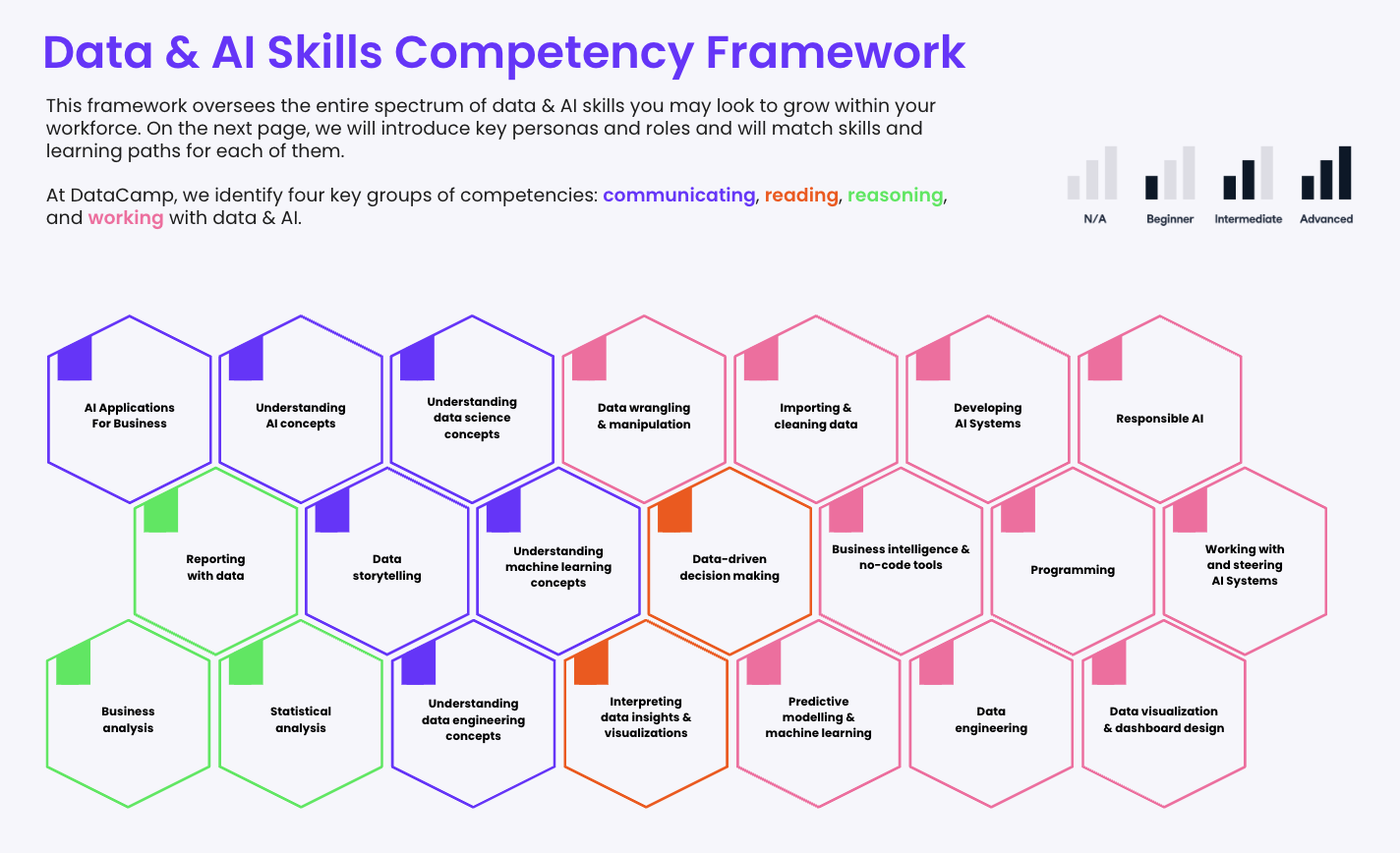
The data and AI competency framework
This skill focuses on understanding the data and using that understanding to make informed decisions. It could be data from a report or dashboard about a particular aspect of the business.
The next level of complexity comes in the form of working with data in a less processed way. This could mean capturing and processing information or using raw data to create visualizations that explain it.
This factor is an extension of the two mentioned above. As well as taking data and making it presentable, this skill is about explaining that data to non-experts in a way that is understandable. Often, this means understanding more advanced data topics.
The final data literacy skill organizations need is for individuals to be able to reason with data. This means extrapolating data insights to make strategies and gain insights into micro and macro trends, and pulling this information together to present findings.
As businesses increasingly embrace data-driven approaches, the question of who should drive data literacy within the organization becomes paramount. Many stakeholders are invested, from Chief Information Officers to Chief Marketing Officers and beyond, but the responsibility may best fit with the Chief Data Officer (CDO).
The advent of the Chief Data Officer role is a testament to the growing importance of data for organizations. In the past ten years alone, the number of Chief Data Officers within organizations has increased sevenfold, going from 12% in 2012 to 82.6% in 2023. Chief Data Officers are mandated with ensuring data is treated as an asset within the organization, and that includes enabling everyone with the mindset and skills to take advantage of data within their day-to-day tasks.
Organizations without a dedicated CDO can assign the task to other data leaders, but it's essential that the role not be solitary. The Learning and Development function or Chief Learning Officer should co-own this endeavor, helping to assess current skills and contextualize data literacy within the organization's future skill set. You can learn more about who owns the data literacy agenda in this podcast.
In the State of Data & AI Literacy 2024 report, we sought to understand from data & learning leaders at the forefront of data and AI literacy upskilling what their most pressing challenges were.
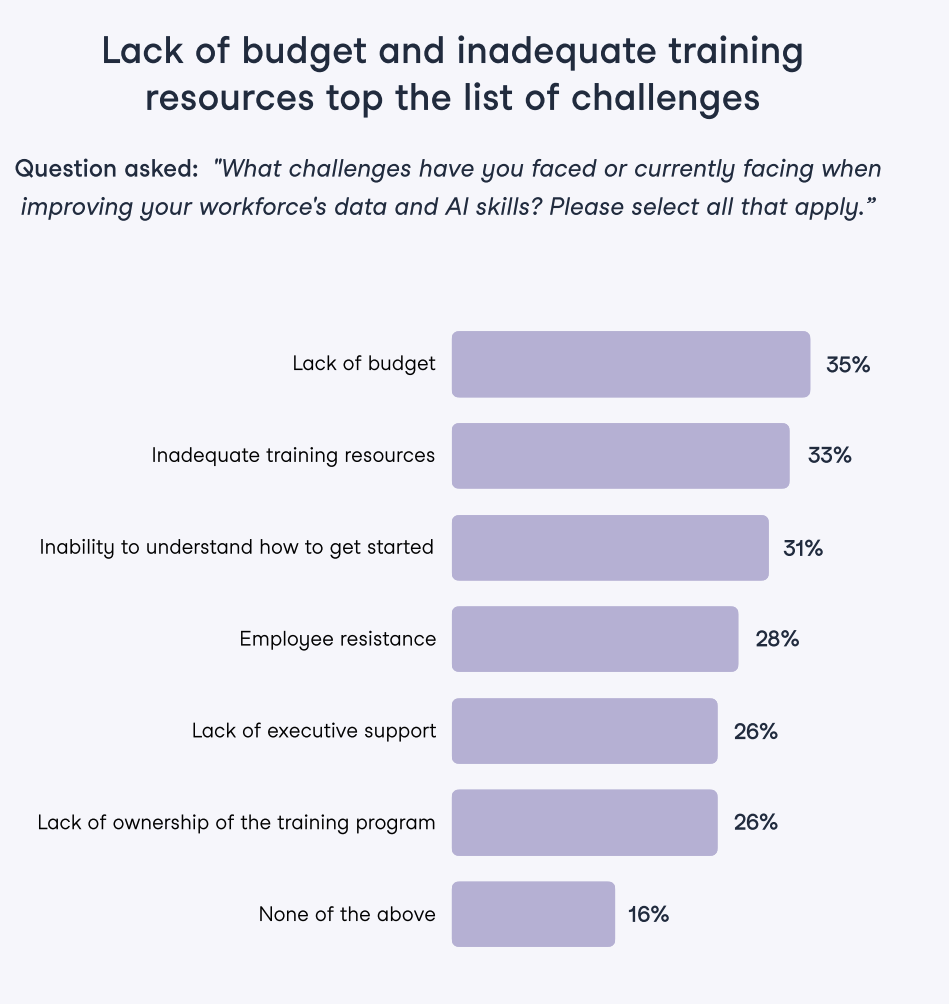
The challenges of building a data literacy program - The State of Data & AI Literacy Report 2024
Looking at these challenges more broadly, we can easily group them into three distinct categories:
Let’s break down how to combat these three challenges.
When surveyed about the biggest challenges leaders face when improving their workforce’s data skills, the biggest culprits were related to executive sponsorship. Namely, these four factors stood out as their challenges:
Executive sponsorship challenges suggest that many organizations have yet to devise comprehensive data strategies that put people at the center of data transformation.
According to Vijay Yadav, Director of Quantitative Sciences & Head of Data Science at the Center for Mathematical Sciences at Merck, successful data strategies also mean prioritizing culture and skills transformation initiatives.
Data culture and skills are a big part of a successful data strategy. Because ultimately, what leaders need to understand is whether everybody in the company sees data as an asset and, if so, how do they see it?
Vijay Yadav, Director of Quantitative Sciences & Head of Data Science at the Center for Mathematical Sciences at Merck
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
No one wants to feel belittled, and when you make data hard and inaccessible, that’s the first feeling folks get. Moreover, leaders shouldn’t use data to punish individuals. We need to use data to improve business processes, to keep teams accountable, but we need to ensure people feel confident surfacing data to discuss business outcomes.
Cindy Howson, Chief Data Strategy Officer at ThoughtSpot
Based on a YouGov survey of 500+ enterprise leaders, find out how organizations are building data and AI skills—and why workforce readiness is emerging as a defining competitive advantage.

We have set different learning objectives for data analytics skills, depending on the different target groups, and shaping tailored learning journeys for each of these groups is crucial.
Elizabeth Reinhart, Data & AI Analytics Capability Building Senior Manager at Allianz
Our data personas were really important for helping us create demand amongst colleagues. It helped us really understand what learning they needed, and we could justify why we've given them some learning content over others based on their persona and their role. It also helped us in our communications because it helped us personalize our messaging and our approach. Our persona work helped us answer “What's in it for me,” because I guarantee you that's all people really care about. How is it going to help them be smarter, quicker, better, and more productive at their job? Part of the persona work really helped bring that to life for people.
Emily Hayward, Data & Digital Change Manager at CBRE
Established in 1890, Allianz has long utilized data in its global insurance and asset management services. Its Group Data Analytics team at Allianz SE took the initiative to empower every employee with data literacy, extending the program beyond typical insurance roles to include HR and Communications.
Allianz partnered with DataCamp to create personalized learning solutions, featuring 22 tailored learning paths and three capstone projects with real Allianz use cases.
They launched the program with a trial involving 100 people and quickly scaled it to engage over 6,000 learners.
Feedback was overwhelmingly positive, with a 4.2/5 average rating from Allianz learners and employees, saving an average of 1.9 hours per week thanks to their new skills.
Overall, the program offered 19,000 hands-on learning hours across diverse topics, reinforcing Allianz's commitment to data literacy.
CBRE, a global leader in commercial real estate, recognized the need to build data literacy to drive efficiencies, enhance client outcomes, and prepare for the industry's rapidly changing landscape. They sought a comprehensive and scalable data upskilling solution for their 2,000+ employees in the UK and Ireland to achieve these goals.
CBRE partnered with DataCamp for Business to develop a tailored, holistic data literacy program that focused on engagement, personalization, and inclusion, meeting the specific needs of various employee personas across the organization.
By partnering with DataCamp for Business, CBRE employees saved 1-2 hours per learner per week, 81% of the workforce reported increased confidence in working with data, and the program achieved an 88% positive engagement rate.
We’ve collated an assortment of resources that can help you and your organization get started with your data literacy journey.

A collection of data literacy cheat sheets
In a data-driven world, data literacy is no longer just a desirable skill; it's a necessity. As we've discussed throughout this article, data literacy is vital at both an individual and organizational level. It empowers individuals to navigate today's digital landscape, enhances their employability, and enables businesses to make informed decisions, drive innovation, and gain a competitive edge. However, becoming a data-literate organization isn't a one-size-fits-all journey.
It requires understanding your organization's unique needs, aligning learning objectives with business goals, and fostering a continuous learning culture. The key is to start small with a pilot project, measure its impact, and then scale according to the needs of your organization. DataCamp for Business can help all throughout this journey. We’ve worked with more than 3,500+ organizations on their data literacy ambitions. To learn more about how we can help transform your organization’s data literacy, you can speak to a learning expert.
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
Learn more about data literacy with these courses!
Course
Course
Course
blog
Kurtis Pykes
14 min
blog
Matt Crabtree
7 min
blog
Matt Crabtree
7 min
blog
Matt Crabtree
5 min
blog
Travis Tang
6 min
blog
DataCamp Team
5 min


