Course
Introduction to Data Science in Python
4 hr
498.3K

Notebooks have been commonplace in data science for most of the last 10 years and every data scientist has worked with one. They allow data scientists to rapidly experiment and share insights through quick environment creation, interactive output, and code snippets that can be executed in any order.
Organizations have been investing heavily in data science and analytics and a key area of investment have been tools that allow data scientists to work efficiently and rapidly experiment with data. Notebooks are at the crux of this and are a component of many tooling innovations we see in the modern data stack today. More importantly, notebooks are also empowering citizen data scientists to democratize data insights.
This article looks at the past, present, and future of the notebook and how notebooks are breaking down silos for data work and collaboration.
Almost every data scientist today has used a notebook, with the most popular being Jupyter Notebooks. However, notebooks have a rich history that precedes data science—one dating back to the early 1980s.
Introduced in 1984 by Donald Knuth, literate programming was intended as a methodology to create programs that are readable by humans. The idea was to write out the program logic in human language with code snippets and macros written as separate comments, known as “WEB”. The macros are similar to pseudocode used to teach computer science.
A preprocessor then parses the WEB to create source code (“tangle”) and documentation (“weave”). Literate programming is still used today, for example in Axiom, but the key ideas within literate programming led to the development of notebooks that look very similar to those we see today.
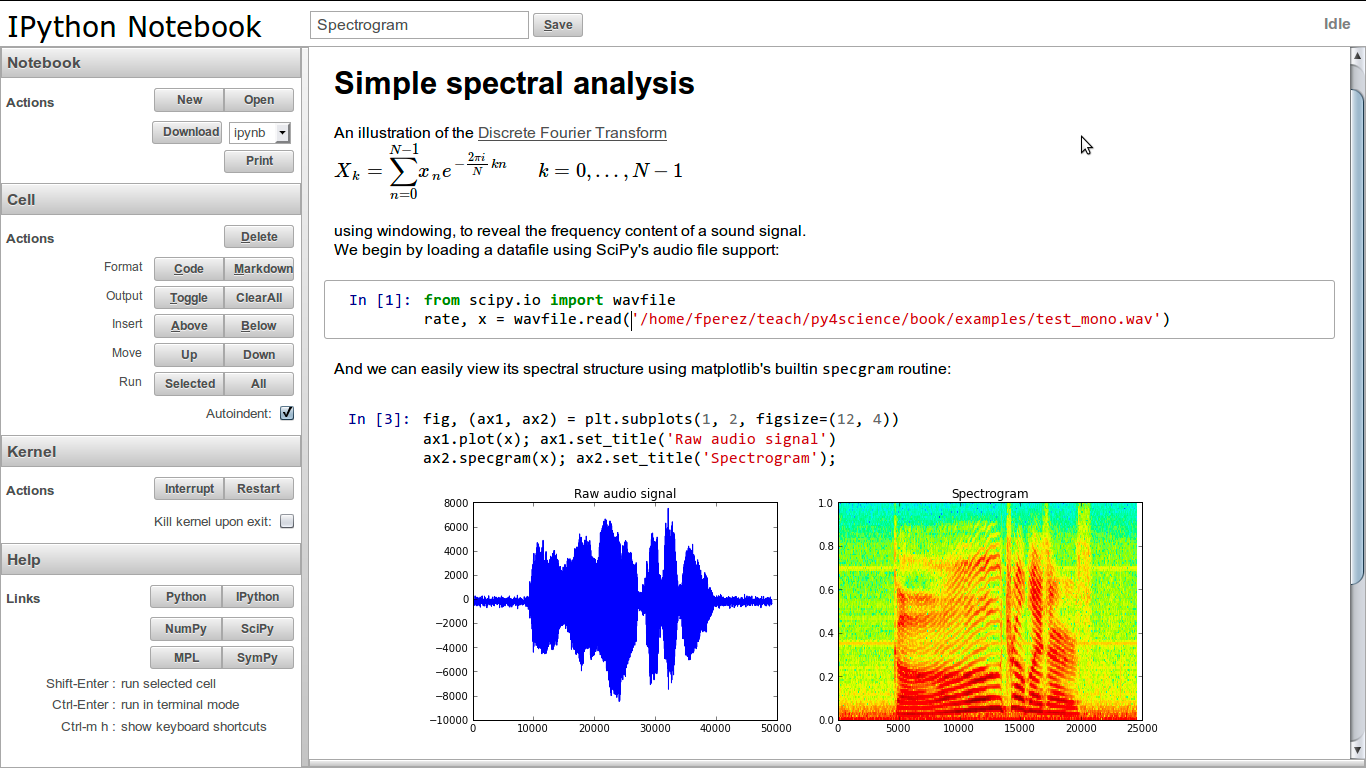
The key early notebooks were Wolfram Mathematica and Maple, released in the late 1980s. They operated with a front end and a kernel in the back end. The image below shows a 3D plot generated using Mathematica with the familiar In[ ] and Out[ ] notation we continue to see in notebooks today.

The Early Wolfrom Mathematica Notebook
These tools had subtle differences, such as using enter rather than shift + enter to run code and variations in the way mathematical operations were displayed. However, both contained ideas that influenced how modern notebooks have been designed.
A key barrier to widespread adoption was cost, as these tools were expensive and required a license to use. This was an issue across the industry that led to the creation in 1998 of the Open Source Initiative, which has led to many of the powerful, free tools we use today (e.g. Jupyter Notebooks!).
In 2001, IPython and SciPy were released, with Matplotlib following in 2003. SciPy allowed a range of scientific calculations to be made in Python, while IPython improved the user experience in the terminal and added support for distributed computing. Like today, Matplotlib allowed for the easy creation of data visualizations in Python.
It wasn’t until 2005 that these open-source tools (and others) were brought into a single tool known as SageMath. The goal of this was to provide an open-source alternative to Mathematica and Maple, combining and building on top of other scientific open-source tools, and providing web-based features that are a staple of modern notebooks today.
In 2011, IPython released its notebook which had a clear distinction between the web application front end and the underlying notebook document.
The IPython Notebook
Jupyter was spun out of IPython in 2014, introducing the notebook interface and taking other language-agnostic parts of IPython. It was named after the original languages it supported: Julia, Python, and R. Jupyter notebooks are now the go-to for data scientists and are undoubtedly the most widely used notebook interface today.
A key area of development in recent years has been apps that separate the front end from the kernel so that the front end is accessed by the user in a browser but the kernel runs in cloud-based data centers. A great example of such a tool is DataCamp Workspace, where you can start working with a Jupyter Notebook instance directly in your browser.
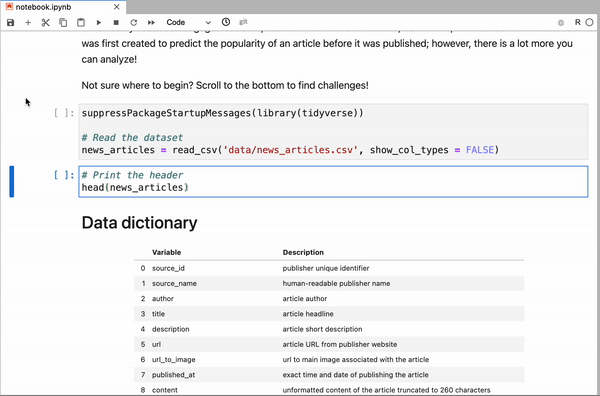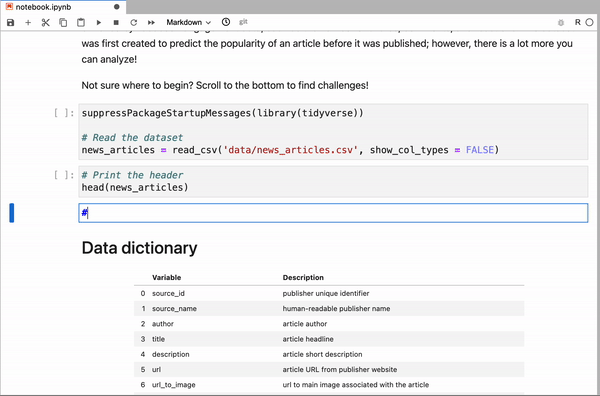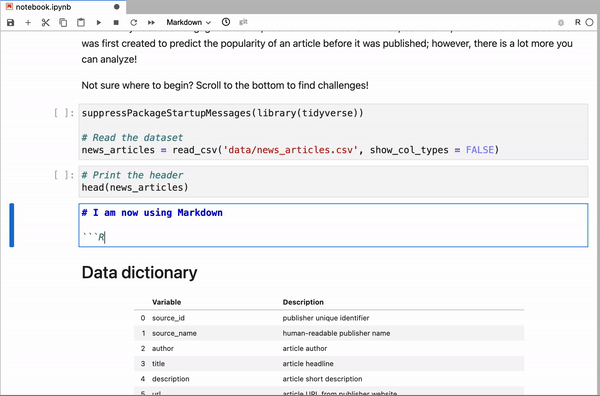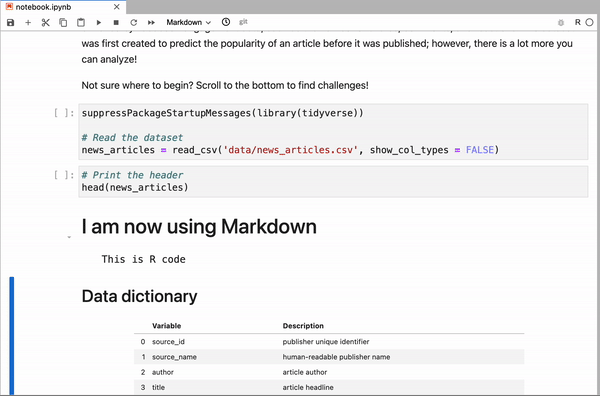
JupyterLab in DataCamp Workspace
As notebooks rose in their adoption and popularity, the past few years have ushered in a wave of modern notebook interfaces that enable anyone to work with data easily. In the next section, we’ll break down how modern notebooks are breaking down barriers to working with data.
The idea of Citizen Data Scientists was coined by Gartner in 2016. Citizen Data Scientists have technical skills but may not have traditional data science, statistics, or computer science backgrounds.
As data science increasingly branches out from being a field to a methodology for solving business problems, Citizen Data Scientists are the face of the modern data-driven organization. Notebooks are an excellent tool for Citizen Data Scientists because they allow rapid experimentation and shareable insights with little to no barriers to entry.
While notebooks have always been excellent for quickly exploring and analyzing a dataset, they have previously been lacking in areas such as collaboration and sharing insights. In 2022, this is no longer the case as modern notebooks and the surrounding ecosystem meet many of these historical blind spots. Here are some of the ways notebooks are ushering in gains in productivity, efficiency, and collaboration.
One clear example of a modern collaborative tool is Google Docs. Many users can use and edit documents, though users can also control who can make edits and who can only suggest comments. Changes are regularly saved in order to prevent disasters from happening.
Similar technology is now available for notebooks with tools like Deepnote and Datacamp Workspace. Multiple users can edit and run notebooks as well as leave comments. All of this collaboration happens in real-time, making the whole process much more efficient.
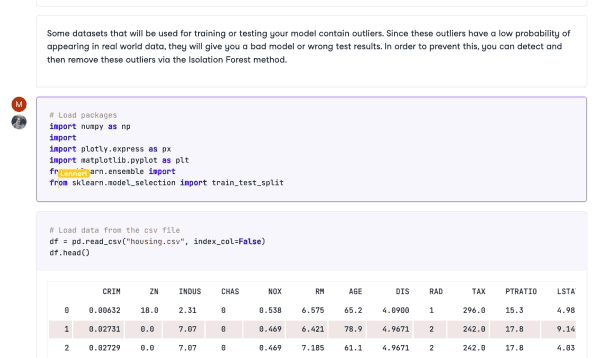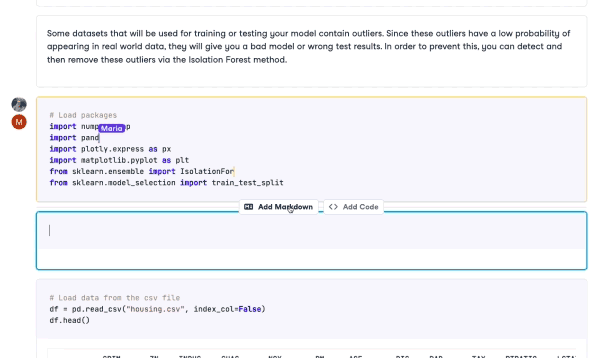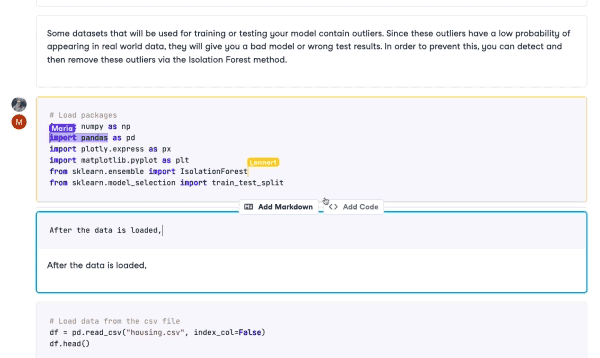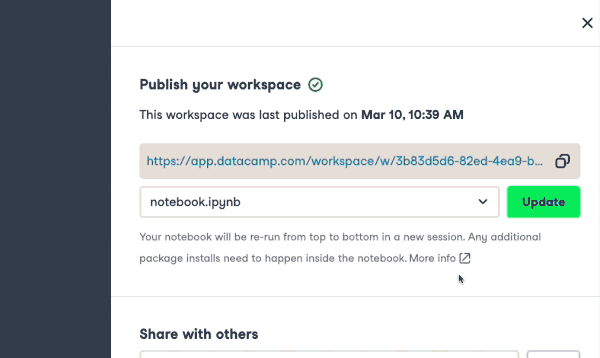
Collaboration in DataCamp Workspace
Collaboration is essential for anyone who works with data. Reducing barriers to collaboration also means reducing data silos by sharing knowledge and expertise. While traditionally, collaborating using notebooks can be slow, the modern data stack is quick and efficient. Many tools integrate seamlessly into an existing tech stack, meaning users can work with the tools they are used to while still collaborating with their colleagues.
Sharing analysis with other users can be difficult—whether they are business stakeholders or more technically minded individuals. Historically, practitioners shared notebook reports in insights via email, Slack, presentations, or custom-built web apps.
However, modern notebooks democratize insights by seamlessly allowing notebooks to be shared. For example, IPyWidgets allows interactive widgets to be added to notebooks, which means users can drag sliders to change graphics and interact more with the insights. Binder turns a repo into hosted interactive notebooks, which means an interactive notebook can be shared and run by anyone else. Voila turns a notebook into a hosted web app, again meaning users can fully interact without even seeing all the code. Datacamp Workspace allows users to share notebooks and provide templates to add stories to data.
Publishing Reports in DataCamp Workspace
Data science is both wide and deep: there is so much to learn in many different areas. Being an NLP expert doesn’t make you a great data engineer or even someone who understands computer vision.
A key link between the different subfields of data science is data and infrastructure. Without good data, models will not perform well. Similarly, without the infrastructure to support model development and data cleaning, it is very difficult to get started.
For Citizen Data Scientists, skills in engineering are not required. Modern notebooks allow anyone to get up and running quickly by leveraging cloud-based infrastructure. Environments and packages are well managed and can be easily updated and modified by most users. This ensures gaps in engineering skills don’t need to be filled, and practitioners can spend time delivering insights.
Moreover, most data science techniques are fully compatible with notebooks—models can be trained, 3D graphs can be plotted, and data pipelines can be built. This ensures Citizen Data Scientists can experiment with the full range of techniques and easily communicate the results to stakeholders or share the code with other technical users.
We’ve already looked at how modern notebooks break down data siloes between teams and lower the barrier to entry for working with data. However, another pain point notebooks historically have had is the lack of integration with other tools used within the data science workflow. A key example of this is SQL.
Historically, practitioners set up database connections with packages such as `mysql.connector` on Python or `DBI` on R. These packages required manually setting up database connections, and manually inputting relevant credentials for data access.
Modern notebooks, on the other hand, provide native SQL support. For example, using DataCamp Workspace, users can set up a secure connection directly from the DataCamp Notebook Editor to databases, like PostgreSQL, MySQL, and Amazon Redshift. Data extracted from integrated databases can then be analyzed using R or Python.
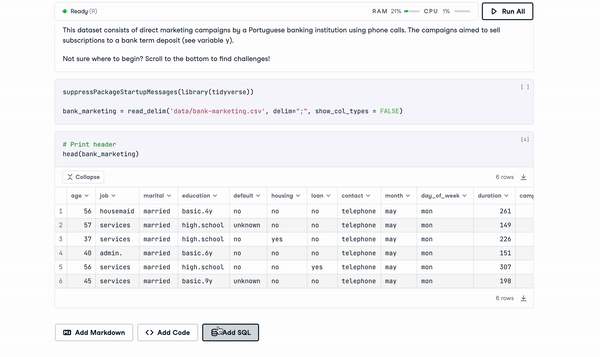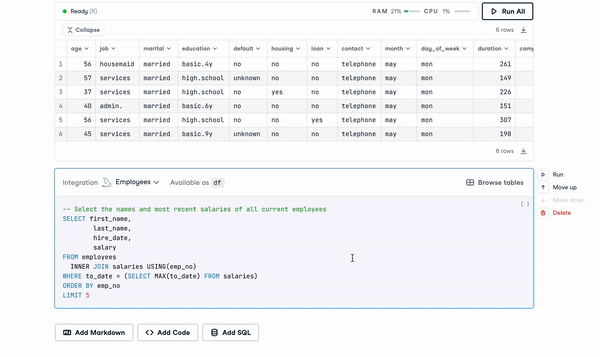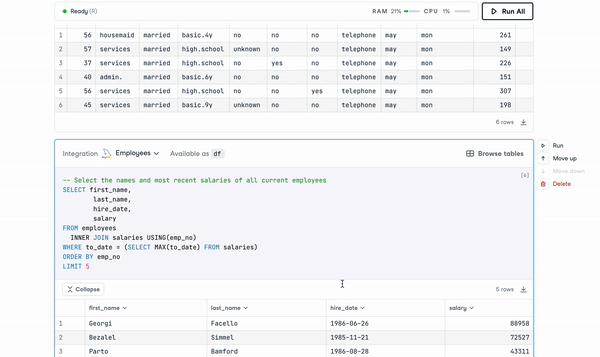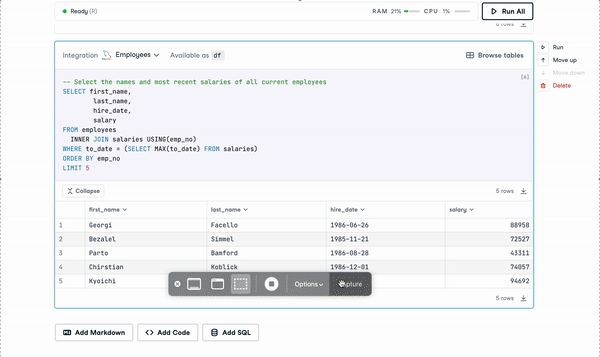
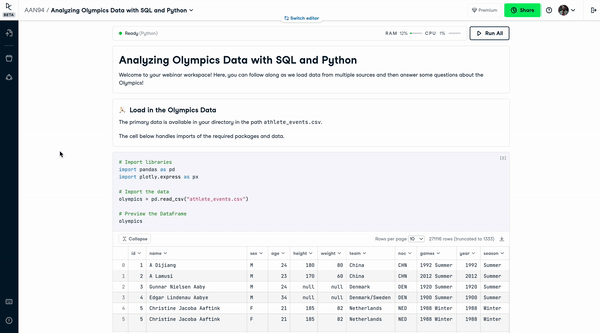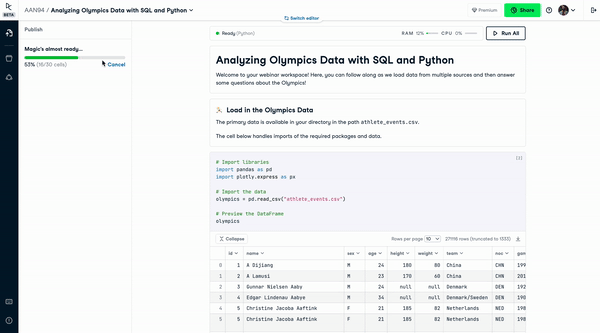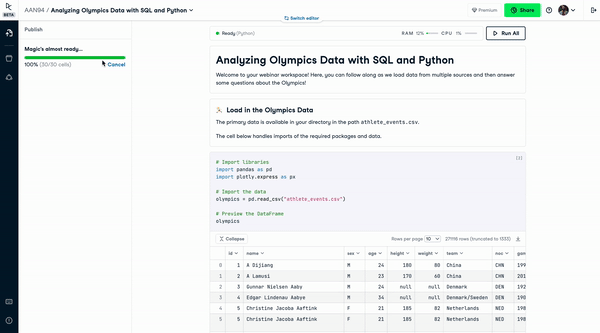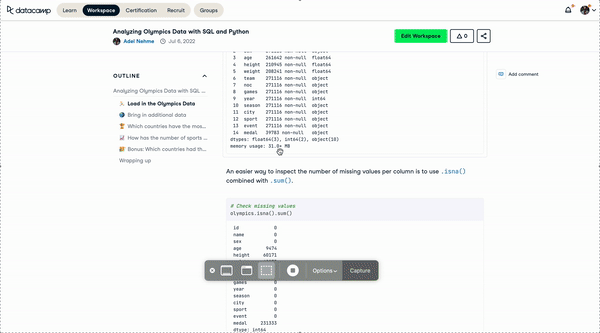
SQL Cells in DataCamp Workspace
The Modern Notebook is at the heart of the data revolution. It equips practitioners of varying skill sets to easily experiment with data, share insights, and bridge the gap between the business and the data team. Moreover, notebooks are empowering citizen data scientists, ushering in a new wave of data fluency within organizations today.
Data-first organizations like Netflix are famous for their notebook innovation, as notebooks are their most popular tool for working with data across personas and teams. The Future of Notebooks will be defined by increased agility, better integration with the remaining data stack, and robust collaboration and sharing to democratize data insights. To learn more about notebooks, check out the following resources:
Learn more about Data Science
Course
Course
Course
blog
Filip Schouwenaars
3 min
podcast
podcast
podcast
Tutorial
Çağlar Uslu
code-along
Joe Franklin


