
Kurs
KI-Ethik
1 Std.
129.4K
Die KI entwickelt sich so schnell, dass es sich anfühlt, als würde man versuchen, ein Flugzeug während des Fluges zu reparieren, wenn man mit den Herausforderungender Sicherheits en Schritt halten will . Je intelligenter Systeme werden und je tiefer sie in alltägliche Geschäftsprozesse eingebunden sind, desto anfälliger werden sie auch für neue Arten von Bedrohungen.
Ich hab das in meiner Arbeit aus nächster Nähe mitgemacht. Ich habe schon oft Sicherheitslücken in Geschäftsprozessen entdeckt, die es jemandem ermöglicht hätten, auf sensible Informationen zuzugreifen, auf die er keinen Zugriff haben sollte, vor allem wenn KI-Lösungen überstürzt und ohne angemessene Sicherheitsmaßnahmen implementiert wurden.
Darum geht's in diesem Artikel: die Risiken, Herausforderungen und bewährten Methoden für die Sicherheit von KI verstehen. KI entwickelt sich so schnell, und wenn wir den Schwachstellen nicht immer einen Schritt voraus sind, riskieren wir, das Vertrauen und die Vorteile zu verlieren, die sie mit sich bringt.
Wenn du mehr über dieses Thema erfahren möchtest, empfehle ich dir, dir die Kurs „KI-Sicherheit und Risikomanagement” anzuschauen.
KI braucht Daten, um zu funktionieren. Und je mehr Daten deine KI nutzt, desto größer ist das Ziel. Hacker wissen das. Stell dir vor, ein Krankenhaus nutzt KI, um Gesundheitsrisiken von Patienten vorherzusagen. Klingt super, bis jemand das System hackt. Plötzlich sind private Patientenakten im Dark Web frei zugänglich oder, noch schlimmer, medizinische Daten werden verändert, was zu schädlichen Entscheidungen führen kann. Die Verschlüsselung sensibler Daten und das Erstellen von Backups sind super wichtig, aber viele Firmen sind so auf Innovation fixiert, dass sie diese grundlegenden Dinge vergessen.
Und Hacker klauen übrigens nicht nur Daten. Sie können selbst mit KI-Modellen herumspielen. Zum Beispiel könnte ein selbstfahrendes Auto denken, dass ein Stoppschild ein Tempolimit-Schild ist. Diese Art von Angriff wird als Datenvergiftungsangriff, bei der Hacker falsche Daten ins System schicken, um die Entscheidungen zu beeinflussen. Wir werden uns das im nächsten Abschnitt genauer anschauen.
Prompt-Injection-Angriffe sind auch eine Art von Angriff. Das sind raffinierte Tricks, die eine KI dazu bringen, was zu sagen oder zu tun, was sie eigentlich nicht tun sollte. Wir haben einen super Artikel über Prompt-Injection, deshalb gehen wir in diesem Artikel nicht so sehr ins Detail, aber er ist echt lesenswert.
Ironischerweise nutzen Hacker auch KI, um zu hacken. Hier geht's um Cybersicherheit zu einem Wettlauf gegen die Zeit – Hacker entwickeln sich weiter, und Sicherheitsteams müssen genauso schnell reagieren. Tools wie die Anomalieerkennung können helfen, sind aber nicht immer zuverlässig.
Hast du schon mal das Sprichwort gehört: „Eine Kette ist nur so stark wie ihr schwächstes Glied“? Das trifft voll und ganz auf KI zu. Firmen bauen oft vorgefertigte KI-Tools in ihre Systeme ein. Aber was passiert, wenn eines dieser Tools kaputt geht? Stell dir vor, ein beliebter Chatbot, den hunderte von Unternehmen nutzen, wird gehackt. Das sind Hunderte von Unternehmen – und all ihre Kundendaten –, die gefährdet sind. Das ist ein digitaler Dominoeffekt.
Und dann ist da noch die Lücke beim Fachwissen. Die KI-Nutzung nimmt zu, aber die Cybersicherheit für KI hinkt noch hinterher.
KI-Systeme haben mit echten Sicherheitsrisiken zu kämpfen, die ihre Leistung und Zuverlässigkeit beeinträchtigen können. Schauen wir uns mal die größten Risiken an.
Adversarial Attacks tricksen KI-Systeme aus, indem sie kleine, heimtückische Änderungen an den Eingaben vornehmen, die die KI verarbeitet. Diese Änderungen sind so subtil, dass Menschen sie normalerweise nicht bemerken, aber sie können die KI total verwirren und dazu bringen, die falsche Entscheidung zu treffen.
Zum Beispiel:
Für diese Angriffe muss der Angreifer nicht wissen, wie die KI intern funktioniert, was ein weiterer Grund dafür ist, dass diese Angriffe echt schwer zu erkennen und zu stoppen sind.
Schauen wir uns jetzt ein paar Beispiele aus der Praxis an.
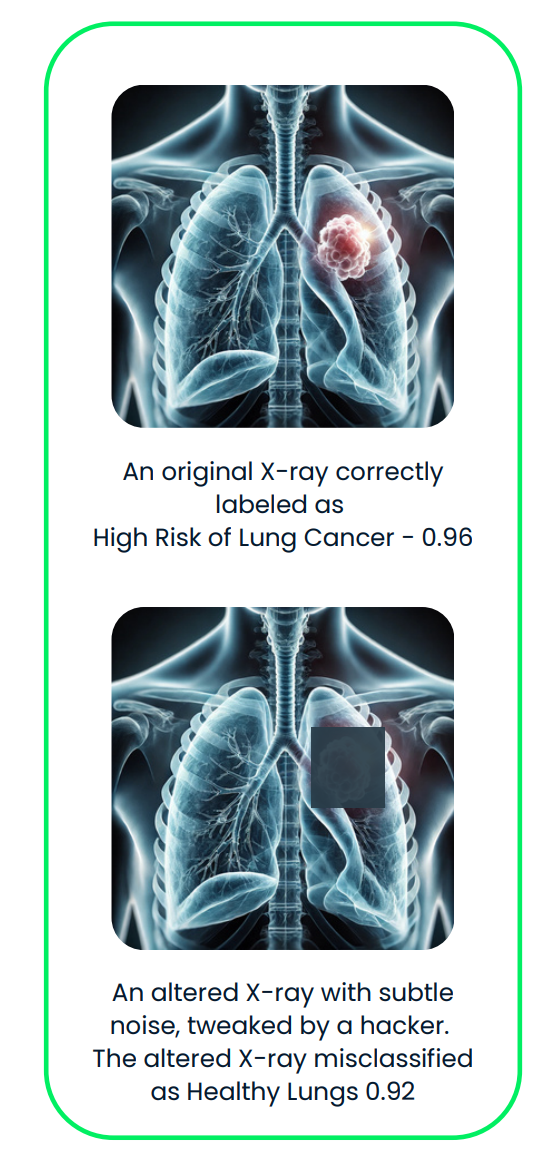
Dieses Diagramm zeigt einen gegnerischen Angriff auf ein KI-System für medizinische Bildgebung. Das Original-Röntgenbild, das richtig als „hohes Lungenkrebsrisiko“ eingestuft wurde, wird mit gegensätzlichem Rauschen leicht verändert, was zu einer falschen Einstufung als „gesunde Lunge“ führt.
Eine super Lektüre ist Adversarial Machine Learning, ein Bereich, der sich mit Angriffen beschäftigt, die Schwachstellen in Machine-Learning-Modellen ausnutzen, und Abwehrmaßnahmen entwickelt, um vor diesen Bedrohungen zu schützen.
Vergiftungsangriffe zielen auf die Trainingsphase von KI-Systemen ab, in der das Modell lernt, wie man Entscheidungen trifft. Angreifer schmuggeln kaputte oder irreführende Daten in den Trainingssatz, um die KI dazu zu bringen, sich falsch zu verhalten oder voreingenommene Ergebnisse zu bevorzugen. Diese Angriffe funktionieren, weil sie die Grundlage des Lernprozesses der KI manipulieren, oft ohne offensichtliche Anzeichen dafür zu hinterlassen, dass etwas nicht stimmt.
Das kann Folgendes beinhalten:
Diese kleinen Änderungen können dazu führen, dass die KI unter bestimmten Bedingungen versagt oder so reagiert, dass es dem Angreifer hilft. Da der Angriff während des Trainings passiert, ist er schwer zu erkennen, wenn das Modell mal eingesetzt wird.
Schauen wir uns ein paar Beispiele aus der Praxis an:

Dieses Diagramm zeigt einen Poisoning-Angriff auf ein KI-System, das falsche und echte Versicherungsansprüche sortiert. Im ersten Panel trennt das System falsche (rote) und echte (schwarze) Behauptungen mithilfe eines sauberen Trainingsdatensatzes richtig voneinander. Im zweiten Panel verschiebt böswillig falsch beschriftete Daten („Poison“) die Entscheidungsgrenze, was dazu führt, dass falsche Behauptungen fälschlicherweise als wahr eingestuft werden, was die Zuverlässigkeit und Sicherheit des Systems gefährdet.
Bei einem Modell-Extraktionsangriff findet ein Angreifer durch Reverse Engineering heraus, wie ein KI-Modell funktioniert. Sie nutzen die gesammelten Eingaben und Ausgaben, um das Design und Verhalten des Systems nachzumachen.
Sobald sie eine Nachbildung des Modells gebaut haben, können sie:
Wenn das geklaute Modell zum Beispiel mit privaten Kundendaten trainiert wurde, könnte der Angreifer persönliche Details über diese Kunden erraten oder eine angepasste Version des Modells für sich selbst basteln.
Schauen wir uns ein paar Beispiele aus der Praxis an:
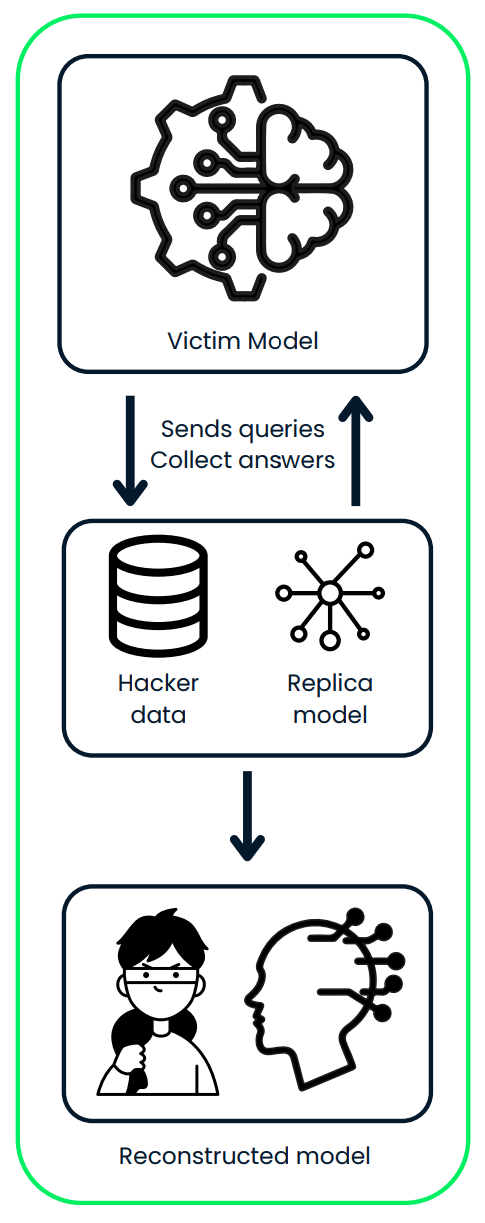
Dieses Diagramm zeigt einen Modell-Extraktionsangriff, bei dem ein Angreifer mit einem KI-Modell interagiert, indem er Anfragen sendet und dessen Vorhersagen sammelt. Der Angreifer nutzt die gesammelten Daten, um ein Replikatmodell zu trainieren und so eine geklaute Version des Originalsystems zu bauen.
Wir haben schon in den vorherigen Abschnitten gesagt, dass es wichtig ist, starke Sicherheitsmaßnahmen zu haben, um sich vor Angriffen zu schützen, wenn KI immer mehr zum Alltag wird. Lass uns über ein paar coole Möglichkeiten reden, wie man KI sicherer machen kann.
Bei dieser Methode lernen Modelle, knifflige, manipulierte Eingaben (sogenannte Adversarial Examples) zu erkennen und damit umzugehen. Wenn du dein Modell mit diesen Beispielen trainierst, wird es besser darin, bestimmten Arten von Angriffen zu widerstehen.
LLM-Destillation bedeutet, dass ein zweites Modell trainiert wird, um das Verhalten des ursprünglichen Modells nachzuahmen, damit es für Angreifer schwieriger wird, es zu manipulieren.
Es ist super wichtig, dass die Daten, die in ein KI-System reinkommen, sauber und sicher sind, um es vor böswilligen Eingaben zu schützen.
Wenn man mehrere verschiedene KI-Modelle zusammen benutzt (ein Ensemble), kann das die Systeme sicherer machen. Selbst wenn ein Modell angegriffen wird, können die anderen einspringen.
Wenn man KI-Systeme verständlich macht, können Leute besser nachvollziehen, wie sie funktionieren, und Schwachstellen oder ungewöhnliches Verhalten erkennen. Mehr zu diesem Thema findest du im Kurs „Explainable AI in Python”.
Wenn man KI-Systeme regelmäßig auf Schwachstellen checkt, kann man Probleme frühzeitig erkennen und dafür sorgen, dass sie langfristig sicher bleiben.
Mit diesen Strategien kann man KI-Systeme sicherer machen und besser vor Angriffen schützen. Aber hier ist die Sache: KI-Sicherheit ist keine Sache, die man einmal einrichtet und dann vergessen kann. Es ist ein fortlaufender Prozess.
Wenn neue Bedrohungen auftauchen – und glaub mir, das passiert immer wieder –, müssen Unternehmen auf der Hut sein. Das heißt, man muss ständig nach Schwachstellen Ausschau halten, Systeme aktualisieren und die Abwehrmaßnahmen verbessern.
|
Methode |
Wie es funktioniert |
Warum es hilft |
Nachteile |
|
Adversariales Training |
Mach ein paar Beispiele für manipulierte Daten und pack sie ins Training der KI rein. |
Macht das System widerstandsfähiger gegen Angriffe, die versuchen, es auszutricksen. |
Kann die Genauigkeit der KI bei normalen (sauberen) Daten leicht verringern. |
|
Defensive Destillation |
Trainiere ein zweites Modell, das das Verhalten des ersten Modells nachmacht und seinen Entscheidungsprozess glättet. |
Macht es Angreifern schwerer, Schwachstellen im Modell auszunutzen. |
Braucht echt viel Rechenleistung, vor allem bei großen Modellen. |
|
Eingabevalidierung und -bereinigung |
Stell sicher, dass die Eingaben das richtige Format haben, in den erwarteten Bereichen liegen und keine schädlichen Elemente enthalten. |
Verhindert Datenverfälschungen und sorgt dafür, dass das KI-System reibungslos läuft. |
Muss in mehreren Schritten sorgfältig umgesetzt werden. |
|
Ensemble-Methoden |
Kombiniere Vorhersagen aus mehreren Modellen, um Entscheidungen zu treffen. |
Es ist für Angreifer schwieriger, alle Modelle gleichzeitig zu kompromittieren. |
Man braucht mehr Computer-Power, um mehrere Modelle zu verwalten und zu pflegen. |
|
Erklärbare KI (XAI) |
Benutz Tools wie LIME, SHAP oder Aufmerksamkeitsmechanismen, um KI-Entscheidungen zu erklären. |
Steigert das Vertrauen und macht es einfacher, Probleme wie Voreingenommenheit oder ungewöhnliches Verhalten zu erkennen und zu beheben. |
Einfachere, erklärbare Modelle funktionieren vielleicht nicht so gut wie die komplizierten. |
|
Regelmäßige Sicherheitsüberprüfungen |
Mach Schwachstellenanalysen, Penetrationstests und Codeüberprüfungen, um Schwachstellen zu finden. |
Findet mögliche Sicherheitslücken und sorgt dafür, dass die Vorschriften eingehalten werden. |
Kann je nach Komplexität des Systems ziemlich ressourcenintensiv sein. |
In diesem Abschnitt schauen wir uns neue Trends an, die dafür sorgen, dass KI-Systeme sicher, genau und vertrauenswürdig bleiben.
Zuerst mal, lass uns darüber reden, warum es so wichtig ist, KI-Modelle und Daten zu schützen.
Also, wie kannst du deine KI eigentlich sicher halten? Hier sind ein paar wichtige Strategien:
Lass uns das mal mit einem Beispiel aus dem echten Leben anschauen. Stell dir eine große internationale Bank vor, die ein KI-Modell entwickelt hat, um betrügerische Transaktionen zu erkennen. Dieses System checkt jeden Tag Millionen von Transaktionen, findet verdächtige Muster und meldet Betrugsfälle.
Die Bank hat 50 Millionen Dollar und drei Jahre gebraucht, um dieses System aufzubauen. Wenn es geklaut wird, könnten Konkurrenten es nutzen, ohne einen Cent zu investieren, was die Bank ihren Vorsprung kosten würde.
Dieses Modell verarbeitet sensible Finanzdaten von Millionen von Kunden. Ein Verstoß könnte diese Infos offenlegen und zu hohen Strafen nach Gesetzen wie der DSGVO führen.
Wenn Hacker während des Trainings gefälschte Daten einspeisen, könnten sie der KI beibringen, bestimmte Betrugsmuster zu übersehen, wodurch die Bank angreifbar würde.
Erfahrene Angreifer könnten sogar private Kundendaten aus den Ergebnissen des Modells herausziehen.
Wie schützt die Bank das?
Das Ergebnis ist ein sichereres, zuverlässigeres KI-System, das Kundendaten schützt und sein Versprechen einhält, Betrug effektiv zu erkennen. Das ist ein Gewinn für die Bank und ihre Kunden.
Stell dir vor, du leitest eine Hochsicherheitsanlage, die auf Gesichtserkennung setzt, um alles sicher zu halten. Wir haben aber gelernt, dass KI-Systeme anfällig für Angriffe sind, wie zum Beispiel gegnerische Eingaben oder manipulierte Trainingsdaten. Hacker können das System manipulieren, um sich Zugang zu verschaffen.
Schauen wir uns mal die vier wichtigsten Abwehrmechanismen an, die Angreifer stoppen können:
Das System ist nicht nur clever, sondern auch vorsichtig. Jede Eingabe muss erst mal echt sein, bevor es weitergeht.
Bei der Sicherung von KI geht's darum, die Datenintegrität zu verwalten, proprietäre Modelle zu schützen und sicherzustellen, dass alles mit deiner bestehenden Cybersicherheits-Konfiguration gut zusammenarbeitet. Dazu kommen noch die Herausforderungen durch neue Bedrohungen, die Einhaltung von Vorschriften, ethische Fragen und Schwachstellen in der Lieferkette. Hier sind ein paar Strategien, um den KI-Lebenszyklus sicher zu machen:
Hier ist ein Beispiel aus der Praxis. Nehmen wir mal ein Gesundheitsunternehmen, das ein KI-gestütztes Diagnosetool entwickelt. Ihre Lieferkette umfasst:
Wie sichern sie diese Pipeline?
So haben sie eine sichere KI-Lieferkette, die dafür sorgt, dass ihr Diagnosetool genau, zuverlässig und mit den Branchenstandards kompatibel ist.
KI ist echt stark, aber diese Stärke kann in den falschen Händen gefährlich sein. Wenn ein KI-System gehackt wird oder schlecht gemacht ist, kann das zu voreingenommenen Entscheidungen, unethischen Ergebnissen oder sogar Missbrauch führen. Das ist echt wichtig, vor allem wenn KI Entscheidungen trifft, die echtes Leben beeinflussen – wie zum Beispiel bei Einstellungen, Krediten oder im Gesundheitswesen.
Also, wie können wir KI-Systeme ethischer und widerstandsfähiger machen? Lass uns das in vier wichtige Schritte aufteilen:
Hier ist ein Beispiel aus der Praxis. Reden wir mal über ein großes Tech-Unternehmen, das ein KI-gestütztes Einstellungssystem nutzt. Wie halten sie es ethisch?
Das ist ein Einstellungssystem, das ethisch, fair und transparent ist – auch wenn es zu Kompromissen kommen könnte.
KI-Systeme werden oft als „Black Boxes“ gesehen, was bedeutet, dass ihr Entscheidungsprozess nicht leicht zu verstehen ist. Das kann es schwierig machen, Probleme zu erkennen oder Vertrauen aufzubauen. Wenn du ein Arzt bist, der sich auf ein KI-Tool verlässt, oder ein Patient, der von dessen Entscheidung betroffen ist, willst du Antworten und keine Fragezeichen. Die Lösung ist Erklärbarkeit. Hier sind vier Strategien, um KI-Systeme transparenter und vertrauenswürdiger zu machen:
Schauen wir mal, wie ein Krankenhaus Vertrauen in ein KI-basiertes Dermatologie-Diagnosetool aufbaut – ein System, das Bilderkennung nutzt, um mögliche Hauterkrankungen zu erkennen.
Dieses KI-Tool ist nicht nur clever, sondern auch nachvollziehbar und zuverlässig. Die Ärzte verstehen die Entscheidungen, die Patienten fühlen sich gut aufgehoben und das Krankenhaus sorgt dafür, dass die Technologie fair und genau funktioniert.
Da KI immer mehr Teil unseres Alltags wird, ist es wichtiger denn je, dass sie sicher bleibt. Warum? Weil genau die Kraft, die die Fähigkeiten der KI antreibt, sie auch zu einem Ziel für Angriffe macht. Bedrohungen wie Angriffe, Datenmanipulation und Modelldiebstahl können die Funktionsweise von KI echt durcheinanderbringen.
Also, wie schützen wir KI? Wir haben gelernt, dass es keine Lösung gibt, die für alle passt. Techniken wie Adversarial Training, regelmäßige Audits und mehrschichtige Sicherheitsvorkehrungen können Risiken reduzieren und deine Systeme robuster machen.
Dann gibt's noch generative KI. Große Sprachmodelle bieten echt tolle Möglichkeiten, bringen aber auch neue Schwachstellen mit sich. Von der Erstellung irreführender Inhalte bis hin zur Manipulation, um schädliche Ergebnisse zu liefern – diese Tools müssen genau im Auge behalten werden. In dem Artikel Wie man Leitplanken für große Sprachmodelle bautwerden Sicherheitsmaßnahmen besprochen, die dafür sorgen sollen, dass LLMs sich so verhalten, wie sie sollen.
Ethik und Transparenz sind einfach super wichtig. KI-Systeme müssen fair, nachvollziehbar und vertrauenswürdig sein. Voreingenommenheit und Missbrauch können das Vertrauen zerstören – und Vertrauen ist in der heutigen, von Technologie geprägten Welt das Wichtigste. Leute nutzen nichts, dem sie nicht vertrauen.
Letztendlich ist es wichtig, immer einen Schritt voraus zu sein. KI-Bedrohungen entwickeln sich ständig weiter. Unternehmen müssen ihre Sicherheitsstrategien regelmäßig anpassen, um mit neuen Risiken Schritt zu halten und geschützt zu bleiben.Der Schlüssel liegt darin, proaktiv und wachsam zu sein und sich für Ethik und Transparenz einzusetzen. So können Unternehmen Vertrauen aufbauen und die Vorteile der KI optimal nutzen.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Tutorial
Derrick Mwiti
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree