
Course
AI Ethics
1 hr
129K
AI is evolving so quickly that keeping up with its security challenges feels like trying to fix a plane while it’s in the air. As systems get smarter and more deeply embedded into everyday business processes, they also become more vulnerable to new types of threats.
I’ve seen this up close in my work. There have been many times when I’ve discovered security holes in business processes that could have allowed someone to access sensitive information they shouldn’t have, especially when AI solutions were implemented in a rushed manner without proper security measures in place.
That’s what this article is about: understanding the risks, challenges, and best practices for keeping AI safe. AI is growing so fast, and if we don’t stay ahead of the vulnerabilities, we risk losing the trust and benefits it brings.
If you want to learn about this topic in more detail, I recommend checking the AI Security and Risk Management course.
AI runs on data. And the more data your AI relies on, the bigger the target. Hackers know this. Imagine a hospital using AI to predict patient health risks. Sounds great, until someone hacks the system. Suddenly, private patient records are up for grabs on the dark web, or worse, medical data is altered, which can lead to harmful decisions. Encrypting sensitive data and having backups are key, but many companies are so focused on innovation that they overlook these basics.
And hackers don’t just steal data by the way. They can mess with AI models themselves. For example, a self-driving car being tricked into thinking a stop sign is a speed limit sign. This type of attack is called a data poisoning attack, where hackers feed bad data into the system to corrupt its decision-making. We will look into this in more detail in the next section.
Prompt injection attacks are also another type of attack. These are subtle manipulations that trick an AI into saying—or doing—something it shouldn’t. We have a fantastic article on prompt injection, so we won’t get into much detail in this article, butit's definitely worth a read.
Ironically, hackers are using AI to hack, too. This is where cybersecurity becomes a race against time—hackers innovate, and security teams have to respond just as fast. Tools like anomaly detection can help, but they’re not foolproof.
Have you ever heard the saying, "A chain is only as strong as its weakest link"? This totally applies to AI. Companies often integrate pre-built AI tools into their systems. But what happens if one of those tools is compromised? Imagine a popular chatbot used by hundreds of businesses getting hacked. That’s hundreds of companies—and all their customer data—at risk. It’s a digital domino effect.
Finally, there’s the expertise gap. AI adoption is rising, but cybersecurity for AI is still playing catch-up.
AI systems face serious security threats that can compromise how well and reliable they work. Let’s look at the main threats.
Adversarial attacks trick AI systems making small, sneaky changes to the inputs the AI processes. These changes are so subtle that humans usually can’t notice them, but they can completely confuse the AI into making the wrong decision.
For example:
These attacks don’t require the attacker to know how the AI works internally, which is another reason why it makes these attacks very hard to detect and stop.
Let’s look now at some real-world examples.
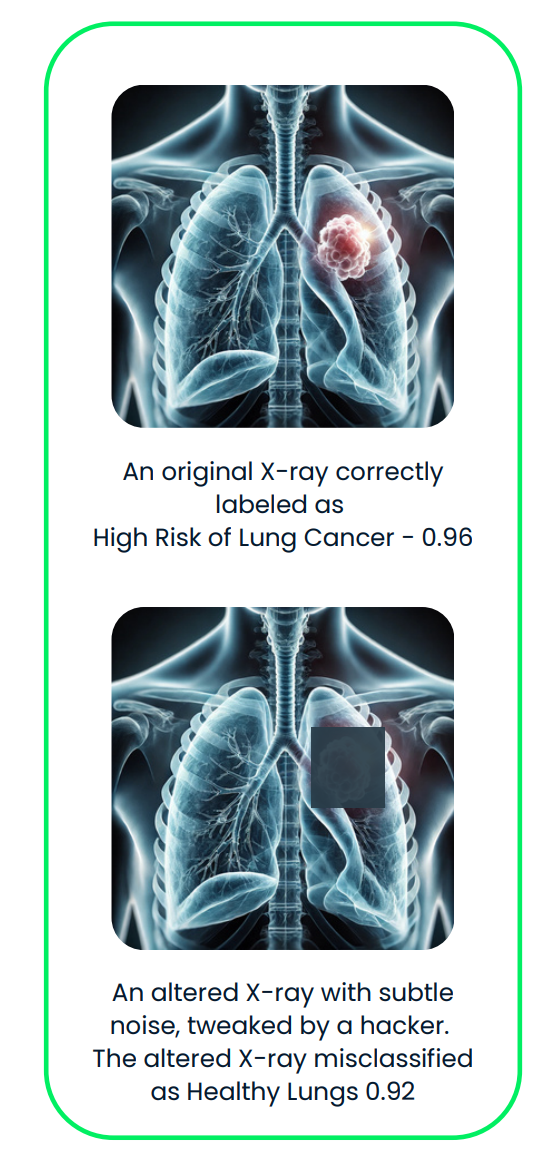
This diagram illustrates an adversarial attack on a medical imaging AI system. The original X-ray, correctly classified as "High Risk of Lung Cancer," is subtly altered with adversarial noise, resulting in a misclassification of "Healthy Lungs."
A great read is Adversarial Machine Learning, a field that studies attacks that exploit vulnerabilities in machine learning models and develops defenses to protect against these threats.
Poisoning attacks target AI systems' training phase, where the model learns how to make decisions. Attackers sneak corrupted or misleading data into the training set so they can manipulate the AI to behave incorrectly or favor biased outcomes. These attacks work because they tamper with the foundation of the AI’s learning process, often without leaving obvious signs that anything is wrong.
This can involve:
These subtle changes can cause the AI to fail under certain conditions or act in ways that benefit the attacker. Since the attack happens during training, it’s hard to spot once the model is deployed.
Let’s look at some real-world examples:

This diagram demonstrates a poisoning attack on an AI system used for classifying false and true insurance claims. In the first panel, the system correctly separates false (red) and true (black) claims using a clean training dataset. In the second panel, maliciously mislabeled data (“poison”) shifts the decision boundary, leading to misclassification of false claims as true, compromising the system’s reliability and security.
In a model extraction attack, an attacker figures out how an AI model works by reverse-engineering it. They use the inputs and outputs they collect to copy the system’s design and behavior.
Once they’ve built a replica of the model, they can:
For example, if the stolen model was trained on private customer data, the attacker could predict personal details about those customers or create a customized version of the model for their own use.
Let’s look at some real-world examples:
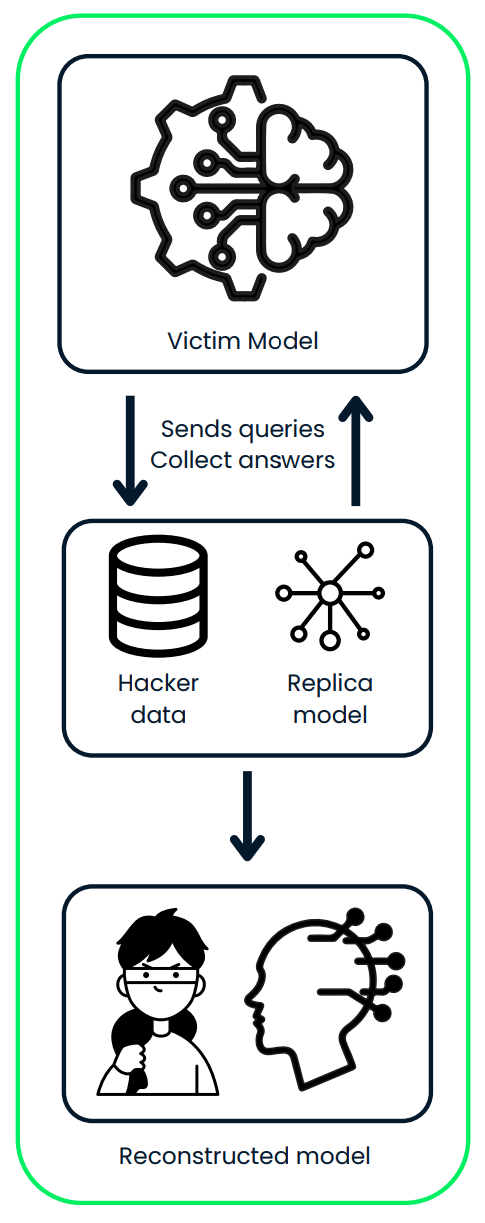
This diagram illustrates a model extraction attack, where an attacker interacts with a victim AI model by sending queries and collecting its predictions. The attacker uses the gathered data to train a replica model, ultimately reconstructing a stolen version of the original system.
We have mentioned in previous sections how, as AI becomes more common, it’s important to put strong security measures in place to protect against attacks. Let’s talk about some effective ways to make AI safer.
This method involves teaching models to recognize and handle tricky, manipulated inputs (called adversarial examples). When you train your model with these examples, it becomes better at resisting certain types of attacks.
LLM distillation involves training a secondary model to mimic the behavior of the original model with the goal of making it harder for attackers to manipulate.
Ensuring that the data going into an AI system is clean and safe is key to protecting it from malicious inputs.
Using several different AI models together (an ensemble) can make systems more secure. Even if one model is attacked, the others can provide backup.
Making AI systems explainable helps people understand how they work and detect any vulnerabilities or unusual behavior. You can explore this topic in more detail in the Explainable AI in Python course.
Regularly checking AI systems for weaknesses can help catch problems early and make sure they stay secure over time.
Using these strategies can make AI systems more secure and better protected against attacks. But here’s the thing—AI security isn’t a "set it and forget it" kind of deal. It’s an ongoing process.
As new threats pop up—and trust me, they always do—businesses need to stay on their toes. That means constantly monitoring for vulnerabilities, updating systems, and improving defenses.
|
Method |
How it Works |
Why it Helps |
Drawbacks |
|
Adversarial Training |
Create examples of manipulated data and include them in the AI’s training. |
Improves robustness against adversarial attacks that try to trick the system. |
May slightly lower the accuracy of the AI on normal (clean) data. |
|
Defensive Distillation |
Train a secondary model to mimic the behavior of the original model, smoothing its decision-making process. |
Makes it harder for attackers to exploit weaknesses in the model. |
Requires a lot of computing power, especially for large models. |
|
Input Validation & Sanitization |
Validate that inputs are in the correct format, fall within expected ranges, and don’t contain harmful elements. |
Prevents data poisoning and ensures smooth functioning of the AI system. |
Requires careful implementation at multiple stages. |
|
Ensemble Methods |
Combine predictions from multiple models to make decisions. |
It’s harder for attackers to compromise all models simultaneously. |
Requires more computing resources to manage and maintain multiple models. |
|
Explainable AI (XAI) |
Use tools like LIME, SHAP, or attention mechanisms to explain AI decisions. |
Increases trust and makes it easier to identify and fix issues such as biases or unusual behaviors. |
Simpler, explainable models may not perform as well as complex ones. |
|
Regular Security Audits |
Perform vulnerability assessments, penetration tests, and code reviews to identify weaknesses. |
Identifies potential security gaps and ensures compliance with regulations. |
Can be resource-intensive depending on the system's complexity. |
In this section, we are looking into new trends that are keeping AI systems secure, accurate, and trustworthy.
First off, let’s talk about why protecting AI models and data is so important.
So, how can you actually keep your AI safe? Here are some key strategies:
Let’s bring this to life with a real-world scenario. Imagine a large international bank that’s developed an AI model to detect fraudulent transactions. This system handles millions of transactions daily, spotting suspicious patterns and flagging fraud.
The bank spent $50 million and three years building this system. If it gets stolen, competitors could use it without investing a cent, costing the bank its edge.
This model processes sensitive financial data from millions of customers. A breach could expose this information, leading to massive fines under laws like GDPR.
If hackers injected fake data during training, they could teach the AI to miss certain fraud patterns, leaving the bank vulnerable.
Sophisticated attackers could even pull private customer details from the model’s outputs.
How does the bank protect it?
This results in a safer, more reliable AI system that keeps customer data secure and delivers on its promise to detect fraud effectively. It’s a win for both the bank and its customers.
Imagine you’re running a high-security facility that relies on facial recognition to keep everything secure. However, we have learnt that AI systems are vulnerable to attacks, like adversarial inputs or poisoned training data. Hackers can manipulate the system to let them in.
Let’s break down the four key defenses that can stop attackers in their tracks:
The system isn’t just smart; it’s cautious. Every input has to prove it’s legit before moving on.
Securing AI is about managing data integrity, protecting proprietary models, and making sure everything plays nice with your existing cybersecurity setup. Add in the need to address evolving threats, regulatory compliance, ethics, and supply chain vulnerabilities. Here are some strategies to secure the AI lifecycle:
Here’s a real-world example. Let’s take a healthcare company developing an AI-powered diagnostic tool. Their supply chain includes:
How do they secure this pipeline?
In this way, they have a secure AI supply chain that ensures their diagnostic tool is accurate, reliable, and compliant with industry standards.
AI is powerful, but that power can be dangerous in the wrong hands. If an AI system gets hacked or is poorly designed, it can lead to biased decisions, unethical outcomes, or even misuse. That’s a big deal, especially when AI is making decisions that affect real lives—like hiring, loans, or healthcare.
So, how do we make AI systems more ethical and resilient? Let’s break it down into four key steps:
Here’s a real-world example. Let’s talk about a large tech company using an AI-powered hiring system. How do they keep it ethical?
This is a hiring system that’s ethical, fair, and transparent—even in the face of potential compromises.
AI systems are often seen as “black boxes,” meaning their decision-making process isn’t easy to understand. This can make it hard to spot issues or build trust. If you’re a doctor relying on an AI tool or a patient affected by its decision, you want answers, not question marks. The solution is explainability. Here are four strategies to make AI systems more transparent and easier to trust:
Let’s look at how a hospital builds trust in an AI dermatology diagnostic tool—a system that uses image recognition to identify potential skin conditions.
This AI tool is not only smart but explainable and trustworthy. Doctors understand its decisions, patients feel confident in their care, and the hospital makes sure the technology works fairly and accurately.
As AI becomes a bigger part of our lives, keeping it safe is more critical than ever. Why? Because the same power that drives AI’s capabilities also makes it a target for attacks. Threats like adversarial attacks, data poisoning, and model theft can seriously disrupt how AI works.
So, how do we defend AI? We have learnt that it is not a one-size-fits-all solution. Techniques like adversarial training, regular audits, and layered safeguards can reduce risks and make your systems more robust.
Then there’s generative AI. Large language models bring incredible opportunities, but they also introduce new vulnerabilities. From producing misleading content to being manipulated into giving harmful outputs, these tools require careful oversight. In the article How to Build Guardrails for Large Language Models, safety measures to ensure LLMs behave the way they should are explored.
Ethics and transparency are non-negotiable. AI systems need to be fair, explainable, and trustworthy. Biases and misuse can erode trust—and trust is everything in today’s tech-driven world. People won’t use what they don’t trust.
Finally, staying ahead is key. AI threats are constantly evolving. Businesses need to regularly update their security strategies, keeping pace with new risks to stay protected.The key is to be proactive, vigilant, and committed to ethics and transparency, and in this way, businesses can build trust and make the most of the benefits of AI.
Learn AI with these courses!
Course
Course
Course
blog
Natasha Al-Khatib
14 min
blog
Austin Chia
12 min
blog
Matt Crabtree
11 min
blog
Matt Crabtree
15 min
blog
Javier Canales Luna
7 min
blog
Kevin Babitz
8 min

