
programa
Associate AI Engineer para desarrolladores
26 h
A medida que la inteligencia artificial sigue evolucionando, uno de los retos principales ha sido descubrir cómo integrar eficazmente el conocimiento en los modelos lingüísticos grandes (LLM), teniendo en cuenta vuestro conocimiento limitado. Para superar estas limitaciones, los investigadores y profesionales han explorado diferentes enfoques para la integración del conocimiento.
Dos de los enfoques más importantes en la actualidad son la generación aumentada por recuperación (RAG) y la generación aumentada por caché (CAG). Yo he trabajado con ambos enfoques y, aunque a menudo se presentan como competidores, he descubierto que son más bien herramientas diferentes para trabajos diferentes, y que a veces incluso funcionan mejor cuando se utilizan conjuntamente.
En este artículo, te guiaré a través de una comparación entre RAG y CAG, explorando qué significa cada concepto, cómo funcionan y dónde encajan mejor en aplicaciones del mundo real. Al final, verás cómo difieren estos enfoques, en qué aspectos coinciden y cómo decidir entre ellos, o incluso combinarlos, a la hora de diseñar sistemas de IA.
Si deseas ir más allá de los conceptos y empezar a crear estos sistemas por ti mismo, te recomiendo que realices nuestro curso práctico, Generación aumentada por recuperación (RAG) con LangChain.
La generación aumentada por recuperación es una técnica de aprendizaje automático () que permite a los modelos de IA ir más allá de sus datos de entrenamiento fijos e incorporar información externa de forma dinámica. En lugar de basarse únicamente en lo que se codificó en el modelo durante el entrenamiento,
RAG conecta el modelo con bases de datos externas y mecanismos de recuperación, lo que te permite obtener documentos o conocimientos relevantes en el momento de realizar una consulta.
Esta idea ganó popularidad cuando las organizaciones se dieron cuenta de que los datos de formación estáticos quedaban obsoletos rápidamente. He visto cómo la información cambia a diario en muchos sectores, y un modelo sin una capa de recuperación externa no puede seguir el ritmo.
RAG se desarrolló para abordar esta brecha e incorporar conocimientos nuevos, específicos del dominio o dinámicos directamente en el proceso de generación.
El flujo de trabajo de RAG comienza con una consulta del usuario. La consulta se codifica primero en una representación vectorial, que luego se utiliza para buscar en una base de datos vectorial (sistema de recuperación) que contiene documentos, registros u otras fuentes de conocimiento. Esta etapa de recuperación garantiza que el modelo identifique la información externa más relevante antes de continuar.
En esta etapa, es fundamental contar con estrategias de fragmentación eficientes: los documentos se dividen en unidades de significado más pequeñas, que suelen oscilar entre 100 y 1000 tokens, de modo que el sistema de recuperación pueda mostrar el contexto más relevante sin sobrecargar el modelo de generación.
Los algoritmos de recuperación, a menudo basados en la búsqueda aproximada del vecino más cercano, garantizan que los fragmentos relevantes se recuperen rápidamente, incluso de bases de conocimiento a gran escala.
Una vez recuperados los documentos relevantes, se pasan a la fase de generación, donde el modelo lingüístico integra esta información en su respuesta. El proceso permite que el sistema genere respuestas que no solo son más coherentes, sino que también se basan en conocimientos externos y actualizados.
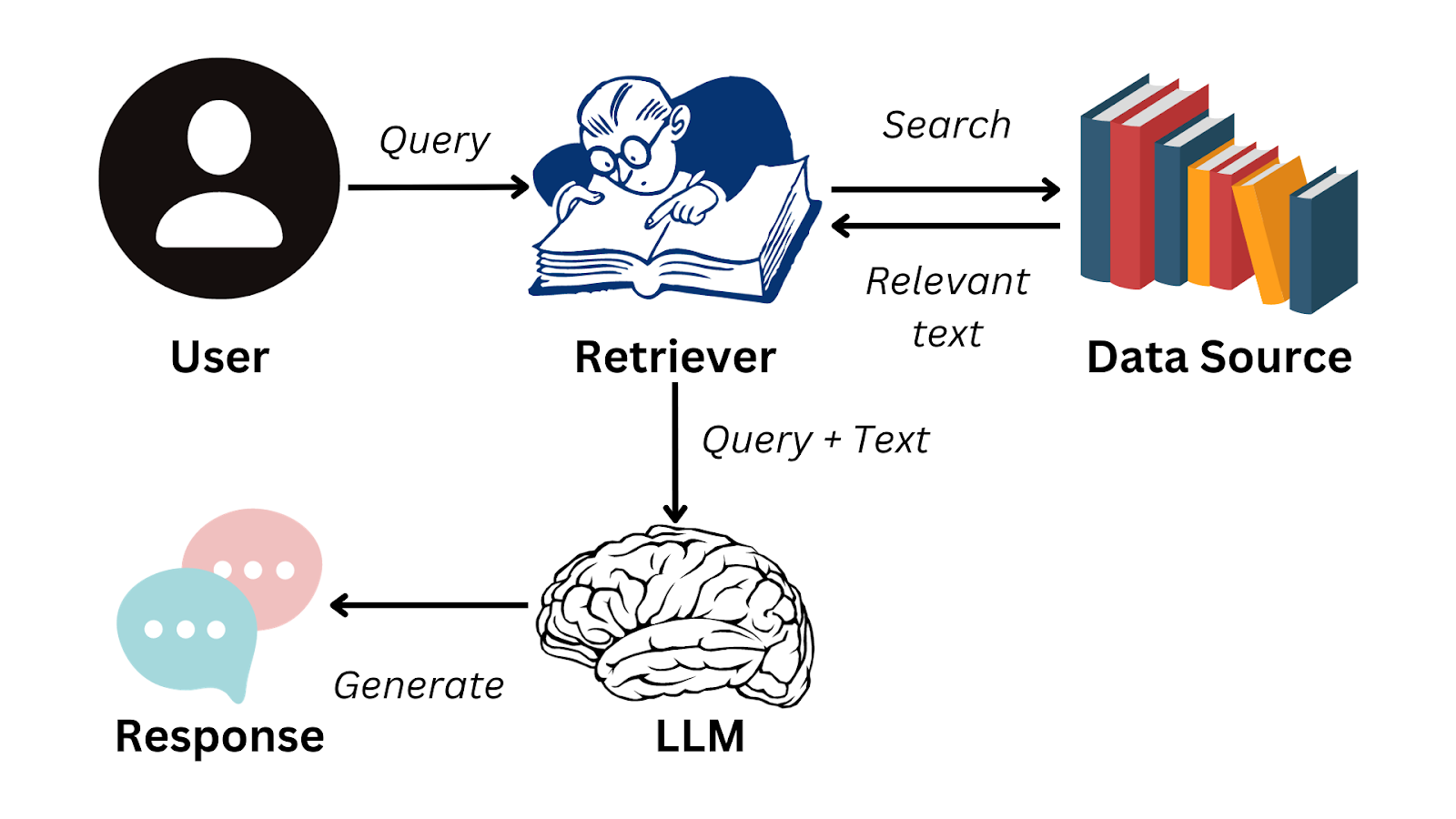
Flujo de trabajo RAG
Las fuentes de conocimiento externas pueden incluir bases de datos privadas, artículos científicos, archivos legales o incluso API en tiempo real. El motor de recuperación es el puente que permite al modelo lingüístico combinar su capacidad generativa con datos fácticos. Piensa en ello como si le dieras a tu IA una tarjeta de biblioteca en lugar de esperar que memorizara todos los libros.
Esta estructura básica se puede perfeccionar aplicando técnicas avanzadas de RAG o utilizando Corrective RAG (CRAG), unaversión mejorada de RAG optimizada para mayor precisión.
Ahora que hemos examinado cómo está estructurado y cómo funciona el RAG, resulta más fácil evaluar qué es lo que hace que este método sea especialmente eficaz en situaciones reales.
Lo que más me gusta de RAG es cómo gestionas el cambio. ¿Tu departamento jurídico actualiza una política a las 3 de la tarde? Tu sistema RAG lo sabe a las 3:01 p. m., sin necesidad de volver a formarte.
Según mi experiencia, RAG destaca en tres áreas principales:
Actualizaciones en tiempo real: La capa de recuperación se conecta con conocimientos externos y proporciona respuestas basadas en los datos más recientes. Esto hace que RAG sea especialmente valioso en campos que cambian rápidamente, como la medicina, las finanzas o la tecnología.
Menos alucinaciones: Los LLM suelen generar textos que parecen plausibles, pero que son incorrectos desde el punto de vista factual. Al basar las respuestas en documentos recuperados, RAG garantiza que el resultado tenga un fundamento factual, lo que aumenta su fiabilidad.
Integración flexible de datos: El conocimiento externo puede provenir de múltiples fuentes, como bases de datos estructuradas, API semiestructuradas o repositorios de texto no estructurados. Las organizaciones pueden adaptar los procesos de recuperación a sus necesidades específicas.
Si bien RAG ofrece ventajas convincentes, es igualmente importante comprender los desafíos y limitaciones que conlleva este enfoque.
Aquí es donde se complica la cosa, y esto es lo que advierto a mis clientes desde el principio. RAG conlleva verdaderas ventajas e inconvenientes:
Complejidad del sistema: Debes coordinar el sistema de recuperación, la base de datos vectorial y el modelo de generación. Esta complejidad crea puntos adicionales de fallo y aumenta los gastos generales de mantenimiento.
Problemas de latencia: El proceso de recuperación añade una sobrecarga computacional a cada consulta. Buscar en grandes bases de conocimiento y recuperar documentos relevantes lleva tiempo, lo que puede perjudicar la experiencia del usuario en aplicaciones en tiempo real.
Dependencia de la calidad de la recuperación: Tus respuestas son tan buenas como tu mecanismo de recuperación. Una recuperación deficiente significa que se introduce contexto irrelevante en el modelo lingüístico, lo que puede degradar la calidad de la respuesta.
Sin embargo, existen varias técnicas clave para mejorar el rendimiento de RAG y abordar estos problemas de manera eficaz.
Tras explorar el enfoque centrado en la recuperación, pasaré ahora a la generación aumentada por caché, que sigue un camino muy diferente para mejorar el rendimiento del modelo.
CAG es el nuevo chico del barrio y, sinceramente, me llevó un tiempo apreciar su elegancia. En lugar de buscar constantemente información como RAG, CAG precarga lo que necesitas y lo mantiene listo.
A diferencia del enfoque de recuperación dinámica de RAG, CAG se centra en precargar y mantener la información relevante en el contexto ampliado del modelo o en la memoria caché. El siguiente gráfico compara ambos enfoques:
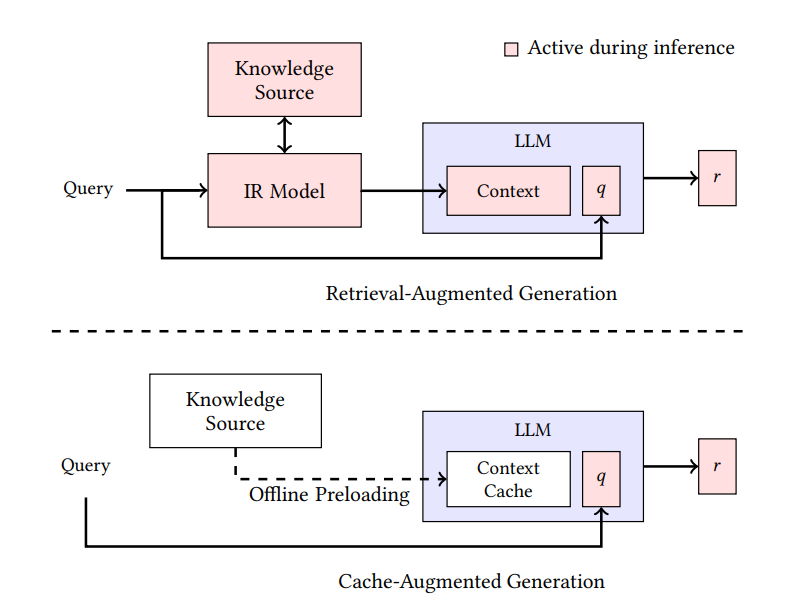
Comparación entre las arquitecturas RAG y CAG
CAG ha ganado protagonismo con el desarrollo de modelos lingüísticos que admiten ventanas contextuales cada vez más grandes, que en ocasiones se extienden hasta millones de tokens. Es como la diferencia entre buscar cada respuesta en un libro de referencia y tener una chuleta que ya has preparado.
CAG se basa en dos mecanismos de almacenamiento en caché complementarios.
En primer lugar, el almacenamiento en caché de conocimientos se produce cuando los documentos o materiales de referencia relevantes se cargan previamente en la ventana de contexto ampliada del modelo. Una vez almacenada, el modelo puede reutilizar esta información en múltiples consultas sin necesidad de obtenerla externamente, como hacen los sistemas RAG.
En segundo lugar, el almacenamiento en caché de clave-valor (KV) se centra en la eficiencia mediante el almacenamiento de los estados de atención (matrices de clave y valor) generados a medida que el modelo procesa los tokens. Cuando llega una consulta similar o repetida, el modelo puede reutilizar estos estados almacenados en caché en lugar de volver a calcularlos desde cero.
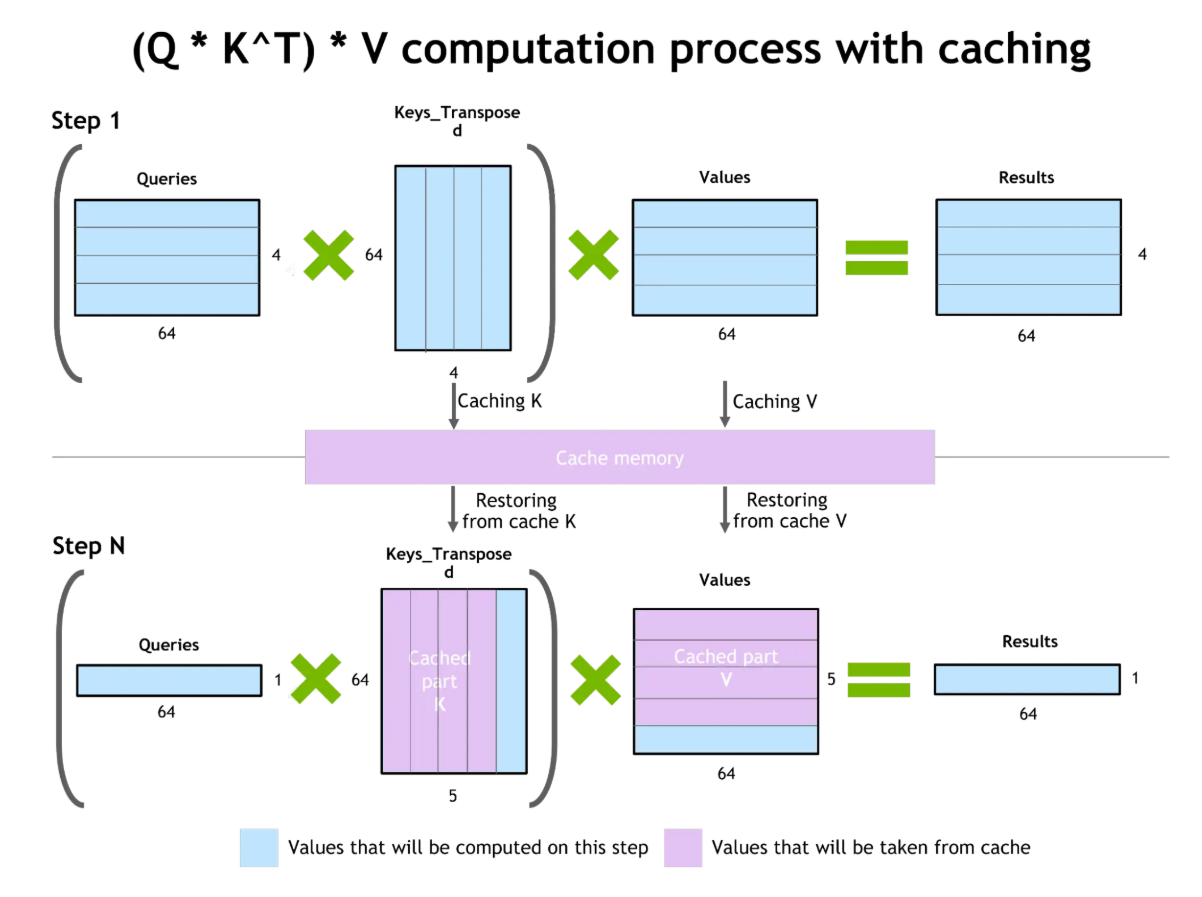
Almacenamiento en caché de clave-valor
Este mecanismo reduce la latencia y permite que el modelo mantenga un contexto a más largo plazo a lo largo de las conversaciones. El flujo de trabajo amplía la memoria efectiva del sistema, lo que te permite gestionar historiales de diálogo más extensos o consultas repetitivas sin tener que empezar desde cero cada vez.
La idea central es que el almacenamiento en caché amplía los límites prácticos de lo que un modelo puede recordar. Al conservar la información y consultarla rápidamente, CAG crea una experiencia de continuidad en conversaciones más largas.
Teniendo en cuenta este flujo de trabajo, podemos empezar a comprender por qué el CAG se ha vuelto cada vez más atractivo para determinadas aplicaciones, especialmente cuando la velocidad y la eficiencia son prioridades fundamentales.
La principal fortaleza de CAG radica en su eficiencia. Dado que el modelo reutiliza los cálculos almacenados en caché, los tiempos de respuesta mejoran significativamente, lo que reduce la latencia, especialmente en situaciones en las que las consultas son repetitivas o los requisitos de conocimiento se mantienen estables. Aquí es donde CAG realmente destaca:
Rapidez y eficiencia: La reutilización de cálculos almacenados en caché mejora drásticamente los tiempos de respuesta, especialmente en el caso de consultas repetitivas o requisitos de conocimiento estables.
Coherencia entre sesiones: Al almacenar el contexto anterior, CAG evita respuestas imprecisas y garantiza la coherencia. Esto lo hace ideal para agentes conversacionales, automatización de flujos de trabajo o chatbots de atención al cliente, donde las consultas repetidas son habituales.
Menor complejidad del sistema: Dado que el modelo no necesita realizar búsquedas externas con tanta frecuencia, el sistema en general es más sencillo en comparación con RAG.
A pesar de estas ventajas, ninguna técnica está exenta de inconvenientes, y CAG presenta una serie de retos únicos que las organizaciones deben considerar cuidadosamente.
Información obsoleta: Los datos almacenados en caché quedan obsoletos con el tiempo, por lo que es posible que estos sistemas no reflejen las actualizaciones recientes o los cambios dinámicos en las bases de conocimiento.
Requisitos de memoria elevados: El mantenimiento de cachés de gran tamaño requiere importantes recursos computacionales. Las organizaciones deben equilibrar cuidadosamente el tamaño de la caché con la memoria disponible y las capacidades de procesamiento.
Gestión compleja de la caché: Garantizar que la información almacenada en caché siga siendo precisa y esté sincronizada en todas las implementaciones distribuidas requiere mecanismos de coordinación sofisticados, y esta complejidad aumenta a medida que el sistema se amplía.
Tras examinar por separado tanto el RAG como el CAG, el siguiente paso es compararlos directamente y destacar las diferencias fundamentales que determinan su adopción en la práctica.
Entonces, ¿cuál deberías usar realmente? Me hacen esta pregunta constantemente, y mi respuesta sincera es: depende de lo que estés construyendo. Después de trabajar con ambos enfoques en diferentes proyectos, he observado algunos patrones claros de p. Permíteme desglosar lo que he aprendido de implementaciones reales.
|
Característica |
RAG (Generación aumentada por recuperación) |
CAG (Generación aumentada por caché) |
|
Mecanismo central |
Justo a tiempo: Obtiene datos relevantes de una base de datos externa durante la consulta. |
Precargado: Carga los datos relevantes en el contexto o la caché del modelo antes de la consulta. |
|
Latencia y velocidad |
Más lento: Requiere tiempo para buscar, recuperar y procesar documentos antes de generar una respuesta. |
El más rápido: Accede a la información al instante desde la memoria, eliminando la sobrecarga de recuperación. |
|
Actualidad de los conocimientos |
En tiempo real: Puede acceder a datos actualizados hace segundos (por ejemplo, noticias de última hora, nuevas leyes). |
Instantánea: El conocimiento solo está tan actualizado como la última actualización de la caché; corre el riesgo de quedar «obsoleto». |
|
Mejor caso de uso |
Conjuntos de datos dinámicos y masivos (por ejemplo, jurisprudencia, investigación médica, noticias). |
Conjuntos de datos estables y repetitivos (por ejemplo, normas de cumplimiento, preguntas frecuentes, procedimientos operativos estándar). |
|
Escalabilidad |
Horizontal: Se adapta bien a bases de datos de gran tamaño; solo está limitado por la velocidad de búsqueda. |
Limitado por la memoria: Limitado por el tamaño de la ventana de contexto del modelo y la RAM disponible. |
|
Complejidad |
Alto: Requiere la gestión de bases de datos vectoriales, la integración de procesos y la lógica de recuperación. |
Moderado: Requiere gestionar el ciclo de vida de la caché, la optimización del contexto y la eficiencia de la memoria. |
|
Cómo lidiar con las alucinaciones |
Fundamentos de las respuestas en los documentos recuperados (citas). |
Responde de forma coherente, en un contexto predefinido. |
RAG y CAG adoptan enfoques fundamentalmente diferentes en cuanto al acceso al conocimiento. RAG sigue un modelo «justo a tiempo»: codifica la consulta del usuario, busca en una base de datos vectorial, recupera los documentos relevantes y, a continuación, los pasa a la fase de generación. Este diseño garantiza el acceso a la información más reciente, pero el paso adicional de recuperación introduce latencia.
Desde el punto de vista arquitectónico, los sistemas RAG se basan en canalizaciones de múltiples etapas que combinan la fragmentación de documentos, la búsqueda vectorial y la coordinación de la recuperación. La fragmentación de documentos debe conservar el significado semántico y, al mismo tiempo, seguir siendo eficaz para la recuperación, y la búsqueda vectorial suele depender de algoritmos aproximados de vecinos más cercanos para gestionar colecciones a gran escala sin un coste elevado.
CAG, por el contrario, funciona mediante precarga. En lugar de buscar nuevos conocimientos, se basa en ventanas de contexto ampliadas y memoria caché para reutilizar información almacenada previamente. Este enfoque espacial reduce la latencia porque el modelo recupera los datos de la memoria en lugar de una base de datos externa.
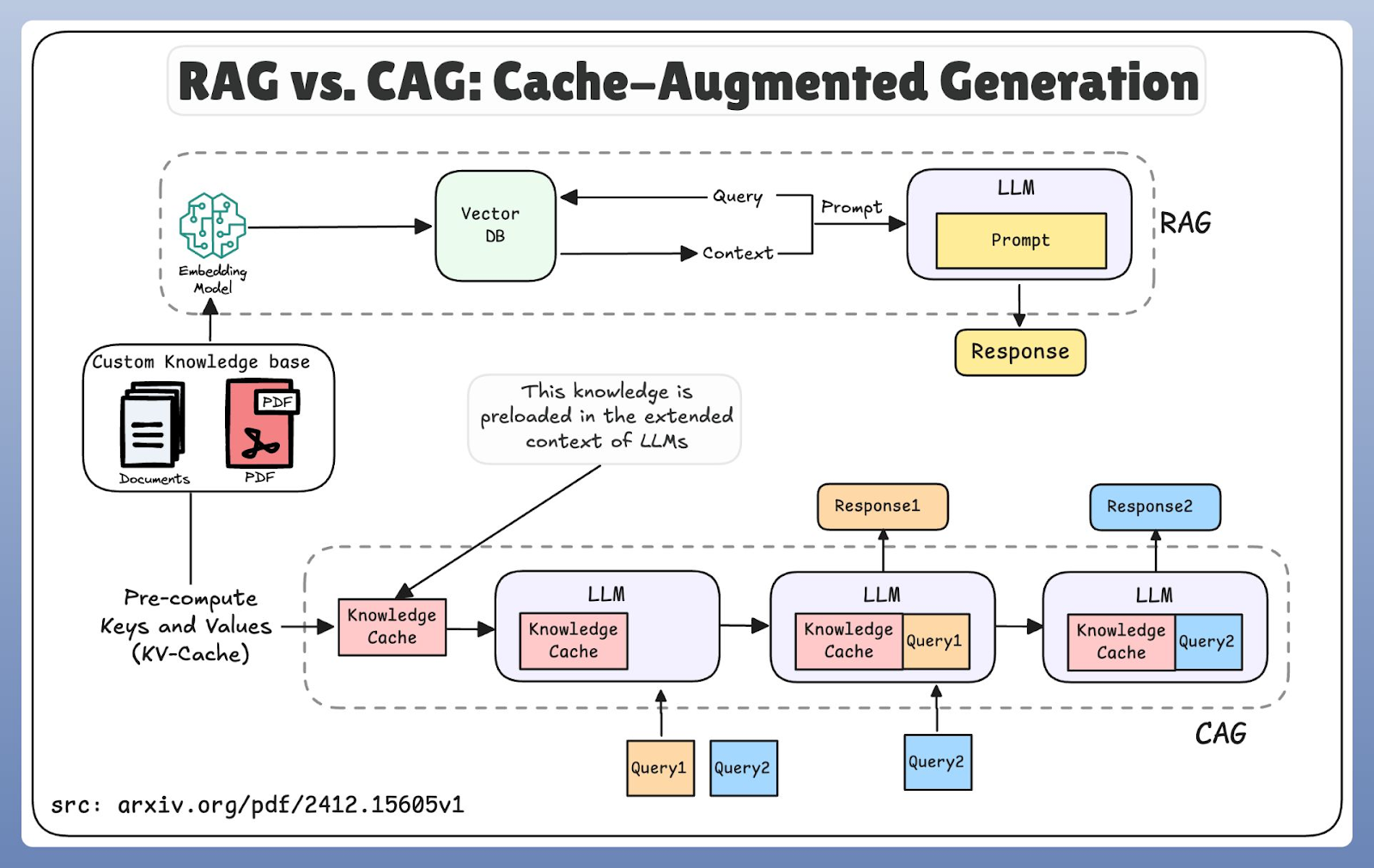
Comparación entre los flujos de trabajo RAG y CAG
Sin embargo, la contrapartida es la frescura: la información almacenada en caché puede quedarse atrás con respecto a las actualizaciones del mundo real. Por lo tanto, los sistemas CAG se centran en la gestión inteligente de la caché, utilizando estrategias para la sustitución de la caché, la asignación de memoria y la optimización de la ventana de contexto.
He visto sistemas de producción en los que esta compensación ha determinado el éxito o el fracaso de la implementación, y la eficacia de estas estrategias determina directamente tanto el rendimiento como la escalabilidad del sistema.
Más allá de la arquitectura técnica, hay una dimensión práctica que vale la pena discutir: cómo maneja cada sistema el cambio.
Esto es lo que he observado sobre la adaptabilidad:
Flexibilidad de RAG: El mecanismo de recuperación dinámica permite a estos sistemas acceder a la nueva información inmediatamente después de su indexación. He visto cómo los sistemas actualizan su base de conocimientos en tiempo real, lo que resulta perfecto para ámbitos en rápida evolución.
Rigidez del CAG: La información almacenada previamente en la caché ofrece mayor coherencia, pero menos adaptabilidad. Aunque esto proporciona velocidad y un comportamiento predecible, tiene dificultades con las consultas inesperadas que no se previeron durante la preparación de la caché.
Por lo que he visto, esta diferencia es más importante cuando tu dominio es impredecible o está en constante evolución.
Ahora hablemos de la precisión y de cómo cada enfoque aborda la tendencia de la IA a inventarse cosas.
Ambas técnicas abordan las alucinaciones de manera diferente en función de sus arquitecturas subyacentes. Los sistemas RAG mitigan las alucinaciones al basar las respuestas en información factual recuperada, lo que proporciona una validación externa del contenido generado.
Los sistemas CAG reducen las alucinaciones mediante el acceso constante a información verificada y almacenada en caché. Sin embargo, si la información almacenada en caché contiene inexactitudes o queda desactualizada, estos errores pueden persistir en múltiples interacciones.
La goma realmente entra en acción cuando piensas en la implementación de la producción a gran escala. Estas son algunas de las compensaciones de rendimiento con las que me he encontrado:
Sistemas RAG: Mayor latencia debido a la sobrecarga de recuperación, pero puedes escalar horizontalmente añadiendo capacidad de recuperación y distribuyendo bases de datos vectoriales. En la práctica, he visto que esto funciona bien una vez que se invierte en la infraestructura.
Sistemas CAG: Tiempos de respuesta superiores, pero escalabilidad limitada por la memoria. El cuello de botella suele producirse cuando la sobrecarga de la gestión de la caché crece más rápido de lo que permite tu presupuesto de memoria.
La cuestión de la escalabilidad rara vez es sencilla. Depende en gran medida de tus patrones de consulta y de los recursos disponibles.
Bueno, basta de teoría. Seamos prácticos. Después de implementar ambos enfoques en diferentes proyectos, este es mi marco de referencia para decidir cuál utilizar.
Así es como suelo guiar a los equipos en esta decisión. Las organizaciones deben evaluar la volatilidad de vuestra información, los requisitos de latencia, las necesidades de coherencia y la disponibilidad de recursos a la hora de elegir entre RAG y CAG. La alta volatilidad de la información favorece al RAG, mientras que los dominios de conocimiento estables se benefician de la eficiencia del CAG.
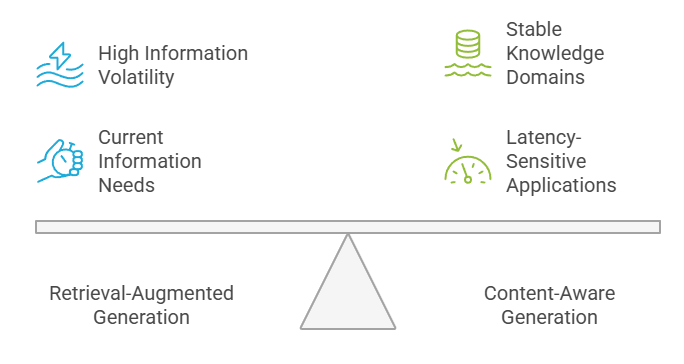
Marco de decisión: RAG contra CAG
Las aplicaciones sensibles a la latencia suelen funcionar mejor con los sistemas CAG, mientras que las aplicaciones que requieren la información más actualizada deben aprovechar las capacidades de los sistemas RAG. La decisión suele implicar equilibrar estos requisitos contrapuestos en función de las prioridades empresariales.
Elige RAG cuando necesites:
Información dinámica y actualizada con frecuencia: Aplicaciones de investigación, atención al cliente para productos en evolución o plataformas de análisis de noticias en las que estar al día es más importante que ser rápido.
Bases de conocimientos amplias y diversas: Plataformas de investigación jurídica, sistemas de información médica y aplicaciones de inteligencia competitiva. Según mi experiencia, si tus datos cambian a diario o semanalmente, RAG suele ser la opción más adecuada.
Protección contra información obsoleta: Cuando el costo de servir datos obsoletos es mayor que el costo de la latencia añadida.
Normalmente les digo a los clientes: si te preocupa que tu IA dé respuestas obsoletas, empieza con RAG. Siempre puedes optimizar la velocidad más adelante. Si optas por RAG, recuerda que para elegir el marco adecuado.
Elige CAG cuando tengas:
Requisitos de conocimientos estables: Chatbots de atención al cliente que gestionan consultas rutinarias, plataformas educativas con planes de estudios establecidos o automatización de flujos de trabajo en los que los conocimientos básicos no varían mucho.
Volúmenes elevados de consultas con patrones repetitivos: Si respondes las mismas 100 preguntas miles de veces al día, la ventaja de velocidad de CAG se acumula rápidamente.
Aplicaciones con latencia crítica: Sistemas de recomendación en tiempo real, experiencias de juego interactivas o cualquier ámbito en el que los milisegundos sean importantes para la experiencia del usuario.
Por lo que he visto, CAG es ideal cuando puedes predecir el 90 % de tus consultas y tu base de conocimientos es relativamente estable.
Déjame mostrarte cómo funciona esto en la práctica. He trabajado (y estudiado) implementaciones en diferentes sectores, y han surgido algunos patrones claros. Esto es lo que realmente funciona en producción.
Comencemos nuestro análisis del sector con la asistencia sanitaria, donde el acceso a información precisa y oportuna es especialmente importante.
En aplicaciones sanitarias, los sistemas RAG ayudan en la toma de decisiones clínicas recuperando la información más reciente sobre investigaciones médicas, protocolos de tratamiento e interacciones farmacológicas. Los profesionales médicos se benefician del acceso a las directrices clínicas actuales y a los resultados de estudios recientes que podrían no estar incluidos en los datos de formación del modelo.
Los sistemas CAG resultan muy útiles en entornos sanitarios que requieren un acceso rápido a protocolos establecidos, resúmenes del historial de los pacientes y procedimientos de diagnóstico estandarizados, donde la coherencia y la rapidez son fundamentales.
En mi opinión, la asistencia sanitaria es el ámbito en el que se aprecia más claramente la conveniencia de los enfoques híbridos: CAG para los protocolos estándar, RAG para cualquier cambio.
Las finanzas son otro caso interesante. Aquí, los requisitos son completamente diferentes a los del sector sanitario.
Las instituciones financieras utilizan los sistemas RAG para el análisis de mercados, la supervisión del cumplimiento normativo y la investigación de inversiones, ámbitos en los que es fundamental tener acceso a datos de mercado en tiempo real y a los últimos cambios normativos. Estos sistemas pueden integrarse con bases de datos financieras y fuentes de noticias para proporcionar información actualizada sobre el mercado.
Por otro lado, los sistemas CAG destacan en aplicaciones financieras que requieren respuestas rápidas a consultas rutinarias, como cálculos financieros estándar, definiciones de productos y procedimientos de cumplimiento establecidos.
Lo que he observado en el ámbito financiero es que la decisión suele depender del riesgo normativo. Si equivocarse puede suponer multas millonarias por incumplimiento normativo, los equipos se inclinan por el RAG.
La educación ofrece otro terreno fértil tanto para el RAG como para el CAG.
Las plataformas de aprendizaje personalizadas suelen beneficiarse del RAG, ya que los estudiantes necesitan acceder a contenidos diversos y constantemente actualizados, como nuevos artículos de investigación, materiales del curso o incluso acontecimientos de actualidad que se utilizan como ejemplos de aprendizaje. Con RAG, un tutor de IA puede proporcionar referencias precisas o lecturas complementarias que no formaban parte de tu conjunto de entrenamiento original.
Por el contrario, CAG funciona bien en situaciones en las que la repetición y la coherencia son fundamentales. Por ejemplo, cuando una plataforma ofrece cuestionarios periódicos, explicaciones de conceptos estándar o sesiones de práctica estructuradas, el almacenamiento en caché garantiza una entrega más rápida y consistente de los comentarios.
De esta manera, los sistemas educativos suelen combinar ambas técnicas, aunando nuevas perspectivas con un refuerzo fiable de los conocimientos básicos.
En el mundo del software, los programadores están adoptando cada vez más ambos métodos para mejorar la productividad.
RAG ayuda a los programadores recuperando documentación, especificaciones de API o pasos para la resolución de problemas de fuentes externas. Dado que las bibliotecas o los marcos de software pueden cambiar rápidamente, la capa de recuperación de RAG destaca por garantizar que las respuestas se mantengan actualizadas.
Por su parte, CAG desempeña un papel importante en tareas que dependen en gran medida de interacciones repetidas, como la autocompletación de código, la asistencia en la depuración o la respuesta a consultas recurrentes de los programadores. Al almacenar en caché los patrones vistos anteriormente, CAG reduce la latencia y acelera el flujo de trabajo de desarrollo.
En conjunto, estos enfoques permiten a los ingenieros avanzar más rápidamente al tiempo que se basan en una orientación precisa y consciente del contexto.
El sector jurídico presenta otro caso práctico fascinante sobre cómo estos enfoques abordan los retos específicos del ámbito con diferentes patrones de acceso a la información.
Los profesionales del ámbito jurídico utilizan los sistemas RAG para la investigación de jurisprudencia y la revisión de contratos, donde es esencial el acceso a los documentos contractuales y los precedentes legales más recientes. Les permite garantizar que su asesoramiento jurídico refleje las últimas sentencias judiciales y cambios normativos tan pronto como se publican.
Por el contrario, CAG es la mejor opción para la supervisión interna del cumplimiento y la aplicación automatizada de políticas, especialmente cuando las reglas son fijas y las consultas son repetitivas. En lugar de recuperar las mismas «Directrices contra el soborno» o el «Artículo 15 del RGPD» miles de veces al día, un sistema CAG precarga estos marcos normativos estáticos directamente en el contexto del modelo.
Dado que la «verdad» fundamental (la ley) rara vez cambia de un día para otro, el almacenamiento en caché de este conocimiento elimina el cuello de botella de recuperación para el 90 % de las consultas que son comprobaciones de cumplimiento estándar.
En el comercio minorista y el comercio electrónico, la velocidad y la relevancia influyen directamente en la experiencia del cliente.
RAG se utiliza a menudo para potenciar la búsqueda avanzada de productos, integrar datos de inventario en tiempo real y ofrecer recomendaciones dinámicas. Por ejemplo, si un cliente pregunta si un producto está en stock, un sistema habilitado para RAG puede consultar bases de datos en tiempo real para proporcionar una respuesta actualizada.
Por otro lado, CAG garantiza respuestas rápidas a las preguntas más habituales de los clientes, como las políticas de envío, las normas de devolución o las actualizaciones del estado de los pedidos. Al reutilizar las interacciones almacenadas en caché, el sistema ofrece respuestas instantáneas y reduce la carga del servidor.
Cuando se usan juntos, RAG y CAG crean una experiencia perfecta que ofrece precisión y eficiencia.
Hasta ahora, hemos tratado RAG y CAG como técnicas independientes. Sin embargo, en la práctica, muchas organizaciones están empezando a adoptar enfoques híbridos que integran ambos métodos. Esta combinación les permite equilibrar la frescura y adaptabilidad de RAG con la velocidad y eficiencia de CAG.
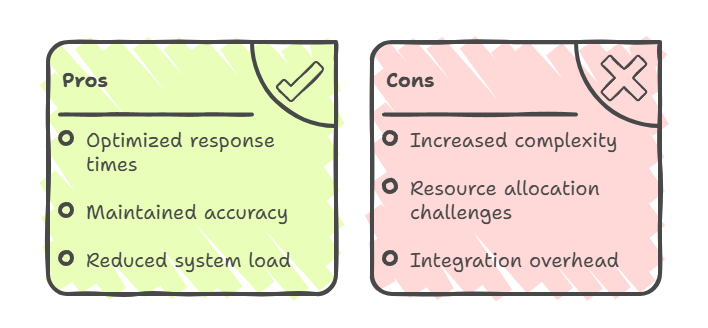
Enfoques híbridos: Ventajas y desventajas
Los sistemas híbridos representan la próxima evolución en la integración del conocimiento, ya que combinan las capacidades de recuperación dinámica de RAG con las ventajas de eficiencia de CAG.
En estos modelos híbridos, el CAG se utiliza normalmente para información estable y de acceso frecuente, mientras que el RAG se emplea para consultas que requieren datos en tiempo real o conocimientos especializados. Esto da como resultado «lo mejor de ambos mundos»: tiempos de respuesta optimizados para consultas comunes, precisión mantenida para contenido dinámico y reducción de la carga general del sistema mediante un enrutamiento inteligente.
Sin embargo, los enfoques híbridos introducen una mayor complejidad arquitectónica. Requieren una sofisticada coordinación entre los sistemas de almacenamiento en caché y recuperación, y exigen un cuidadoso equilibrio en la asignación de recursos.
La sobrecarga de integración incluye la gestión de vías de conocimiento duales, el mantenimiento de la sincronización entre los datos almacenados en caché y los recuperados, y la implementación de una lógica de enrutamiento inteligente que determina qué método utilizar para cada consulta.
Si quieres optar por una solución híbrida, es imprescindible que sepas lo que estás haciendo.
Según mi experiencia, la adopción más extendida de las arquitecturas híbridas se encuentra actualmente en los ecosistemas de servicio al cliente. A menudo veo plataformas en las que CAG gestiona las preguntas frecuentes estáticas y de gran volumen para su recuperación instantánea, mientras que RAG se utiliza de forma selectiva para obtener detalles de cuentas en tiempo real o historiales de transacciones.
Otro ejemplo clásico se encuentra en las aplicaciones de investigación, donde CAG mantiene almacenado el conocimiento fundamental, mientras que RAG recupera las últimas publicaciones o datos dinámicos para nuevas consultas. Del mismo modo, en las plataformas de comercio electrónico, CAG gestiona las descripciones de productos o las políticas almacenadas en caché, mientras que RAG integra los niveles de inventario en tiempo real y las actualizaciones de precios.
Mira, no hay una respuesta correcta universal aquí, y cualquiera que te diga lo contrario probablemente esté tratando de venderte algo. La elección entre RAG y CAG, o la decisión de combinarlos, depende en última instancia de tus requisitos, limitaciones y objetivos específicos.
RAG destaca cuando necesitas acceder a información dinámica y actualizada, y puedes tolerar cierta latencia a cambio de precisión y actualidad. CAG destaca en situaciones en las que la velocidad y la coherencia son fundamentales, y tus requisitos de conocimientos se mantienen relativamente estables.
En el futuro, es probable que veamos aparecer enfoques híbridos más sofisticados que dirijan de forma inteligente las consultas entre la información almacenada en caché y la recuperada, optimizando tanto el rendimiento como la precisión.
Para dominar todas las habilidades necesarias para diseñar e implementar sistemas RAG, CAG o híbridos,considera la posibilidad de inscribirte en nuestro completo programa de ingeniero de IA.
Cursos de IA generativa
programa
programa
Curso
blog
Javier Canales Luna
14 min
blog
Natasha Al-Khatib
14 min
blog
Arun Nanda
15 min
blog
Austin Chia
Tutorial
Ryan Ong
Tutorial
Ryan Ong
