
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Während sich die künstliche Intelligenz weiterentwickelt, ist es eine der größten Herausforderungen, herauszufinden, wie man Wissen effektiv in große Sprachmodelle (LLMs) einbaut, vor allem weil deren Wissen begrenzt ist. Um diese Probleme zu lösen, haben Forscher und Praktiker verschiedene Wege zur Wissensintegration ausprobiert.
Zwei der wichtigsten Ansätze sind heute die abrufgestützte Generierung (RAG) und die cachegestützte Generierung (CAG). Ich habe mit beiden Methoden gearbeitet, und obwohl sie oft als Konkurrenten dargestellt werden, finde ich, dass sie eher wie verschiedene Werkzeuge für unterschiedliche Aufgaben sind – manchmal sogar besser, wenn man sie zusammen einsetzt.
In diesem Artikel zeige ich dir, wie RAG und CAG sich unterscheiden, was die einzelnen Konzepte bedeuten, wie sie funktionieren und wo sie in der Praxis am besten eingesetzt werden können. Am Ende wirst du sehen, wie sich diese Ansätze unterscheiden, wo sie sich überschneiden und wie du dich bei der Entwicklung von KI-Systemen zwischen ihnen entscheiden oder sie sogar kombinieren kannst.
Wenn du über die Konzepte hinausgehen und diese Systeme selbst entwickeln möchtest, empfehle ich dir unseren praktischen Kurs „Retrieval Augmented Generation (RAG) mit LangChain”.
Retrieval-Augmented Generation ist eine Technik namens „Te“, die es KI-Modellen ermöglicht, über ihre festen Trainingsdaten hinauszugehen und externe Infos dynamisch einzubeziehen. Anstatt sich nur auf das zu verlassen, was während des Trainings in das Modell eingebaut wurde,
RAG verbindet das Modell mit externen Datenbanken und Suchmechanismen, sodass es bei einer Anfrage relevante Dokumente oder Infos abrufen kann.
Diese Idee wurde immer beliebter, als Unternehmen merkten, dass statische Trainingsdaten schnell veralten. Ich hab gesehen, wie sich Infos in vielen Branchen täglich ändern, und ein Modell ohne externe Abfrageschicht kann da nicht mithalten.
RAG wurde entwickelt, um diese Lücke zu schließen und neues, domänenspezifisches oder dynamisches Wissen direkt in den Generierungsprozess einzubringen.
Der RAG-Workflow fängt mit einer Anfrage vom Benutzer an. Die Abfrage wird erst mal in eine Vektordarstellung umgewandelt, die dann benutzt wird, um eine Vektordatenbank (Abfragesystem) zu durchsuchen, die Dokumente, Datensätze oder andere Wissensquellen enthält. Diese Abrufphase stellt sicher, dass das Modell die relevantesten externen Informationen identifiziert, bevor es fortfährt.
Effiziente Chunking-Strategien sind in dieser Phase super wichtig: Dokumente werden in kleinere Bedeutungseinheiten aufgeteilt, die normalerweise zwischen 100 und 1.000 Token umfassen, damit das Abrufsystem den relevantesten Kontext anzeigen kann, ohne das Generierungsmodell zu überfordern.
Suchalgorithmen, die oft auf der Suche nach ungefähren nächsten Nachbarn basieren, sorgen dafür, dass relevante Teile schnell gefunden werden, selbst in riesigen Wissensdatenbanken.
Sobald die relevanten Dokumente gefunden sind, werden sie an die Generierungsphase weitergeleitet, wo das Sprachmodell diese Infos in seine Antwort einbaut. Der Prozess ermöglicht es dem System, Antworten zu generieren, die nicht nur kohärenter sind, sondern auch auf externem, aktuellem Wissen basieren.
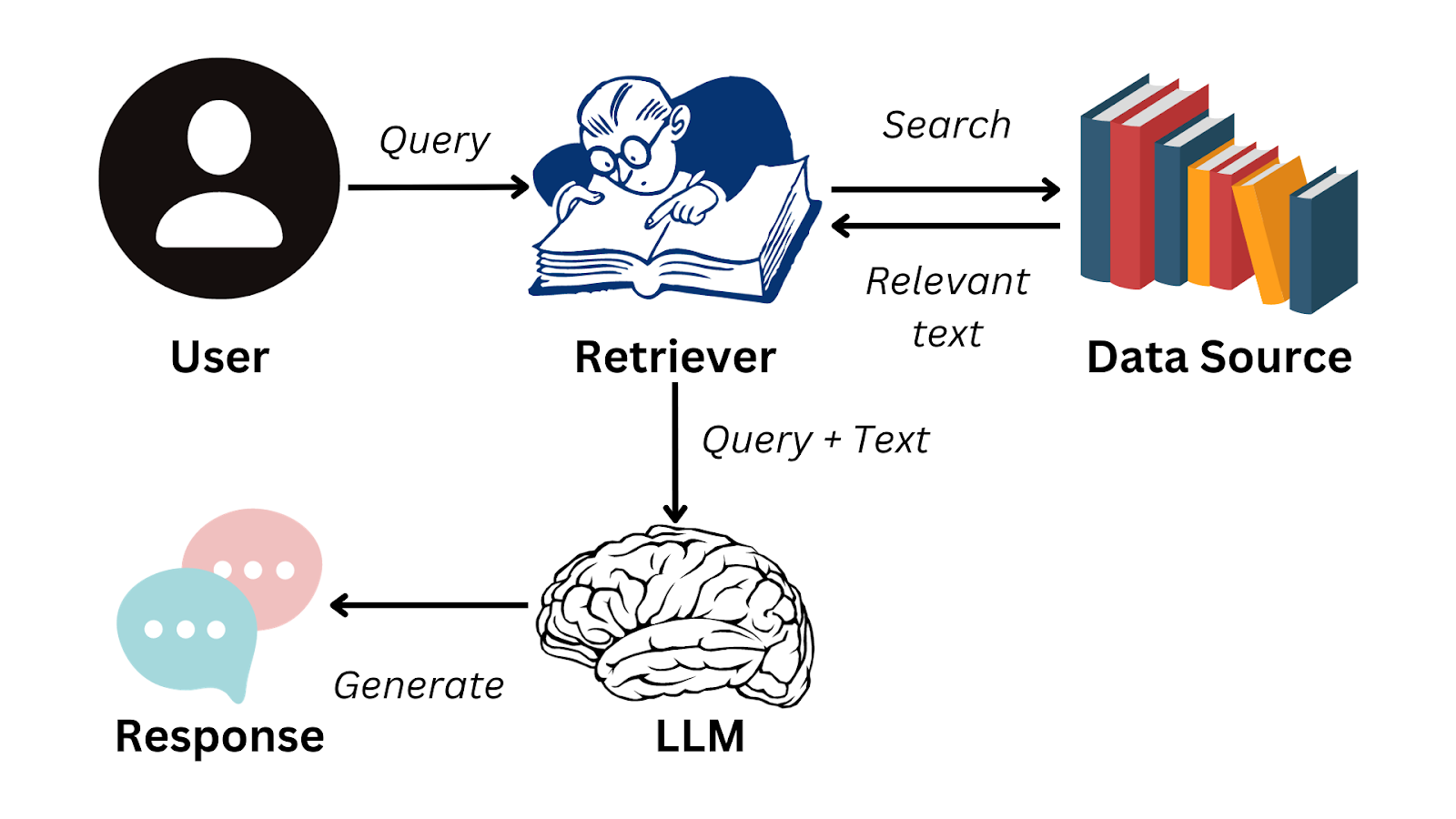
RAG-Arbeitsablauf
Zu den externen Wissensquellen können proprietäre Datenbanken, wissenschaftliche Arbeiten, Rechtsarchive oder sogar Echtzeit-APIs gehören. Die Suchmaschine ist die Brücke, die es dem Sprachmodell ermöglicht, seine generativen Fähigkeiten mit Fakten zu verbinden. Stell dir das so vor, als würdest du deiner KI einen Bibliotheksausweis geben, anstatt zu hoffen, dass sie sich jedes Buch merkt.
Diese Grundstruktur kann durch die Anwendung fortgeschrittener RAG-Techniken oder durch den Einsatz von Corrective RAG (CRAG)verbessert werden, eineroptimierten Version von RAG, die auf Genauigkeit ausgelegt ist.
Nachdem wir uns angesehen haben, wie RAG aufgebaut ist und funktioniert, können wir jetzt besser einschätzen, warum diese Methode in der Praxis so gut funktioniert.
Was ich an RAG am meisten mag, ist, wie es mit Veränderungen umgeht. Deine Rechtsabteilung ändert eine Richtlinie um 15 Uhr? Dein RAG-System weiß das schon um 15:01 Uhr – du musst nichts nachlernen.
Meiner Erfahrung nach ist RAG in drei Hauptbereichen echt gut:
Echtzeit-Updates: Die Abruflage verbindet sich mit externem Wissen und liefert Antworten auf Basis der neuesten Daten. Das macht RAG besonders nützlich in Bereichen, die sich schnell ändern, wie Medizin, Finanzen oder Technologie.
Weniger Halluzinationen: LLMs machen oft Texte, die zwar plausibel klingen, aber eigentlich falsch sind. Indem die Antworten auf gefundenen Dokumenten basieren, sorgt RAG dafür, dass die Ergebnisse auf Fakten beruhen, was die Zuverlässigkeit erhöht.
Flexible Datenintegration: Externes Wissen kann aus verschiedenen Quellen kommen, wie zum Beispiel strukturierten Datenbanken, halbstrukturierten APIs oder unstrukturierten Textarchiven. Unternehmen können Abruf-Pipelines an ihre speziellen Bedürfnisse anpassen.
RAG hat zwar echt coole Vorteile, aber es ist genauso wichtig, die Herausforderungen und Einschränkungen zu verstehen, die mit diesem Ansatz einhergehen.
Hier wird's knifflig, und davor warne ich meine Kunden schon im Voraus. RAG hat echt Nachteile:
Komplexität des Systems: Du musst das Abrufsystem, die Vektordatenbank und das Generierungsmodell zusammenführen. Diese Komplexität führt zu zusätzlichen Fehlerquellen und erhöht den Wartungsaufwand.
Latenzprobleme: Der Abrufprozess macht jede Anfrage rechenintensiver. Das Durchsuchen großer Wissensdatenbanken und das Finden relevanter Dokumente dauert seine Zeit, was die Benutzerfreundlichkeit in Echtzeitanwendungen beeinträchtigen kann.
Abhängigkeit der Suchqualität: Deine Antworten sind nur so gut wie dein Abrufmechanismus. Schlechte Abfrage bedeutet, dass irrelevante Infos ins Sprachmodell eingespeist werden, was die Antwortqualität beeinträchtigen kann.
Es gibt aber ein paar wichtige Techniken, um die Leistung von RAG zu verbessern und diese Probleme gut in den Griff zu kriegen.
Nachdem ich den auf das Abrufen fokussierten Ansatz angeschaut habe, werde ich mich jetzt mit der cache-erweiterten Generierung beschäftigen, die einen ganz anderen Weg geht, um die Modellleistung zu verbessern.
CAG ist der Neue hier, und ehrlich gesagt, hat es eine Weile gedauert, bis ich seine Eleganz zu schätzen wusste. Anstatt ständig Infos wie RAG abzurufen, lädt CAG alles, was du brauchst, vorab und hält es bereit.
Im Gegensatz zum dynamischen Abrufansatz von RAG konzentriert sich CAG darauf, relevante Infos im erweiterten Kontext oder Cache-Speicher des Modells vorab zu laden und zu speichern. Die folgende Grafik zeigt, wie die beiden Ansätze sich unterscheiden:
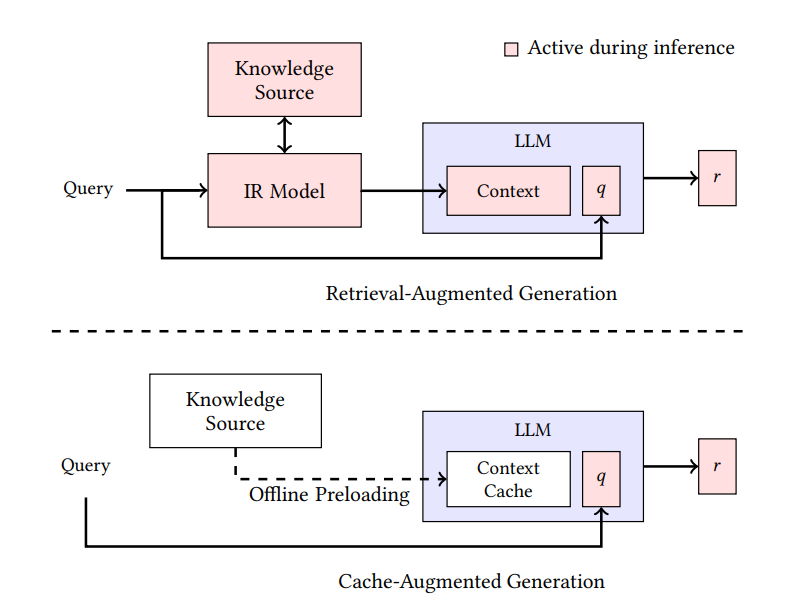
RAG- und CAG-Architekturen im Vergleich
CAG ist bekannt geworden, weil es Sprachmodelle entwickelt hat, die immer größere Kontextfenster unterstützen, manchmal bis zu Millionen von Tokens. Es ist wie der Unterschied zwischen dem Nachschlagen jeder Antwort in einem Nachschlagewerk und dem Benutzen eines Spickzettels, den du schon vorbereitet hast.
CAG nutzt zwei Caching-Mechanismen, die sich gegenseitig ergänzen.
Erstens passiertdas Caching von Wissen , wenn wichtige Dokumente oder Referenzmaterialien schon mal ins erweiterte Kontextfenster des Modells geladen werden. Sobald die Infos gespeichert sind, kann das Modell sie für mehrere Abfragen wiederverwenden, ohne sie wie bei RAG-Systemen von außen holen zu müssen.
Zweitens konzentriert sich das Key-Value-Caching- , auf Effizienz, indem es die Aufmerksamkeitszustände (Key- und Value-Matrizen) speichert, die bei der Verarbeitung von Tokens durch das Modell entstehen. Wenn eine ähnliche oder wiederholte Anfrage reinkommt, kann das Modell diese zwischengespeicherten Zustände wiederverwenden, anstatt sie neu zu berechnen.
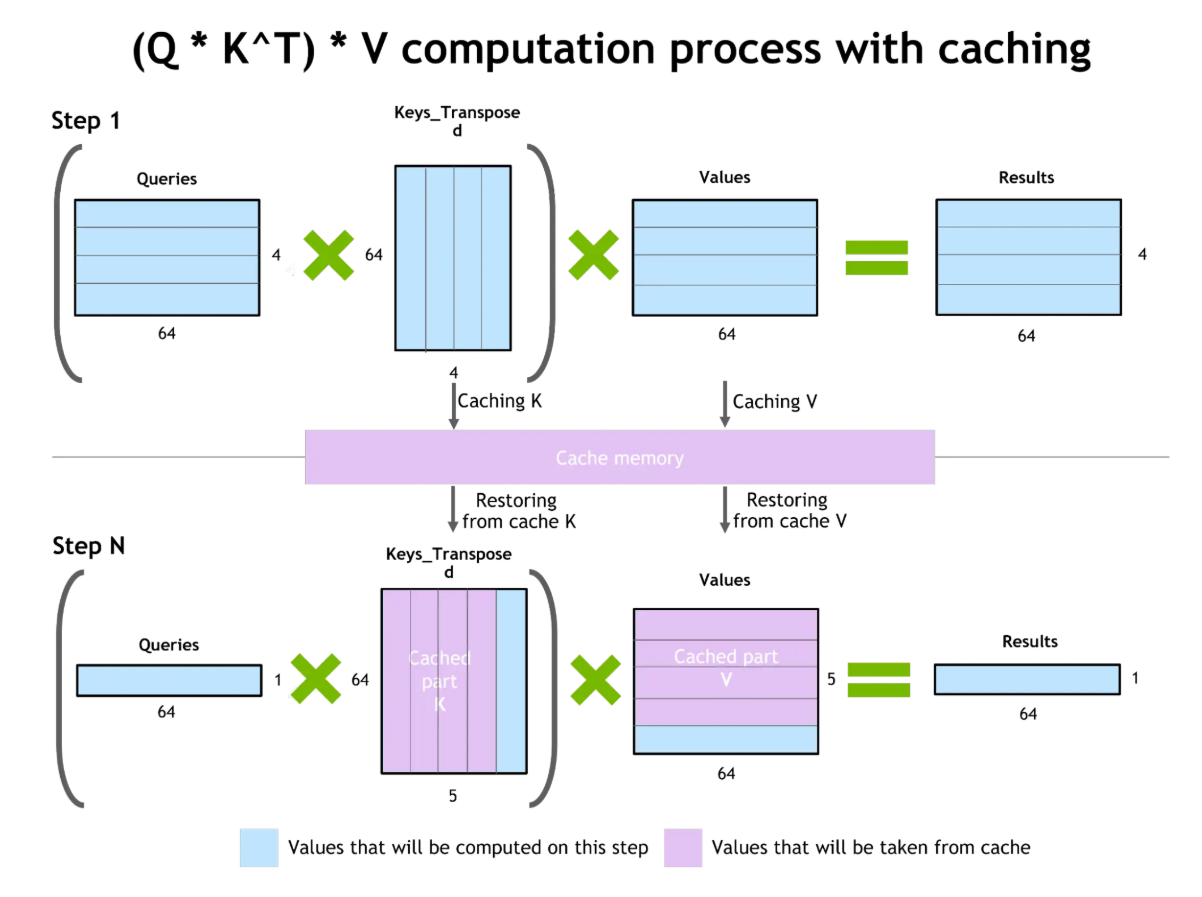
Dieser Mechanismus reduziert die Latenz und ermöglicht es dem Modell, den Kontext über mehrere Unterhaltungen hinweg länger zu behalten. Der Workflow erweitert den effektiven Speicher des Systems, sodass es umfangreichere Dialogverläufe oder sich wiederholende Abfragen verarbeiten kann, ohne jedes Mal von vorne anfangen zu müssen.
Die Grundidee ist, dass Caching die praktischen Grenzen dessen erweitert, was ein Modell sich merken kann. Durch das Speichern von Infos und schnelles Nachschlagen schafft CAG ein Gefühl von Kontinuität bei längeren Unterhaltungen.
Mit diesem Arbeitsablauf im Hinterkopf wird klar, warum CAG für bestimmte Anwendungen immer attraktiver wird, vor allem wenn es auf Geschwindigkeit und Effizienz ankommt.
Die größte Stärke von CAG ist, wie effizient es ist. Weil das Modell zwischengespeicherte Berechnungen wiederverwendet, werden die Antwortzeiten deutlich besser, was die Latenz reduziert, vor allem in Fällen, wo Abfragen oft wiederholt werden oder die Wissensanforderungen gleich bleiben. Hier zeigt CAG seine wahre Stärke:
Schnelligkeit und Effizienz: Die Wiederverwendung zwischengespeicherter Berechnungen verbessert die Antwortzeiten echt, vor allem bei sich wiederholenden Abfragen oder stabilen Wissensanforderungen.
Konsistenz über alle Sitzungen hinweg: Durch das Speichern von vorherigem Kontext vermeidet CAG unpassende Antworten und sorgt für Kohärenz. Das macht es super für Chatbots, die sich mit Gesprächen beschäftigen, für die Automatisierung von Arbeitsabläufen oder für Chatbots im Kundensupport, wo oft die gleichen Fragen auftauchen.
Weniger kompliziertes System: Da das Modell nicht so oft externe Abfragen machen muss, ist das ganze System im Vergleich zu RAG einfacher.
Trotz dieser Vorteile hat jede Technik ihre Vor- und Nachteile, und CAG bringt seine eigenen Herausforderungen mit sich, die Unternehmen sorgfältig abwägen müssen.
Veraltete Infos: Zwischengespeicherte Daten werden mit der Zeit veraltet, sodass diese Systeme möglicherweise nicht die neuesten Aktualisierungen oder dynamischen Änderungen in Wissensdatenbanken widerspiegeln.
Hohe Speicheranforderungen: Große Caches zu verwalten braucht echt viele Rechenressourcen. Unternehmen müssen die Cache-Größe sorgfältig gegen den verfügbaren Speicher und die Verarbeitungskapazitäten abwägen.
Komplexes Cache-Management: Damit die zwischengespeicherten Infos in verteilten Umgebungen immer richtig und synchron sind, braucht man echt ausgeklügelte Koordinationsmechanismen – und das wird mit der Größe des Systems immer komplizierter.
Nachdem wir uns RAG und CAG einzeln angeschaut haben, geht's jetzt darum, sie direkt zu vergleichen und die wichtigen Unterschiede zu zeigen, die ihre Anwendung in der Praxis beeinflussen.
Also, welches solltest du eigentlich benutzen? Diese Frage wird mir ständig gestellt, und meine ehrliche Antwort lautet: Es kommt drauf an, was du baust. Nachdem ich beide Ansätze in verschiedenen Projekten ausprobiert habe, sind mir ein paar klare Muster in der Per Arbeit aufgefallen. Ich erzähl dir mal, was ich aus echten Implementierungen gelernt habe.
|
Feature |
RAG (Retrieval-Augmented Generation) |
CAG (Cache-Augmented Generation) |
|
Kernmechanismus |
Just-in-Time: Holt während der Abfrage relevante Daten aus einer externen Datenbank. |
Vorinstalliert: Lädt vor der Abfrage relevante Daten in den Kontext oder Cache des Modells. |
|
Latenz & Geschwindigkeit |
Langsamer: Man braucht Zeit, um Dokumente zu suchen, abzurufen und zu bearbeiten, bevor man eine Antwort geben kann. |
Am schnellsten: Greift sofort auf Infos aus dem Speicher zu, ohne dass man sie erst suchen muss. |
|
Aktualität des Wissens |
Echtzeit: Kann auf Daten zugreifen, die vor Sekunden aktualisiert wurden (z. B. aktuelle Nachrichten, neue Gesetze). |
Snapshot: Das Wissen ist nur so aktuell wie das letzte Cache-Update; es besteht die Gefahr, dass es „veraltet” ist. |
|
Bester Anwendungsfall |
Dynamische, riesige Datensätze (z. B. Rechtsprechung, medizinische Forschung, Nachrichten). |
Stabile, sich wiederholende Datensätze (z. B. Compliance-Regeln, FAQs, Standardarbeitsanweisungen). |
|
Skalierbarkeit |
Horizontal: Skaliert gut mit riesigen Datenbanken; nur durch die Suchgeschwindigkeit eingeschränkt. |
Speichergebunden: Eingeschränkt durch die Größe des Kontextfensters des Modells und den verfügbaren Arbeitsspeicher. |
|
Komplexität |
Hoch: Man muss Vektordatenbanken verwalten, Pipelines einbetten und Abruf-Logik einrichten. |
Mäßig: Man muss den Cache-Lebenszyklus verwalten, den Kontext optimieren und auf Speichereffizienz achten. |
|
Umgang mit Halluzinationen |
Begründungen in den gefundenen Dokumenten (Zitate). |
Begründet Antworten in einem einheitlichen, vorab festgelegten Kontext. |
RAG und CAG haben echt unterschiedliche Ansätze, wie man an Wissen ran kommt. RAG arbeitet nach einem Just-in-Time-Modell: Es verschlüsselt die Anfrage des Benutzers, durchsucht eine Vektordatenbank, findet relevante Dokumente und schickt sie dann zur Generierungsphase weiter. Dieses Design sorgt dafür, dass man immer die aktuellsten Infos bekommt, aber der zusätzliche Schritt beim Abrufen führt zu einer Verzögerung.
Architektonisch basieren RAG-Systeme auf mehrstufigen Pipelines, die Dokument-Chunking, Vektorsuche und Abrufkoordination kombinieren. Beim Chunking von Dokumenten muss die Bedeutung erhalten bleiben, während das Abrufen effizient bleibt. Die Vektorsuche nutzt oft Algorithmen für ungefähre nächste Nachbarn, um große Sammlungen ohne hohe Kosten zu verarbeiten.
CAG hingegen funktioniert mit Vorladung. Anstatt nach neuen Infos zu suchen, nutzt es erweiterte Kontextfenster und Cache-Speicher, um schon gespeicherte Infos wiederzuverwenden. Dieser räumliche Ansatz reduziert die Latenz, weil das Modell die Daten aus dem Speicher statt aus einer externen Datenbank holt.
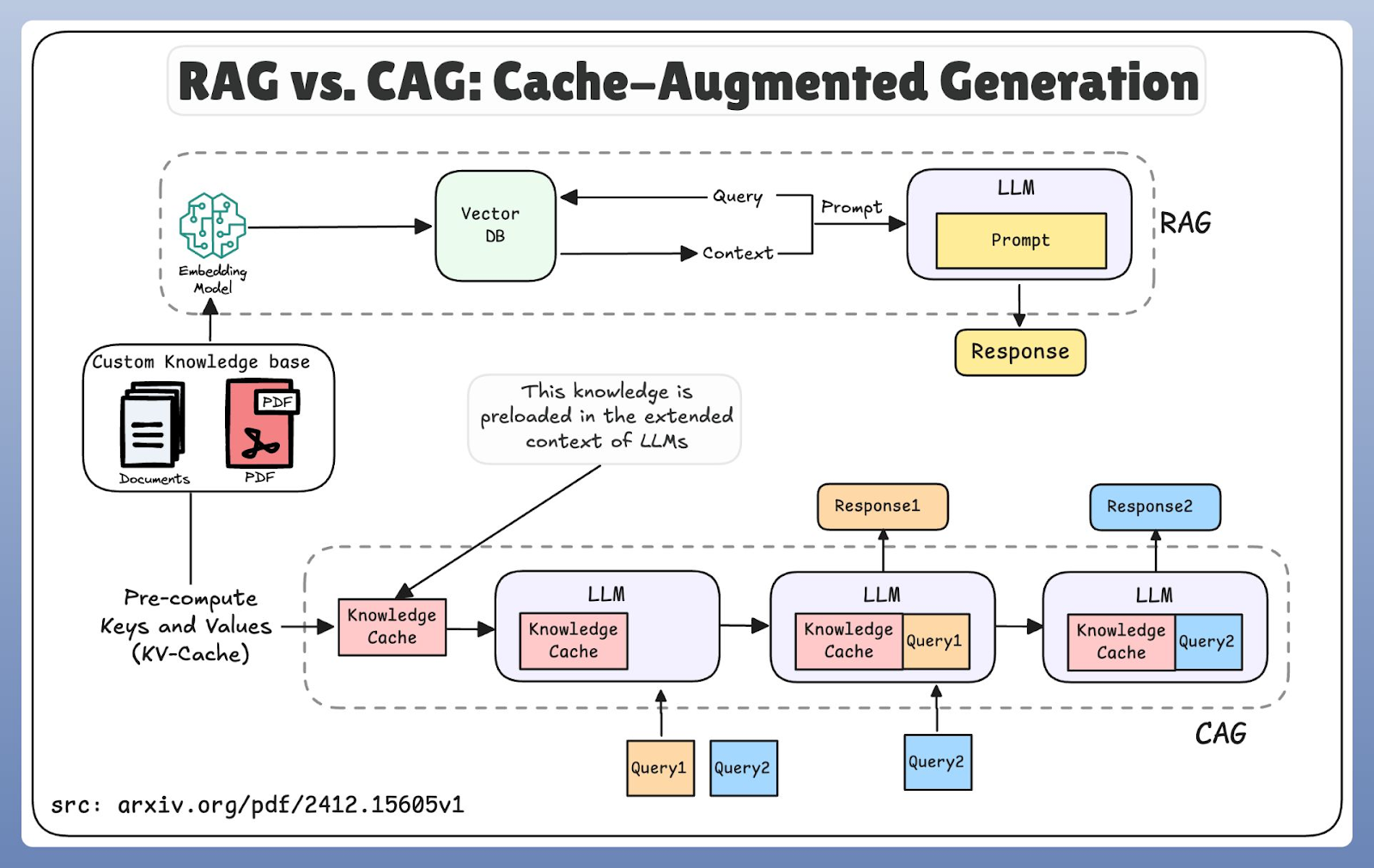
Vergleich zwischen RAG- und CAG-Workflow
Der Nachteil ist aber, dass die Infos nicht immer aktuell sind: Die gespeicherten Infos können hinter den echten Updates zurückbleiben. Deshalb konzentrieren sich CAG-Systeme auf intelligentes Cache-Management und nutzen Strategien für Cache-Ersetzung, Speicherzuweisung und Kontextfensteroptimierung.
Ich habe Produktionssysteme gesehen, bei denen dieser Kompromiss über Erfolg oder Misserfolg der Implementierung entschieden hat, und die Wirksamkeit dieser Strategien bestimmt direkt sowohl die Leistung als auch die Skalierbarkeit des Systems.
Abgesehen von der technischen Architektur gibt es noch einen praktischen Aspekt, über den man reden sollte: Wie geht jedes System mit Änderungen um?
Hier ist, was ich über Anpassungsfähigkeit gemerkt habe:
Die Flexibilität von RAG: Der dynamische Abrufmechanismus lässt diese Systeme sofort nach der Indizierung auf neue Infos zugreifen. Ich hab gesehen, wie Systeme ihre Wissensdatenbank in Echtzeit aktualisieren, was für sich schnell entwickelnde Bereiche super ist.
Die Starrheit von CAG: Vorab zwischengespeicherte Infos bedeuten mehr Konsistenz, aber weniger Flexibilität. Das sorgt zwar für Schnelligkeit und vorhersehbares Verhalten, aber es gibt Probleme mit unerwarteten Abfragen, die bei der Cache-Vorbereitung nicht bedacht wurden.
Meiner Erfahrung nach ist dieser Unterschied vor allem dann wichtig, wenn deine Domain unvorhersehbar ist oder sich ständig weiterentwickelt.
Jetzt reden wir mal über Genauigkeit und wie jeder Ansatz mit der Tendenz der KI umgeht, sich Sachen auszudenken.
Beide Techniken gehen je nach ihrer zugrunde liegenden Architektur unterschiedlich mit Halluzinationen um. RAG-Systeme reduzieren Halluzinationen, indem sie Antworten auf abgerufene Fakten stützen und so eine externe Bestätigung für generierte Inhalte bieten.
CAG-Systeme reduzieren Halluzinationen, indem sie ständig auf geprüfte, zwischengespeicherte Infos zugreifen. Wenn die zwischengespeicherten Infos aber nicht stimmen oder veraltet sind, können diese Fehler bei mehreren Interaktionen immer wieder auftauchen.
Wenn du über den Einsatz in der Produktion in großem Maßstab nachdenkst, wird es richtig ernst. Hier sind ein paar der Kompromisse bei der Leistung, die ich gemacht habe:
RAG-Systeme: Höhere Latenz wegen des Abruf-Overheads, aber du kannst horizontal skalieren, indem du Abrufkapazität hinzufügst und Vektordatenbanken verteilst. Ich hab gesehen, dass das in der Praxis gut klappt, wenn man erst mal in die Infrastruktur investiert hat.
CAG-Systeme: Super Reaktionszeiten, aber die Skalierbarkeit ist durch den Speicher begrenzt. Der Engpass tritt normalerweise auf, wenn der Aufwand für die Cache-Verwaltung schneller wächst, als es dein Speicherbudget zulässt.
Die Frage der Skalierbarkeit ist selten einfach zu beantworten. Das hängt stark von deinen Abfragemustern und den verfügbaren Ressourcen ab.
Okay, genug Theorie. Lass uns mal praktisch werden. Nachdem ich beide Ansätze in verschiedenen Projekten ausprobiert habe, hier mein Rahmen, um zu entscheiden, welchen ich benutze.
So leite ich Teams normalerweise durch diese Entscheidung. Unternehmen sollten bei der Entscheidung zwischen RAG und CAG die Volatilität ihrer Daten, die Anforderungen an die Latenz, die Konsistenzbedürfnisse und die Verfügbarkeit von Ressourcen berücksichtigen. Hohe Informationsvolatilität ist gut für RAG, während stabile Wissensbereiche von der Effizienz von CAG profitieren.
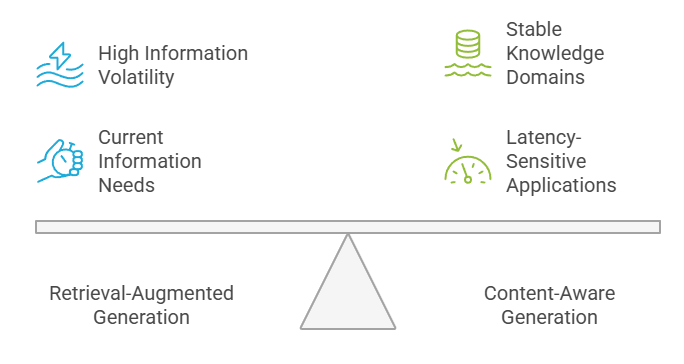
Entscheidungsrahmen: RAG gegen CAG
Latenzempfindliche Anwendungen laufen normalerweise besser mit CAG-Systemen, während Anwendungen, die die aktuellsten Infos brauchen, RAG-Funktionen nutzen sollten. Die Entscheidung hängt oft davon ab, wie man diese konkurrierenden Anforderungen unter Berücksichtigung der geschäftlichen Prioritäten gegeneinander abwägt.
Wähle RAG, wenn du Folgendes brauchst:
Dynamische, regelmäßig aktualisierte Infos: Forschungsanwendungen, Kundensupport für sich weiterentwickelnde Produkte oder Nachrichtenanalyseplattformen, bei denen Aktualität wichtiger ist als Schnelligkeit.
Große, vielfältige Wissensdatenbanken: Rechercheplattformen für Rechtsfragen, medizinische Informationssysteme und Anwendungen für Wettbewerbsinformationen. Meiner Erfahrung nach ist RAG normalerweise die richtige Wahl, wenn sich deine Daten täglich oder wöchentlich ändern.
Schutz vor veralteten Infos: Wenn es teurer ist, veraltete Daten zu liefern, als die zusätzliche Latenz in Kauf zu nehmen.
Ich sag meinen Kunden meistens: Wenn du dir Sorgen machst, dass deine KI veraltete Antworten gibt, fang mit RAG an. Du kannst die Geschwindigkeit später immer noch optimieren. Wenn du dich für RAG entscheidest, denk dran: „ ”, um das richtige Framework auszuwählen.
Entscheide dich für CAG, wenn du:
Stabile Wissensanforderungen: Chatbots für den Kundenservice, die Routineanfragen bearbeiten, Bildungsplattformen mit festen Lehrplänen oder Workflow-Automatisierung, wo sich das Kernwissen nicht großartig ändert.
Viele Suchanfragen mit sich wiederholenden Mustern: Wenn du jeden Tag tausende Male die gleichen 100 Fragen beantwortest, macht sich der Geschwindigkeitsvorteil von CAG schnell bemerkbar.
Latenzkritische Anwendungen: Echtzeit-Empfehlungssysteme, interaktive Spielerlebnisse oder überall dort, wo Millisekunden für die Benutzererfahrung wichtig sind.
Meiner Erfahrung nach ist CAG super, wenn du 90 % deiner Anfragen vorhersagen kannst und deine Wissensdatenbank ziemlich stabil ist.
Ich zeig dir mal, wie das in der Praxis läuft. Ich habe mit Implementierungen in verschiedenen Branchen gearbeitet (und mich damit beschäftigt) und dabei sind ein paar klare Muster aufgefallen. Hier ist, was in der Produktion wirklich funktioniert.
Fangen wir unsere Branchenanalyse mit dem Gesundheitswesen an, wo es besonders wichtig ist, genaue und aktuelle Infos zu kriegen.
Im Gesundheitswesen helfen RAG-Systeme bei der klinischen Entscheidungsfindung, indem sie die neuesten medizinischen Forschungsergebnisse, Behandlungsprotokolle und Infos zu Wechselwirkungen von Medikamenten abrufen. Mediziner können auf aktuelle klinische Leitlinien und neueste Studienergebnisse zugreifen, die vielleicht nicht in den Trainingsdaten des Modells enthalten sind.
CAG-Systeme sind echt nützlich im Gesundheitswesen, wo man schnell auf Protokolle, Patientenakten und standardisierte Diagnoseprozesse zugreifen muss, bei denen es vor allem auf Konsistenz und Schnelligkeit ankommt.
Ich finde, im Gesundheitswesen sieht man am besten, warum hybride Ansätze so sinnvoll sind: CAG für Standardprotokolle, RAG für alles, was sich ändert.
Finanzen sind auch ein spannender Fall. Hier sind die Anforderungen total anders als im Gesundheitswesen.
Finanzinstitute nutzen RAG-Systeme für Marktanalysen, die Überwachung der Einhaltung gesetzlicher Vorschriften und die Anlageforschung, wo der Zugriff auf Echtzeit-Marktdaten und aktuelle regulatorische Änderungen super wichtig ist. Diese Systeme können mit Finanzdatenbanken und Newsfeeds verbunden werden, um aktuelle Marktinformationen zu liefern.
Andererseits sind CAG-Systeme super für Finanzanwendungen, die schnelle Antworten auf Routineanfragen brauchen, wie zum Beispiel Standard-Finanzberechnungen, Produktdefinitionen und festgelegte Compliance-Verfahren.
Was mir im Finanzbereich aufgefallen ist, ist, dass die Entscheidung oft auf das regulatorische Risiko hinausläuft. Wenn Fehler Millionen an Compliance-Strafen kosten können, entscheiden sich Teams eher für RAG.
Bildung ist auch ein super Bereich für RAG und CAG.
Personalisierte Lernplattformen profitieren oft von RAG, weil die Schüler Zugang zu vielfältigen und ständig aktualisierten Inhalten brauchen, wie neuen Forschungsartikeln, Kursmaterialien oder sogar aktuellen Ereignissen, die als Lernbeispiele dienen. Mit RAG kann ein KI-Tutor genaue Referenzen oder zusätzliche Lektüre empfehlen, die nicht in seinem ursprünglichen Trainingssatz enthalten waren.
CAG hingegen ist super in Situationen, in denen Wiederholung und Beständigkeit wichtig sind. Wenn eine Plattform zum Beispiel regelmäßig Quizze, Erklärungen zu Standardkonzepten oder strukturierte Übungsrunden anbietet, sorgt Caching dafür, dass das Feedback schneller und zuverlässiger kommt.
So bringen Bildungssysteme oft beides zusammen, indem sie neue Ideen mit einer soliden Vertiefung des Grundwissens verbinden.
In der Software-Welt setzen Entwickler immer öfter auf beide Methoden, um ihre Produktivität zu steigern.
RAG hilft Entwicklern, indem es Dokumentation, API-Spezifikationen oder Schritte zur Fehlerbehebung aus externen Quellen abruft. Da sich Softwarebibliotheken oder Frameworks schnell ändern können, ist die Abrufschicht von RAG super, um sicherzustellen, dass die Antworten immer aktuell bleiben.
CAG hilft bei Aufgaben, die viel mit wiederholten Interaktionen zu tun haben, wie Code-Vervollständigung, Hilfe beim Debuggen oder Antworten auf häufig gestellte Fragen von Entwicklern. Durch das Zwischenspeichern von schon bekannten Mustern macht CAG die Latenzzeit kürzer und bringt den Entwicklungsprozess schneller voran.
Zusammen helfen diese Ansätze Ingenieuren, schneller voranzukommen, während sie sich auf genaue und kontextbezogene Anleitungen verlassen können.
Der Rechtsbereich ist ein weiteres spannendes Beispiel für Fallstudien, wie diese Ansätze domänenspezifische Herausforderungen mit unterschiedlichen Informationszugriffsmustern angehen.
Juristen nutzen RAG-Systeme für die Recherche von Präzedenzfällen und die Prüfung von Verträgen, wo der Zugriff auf die aktuellsten Vertragsdokumente und Rechtsfälle echt wichtig ist. So können sie sicherstellen, dass ihre Rechtsberatung die neuesten Gerichtsentscheidungen und regulatorischen Änderungen berücksichtigt, sobald diese veröffentlicht werden.
Andersrum ist CAG die bessere Wahl für die interne Compliance-Überwachung und automatisierte Richtlinienumsetzung, vor allem wenn die Regeln feststehen und die Abfragen sich ständig wiederholen. Anstatt jeden Tag tausende Male die gleichen „Anti-Korruptionsrichtlinien“ oder „DSGVO Artikel 15“ abzurufen, lädt ein CAG-System diese statischen regulatorischen Rahmenbedingungen direkt in den Kontext des Modells.
Da sich die grundlegende „Wahrheit“ (das Gesetz) im Alltag kaum ändert, vermeidet das Zwischenspeichern dieses Wissens den Engpass beim Abruf für 90 % der Abfragen, bei denen es sich um Standard-Konformitätsprüfungen handelt.
Im Einzelhandel und E-Commerce machen Geschwindigkeit und Relevanz das Kundenerlebnis aus.
RAG wird oft eingesetzt, um eine erweiterte Produktsuche zu ermöglichen, Live-Bestandsdaten zu integrieren und dynamische Empfehlungen zu geben. Wenn zum Beispiel ein Kunde fragt, ob ein Produkt auf Lager ist, kann ein RAG-fähiges System Echtzeit-Datenbanken checken, um eine aktuelle Antwort zu geben.
CAG hingegen sorgt dafür, dass häufig gestellte Kundenfragen, wie zum Beispiel zu Versandbedingungen, Rückgaberegeln oder Bestellstatus-Updates, schnell beantwortet werden. Durch die Wiederverwendung zwischengespeicherter Interaktionen liefert das System sofortige Antworten und reduziert die Serverlast.
Wenn man RAG und CAG zusammen benutzt, kriegt man ein nahtloses Erlebnis, das sowohl genau als auch effizient ist.
Bis jetzt haben wir RAG und CAG als separate Techniken betrachtet. In der Praxis fangen aber viele Unternehmen an, hybride Ansätze zu nutzen, die beide Methoden zusammenbringen. Mit dieser Kombination können sie die Frische und Anpassungsfähigkeit von RAG mit der Geschwindigkeit und Effizienz von CAG verbinden.
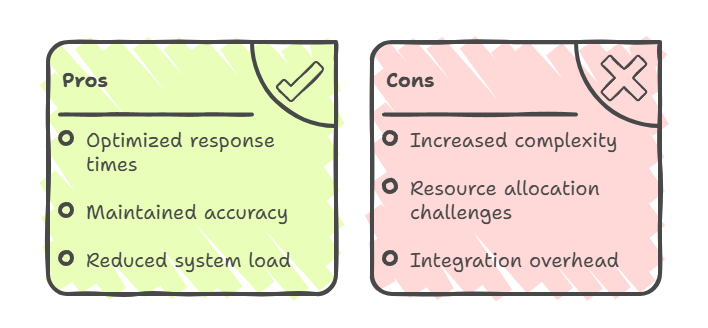
Hybride Ansätze: Vor- und Nachteile
Hybridsysteme sind die nächste Stufe in der Wissensintegration und verbinden die dynamischen Suchfunktionen von RAG mit den Effizienzvorteilen von CAG.
Bei diesen hybriden Modellen wird CAG normalerweise für oft genutzte, stabile Infos verwendet, während RAG für Abfragen eingesetzt wird, die Echtzeitdaten oder spezielles Wissen brauchen. Das bringt das Beste aus beiden Welten: schnellere Antworten auf häufige Fragen, immer noch genaue Infos bei dynamischen Inhalten und weniger Belastung für das ganze System durch cleveres Routing.
Hybride Ansätze machen die Architektur aber komplizierter. Sie brauchen eine ausgeklügelte Koordination zwischen Caching- und Abrufsystemen und erfordern eine sorgfältige Balance bei der Ressourcenzuteilung.
Der Integrationsaufwand umfasst die Verwaltung doppelter Wissenspfade, die Synchronisierung zwischen zwischengespeicherten und abgerufenen Daten sowie die Implementierung einer intelligenten Routing-Logik, die für jede Abfrage die zu verwendende Methode festlegt.
Wenn du dich für eine Hybridlösung entscheidest, musst du wirklich wissen, was du tust.
Meiner Meinung nach sind hybride Architekturen im Moment am häufigsten in Kundenservice-Umgebungen zu finden. Ich sehe oft Plattformen, wo CAG die statischen FAQs mit hohem Volumen für den sofortigen Abruf übernimmt, während RAG gezielt eingesetzt wird, um Live-Kontodetails oder die Transaktionshistorie abzurufen.
Ein weiteres klassisches Beispiel findet sich in Forschungsanwendungen, wo CAG grundlegendes Wissen im Cache speichert, während RAG die neuesten Veröffentlichungen oder dynamische Daten für neue Abfragen abruft. Ähnlich wie bei E-Commerce-Plattformen kümmert sich CAG um zwischengespeicherte Produktbeschreibungen oder Richtlinien, während RAG Echtzeit-Bestandsdaten und Preisaktualisierungen einbindet.
Hör mal, es gibt hier keine allgemeingültige richtige Antwort, und jeder, der dir was anderes erzählt, will dir wahrscheinlich was verkaufen. Die Wahl zwischen RAG und CAG oder die Entscheidung, sie zu kombinieren, hängt letztendlich von deinen spezifischen Anforderungen, Einschränkungen und Zielen ab.
RAG ist super, wenn du dynamische, aktuelle Infos brauchst und ein bisschen Verzögerung in Kauf nehmen kannst, solange die Infos genau und aktuell sind. CAG ist super, wenn es auf Geschwindigkeit und Beständigkeit ankommt und dein Wissensbedarf ziemlich gleich bleibt.
In Zukunft werden wir wahrscheinlich immer ausgefeiltere hybride Ansätze sehen, die Anfragen intelligent zwischen zwischengespeicherten und abgerufenen Infos weiterleiten und so sowohl die Leistung als auch die Genauigkeit optimieren.
Um alle Fähigkeiten zu meistern, die du für das Design und die Bereitstellung von RAG-, CAG- oder Hybridsystemen brauchst, solltest duüberleg dir, dich für unseren umfassenden Lernpfad zum KI-Ingenieur anzumelden.
Kurse zu generativer KI
Lernpfad
Lernpfad
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Stephen Gruppetta
