
Cursus
Associate AI Engineer pour développeurs
26 h
Alors que l'intelligence artificielle continue d'évoluer, l'un des principaux défis consiste à déterminer comment intégrer efficacement les connaissances dans les grands modèles linguistiques (LLM), compte tenu de leurs connaissances limitées. Afin de surmonter ces contraintes, les chercheurs et les praticiens ont exploré différentes approches en matière d'intégration des connaissances.
Deux des approches les plus importantes à l'heure actuelle sont la génération augmentée par la récupération (RAG) et la génération augmentée par le cache (CAG). J', j'ai travaillé avec les deux approches, et bien qu'elles soient souvent présentées comme concurrentes, j'ai constaté qu'elles s'apparentent davantage à des outils différents pour des tâches différentes, parfois même plus efficaces lorsqu'elles sont utilisées conjointement.
Dans cet article, je vais vous présenter une comparaison entre RAG et CAG, en explorant la signification de chaque concept, leur fonctionnement et leur utilisation optimale dans des applications concrètes. À la fin, vous comprendrez en quoi ces approches diffèrent, où elles se recoupent et comment choisir entre elles, voire les combiner, lors de la conception de systèmes d'IA.
Si vous souhaitez aller au-delà des concepts et commencer à développer vous-même ces systèmes, je vous recommande de suivre notre cours pratique intitulé « Retrieval Augmented Generation (RAG) avec LangChain ».
La génération augmentée par récupération est une technique d'te qui permet aux modèles d'IA d'aller au-delà de leurs données d'entraînement fixes et d'intégrer dynamiquement des informations externes. Au lieu de se fier uniquement à ce qui a été codé dans le modèle pendant l'entraînement,
RAG relie le modèle à des bases de données externes et à des mécanismes de recherche, lui permettant ainsi de récupérer des documents ou des connaissances pertinents au moment d'une requête.
Cette idée a gagné en popularité lorsque les organisations ont réalisé que les données de formation statiques devenaient rapidement obsolètes. J'ai observé comment les informations évoluent quotidiennement dans de nombreux secteurs, et un modèle dépourvu de couche de récupération externe ne peut pas suivre le rythme.
RAG a été développé pour combler cette lacune et intégrer des connaissances nouvelles, spécifiques à un domaine ou dynamiques directement dans le processus de génération.
Le flux de travail RAG commence par une requête utilisateur. La requête est d'abord codée en une représentation vectorielle, qui est ensuite utilisée pour effectuer une recherche dans une base de données vectorielle (système de recherche) contenant des documents, des enregistrements ou d'autres sources de connaissances. Cette étape de récupération garantit que le modèle identifie les informations externes les plus pertinentes avant de poursuivre.
À ce stade, il est essentiel de mettre en place des stratégies de segmentation efficaces : les documents sont divisés en unités de sens plus petites, généralement comprises entre 100 et 1 000 tokens, afin que le système de recherche puisse faire apparaître le contexte le plus pertinent sans surcharger le modèle de génération.
Les algorithmes de recherche, souvent basés sur la recherche approximative du plus proche voisin, garantissent que les informations pertinentes sont récupérées rapidement, même à partir de bases de connaissances à grande échelle.
Une fois les documents pertinents récupérés, ils sont transmis à l'étape de génération, où le modèle linguistique intègre ces informations dans sa réponse. Ce processus permet au système de fournir des réponses non seulement plus cohérentes, mais également fondées sur des connaissances externes actualisées.
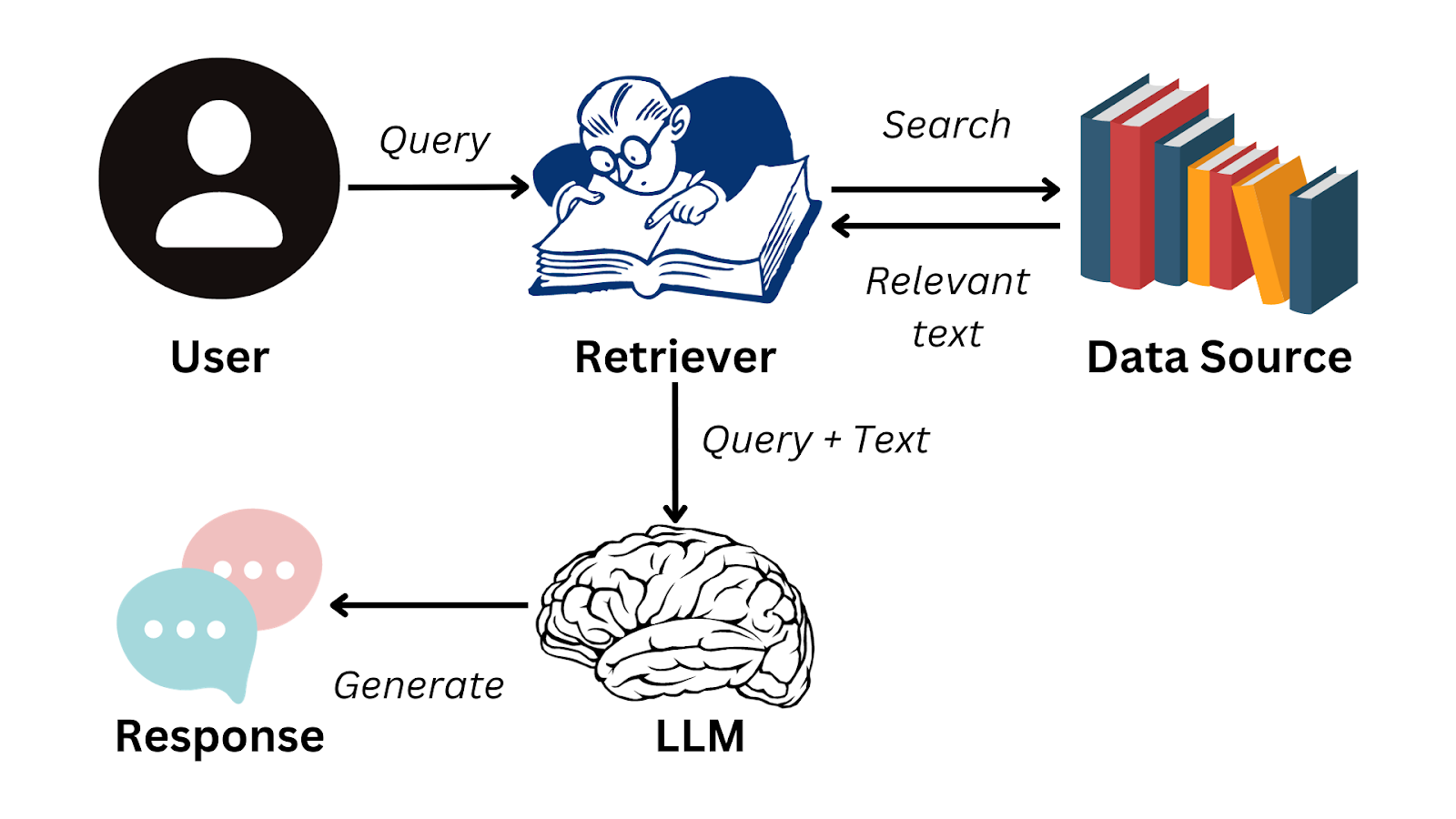
Flux de travail RAG
Les sources de connaissances externes peuvent inclure des bases de données propriétaires, des articles scientifiques, des archives juridiques ou même des API en temps réel. Le moteur de recherche constitue le pont qui permet au modèle linguistique de combiner sa capacité générative avec des données factuelles. Considérez cela comme si vous fournissiez à votre IA une carte de bibliothèque plutôt que d'espérer qu'elle mémorise chaque ouvrage.
Cette structure de base peut être affinée en appliquant des techniques RAG avancées ou en utilisant Corrective RAG (CRAG), uneversion améliorée de RAG optimisée pour la précision.
Maintenant que nous avons examiné la structure et le fonctionnement du RAG, il est plus facile d'évaluer ce qui rend cette méthode particulièrement efficace dans des scénarios réels.
Ce que j'apprécie le plus chez RAG, c'est sa capacité à gérer le changement. Votre service juridique met à jour une politique à 15 h ? Votre système RAG en est informé à 15 h 01, sans qu'aucune formation supplémentaire ne soit nécessaire.
D'après mon expérience, RAG se distingue dans trois domaines principaux :
Mises à jour en temps réel : La couche de récupération se connecte à des connaissances externes, fournissant des réponses basées sur les données les plus récentes. Cela rend le RAG particulièrement précieux dans des domaines en constante évolution tels que la médecine, la finance ou la technologie.
Réduction des hallucinations: Les modèles de langage à grande échelle (LLM) génèrent souvent des textes qui semblent plausibles, mais qui sont factuellement incorrects. En fondant ses réponses sur des documents récupérés, le RAG garantit que les résultats sont ancrés dans la réalité, ce qui renforce leur fiabilité.
Intégration flexible des données : Les connaissances externes peuvent provenir de multiples sources, telles que des bases de données structurées, des API semi-structurées ou des référentiels de texte non structurés. Les organisations peuvent adapter les pipelines de récupération à leurs besoins spécifiques.
Bien que le RAG offre des avantages convaincants, il est tout aussi important de comprendre les défis et les contraintes liés à cette approche.
C'est là que cela devient délicat, et c'est ce dont j'informe mes clients dès le départ. RAG implique de véritables compromis :
Complexité du système : Il est nécessaire d'orchestrer le système de récupération, la base de données vectorielle et le modèle de génération. Cette complexité engendre des points de défaillance supplémentaires et augmente les frais généraux liés à la maintenance.
Problèmes de latence : Le processus de récupération ajoute une charge informatique supplémentaire à chaque requête. La recherche dans de vastes bases de connaissances et la récupération de documents pertinents prennent du temps, ce qui peut nuire à l'expérience utilisateur dans les applications en temps réel.
Dépendance de la qualité de la récupération : La qualité de vos réponses dépend de l'efficacité de votre mécanisme de récupération. Une récupération inadéquate implique que des informations contextuelles non pertinentes sont transmises au modèle linguistique, ce qui peut nuire à la qualité de la réponse.
Cependant, il existe plusieurs techniques clés pour améliorer les performances du RAG et traiter efficacement ces problèmes.
Après avoir examiné l'approche axée sur la récupération, je vais maintenant aborder la génération augmentée par cache, qui suit une voie très différente pour améliorer les performances du modèle.
CAG est le dernier arrivé, et honnêtement, il m'a fallu un certain temps pour apprécier son élégance. Au lieu de rechercher constamment des informations comme le RAG, le CAG précharge ce dont vous avez besoin et le garde à disposition.
Contrairement à l'approche de récupération dynamique du RAG, le CAG se concentre sur le préchargement et la conservation des informations pertinentes dans le contexte étendu du modèle ou dans la mémoire cache. Le graphique suivant compare les deux approches :
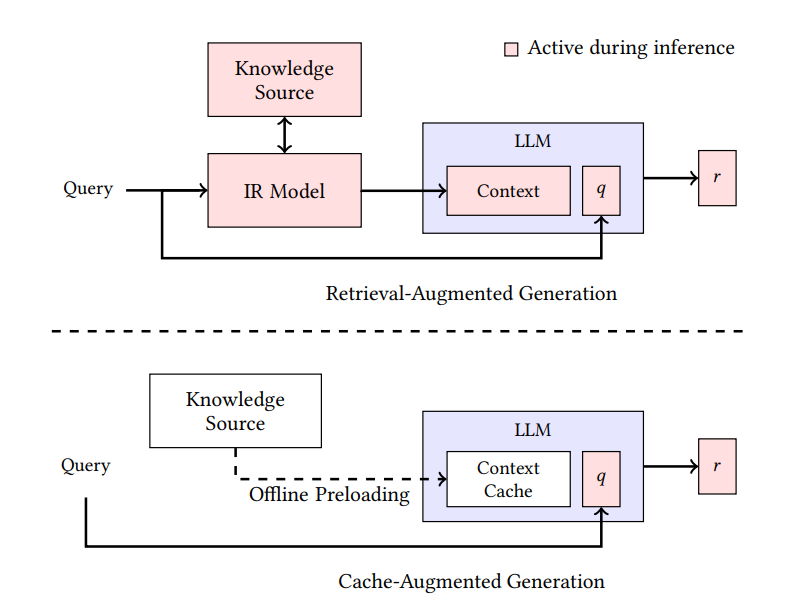
Comparaison des architectures RAG et CAG
CAG s'est distingué grâce au développement de modèles linguistiques prenant en charge des fenêtres contextuelles de plus en plus grandes, pouvant parfois atteindre des millions de tokens. C'est comme la différence entre rechercher chaque réponse dans un ouvrage de référence et disposer d'une fiche de révision que vous avez déjà préparée.
CAG s'appuie sur deux mécanismes de mise en cache complémentaires.
Tout d'abord, la mise en cache des connaissances se produit lorsque des documents ou des références pertinents sont préchargés dans la fenêtre de contexte étendue du modèle. Une fois stockées, le modèle peut réutiliser ces informations dans plusieurs requêtes sans avoir à les récupérer en externe, comme le font les systèmes RAG.
Deuxièmement, l' de mise en cache clé-valeur (KV) met l'accent sur l'efficacité en stockant les états d'attention (matrices clé et valeur) générés lorsque le modèle traite les jetons. Lorsqu'une requête similaire ou répétée est reçue, le modèle peut réutiliser ces états mis en cache au lieu de les recalculer à partir de zéro.
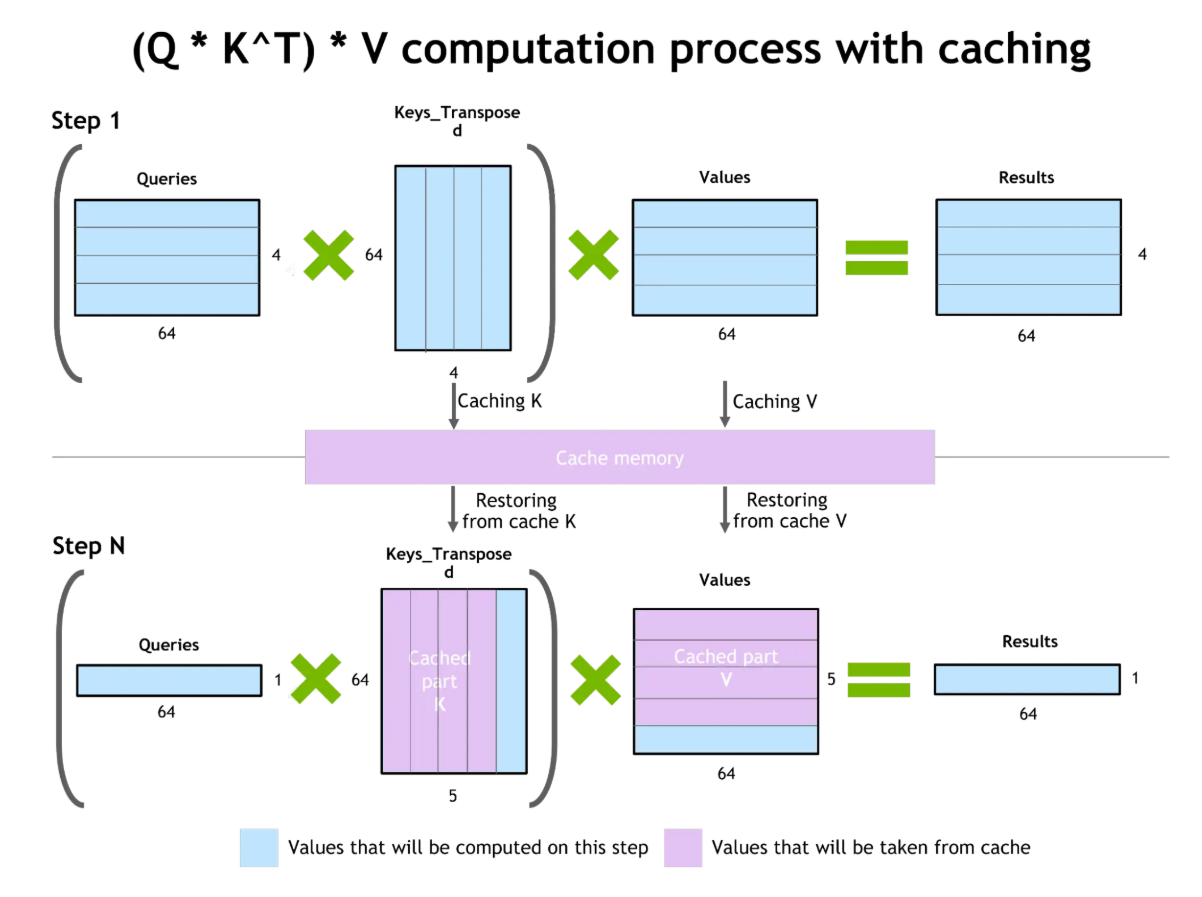
Ce mécanisme réduit la latence et permet au modèle de conserver le contexte à plus long terme tout au long des conversations. Le flux de travail augmente la mémoire effective du système, lui permettant ainsi de traiter des historiques de dialogue plus volumineux ou des requêtes répétitives sans devoir recommencer à zéro à chaque fois.
L'idée principale est que la mise en cache étend les limites pratiques de ce qu'un modèle peut mémoriser. En conservant les informations et en y faisant rapidement référence, CAG crée une expérience de continuité tout au long des conversations prolongées.
En gardant ce flux de travail à l'esprit, nous pouvons commencer à comprendre pourquoi le CAG est devenu de plus en plus attractif pour certaines applications, en particulier lorsque la rapidité et l'efficacité sont des priorités absolues.
La principale force de CAG réside dans son efficacité. Étant donné que le modèle réutilise les calculs mis en cache, les temps de réponse s'améliorent considérablement, ce qui réduit la latence, en particulier dans les scénarios où les requêtes sont répétitives ou où les besoins en connaissances restent stables. C'est là que CAG se distingue véritablement :
Rapidité et efficacité : La réutilisation des calculs mis en cache améliore considérablement les temps de réponse, en particulier pour les requêtes répétitives ou les besoins en connaissances stables.
Cohérence entre les sessions : En conservant le contexte antérieur, CAG évite les réponses incohérentes et garantit la cohérence. Cela le rend particulièrement adapté aux agents conversationnels, à l'automatisation des flux de travail ou aux chatbots d'assistance à la clientèle, où les requêtes répétitives sont fréquentes.
Réduction de la complexité du système : Étant donné que le modèle n'a pas besoin d'effectuer autant de recherches externes, le système global est plus simple par rapport au RAG.
Malgré ces avantages, aucune technique n'est sans inconvénients, et la CAG présente ses propres défis que les organisations doivent examiner attentivement.
Informations obsolètes : Les données mises en cache deviennent obsolètes au fil du temps, de sorte que ces systèmes peuvent ne pas refléter les mises à jour récentes ou les changements dynamiques dans les bases de connaissances.
Exigences élevées en matière de mémoire : La gestion de caches volumineux nécessite des ressources informatiques importantes. Les organisations doivent trouver un équilibre entre la taille du cache, la mémoire disponible et les capacités de traitement.
Gestion complexe du cache : Garantir que les informations mises en cache restent précises et synchronisées entre les déploiements distribués nécessite des mécanismes de coordination sophistiqués, et cette complexité augmente à mesure que le système évolue.
Après avoir examiné séparément les méthodes RAG et CAG, l'étape suivante consiste à les comparer directement et à mettre en évidence les différences essentielles qui déterminent leur adoption dans la pratique.
Par conséquent, lequel devriez-vous réellement utiliser ? On me pose fréquemment cette question, et ma réponse sincère est : cela dépend de ce que vous construisez. Après avoir utilisé ces deux approches dans différents projets, j'ai observé des modèles d'lus clairs. Permettez-moi de vous présenter ce que j'ai appris à partir de mises en œuvre réelles.
|
Caractéristique |
RAG (génération augmentée par la récupération) |
CAG (génération augmentée par cache) |
|
Mécanisme central |
Juste à temps : Récupère les données pertinentes à partir d'une base de données externe pendant la requête. |
Préchargé : Charge les données pertinentes dans le contexte ou le cache du modèle avant la requête. |
|
Latence et vitesse |
Plus lent : Nécessite du temps pour rechercher, récupérer et traiter les documents avant de générer une réponse. |
Le plus rapide : Accède instantanément aux informations stockées en mémoire, ce qui élimine les frais généraux liés à la récupération. |
|
Actualité des connaissances |
En temps réel : Permet d'accéder à des données mises à jour il y a quelques secondes (par exemple, actualités de dernière minute, nouvelles lois). |
Instantané : Les informations ne sont à jour qu'à la dernière mise à jour du cache ; elles risquent d'être obsolètes. |
|
Meilleur cas d'utilisation |
Ensembles de données dynamiques et volumineux (par exemple, jurisprudence, recherche médicale, actualités). |
Ensembles de données stables et répétitifs (par exemple, règles de conformité, FAQ, procédures opérationnelles standard). |
|
Évolutivité |
Horizontal : S'adapte parfaitement aux bases de données volumineuses ; limité uniquement par la vitesse de recherche. |
Limité par la mémoire : Limité par la taille de la fenêtre contextuelle du modèle et la mémoire vive disponible. |
|
Complexité |
Élevé : Nécessite la gestion de bases de données vectorielles, l'intégration de pipelines et une logique de récupération. |
Modéré : Nécessite la gestion du cycle de vie du cache, l'optimisation du contexte et l'efficacité de la mémoire. |
|
Gestion des hallucinations |
Justifie ses réponses à l'aide de documents trouvés (citations). |
Justifie ses réponses dans un contexte cohérent et préétabli. |
RAG et CAG adoptent des approches fondamentalement différentes en matière d'accès aux connaissances. RAG suit un modèle juste à temps : il encode la requête de l'utilisateur, effectue une recherche dans une base de données vectorielle, récupère les documents pertinents, puis les transmet à l'étape de génération. Cette conception garantit l'accès aux informations les plus récentes, mais l'étape supplémentaire de récupération introduit un délai.
Sur le plan architectural, les systèmes RAG s'appuient sur des pipelines à plusieurs étapes qui combinent le découpage de documents, la recherche vectorielle et la coordination de la récupération. Le découpage des documents doit préserver la signification sémantique tout en restant efficace pour la recherche, et la recherche vectorielle dépend souvent d'algorithmes approximatifs de plus proche voisin pour traiter des collections à grande échelle sans coût élevé.
Le CAG, en revanche, fonctionne par préchargement. Au lieu de rechercher activement de nouvelles connaissances, il s'appuie sur des fenêtres contextuelles étendues et la mémoire cache pour réutiliser les informations précédemment stockées. Cette approche spatiale réduit la latence, car le modèle récupère les données à partir de la mémoire plutôt que d'une base de données externe.
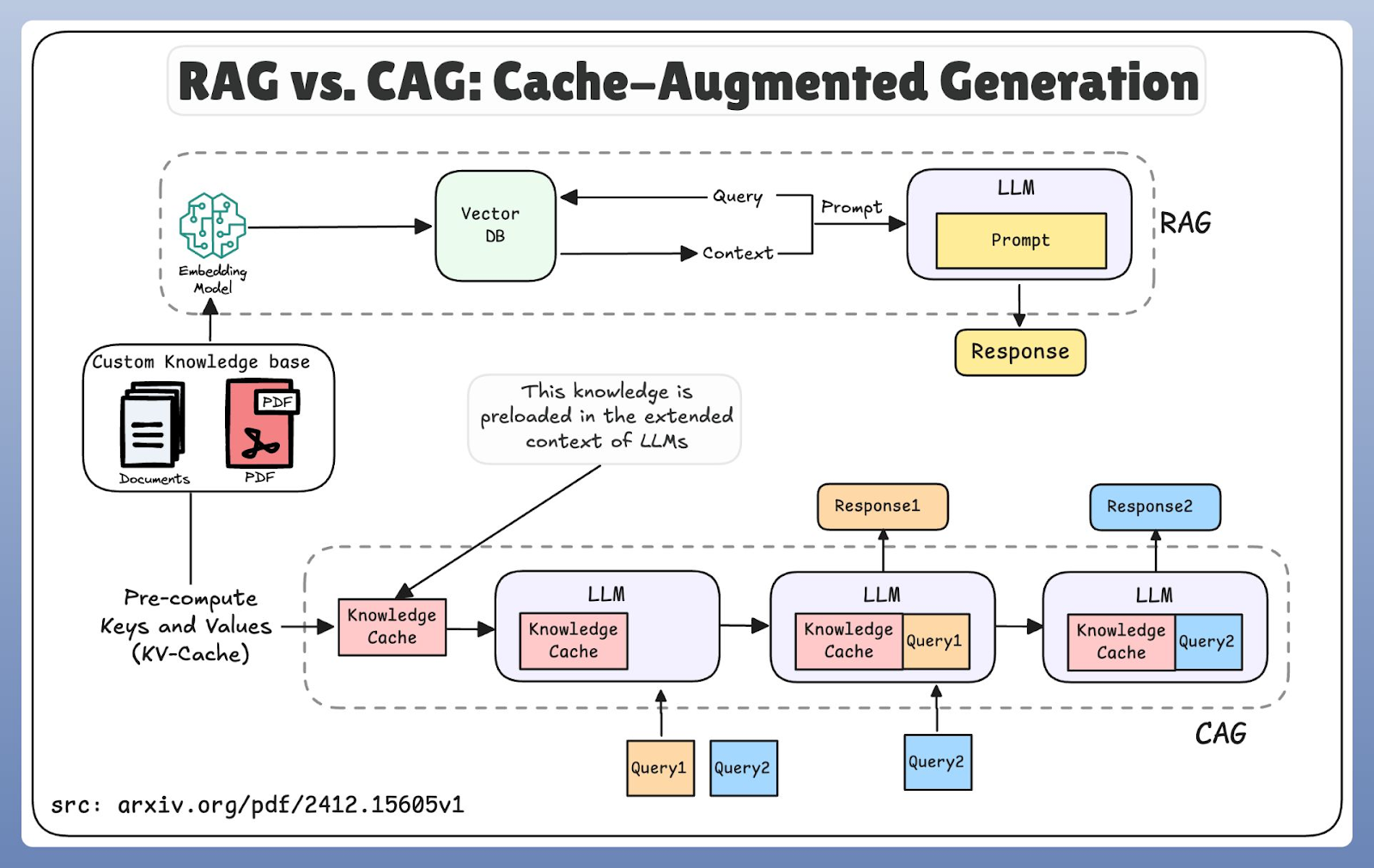
Comparaison des flux de travail RAG et CAG
Cependant, cela se fait au détriment de la fraîcheur : les informations mises en cache peuvent être en retard par rapport aux mises à jour réelles. Par conséquent, les systèmes CAG se concentrent sur la gestion intelligente du cache, en utilisant des stratégies de remplacement du cache, d'allocation de mémoire et d'optimisation de la fenêtre contextuelle.
J'ai observé des systèmes de production où ce compromis a déterminé le succès ou l'échec de la mise en œuvre, et l'efficacité de ces stratégies détermine directement à la fois les performances et l'évolutivité du système.
Au-delà de l'architecture technique, il existe une dimension pratique qui mérite d'être abordée : la manière dont chaque système gère le changement.
Voici ce que j'ai observé concernant l'adaptabilité :
La flexibilité de RAG : Le mécanisme de récupération dynamique permet à ces systèmes d'accéder immédiatement aux nouvelles informations dès leur indexation. J'ai observé des systèmes mettre à jour leur base de connaissances en temps réel, ce qui est idéal pour les domaines en constante évolution.
Rigidité du CAG : Les informations pré-mises en cache garantissent une plus grande cohérence, mais offrent moins de flexibilité. Bien que cela offre rapidité et prévisibilité, cela pose des difficultés avec les requêtes imprévues qui n'avaient pas été anticipées lors de la préparation du cache.
D'après mon expérience, cette différence est particulièrement importante lorsque votre domaine est imprévisible ou en constante évolution.
Abordons maintenant la question de la précision et la manière dont chaque approche traite la tendance de l'IA à inventer des informations.
Les deux techniques traitent les hallucinations différemment en fonction de leurs architectures sous-jacentes. Les systèmes RAG atténuent les hallucinations en fondant les réponses sur des informations factuelles récupérées, fournissant ainsi une validation externe du contenu généré.
Les systèmes CAG réduisent les hallucinations grâce à un accès constant à des informations vérifiées et mises en cache. Cependant, si les informations mises en cache contiennent des inexactitudes ou deviennent obsolètes, ces erreurs peuvent persister au cours de plusieurs interactions.
C'est lorsque l'on envisage un déploiement de production à grande échelle que l'on se rend véritablement compte de la réalité. Voici quelques-uns des compromis en matière de performances que j'ai rencontrés :
Systèmes RAG : Une latence plus élevée en raison de la charge liée à la récupération, mais il est possible de procéder à une extension horizontale en augmentant la capacité de récupération et en distribuant les bases de données vectorielles. Dans la pratique, j'ai constaté que cela fonctionne efficacement une fois que l'on a investi dans l'infrastructure.
Systèmes CAG : Temps de réponse supérieurs, mais évolutivité limitée par la mémoire. Le goulot d'étranglement survient généralement lorsque la charge liée à la gestion du cache augmente plus rapidement que ne le permet votre budget mémoire.
La question de l'évolutivité est rarement simple. Cela dépend fortement de vos modèles de requêtes et des ressources disponibles.
Très bien, assez de théorie. Passons à la pratique. Après avoir mis en œuvre ces deux approches dans différents projets, voici le cadre que j'utilise pour déterminer laquelle choisir.
Voici comment j'accompagne généralement les équipes dans cette prise de décision. Les organisations doivent évaluer la volatilité de leurs informations, leurs exigences en matière de latence, leurs besoins en matière de cohérence et la disponibilité de leurs ressources lorsqu'elles choisissent entre RAG et CAG. La forte volatilité des informations favorise le RAG, tandis que les domaines de connaissances stables bénéficient de l'efficacité du CAG.
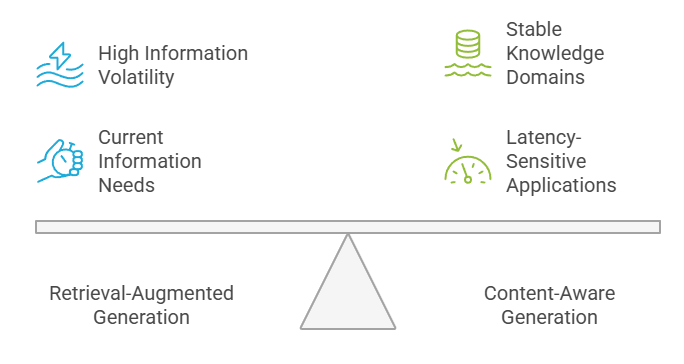
Cadre décisionnel : RAG contre CAG
Les applications sensibles à la latence fonctionnent généralement mieux avec les systèmes CAG, tandis que les applications nécessitant les informations les plus récentes devraient tirer parti des capacités RAG. La décision implique souvent de trouver un équilibre entre ces exigences contradictoires en fonction des priorités commerciales.
Veuillez choisir RAG lorsque vous avez besoin de :
Informations dynamiques et fréquemment mises à jour : Applications de recherche, assistance clientèle pour des produits en constante évolution ou plateformes d'analyse de l'actualité où l'actualité prime sur la rapidité.
Bases de connaissances étendues et variées : Plateformes de recherche juridique, systèmes d'information médicale et applications de veille concurrentielle. D'après mon expérience, si vos données changent quotidiennement ou hebdomadairement, le RAG est généralement la solution appropriée.
Protection contre les informations obsolètes : Lorsque le coût lié à la fourniture de données obsolètes est supérieur au coût lié à l'ajout de latence.
Je conseille généralement à mes clients : si vous craignez que votre IA fournisse des réponses obsolètes, commencez par utiliser RAG. Vous pouvez toujours optimiser la vitesse ultérieurement. Si vous optez pour RAG, veuillez vous référer à pour sélectionner le cadre approprié.
Veuillez choisir CAG lorsque vous rencontrez les situations suivantes :
Exigences en matière de connaissances stables : Les chatbots du service client traitant les demandes courantes, les plateformes éducatives proposant des programmes établis ou l'automatisation des flux de travail où les connaissances fondamentales ne changent pas beaucoup.
Volumes de requêtes élevés avec des modèles répétitifs : Si vous répondez aux mêmes 100 questions des milliers de fois par jour, l'avantage de la vitesse de CAG se multiplie rapidement.
Applications où la latence est critique : Systèmes de recommandation en temps réel, expériences de jeu interactives ou tout autre domaine où chaque milliseconde compte pour l'expérience utilisateur.
D'après mon expérience, le CAG est idéal lorsque vous pouvez prédire 90 % de vos requêtes et que votre base de connaissances est relativement stable.
Permettez-moi de vous démontrer comment cela se déroule dans la pratique. J'ai collaboré avec (et étudié) des mises en œuvre dans différents secteurs, et certaines tendances claires se sont dégagées. Voici ce qui fonctionne réellement en production.
Commençons notre analyse sectorielle par le domaine de la santé, où l'accès à des informations précises et opportunes revêt une importance particulière.
Dans le domaine des soins de santé, les systèmes RAG facilitent la prise de décision clinique en récupérant les dernières recherches médicales, les protocoles de traitement et les informations sur les interactions médicamenteuses. Les professionnels de santé bénéficient d'un accès aux directives cliniques actuelles et aux résultats d'études récentes qui pourraient ne pas être inclus dans les données d'entraînement du modèle.
Les systèmes CAG s'avèrent précieux dans les situations de soins de santé qui nécessitent un accès rapide à des protocoles établis, à des résumés des antécédents des patients et à des procédures de diagnostic standardisées où la cohérence et la rapidité sont primordiales.
À mon avis, c'est dans le domaine des soins de santé que l'on observe le plus clairement les avantages des approches hybrides : CAG pour les protocoles standard, RAG pour tout ce qui change.
La finance constitue un autre cas intéressant. Dans ce domaine, les exigences sont totalement différentes de celles du secteur de la santé.
Les institutions financières utilisent les systèmes RAG pour l'analyse de marché, la surveillance de la conformité réglementaire et la recherche en matière d'investissement, où l'accès aux données de marché en temps réel et aux récentes modifications réglementaires est essentiel. Ces systèmes peuvent s'intégrer à des bases de données financières et à des flux d'actualités afin de fournir des informations actualisées sur le marché.
D'autre part, les systèmes CAG sont particulièrement performants dans les applications financières qui exigent des réponses rapides à des demandes courantes, telles que les calculs financiers standard, les définitions de produits et les procédures de conformité établies.
Ce que j'ai observé dans le domaine financier, c'est que la décision repose souvent sur le risque réglementaire. Si une erreur peut entraîner des amendes de conformité de plusieurs millions, les équipes ont tendance à privilégier le RAG.
L'éducation constitue un autre terrain propice pour le RAG et le CAG.
Les plateformes d'apprentissage personnalisées bénéficient souvent du RAG, car les étudiants ont besoin d'accéder à des contenus variés et constamment mis à jour, notamment de nouveaux articles de recherche, des supports de cours ou même des événements d'actualité utilisés comme exemples d'apprentissage. Grâce à la technologie RAG, un tuteur IA peut fournir des références précises ou des lectures complémentaires qui ne faisaient pas partie de son ensemble de formation initial.
En revanche, le CAG est particulièrement performant dans les situations où la répétition et la cohérence sont essentielles. Par exemple, lorsqu'une plateforme propose régulièrement des quiz, des explications sur des concepts standard ou des sessions d'entraînement structurées, la mise en cache garantit une transmission plus rapide et plus cohérente des commentaires.
De cette manière, les systèmes éducatifs combinent souvent les deux techniques, alliant de nouvelles perspectives à un renforcement fiable des connaissances fondamentales.
Dans le domaine des logiciels, les développeurs adoptent de plus en plus ces deux méthodes pour améliorer leur productivité.
RAG assiste les développeurs en récupérant de la documentation, des spécifications API ou des étapes de dépannage à partir de sources externes. Étant donné que les bibliothèques logicielles ou les frameworks peuvent évoluer rapidement, la couche de récupération de RAG se distingue en garantissant que les réponses restent à jour.
Le CAG, quant à lui, intervient dans des tâches qui nécessitent de nombreuses interactions répétitives, telles que l'autocomplétion de code, l'assistance au débogage ou la réponse aux requêtes récurrentes des développeurs. En mettant en cache les modèles déjà observés, CAG réduit la latence et accélère le flux de travail de développement.
Ensemble, ces approches permettent aux ingénieurs d'avancer plus rapidement tout en s'appuyant sur des conseils précis et adaptés au contexte.
Le secteur juridique constitue un autre exemple fascinant d'études de cas quant à la manière dont ces approches permettent de relever les défis spécifiques à ce domaine, qui présente des modèles d'accès à l'information différents.
Les professionnels du droit utilisent les systèmes RAG pour la recherche jurisprudentielle et l'examen des contrats, où l'accès aux documents contractuels et aux précédents juridiques les plus récents est essentiel. Cela leur permet de s'assurer que leurs conseils juridiques reflètent les dernières décisions judiciaires et les changements réglementaires dès leur publication.
À l'inverse, CAG est le choix idéal pour la surveillance interne de la conformité et l'application automatisée des politiques, en particulier lorsque les règles sont fixes et les requêtes répétitives. Au lieu de récupérer les mêmes « directives anti-corruption » ou « article 15 du RGPD » des milliers de fois par jour, un système CAG précharge ces cadres réglementaires statiques directement dans le contexte du modèle.
Étant donné que la « vérité » fondamentale (la loi) change rarement au quotidien, la mise en cache de ces informations élimine le goulot d'étranglement lié à la récupération pour 90 % des requêtes qui sont des vérifications de conformité standard.
Dans le commerce de détail et le commerce électronique, la rapidité et la pertinence influencent directement l'expérience client.
RAG est fréquemment utilisé pour optimiser la recherche avancée de produits, intégrer des données d'inventaire en temps réel et fournir des recommandations dynamiques. Par exemple, si un client demande si un produit est disponible en stock, un système compatible RAG peut consulter des bases de données en temps réel afin de fournir une réponse actualisée.
Le CAG, quant à lui, garantit des réponses rapides aux questions courantes des clients, telles que les politiques d'expédition, les règles de retour ou les mises à jour du statut des commandes. En réutilisant les interactions mises en cache, le système fournit des réponses instantanées et réduit la charge du serveur.
Utilisés conjointement, RAG et CAG offrent une expérience fluide alliant précision et efficacité.
Jusqu'à présent, nous avons traité les techniques RAG et CAG séparément. Dans la pratique, cependant, de nombreuses organisations commencent à adopter des approches hybrides qui intègrent les deux méthodes. Cette combinaison leur permet d'équilibrer la fraîcheur et l'adaptabilité du RAG avec la rapidité et l'efficacité du CAG.
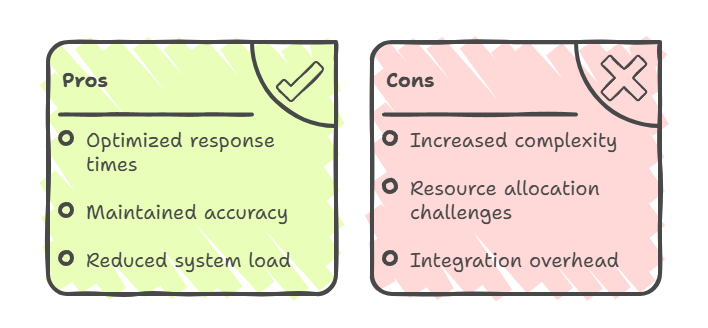
Approches hybrides : Avantages et inconvénients
Les systèmes hybrides représentent la prochaine évolution en matière d'intégration des connaissances, combinant les capacités de recherche dynamique du RAG avec les avantages du CAG en termes d'efficacité.
Dans ces modèles hybrides, le CAG est généralement utilisé pour les informations stables et fréquemment consultées, tandis que le RAG est déployé pour les requêtes qui nécessitent des données en temps réel ou des connaissances spécialisées. Il en résulte « le meilleur des deux mondes » : des temps de réponse optimisés pour les requêtes courantes, une précision maintenue pour le contenu dynamique et une charge globale réduite du système grâce à un routage intelligent.
Cependant, les approches hybrides introduisent une complexité architecturale accrue. Ils nécessitent une coordination sophistiquée entre les systèmes de mise en cache et de récupération, ainsi qu'un équilibre minutieux dans l'allocation des ressources.
La charge liée à l'intégration comprend la gestion de deux voies de connaissances, le maintien de la synchronisation entre les données mises en cache et les données récupérées, ainsi que la mise en œuvre d'une logique de routage intelligente qui détermine la méthode à utiliser pour chaque requête.
Si vous envisagez d'opter pour une solution hybride, il est essentiel que vous compreniez parfaitement ce que vous faites.
D'après mon expérience, l'adoption la plus répandue des architectures hybrides se trouve actuellement dans les écosystèmes de service à la clientèle. Je rencontre fréquemment des plateformes où le CAG gère les FAQ statiques à haut volume pour une récupération instantanée, tandis que le RAG est déployé de manière sélective pour récupérer les détails des comptes en temps réel ou l'historique des transactions.
Un autre exemple classique se trouve dans les applications de recherche, où le CAG conserve en mémoire cache les connaissances fondamentales, tandis que le RAG récupère les dernières publications ou les données dynamiques pour les nouvelles requêtes. De même, sur les plateformes de commerce électronique, le CAG gère les descriptions de produits ou les politiques mises en cache, tandis que le RAG intègre les niveaux de stock en temps réel et les mises à jour des prix.
Veuillez noter qu'il n'existe pas de réponse universelle à cette question, et toute personne qui vous affirmerait le contraire cherche probablement à vous vendre quelque chose. Le choix entre RAG et CAG, ou la décision de les combiner, dépend en fin de compte de vos exigences, contraintes et objectifs spécifiques.
RAG est particulièrement efficace lorsque vous avez besoin d'accéder à des informations dynamiques et actualisées et que vous pouvez tolérer une certaine latence en échange de la précision et de la fraîcheur des données. CAG excelle dans les situations où la rapidité et la cohérence sont primordiales, et où vos besoins en matière de connaissances restent relativement stables.
À l'avenir, nous assisterons probablement à l'émergence d'approches hybrides plus sophistiquées qui achemineront intelligemment les requêtes entre les informations mises en cache et celles récupérées, optimisant ainsi à la fois les performances et la précision.
Pour acquérir toutes les compétences nécessaires à la conception et au déploiement de systèmes RAG, CAG ou hybrides, nous vous invitons à envisager de vous inscrire à notre programme complet de formation professionnelle d'ingénieur en IA.envisagez de vous inscrire à notre cursus complet de carrière d'ingénieur en IA.
Cours sur l'IA générative
Cursus
Cursus
Cours