
Programa
Associate AI Engineer para desenvolvedores
26 h
À medida que a inteligência artificial continua a evoluir, um dos principais desafios tem sido descobrir como integrar o conhecimento de forma eficaz em Modelos de Linguagem de Grande Porte (LLMs), considerando o seu conhecimento limitado. Para superar essas limitações, pesquisadores e profissionais têm explorado diferentes abordagens para a integração do conhecimento.
Duas das abordagens mais importantes hoje em dia são a geração aumentada por recuperação, ou RAG, e a geração aumentada por cache, ou CAG. Eu,, já trabalhei com as duas abordagens e, embora elas sejam frequentemente apresentadas como concorrentes, descobri que são mais como ferramentas diferentes para trabalhos diferentes — às vezes, até melhores quando usadas juntas.
Neste artigo, vou te mostrar uma comparação entre RAG e CAG, explicando o que cada conceito significa, como funcionam e onde se encaixam melhor em aplicações do mundo real. No final, você vai ver como essas abordagens são diferentes, onde elas se parecem e como escolher entre elas, ou até mesmo combiná-las, ao projetar sistemas de IA.
Se você quiser ir além dos conceitos e começar a construir esses sistemas por conta própria, recomendo fazer nosso curso prático, Retrieval Augmented Generation (RAG) com LangChain.
A geração aumentada por recuperação é uma técnica de teo que permite que os modelos de IA vão além dos seus dados de treinamento fixos e incorporem informações externas de forma dinâmica. Em vez de depender só do que foi codificado no modelo durante o treinamento,
O RAG conecta o modelo a bancos de dados externos e mecanismos de recuperação, permitindo que ele busque documentos ou conhecimentos relevantes no momento de uma consulta.
Essa ideia ficou mais popular quando as organizações perceberam que os dados de treinamento estáticos ficam obsoletos rapidinho. Já vi como as informações mudam todo dia em vários setores, e um modelo sem uma camada de recuperação externa não consegue acompanhar.
O RAG foi criado pra resolver essa lacuna e trazer conhecimento novo, específico do domínio ou dinâmico direto pro processo de geração.
O fluxo de trabalho do RAG começa com uma consulta do usuário. A consulta é primeiro codificada em uma representação vetorial, que é então usada para pesquisar um banco de dados vetorial (sistema de recuperação) que contém documentos, registros ou outras fontes de conhecimento. Essa etapa de recuperação garante que o modelo identifique as informações externas mais relevantes antes de prosseguir.
Estratégias eficientes de fragmentação são essenciais nesta fase: os documentos são divididos em unidades menores de significado, geralmente variando de 100 a 1.000 tokens, para que o sistema de recuperação possa apresentar o contexto mais relevante sem sobrecarregar o modelo de geração.
Os algoritmos de recuperação, geralmente baseados na pesquisa aproximada do vizinho mais próximo, garantem que os trechos relevantes sejam recuperados rapidamente, mesmo em bases de conhecimento de grande escala.
Depois que os documentos relevantes são recuperados, eles vão para a etapa de geração, onde o modelo de linguagem junta essas informações na resposta. O processo permite que o sistema produza respostas que não só são mais coerentes, mas também baseadas em conhecimento externo e atualizado.
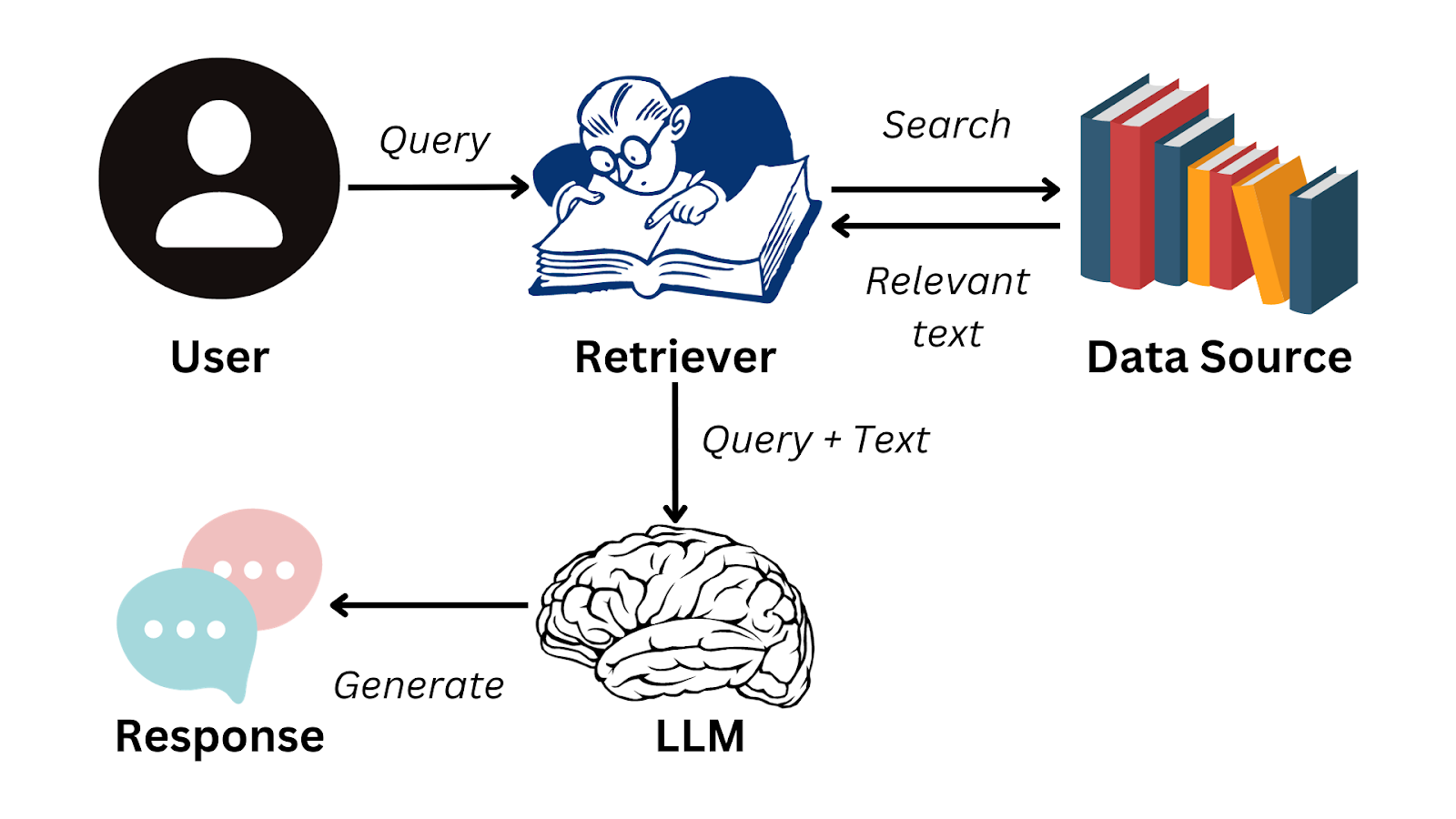
Fluxo de trabalho RAG
As fontes externas de conhecimento podem incluir bancos de dados proprietários, artigos científicos, arquivos jurídicos ou até APIs em tempo real. O mecanismo de recuperação é a ponte que permite que o modelo de linguagem combine sua capacidade de geração com dados factuais. Pense nisso como dar ao seu AI um cartão de biblioteca, em vez de esperar que ele memorize todos os livros.
Essa estrutura básica pode ser aprimorada aplicando técnicas avançadas de RAG ou usando o Corrective RAG (CRAG), umaversão melhorada do RAG otimizada para precisão.
Agora que vimos como o RAG é estruturado e funciona, fica mais fácil avaliar o que torna esse método tão poderoso em cenários reais.
O que mais curto no RAG é como ele lida com as mudanças. O seu departamento jurídico atualiza uma política às 15h? Seu sistema RAG fica sabendo disso às 15h01 — sem precisar de nenhum novo treinamento.
Pela minha experiência, a RAG se destaca em três áreas principais:
Atualizações em tempo real: A camada de recuperação se conecta a conhecimentos externos, fornecendo respostas com base nos dados mais recentes. Isso torna o RAG especialmente valioso em áreas que mudam rápido, como medicina, finanças ou tecnologia.
Menos alucinações: Os LLMs geralmente criam textos que parecem plausíveis, mas que, na verdade, estão errados. Ao basear as respostas em documentos recuperados, o RAG garante que o resultado tenha uma base factual, aumentando a confiabilidade.
Integração flexível de dados: O conhecimento externo pode vir de várias fontes, como bancos de dados estruturados, APIs semiestruturadas ou repositórios de texto não estruturados. As organizações podem personalizar os pipelines de recuperação de acordo com suas necessidades específicas.
Embora o RAG ofereça vantagens atraentes, é igualmente importante entender os desafios e as limitações que vêm com essa abordagem.
É aqui que fica complicado, e é sobre isso que eu aviso meus clientes desde o início. O RAG tem suas vantagens e desvantagens:
Complexidade do sistema: Você precisa organizar o sistema de recuperação, o banco de dados vetorial e o modelo de geração. Essa complexidade cria mais pontos de falha e aumenta os custos de manutenção.
Problemas de latência: O processo de recuperação adiciona uma sobrecarga computacional a cada consulta. Pesquisar em grandes bases de conhecimento e encontrar documentos relevantes leva tempo, o que pode prejudicar a experiência do usuário em aplicativos em tempo real.
Dependência da qualidade da recuperação: Suas respostas são tão boas quanto o seu mecanismo de recuperação. Uma recuperação ruim significa que um contexto irrelevante é alimentado ao modelo de linguagem, podendo prejudicar a qualidade da resposta.
Mas tem várias técnicas importantes pra melhorar o desempenho do RAG e lidar com esses problemas de forma eficaz.
Depois de explorar a abordagem focada na recuperação, vou agora passar para a geração aumentada por cache, que segue um caminho bem diferente para melhorar o desempenho do modelo.
O CAG é o mais novo do pedaço e, sinceramente, demorei um pouco para curtir a elegância dele. Em vez de ficar sempre buscando informações como o RAG, o CAG já carrega o que você precisa e mantém tudo pronto.
Diferente da abordagem de recuperação dinâmica do RAG, o CAG foca em pré-carregar e manter informações relevantes no contexto estendido do modelo ou na memória cache. O gráfico a seguir compara as duas abordagens:
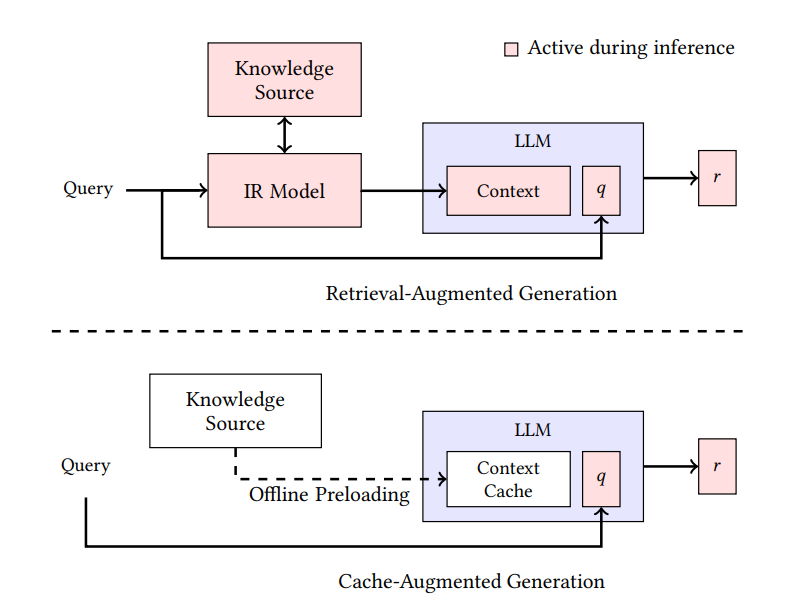
Arquiteturas RAG e CAG comparadas
O CAG ganhou destaque com o desenvolvimento de modelos de linguagem que suportam janelas de contexto cada vez maiores, às vezes chegando a milhões de tokens. É tipo a diferença entre procurar todas as respostas em um livro de referência e ter uma folha de cola que você já preparou.
O CAG usa dois mecanismos de cache que se complementam.
Primeiro, o armazenamento em cache de conhecimento acontece quando documentos ou materiais de referência relevantes são pré-carregados na janela de contexto estendido do modelo. Depois de armazenado, o modelo pode reutilizar essas informações em várias consultas sem precisar buscá-las externamente, como fazem os sistemas RAG.
Segundo, o cache de chave-valor (KV) foca na eficiência, guardando os estados de atenção (matrizes de chave e valor) gerados enquanto o modelo processa tokens. Quando uma consulta parecida ou repetida chega, o modelo pode usar de novo esses estados armazenados em cache, em vez de recalcular tudo de novo.
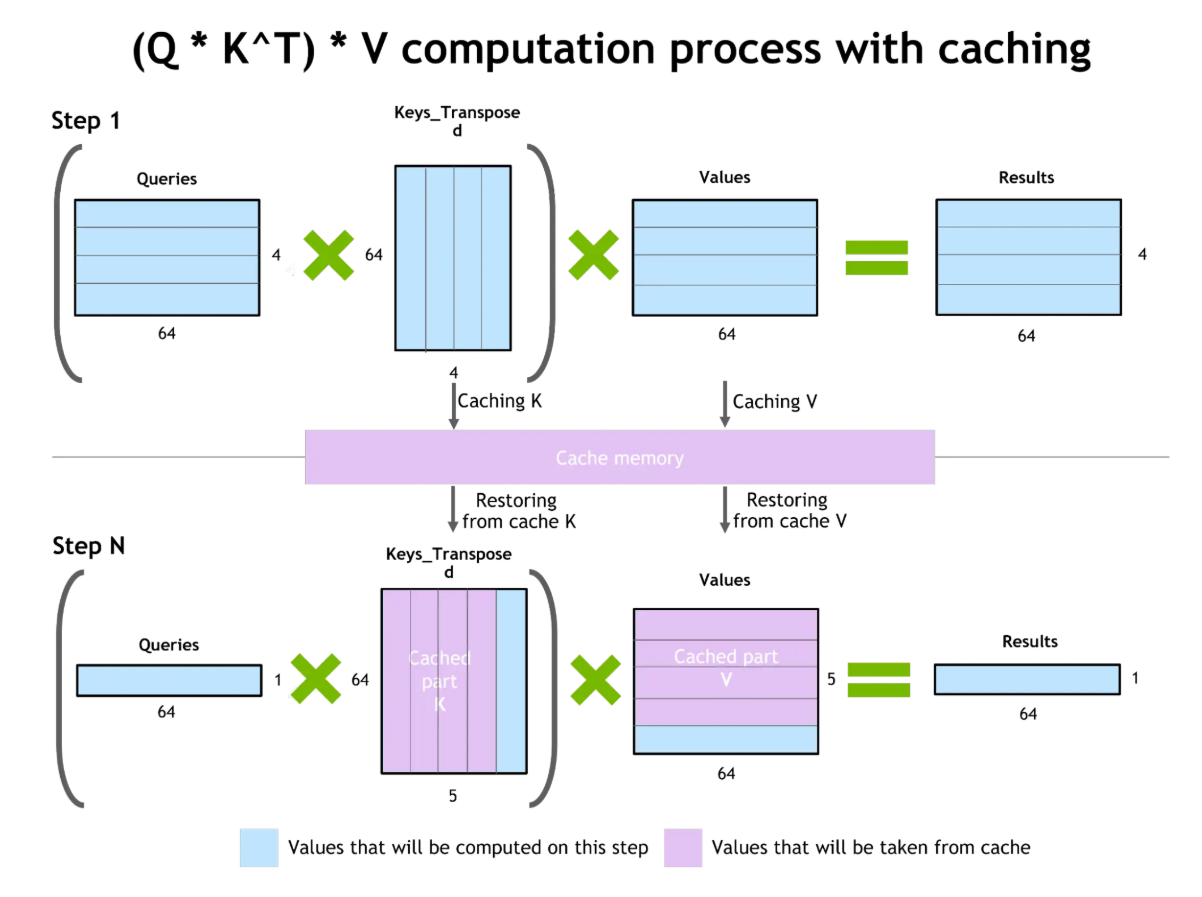
Esse mecanismo reduz a latência e permite que o modelo mantenha o contexto de longo prazo nas conversas. O fluxo de trabalho aumenta a memória efetiva do sistema, permitindo que ele lide com históricos de diálogo mais extensos ou consultas repetitivas sem precisar começar do zero todas as vezes.
A ideia principal é que o cache amplia os limites práticos do que um modelo pode lembrar. Ao manter as informações e acessá-las rapidinho, o CAG cria uma experiência de continuidade em conversas mais longas.
Com esse fluxo de trabalho em mente, podemos começar a entender por que o CAG se tornou cada vez mais atraente para certas aplicações, especialmente quando velocidade e eficiência são prioridades.
O principal ponto forte do CAG é a eficiência dele. Como o modelo reutiliza cálculos armazenados em cache, os tempos de resposta melhoram bastante, reduzindo a latência, principalmente em situações em que as consultas são repetitivas ou os requisitos de conhecimento continuam estáveis. É aqui que a CAG realmente se destaca:
Rapidez e eficiência: Reutilizar cálculos armazenados em cache melhora bastante os tempos de resposta, principalmente para consultas repetitivas ou requisitos de conhecimento estáveis.
Consistência entre as sessões: Ao guardar o contexto anterior, o CAG evita respostas inconsistentes e garante a coerência. Isso o torna ideal para agentes conversacionais, automação de fluxo de trabalho ou chatbots de suporte ao cliente, onde consultas repetidas são comuns.
Menos complicações no sistema: Como o modelo não precisa fazer pesquisas externas com tanta frequência, o sistema geral é mais simples em comparação com o RAG.
Apesar dessas vantagens, nenhuma técnica é perfeita, e a CAG traz seus próprios desafios que as organizações precisam pensar com cuidado.
Informação desatualizada: Os dados armazenados em cache ficam desatualizados com o tempo, então esses sistemas podem não refletir as atualizações recentes ou mudanças dinâmicas nas bases de conhecimento.
Requisitos de memória pesados: Manter caches grandes exige muitos recursos computacionais. As organizações precisam equilibrar com cuidado o tamanho do cache com a memória disponível e a capacidade de processamento.
Gerenciamento complexo de cache: Garantir que as informações armazenadas em cache continuem precisas e sincronizadas em implantações distribuídas exige mecanismos de coordenação bem sofisticados — e essa complexidade aumenta conforme o sistema cresce.
Depois de dar uma olhada no RAG e no CAG separadamente, o próximo passo é comparar os dois diretamente e mostrar as diferenças importantes que influenciam como eles são usados na prática.
Então, qual você deve usar? Me perguntam isso o tempo todo, e minha resposta sincera é: depende do que você está construindo. Depois de trabalhar com as duas abordagens em diferentes projetos, percebi alguns padrões claros de p. Vou explicar o que aprendi com implementações reais.
|
Recurso |
RAG (Geração Aumentada por Recuperação) |
CAG (Geração Aumentada por Cache) |
|
Mecanismo central |
Just-in-Time: Pega os dados relevantes de um banco de dados externo durante a consulta. |
Pré-carregado: Carrega dados relevantes no contexto ou cache do modelo antes da consulta. |
|
Latência e velocidade |
Mais lento: Precisa de tempo pra procurar, pegar e processar documentos antes de dar uma resposta. |
Mais rápido: Acessa informações instantaneamente da memória, eliminando a sobrecarga de recuperação. |
|
Atualização do conhecimento |
Tempo real: Pode acessar dados atualizados há segundos (por exemplo, notícias de última hora, novas leis). |
Instantâneo: O conhecimento só é atualizado na última atualização do cache; corre o risco de ficar “desatualizado”. |
|
Melhor caso de uso |
Conjuntos de dados dinâmicos e enormes (por exemplo, jurisprudência, pesquisa médica, notícias). |
Conjuntos de dados estáveis e repetitivos (por exemplo, regras de conformidade, perguntas frequentes, procedimentos operacionais padrão). |
|
Escalabilidade |
Horizontal: Escala bem com grandes bancos de dados; limitado apenas pela velocidade de pesquisa. |
Limitado pela memória: Limitado pelo tamanho da janela de contexto do modelo e pela memória RAM disponível. |
|
Complexidade |
Alto: Precisa gerenciar bancos de dados vetoriais, incorporar pipelines e lógica de recuperação. |
Moderado: Precisa cuidar do ciclo de vida do cache, otimizar o contexto e garantir a eficiência da memória. |
|
Lidando com alucinações |
Fundamentos das respostas nos documentos recuperados (citações). |
Respostas fundamentadas em um contexto consistente e pré-carregado. |
O RAG e o CAG têm abordagens bem diferentes em relação ao acesso ao conhecimento. O RAG segue um modelo just-in-time: codifica a consulta do usuário, pesquisa um banco de dados vetorial, recupera documentos relevantes e, em seguida, os passa para a etapa de geração. Esse design garante o acesso às informações mais recentes, mas a etapa adicional de recuperação introduz latência.
Em termos de arquitetura, os sistemas RAG dependem de pipelines de várias etapas que juntam fragmentação de documentos, pesquisa vetorial e coordenação de recuperação. A divisão de documentos em partes deve manter o significado semântico e, ao mesmo tempo, ser eficiente para a recuperação, e a pesquisa vetorial geralmente depende de algoritmos aproximados de vizinho mais próximo para lidar com coleções grandes sem custos altos.
O CAG, por outro lado, funciona com pré-carregamento. Em vez de buscar novos conhecimentos, ele usa janelas de contexto estendidas e memória cache para reutilizar informações armazenadas anteriormente. Essa abordagem espacial reduz a latência porque o modelo recupera os dados da memória, em vez de um banco de dados externo.
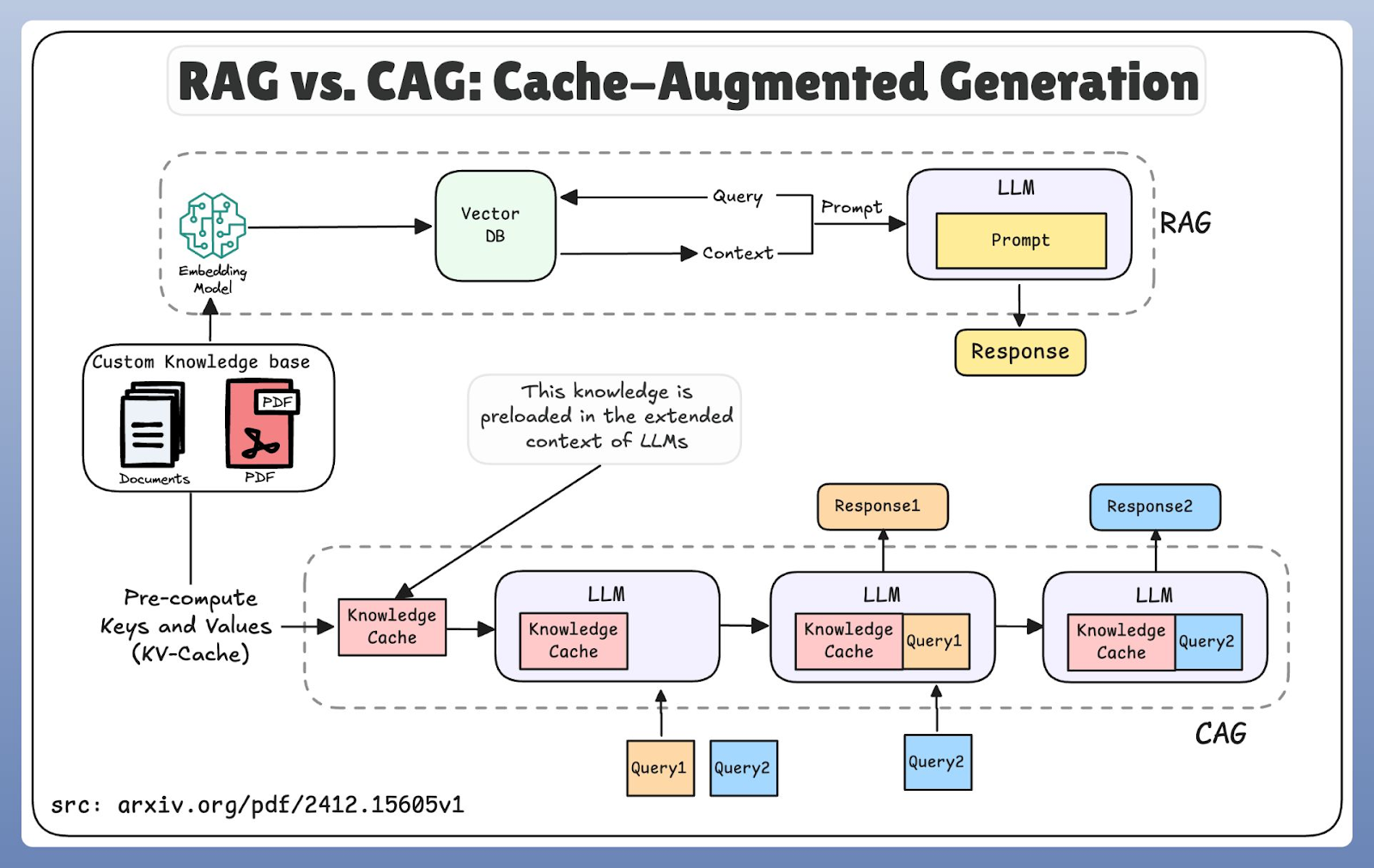
Comparando o fluxo de trabalho do RAG e do CAG
Mas, o problema é a atualização: as informações guardadas podem ficar para trás em relação às mudanças reais. Então, os sistemas CAG se concentram no gerenciamento inteligente do cache, usando estratégias para substituição do cache, alocação de memória e otimização da janela de contexto.
Já vi sistemas de produção em que essa escolha fez toda a diferença na implementação, e a eficácia dessas estratégias determina diretamente o desempenho e a escalabilidade do sistema.
Além da arquitetura técnica, tem uma questão prática que vale a pena discutir: como cada sistema lida com as mudanças.
Aqui está o que eu percebi sobre adaptabilidade:
Flexibilidade do RAG: O mecanismo de recuperação dinâmica permite que esses sistemas acessem novas informações imediatamente após a indexação. Já vi sistemas atualizarem sua base de conhecimento em tempo real, o que é perfeito para áreas que mudam rápido.
Rigidez do CAG: Informações pré-armazenadas significam mais consistência, mas menos adaptabilidade. Embora isso ofereça velocidade e comportamento previsível, ele tem dificuldade com consultas inesperadas que não foram previstas durante a preparação do cache.
Pelo que eu percebi, essa diferença é mais importante quando o seu domínio é imprevisível ou está sempre mudando.
Agora vamos falar sobre precisão e como cada abordagem lida com a tendência da IA de inventar coisas.
As duas técnicas lidam com alucinações de maneiras diferentes, dependendo de como são feitas. Os sistemas RAG ajudam a reduzir as alucinações, baseando as respostas em informações reais recuperadas, o que dá uma validação externa para o conteúdo gerado.
Os sistemas CAG diminuem as alucinações por meio do acesso consistente a informações verificadas e armazenadas em cache. Mas, se as informações guardadas no cache tiverem erros ou ficarem desatualizadas, esses erros podem continuar aparecendo em várias interações.
É na hora de pensar na implantação da produção em grande escala que a coisa fica séria. Essas são algumas das desvantagens de desempenho que eu encontrei:
Sistemas RAG: Maior latência por causa da sobrecarga de recuperação, mas dá pra escalar horizontalmente adicionando capacidade de recuperação e distribuindo bancos de dados vetoriais. Na prática, já vi isso funcionar bem depois que você investe na infraestrutura.
Sistemas CAG: Tem tempos de resposta bem rápidos, mas a escalabilidade é limitada pela memória. O gargalo geralmente surge quando a sobrecarga do gerenciamento do cache cresce mais rápido do que a sua memória permite.
A questão da escalabilidade raramente é simples. Depende muito dos seus padrões de consulta e dos recursos disponíveis.
Tá bom, chega de teoria. Vamos ser práticos. Depois de usar as duas abordagens em projetos diferentes, aqui está a minha estrutura para decidir qual usar.
É assim que eu geralmente ajudo as equipes a tomar essa decisão. As organizações devem avaliar a volatilidade das suas informações, os requisitos de latência, as necessidades de consistência e a disponibilidade de recursos ao escolher entre RAG e CAG. A alta volatilidade das informações favorece o RAG, enquanto os domínios de conhecimento estáveis se beneficiam da eficiência do CAG.
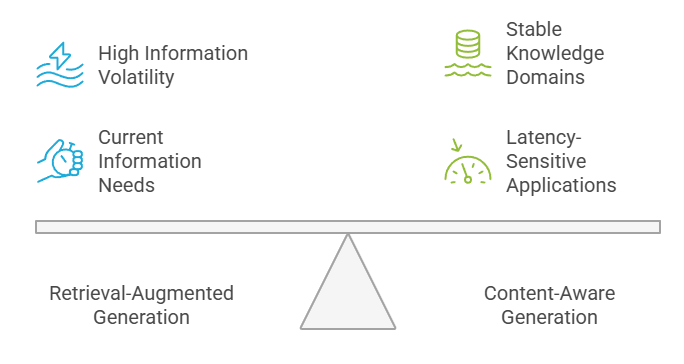
Estrutura de decisão: RAG vs. CAG
Aplicativos sensíveis à latência geralmente funcionam melhor com sistemas CAG, enquanto aplicativos que precisam das informações mais recentes devem usar os recursos do RAG. A decisão geralmente envolve equilibrar essas exigências conflitantes com base nas prioridades do negócio.
Escolha a RAG quando precisar de:
Informações dinâmicas e atualizadas com frequência: Aplicativos de pesquisa, suporte ao cliente para produtos em evolução ou plataformas de análise de notícias onde estar atualizado é mais importante do que ser rápido.
Bases de conhecimento grandes e diversificadas: Plataformas de pesquisa jurídica, sistemas de informação médica e aplicativos de inteligência competitiva. Pela minha experiência, se seus dados mudam todo dia ou toda semana, o RAG geralmente é a escolha certa.
Proteção contra informações desatualizadas: Quando o custo de servir dados obsoletos é maior do que o custo da latência adicional.
Costumo dizer aos clientes: se você está preocupado com a possibilidade de sua IA dar respostas desatualizadas, comece com o RAG. Você sempre pode otimizar a velocidade mais tarde. Se você optar pelo RAG, lembre-se de usar o para escolher a estrutura certa.
Escolha a CAG quando você tiver:
Requisitos de conhecimento estáveis: Chatbots de atendimento ao cliente que lidam com perguntas rotineiras, plataformas educacionais com currículos estabelecidos ou automação de fluxo de trabalho onde o conhecimento básico não muda muito.
Muitas consultas com padrões repetitivos: Se você está respondendo às mesmas 100 perguntas milhares de vezes por dia, a vantagem da velocidade do CAG se acumula rapidamente.
Aplicativos que exigem latência crítica: Sistemas de recomendação em tempo real, experiências de jogos interativos ou qualquer lugar onde milissegundos sejam importantes para a experiência do usuário.
Pelo que eu vi, o CAG é ideal quando você consegue prever 90% das suas consultas e sua base de conhecimento é relativamente estável.
Deixa eu te mostrar como isso funciona na prática. Trabalhei com (e estudei) implementações em diferentes setores, e alguns padrões claros surgiram. Aqui está o que realmente funciona na produção.
Vamos começar nossa análise do setor com a área da saúde, onde o acesso a informações precisas e oportunas é super importante.
Em aplicações na área da saúde, os sistemas RAG auxiliam na tomada de decisões clínicas, recuperando as últimas pesquisas médicas, protocolos de tratamento e informações sobre interações medicamentosas. Os profissionais médicos se beneficiam do acesso às diretrizes clínicas atuais e aos resultados de estudos recentes que podem não estar nos dados de treinamento do modelo.
Os sistemas CAG são super úteis em situações de saúde que precisam de acesso rápido a protocolos estabelecidos, resumos do histórico do paciente e procedimentos de diagnóstico padronizados, onde consistência e rapidez são essenciais.
Na minha opinião, a área da saúde é onde se vêem os casos mais evidentes de abordagens híbridas: CAG para protocolos padrão, RAG para qualquer coisa que mude.
Finanças é outro caso interessante. Aqui, os requisitos são completamente diferentes dos da área da saúde.
As instituições financeiras usam sistemas RAG para análise de mercado, monitoramento de conformidade regulatória e pesquisa de investimentos, onde o acesso a dados de mercado em tempo real e mudanças regulatórias recentes é super importante. Esses sistemas podem se conectar com bancos de dados financeiros e feeds de notícias para dar uma visão atual do mercado.
Por outro lado, os sistemas CAG são ótimos em aplicações financeiras que precisam de respostas rápidas para consultas de rotina, como cálculos financeiros padrão, definições de produtos e procedimentos de conformidade estabelecidos.
O que percebi nas finanças é que a decisão geralmente se resume ao risco regulatório. Se errar pode custar milhões em multas por não conformidade, as equipes tendem a optar pelo RAG.
A educação é outro terreno fértil tanto para o RAG quanto para o CAG.
As plataformas de aprendizagem personalizadas geralmente se beneficiam do RAG, já que os alunos precisam de acesso a conteúdos variados e sempre atualizados, incluindo novos artigos de pesquisa, materiais do curso ou até mesmo eventos atuais usados como exemplos de aprendizagem. Com o RAG, um tutor de IA pode fornecer referências precisas ou leituras complementares que não faziam parte do seu conjunto de treinamento original.
Já o CAG é ótimo pra situações em que repetição e consistência são essenciais. Por exemplo, quando uma plataforma oferece questionários regulares, explicações de conceitos padrão ou sessões de prática estruturadas, o cache garante um feedback mais rápido e consistente.
Assim, os sistemas educacionais costumam juntar as duas técnicas, combinando novas ideias com o reforço confiável do conhecimento básico.
No mundo do software, os desenvolvedores estão cada vez mais usando os dois métodos para melhorar a produtividade.
O RAG ajuda os desenvolvedores a encontrar documentação, especificações de API ou passos para resolver problemas em fontes externas. Como as bibliotecas ou estruturas de software podem mudar rapidamente, a camada de recuperação do RAG se destaca por garantir que as respostas permaneçam atualizadas.
Já o CAG é útil pra tarefas que dependem muito de interações repetidas, tipo autocompletar código, ajudar na depuração ou responder a perguntas recorrentes dos desenvolvedores. Ao armazenar em cache padrões vistos anteriormente, o CAG reduz a latência e acelera o fluxo de trabalho de desenvolvimento.
Juntas, essas abordagens permitem que os engenheiros trabalhem mais rápido, contando com orientações precisas e que levam em conta o contexto.
O setor jurídico é outro estudo de caso interessante de como essas abordagens lidam com desafios específicos do domínio, com diferentes padrões de acesso à informação.
Os profissionais do direito usam sistemas RAG para pesquisar jurisprudência e revisar contratos, onde é essencial ter acesso aos documentos contratuais e precedentes legais mais recentes. Isso permite que eles garantam que seus conselhos jurídicos reflitam as decisões judiciais e mudanças regulatórias mais recentes assim que forem publicadas.
Por outro lado, o CAG é a melhor escolha para monitoramento interno de conformidade e aplicação automatizada de políticas, principalmente quando as regras são fixas e as consultas são repetitivas. Em vez de pegar as mesmas “Diretrizes Antissuborno” ou “Artigo 15 do GDPR” milhares de vezes por dia, um sistema CAG já carrega essas estruturas regulatórias estáticas direto no contexto do modelo.
Como a “verdade” central (a lei) raramente muda no dia a dia, armazenar esse conhecimento elimina o gargalo de recuperação para 90% das consultas que são verificações de conformidade padrão.
No varejo e no comércio eletrônico, a rapidez e a relevância moldam diretamente a experiência do cliente.
O RAG é frequentemente usado para impulsionar pesquisas avançadas de produtos, integrar dados de estoque em tempo real e oferecer recomendações dinâmicas. Por exemplo, se um cliente perguntar se um produto está em estoque, um sistema habilitado para RAG pode verificar bancos de dados em tempo real para fornecer uma resposta atualizada.
Já o CAG garante respostas rápidas para as perguntas mais comuns dos clientes, como políticas de envio, regras de devolução ou atualizações do status dos pedidos. Ao reutilizar interações armazenadas em cache, o sistema fornece respostas instantâneas e reduz a carga do servidor.
Quando usados juntos, o RAG e o CAG criam uma experiência perfeita, oferecendo precisão e eficiência.
Até agora, a gente tratou o RAG e o CAG como técnicas diferentes. Na prática, porém, muitas organizações estão começando a adotar abordagens híbridas que juntam os dois métodos. Essa combinação permite equilibrar a novidade e a adaptabilidade do RAG com a rapidez e a eficiência do CAG.
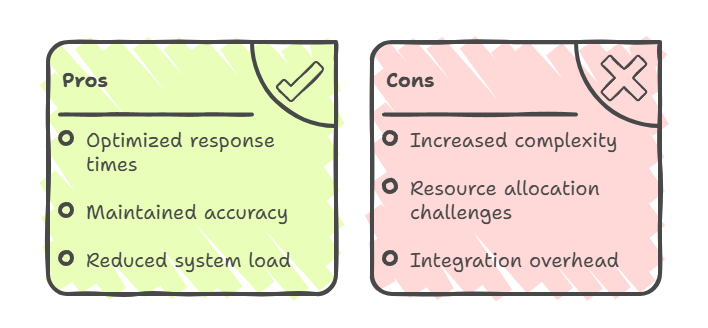
Abordagens híbridas: Prós e contras
Os sistemas híbridos são a próxima evolução na integração de conhecimento, juntando as capacidades dinâmicas de recuperação do RAG com as vantagens de eficiência do CAG.
Nesses modelos híbridos, o CAG é normalmente usado para informações estáveis e acessadas com frequência, enquanto o RAG é usado para consultas que precisam de dados em tempo real ou conhecimento especializado. Isso resulta no “melhor dos dois mundos”: tempos de resposta otimizados para consultas comuns, precisão mantida para conteúdo dinâmico e redução da carga geral do sistema por meio de roteamento inteligente.
Mas, as abordagens híbridas trazem mais complexidade arquitetônica. Eles exigem uma coordenação sofisticada entre os sistemas de armazenamento em cache e recuperação, além de um equilíbrio cuidadoso na alocação de recursos.
A sobrecarga de integração inclui gerenciar caminhos duplos de conhecimento, manter a sincronização entre dados armazenados em cache e recuperados e implementar uma lógica de roteamento inteligente que determina qual método usar para cada consulta.
Se você quer usar uma solução híbrida, precisa mesmo saber o que está fazendo.
Pela minha experiência, a adoção mais comum de arquiteturas híbridas hoje em dia é nos ecossistemas de atendimento ao cliente. Eu vejo muitas vezes plataformas onde o CAG lida com as perguntas frequentes estáticas e de alto volume para recuperação instantânea, enquanto o RAG é usado de forma seletiva para buscar detalhes de contas ativas ou histórico de transações.
Outro exemplo clássico pode ser encontrado em aplicativos de pesquisa, onde o CAG mantém o conhecimento básico em cache, enquanto o RAG busca as últimas publicações ou dados dinâmicos para novas consultas. Da mesma forma, nas plataformas de comércio eletrônico, o CAG lida com descrições ou políticas de produtos armazenadas em cache, enquanto o RAG integra níveis de estoque em tempo real e atualizações de preços.
Olha, não tem uma resposta certa pra todo mundo aqui, e quem disser o contrário provavelmente tá tentando te vender alguma coisa. A escolha entre RAG e CAG, ou a decisão de combiná-los, depende, em última análise, de seus requisitos, restrições e objetivos específicos.
O RAG é ótimo quando você precisa de acesso a informações dinâmicas e atualizadas e pode aceitar um pouco de latência em troca de precisão e atualização. O CAG é ótimo em situações onde a velocidade e a consistência são super importantes, e suas necessidades de conhecimento continuam relativamente estáveis.
No futuro, provavelmente veremos surgir abordagens híbridas mais sofisticadas que encaminham consultas de forma inteligente entre informações armazenadas em cache e recuperadas, otimizando tanto o desempenho quanto a precisão.
Para dominar todas as habilidades necessárias para projetar e implantar sistemas RAG, CAG ou híbridos, considere se inscrever em nossa carreira abrangente de Engenheiro de IA.considere se inscrever no nosso programa abrangente de Engenheiro de IA.
Cursos de IA generativa
Programa
Programa
Curso
blog
Natassha Selvaraj
10 min
blog
Javier Canales Luna
14 min
blog
Abid Ali Awan
11 min
blog
Natasha Al-Khatib
14 min
Tutorial
Ryan Ong
