
Track
Associate AI Engineer for Developers
26 hr
As artificial intelligence continues to evolve, one of the central challenges has been figuring out how to integrate knowledge effectively into Large Language Models (LLMs), considering their limited knowledge. To overcome these limitations, researchers and practitioners have explored different approaches to knowledge integration.
Two of the most important approaches today are retrieval-augmented generation, or RAG, and cache-augmented generation, or CAG. I've worked with both approaches, and while they're often presented as competitors, I've found they're more like different tools for different jobs—sometimes even better when used together.
In this article, I will walk you through a comparison of RAG and CAG, exploring what each concept means, how they work, and where they fit best in real-world applications. By the end, you will see how these approaches differ, where they overlap, and how to decide between them, or even combine them, when designing AI systems.
If you want to go beyond concepts and start building these systems yourself, I recommend taking our hands-on course, Retrieval Augmented Generation (RAG) with LangChain.
Retrieval-augmented generation is a technique that enables AI models to reach beyond their fixed training data and incorporate external information dynamically. Instead of relying solely on what was encoded into the model during training,
RAG connects the model to external databases and retrieval mechanisms, allowing it to fetch relevant documents or knowledge at the time of a query.
This idea grew in popularity as organizations realized that static training data quickly becomes outdated. I've seen how information changes daily in many industries, and a model without an external retrieval layer cannot keep up.
RAG was developed to address this gap and bring fresh, domain-specific, or dynamic knowledge directly into the generation process.
The RAG workflow begins with a user query. The query is first encoded into a vector representation, which is then used to search a vector database (retrieval system) containing documents, records, or other knowledge sources. This retrieval stage ensures that the model identifies the most relevant external information before proceeding.
Efficient chunking strategies are vital at this stage: documents are broken into smaller units of meaning, typically ranging from 100 to 1,000 tokens, so that the retrieval system can surface the most relevant context without overwhelming the generation model.
Retrieval algorithms, often based on approximate nearest neighbor search, ensure that relevant chunks are retrieved quickly, even from large-scale knowledge bases.
Once relevant documents are retrieved, they are passed to the generation stage, where the language model integrates this information into its response. The process allows the system to produce answers that are not only more coherent but also grounded in external, up-to-date knowledge.
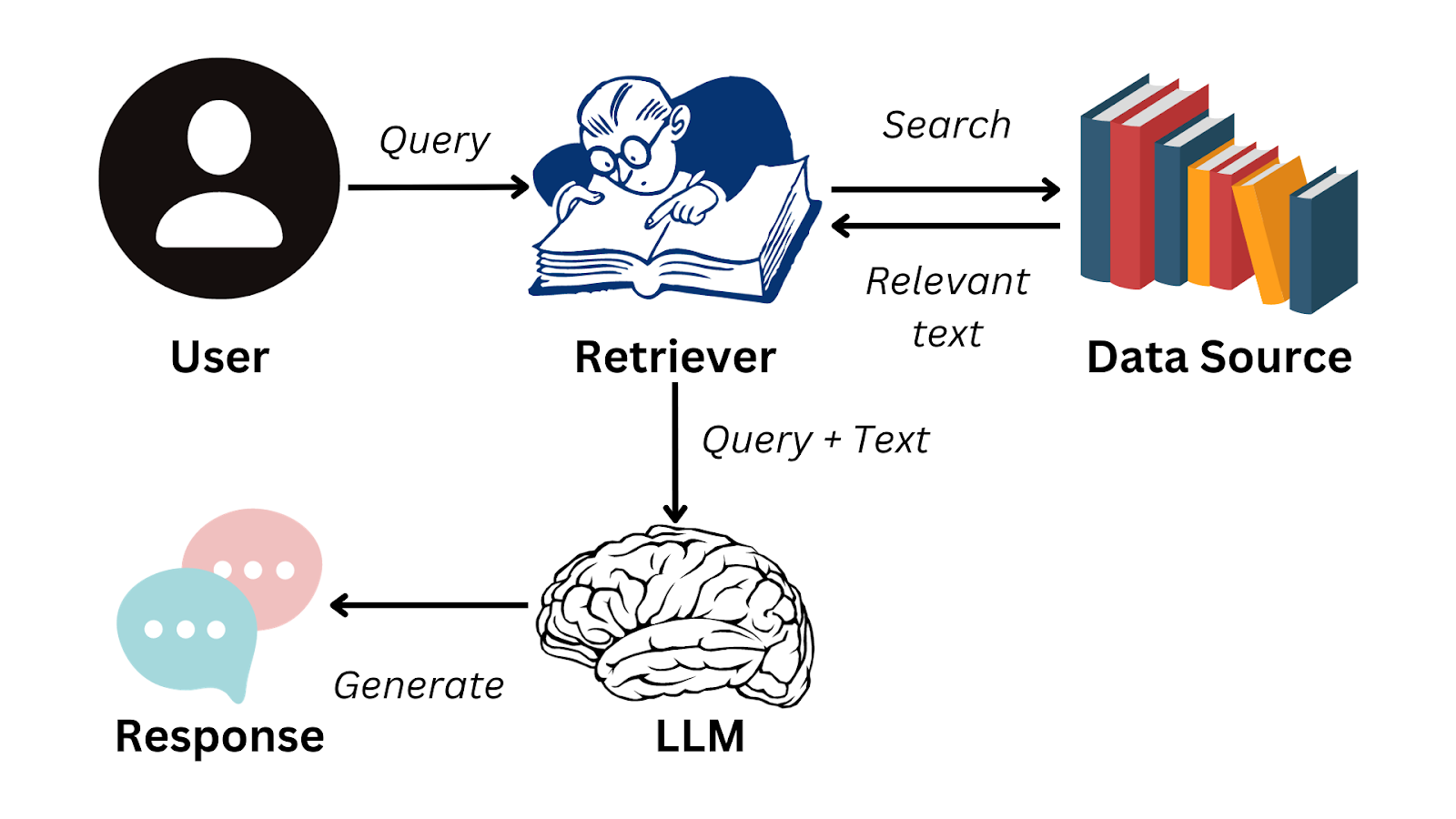
RAG workflow
The external knowledge sources might include proprietary databases, scientific papers, legal archives, or even real-time APIs. The retrieval engine is the bridge that allows the language model to combine its generative ability with factual data. Think of it like giving your AI a library card instead of hoping it memorized every book.
This basic structure can be refined by applying advanced RAG techniques or using Corrective RAG (CRAG), an improved version of RAG optimized for accuracy.
Now that we’ve examined how RAG is structured and operates, it becomes easier to evaluate what makes this method particularly powerful in real-world scenarios.
What I love most about RAG is how it handles change. Your legal department updates a policy at 3 PM? Your RAG system knows about it by 3:01 PM—no retraining required.
From my experience, RAG excels in three main areas:
Real-time updates: The retrieval layer connects to external knowledge, providing answers based on the latest data. This makes RAG especially valuable in fast-changing fields like medicine, finance, or technology.
Fewer hallucinations: LLMs often generate text that sounds plausible but is factually incorrect. By grounding answers in retrieved documents, RAG ensures the output has a factual anchor, increasing trustworthiness.
Flexible data integration: External knowledge can come from multiple sources, such as structured databases, semi-structured APIs, or unstructured text repositories. Organizations can tailor retrieval pipelines to their specific needs.
While RAG offers compelling advantages, it's equally important to understand the challenges and constraints that come with this approach.
Here's where it gets tricky, and this is what I warn my clients about upfront. RAG comes with real trade-offs:
System complexity: You need to orchestrate the retrieval system, vector database, and generation model. This complexity creates additional points of failure and increases maintenance overhead.
Latency issues: The retrieval process adds computational overhead to each query. Searching through large knowledge bases and retrieving relevant documents takes time, which can hurt user experience in real-time applications.
Retrieval quality dependency: Your responses are only as good as your retrieval mechanism. Poor retrieval means irrelevant context gets fed to the language model, potentially degrading response quality.
However, there are several key techniques to improve RAG performance and deal with these problems effectively.
After exploring the retrieval-focused approach, I’ll now turn to cache-augmented generation, which takes a very different path toward enhancing model performance.
CAG is the newer kid on the block, and honestly, it took me a while to appreciate its elegance. Instead of constantly fetching information like RAG, CAG preloads what you need and keeps it ready.
Unlike RAG's dynamic retrieval approach, CAG focuses on pre-loading and maintaining relevant information in the model's extended context or cache memory. The following graphic compares both approaches:
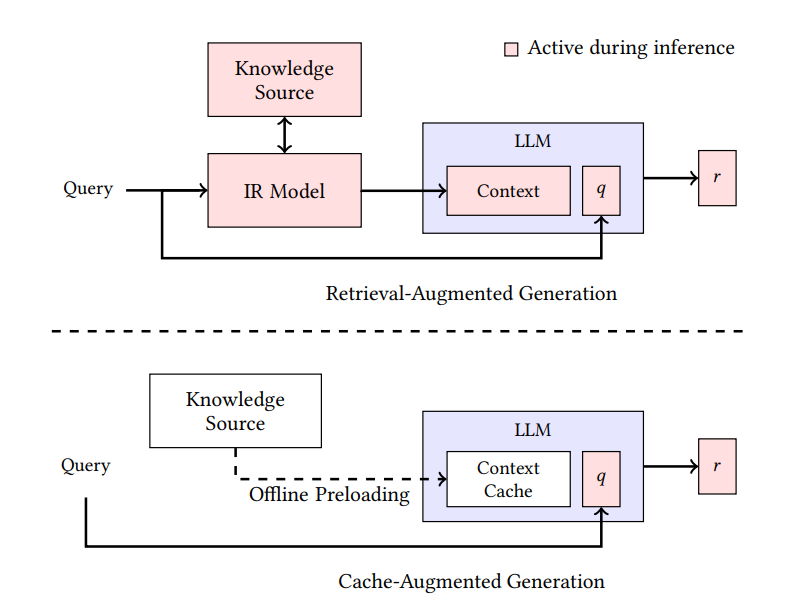
RAG and CAG architectures compared
CAG has gained prominence with the development of language models supporting increasingly larger context windows, sometimes extending to millions of tokens. It's like the difference between looking up every answer in a reference book versus having a cheat sheet you've already prepared.
CAG relies on two complementary caching mechanisms.
First, knowledge caching occurs when relevant documents or reference materials are preloaded into the model’s extended context window. Once stored, the model can reuse this information across multiple queries without needing to fetch it externally, as RAG systems do.
Second, key-value (KV) caching focuses on efficiency by storing the attention states (key and value matrices) generated as the model processes tokens. When a similar or repeated query arrives, the model can reuse these cached states instead of recomputing them from scratch.
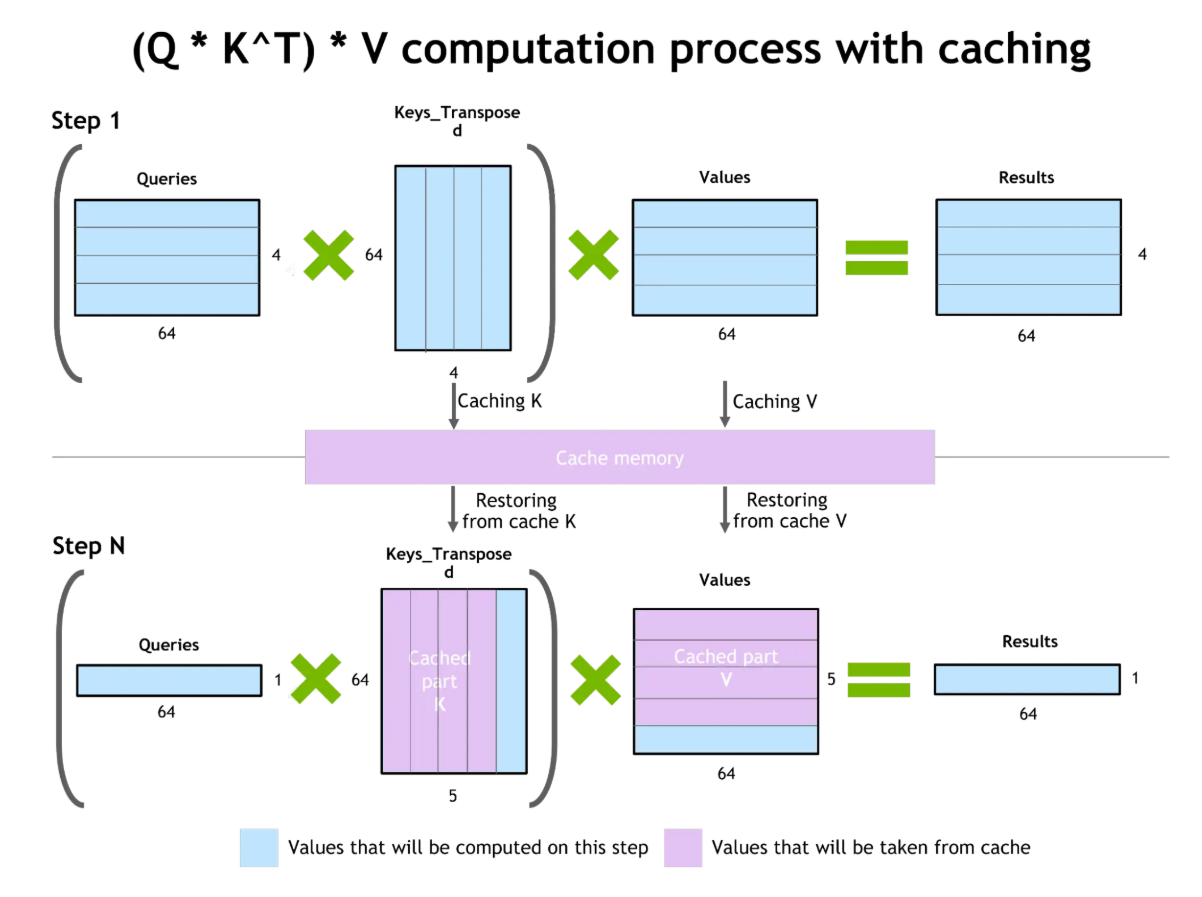
This mechanism reduces latency and allows the model to maintain longer-term context across conversations. The workflow expands the system's effective memory, enabling it to handle more extensive dialogue histories or repetitive queries without having to start from scratch each time.
The core idea is that caching extends the practical limits of what a model can remember. By persisting information and referencing it quickly, CAG creates an experience of continuity across longer conversations.
With this workflow in mind, we can start to see why CAG has become increasingly attractive for certain applications, especially when speed and efficiency are top priorities
The primary strength of CAG lies in its efficiency. Because the model reuses cached computations, response times improve significantly, reducing latency, particularly in scenarios where queries are repetitive or knowledge requirements remain stable. Here's where CAG really shines:
Speed and efficiency: Reusing cached computations drastically improves response times, especially for repetitive queries or stable knowledge requirements.
Consistency across sessions: By storing prior context, CAG avoids drifting responses and ensures coherence. This makes it ideal for conversational agents, workflow automation, or customer support chatbots where repeated queries are common.
Lower system complexity: Since the model doesn't need to perform external lookups as frequently, the overall system is simpler compared to RAG.
Despite these advantages, no technique is without trade-offs, and CAG introduces its own unique set of challenges that organizations must carefully consider.
Stale information: Cached data becomes outdated over time, so these systems may not reflect recent updates or dynamic changes in knowledge bases.
Heavy memory requirements: Maintaining large caches requires substantial computational resources. Organizations must carefully balance cache size with available memory and processing capabilities.
Complex cache management: Ensuring cached information remains accurate and synchronized across distributed deployments requires sophisticated coordination mechanisms—and this complexity grows as the system scales.
Having examined both RAG and CAG individually, the next step is to compare them directly and highlight the critical differences that shape their adoption in practice.
So, which one should you actually use? I'm asked this question constantly, and my honest answer is: it depends on what you're building. After working with both approaches across different projects, I've noticed some clear patterns. Let me break down what I've learned from real implementations.
|
Feature |
RAG (Retrieval-Augmented Generation) |
CAG (Cache-Augmented Generation) |
|
Core Mechanism |
Just-in-Time: Fetches relevant data from an external database during the query. |
Pre-Loaded: Loads relevant data into the model's context or cache before the query. |
|
Latency & Speed |
Slower: Requires time to search, retrieve, and process documents before generating an answer. |
Fastest: Accesses information instantly from memory, eliminating retrieval overhead. |
|
Knowledge Freshness |
Real-Time: Can access data updated seconds ago (e.g., breaking news, new laws). |
Snapshot: Knowledge is only as fresh as the last cache update; risks being "stale." |
|
Best Use Case |
Dynamic, massive datasets (e.g., Case Law, Medical Research, News). |
Stable, repetitive datasets (e.g., Compliance Rules, FAQs, Standard Operating Procedures). |
|
Scalability |
Horizontal: Scales well with vast databases; limited only by search speed. |
Memory-Bound: Limited by the model's context window size and available RAM. |
|
Complexity |
High: Requires managing vector databases, embedding pipelines, and retrieval logic. |
Moderate: Requires managing cache lifecycle, context optimization, and memory efficiency. |
|
Handling Hallucinations |
Grounds answers in retrieved documents (citations). |
Grounds answers in consistent, pre-loaded context. |
RAG and CAG take fundamentally different approaches to knowledge access. RAG follows a just-in-time model: it encodes the user’s query, searches a vector database, retrieves relevant documents, and then passes them to the generation stage. This design ensures access to the most recent information, but the additional retrieval step introduces latency.
Architecturally, RAG systems rely on multi-stage pipelines that combine document chunking, vector search, and retrieval coordination. Document chunking must preserve semantic meaning while remaining efficient for retrieval, and vector search often depends on approximate nearest neighbor algorithms to handle large-scale collections without high cost.
CAG, by contrast, operates through pre-loading. Instead of reaching outward for new knowledge, it relies on extended context windows and cache memory to reuse previously stored information. This spatial approach reduces latency because the model retrieves from memory rather than an external database.
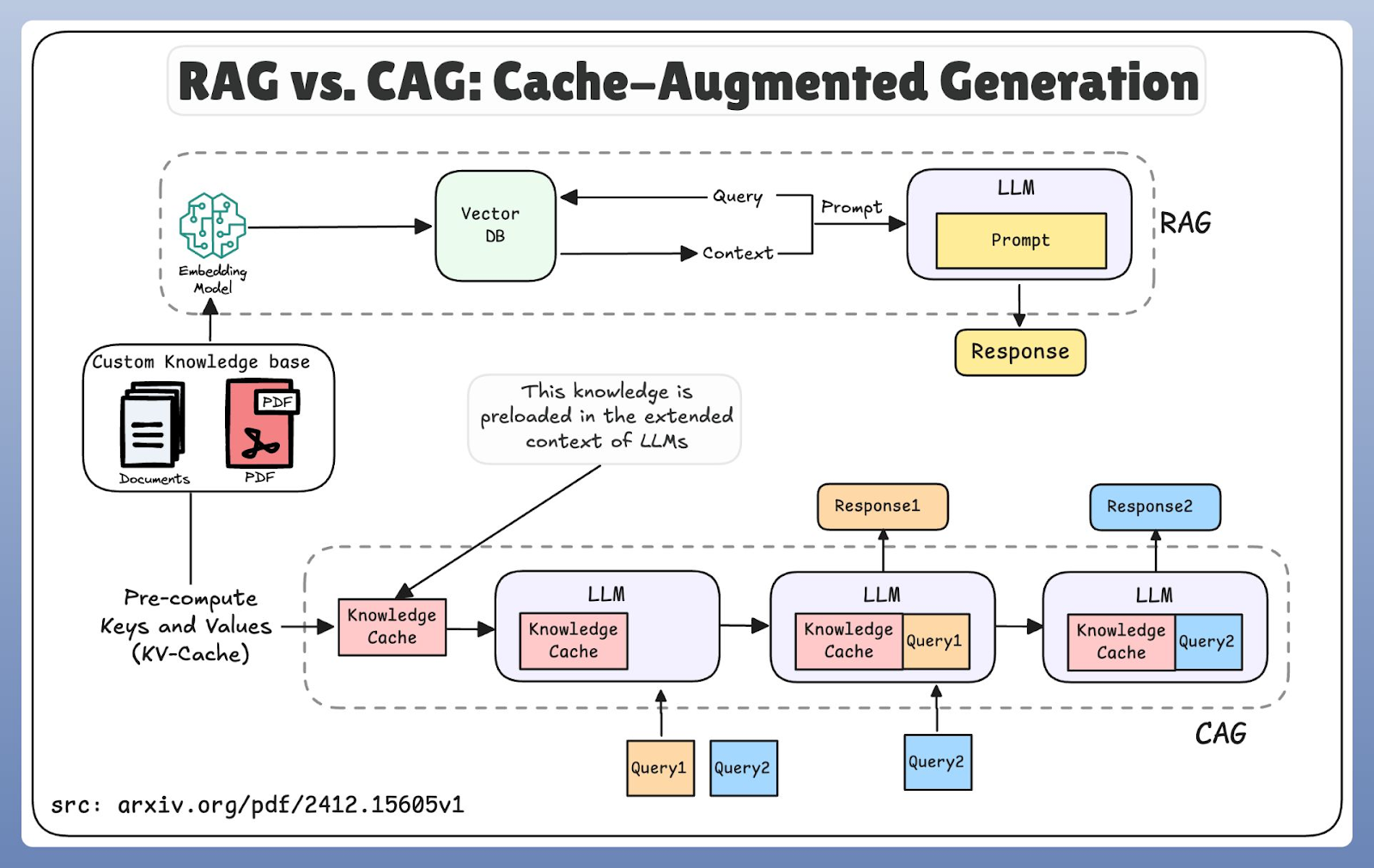
RAG and CAG workflow comparison
However, the trade-off is freshness: cached information may lag behind real-world updates. Therefore, CAG systems focus on intelligent cache management, using strategies for cache replacement, memory allocation, and context window optimization.
I've seen production systems where this trade-off made or broke the implementation, and the effectiveness of these strategies directly determines both the performance and scalability of the system.
Beyond the technical architecture, there's a practical dimension worth discussing: how each system handles change.
Here's what I've observed about adaptability:
RAG's flexibility: The dynamic retrieval mechanism lets these systems access new information immediately upon indexing. I've watched systems update their knowledge base in real-time, perfect for rapidly evolving domains.
CAG's rigidity: Pre-cached information means more consistency but less adaptability. While this provides speed and predictable behavior, it struggles with unexpected queries that weren't anticipated during cache preparation.
From what I've seen, this difference matters most when your domain is unpredictable or constantly evolving.
Now let's talk about accuracy and how each approach deals with AI's tendency to make things up.
Both techniques address hallucinations differently based on their underlying architectures. RAG systems mitigate hallucinations by grounding responses in retrieved factual information, providing external validation for generated content.
CAG systems reduce hallucinations through consistent access to verified, cached information. However, if the cached information contains inaccuracies or becomes outdated, these errors may persist across multiple interactions.
The rubber really meets the road when you're thinking about production deployment at scale. These are some of the performance trade-offs I've encountered:
RAG systems: Higher latency due to retrieval overhead, but you can scale horizontally by adding retrieval capacity and distributing vector databases. In practice, I've seen this work well once you invest in the infrastructure.
CAG systems: Superior response times but memory-constrained scalability. The bottleneck usually hits when cache management overhead grows faster than your memory budget allows.
The scalability question is rarely simple. It depends heavily on your query patterns and available resources.
Alright, enough theory. Let's get practical. After implementing both approaches across different projects, here's my framework for deciding which one to use.
Here's how I typically guide teams through this decision. Organizations should assess their information volatility, latency requirements, consistency needs, and resource availability when choosing between RAG and CAG. High information volatility favors RAG, while stable knowledge domains benefit from CAG's efficiency.
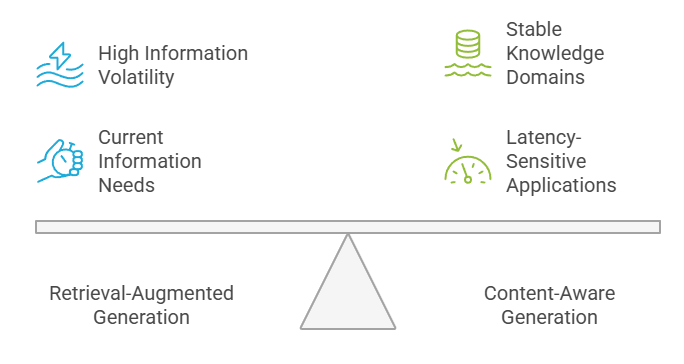
Decision Framework: RAG vs. CAG
Latency-sensitive applications typically perform better with CAG systems, whereas applications requiring the most current information should leverage RAG capabilities. The decision often involves balancing these competing requirements based on business priorities.
Choose RAG when you need:
Dynamic, frequently updated information: Research applications, customer support for evolving products, or news analysis platforms where being current matters more than being fast.
Large, diverse knowledge bases: Legal research platforms, medical information systems, and competitive intelligence applications. In my experience, if your data changes daily or weekly, RAG is usually the right call.
Protection against outdated information: When the cost of serving stale data is higher than the cost of added latency.
I usually tell clients: if you're worried about your AI giving outdated answers, start with RAG. You can always optimize for speed later. If you go with RAG, remember to choose the right framework.
Choose CAG when you have:
Stable knowledge requirements: Customer service chatbots handling routine inquiries, educational platforms with established curricula, or workflow automation where the core knowledge doesn't change much.
High query volumes with repetitive patterns: If you're answering the same 100 questions thousands of times per day, CAG's speed advantage compounds quickly.
Latency-critical applications: Real-time recommendation systems, interactive gaming experiences, or anywhere milliseconds matter to user experience.
From what I've seen, CAG is ideal when you can predict 90% of your queries, and your knowledge base is relatively stable.
Let me show you how this plays out in practice. I've worked with (and studied) implementations across different industries, and some clear patterns have emerged. Here's what actually works in production.
Let's begin our industry analysis with healthcare, where the stakes of accessing accurate and timely information are particularly high.
In healthcare applications, RAG systems support clinical decision-making by retrieving the latest medical research, treatment protocols, and drug interaction information. Medical professionals benefit from access to current clinical guidelines and recent study findings that might not be included in the model's training data.
CAG systems prove valuable in healthcare scenarios requiring quick access to established protocols, patient history summaries, and standardized diagnostic procedures where consistency and speed are paramount.
In my opinion, healthcare is where you see the clearest case for hybrid approaches: CAG for standard protocols, RAG for anything that changes.
Finance is another interesting case. Here, the requirements are completely different from those in healthcare.
Financial institutions use RAG systems for market analysis, regulatory compliance monitoring, and investment research, where access to real-time market data and recent regulatory changes is crucial. These systems can integrate with financial databases and news feeds to provide current market insights.
On the other hand, CAG systems excel in financial applications requiring rapid responses to routine inquiries, such as standard financial calculations, product definitions, and established compliance procedures.
What I've noticed in finance is that the decision often comes down to regulatory risk. If being wrong could cost millions in compliance fines, teams lean toward RAG.
Education provides another fertile ground for both RAG and CAG.
Personalized learning platforms often benefit from RAG, since students require access to diverse and constantly updated content, including new research articles, course materials, or even current events used as learning examples. With RAG, an AI tutor can provide accurate references or supplementary readings that were not part of its original training set.
CAG, by contrast, performs well in situations where repetition and consistency are key. For instance, when a platform delivers regular quizzes, explanations of standard concepts, or structured practice sessions, caching ensures faster and more consistent delivery of feedback.
In this way, education systems often combine both techniques, combining fresh insights with reliable reinforcement of core knowledge.
Shifting to the world of software, developers are increasingly adopting both methods to improve productivity.
RAG supports developers by retrieving documentation, API specifications, or troubleshooting steps from external sources. Since software libraries or frameworks can change quickly, RAG’s retrieval layer shines in ensuring that answers remain current.
CAG, meanwhile, plays a role in tasks that rely heavily on repeated interactions, such as code autocompletion, debugging assistance, or responding to recurring developer queries. By caching previously seen patterns, CAG reduces latency and accelerates the development workflow.
Together, these approaches enable engineers to move faster while relying on accurate and context-aware guidance.
The legal sector presents another fascinating case study in how these approaches address domain-specific challenges with different information access patterns.
Legal professionals utilize RAG systems for case law research and contract review, where access to the most recent contract documents and legal precedents is essential. It enables them to ensure their legal advice reflects the very latest court decisions and regulatory changes as soon as they are published.
Conversely, CAG is the superior choice for internal compliance monitoring and automated policy enforcement, particularly when the rules are fixed and the queries are repetitive. Instead of retrieving the same "Anti-Bribery Guidelines" or "GDPR Article 15" thousands of times a day, a CAG system pre-loads these static regulatory frameworks directly into the model's context.
Because the core "truth" (the law) rarely changes day-to-day, caching this knowledge eliminates the retrieval bottleneck for 90% of queries that are standard compliance checks.
In retail and e-commerce, speed and relevance directly shape customer experience.
RAG is often deployed to power advanced product search, integrate live inventory data, and provide dynamic recommendations. For example, if a customer asks whether a product is in stock, a RAG-enabled system can check real-time databases to provide an up-to-date answer.
CAG, on the other hand, ensures fast responses to common customer questions, such as shipping policies, return rules, or order status updates. By reusing cached interactions, the system delivers instant answers and reduces server load.
When used together, RAG and CAG create a seamless experience offering both accuracy and efficiency.
Up to this point, we have treated RAG and CAG as separate techniques. In practice, however, many organizations are beginning to adopt hybrid approaches that integrate both methods. This combination allows them to balance the freshness and adaptability of RAG with the speed and efficiency of CAG.
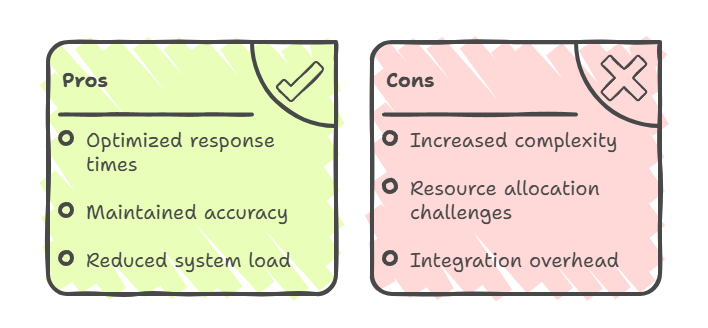
Hybrid Approaches: Pros and Cons
Hybrid systems represent the next evolution in knowledge integration, combining RAG's dynamic retrieval capabilities with CAG's efficiency benefits.
In these hybrid models, CAG is typically used for frequently accessed, stable information, while RAG is deployed for queries that require real-time data or specialized knowledge. This results in “the best of both worlds”: optimized response times for common queries, maintained accuracy for dynamic content, and reduced overall system load through intelligent routing.
However, hybrid approaches introduce increased architectural complexity. They require sophisticated orchestration between caching and retrieval systems, and demand careful balance in resource allocation.
The integration overhead includes managing dual knowledge pathways, maintaining synchronization between cached and retrieved data, and implementing intelligent routing logic that determines which method to use for each query.
If you want to go with a hybrid solution, you really need to know what you are doing.
In my experience, the most widespread adoption of hybrid architectures is currently found in customer service ecosystems. I frequently see platforms where CAG handles the high-volume, static FAQs for instant retrieval, while RAG is selectively deployed to fetch live account details or transaction history.
Another classic example can be found in research applications, where CAG maintains cached foundational knowledge while RAG retrieves the latest publications or dynamic data for new queries. Similarly, in e-commerce platforms, CAG handles cached product descriptions or policies, while RAG integrates real-time inventory levels and pricing updates.
Look, there's no universal right answer here, and anyone who tells you otherwise is probably selling something. The choice between RAG and CAG, or the decision to combine them, ultimately depends on your specific requirements, constraints, and goals.
RAG excels when you need access to dynamic, up-to-date information and can tolerate some latency in exchange for accuracy and freshness. CAG shines in scenarios where speed and consistency matter most, and your knowledge requirements remain relatively stable.
In the future, we'll likely see more sophisticated hybrid approaches surface that intelligently route queries between cached and retrieved information, optimizing for both performance and accuracy.
To master the complete skillset required to design and deploy RAG, CAG, or hybrid systems, consider enrolling in our comprehensive AI Engineer career track.
Generative AI Courses
Track
Track
Course
blog
Natassha Selvaraj
10 min
blog
Bhavishya Pandit
6 min
blog
Oluseye Jeremiah
10 min
blog
Stanislav Karzhev
12 min
Tutorial
Eugenia Anello
Tutorial
Iván Palomares Carrascosa
