Hyperparameter Tuning in Python
BeginnerSkill Level
4 hr
18.8K learners
The best way to think about hyperparameters is like the settings of an algorithm that can be adjusted to optimize performance, just as you might turn the knobs of an AM radio to get a clear signal. When creating a machine learning model, you'll be presented with design choices as to how to define your model architecture. Often, you don't immediately know what the optimal model architecture should be for a given model, and thus you'd like to be able to explore a range of possibilities. In a true machine learning fashion, you’ll ideally ask the machine to perform this exploration and select the optimal model architecture automatically.
You will see in the case study section on how the right choice of hyperparameter values affect the performance of a machine learning model. In this context, choosing the right set of values is typically known as “Hyperparameter optimization” or “Hyperparameter tuning”.
Models can have many hyperparameters and finding the best combination of parameters can be treated as a search problem.
Although there are many hyperparameter optimization/tuning algorithms now, this post discusses two simple strategies: 1. grid search and 2. Random Search.
Grid search is an approach to hyperparameter tuning that will methodically build and evaluate a model for each combination of algorithm parameters specified in a grid.
Let’s consider the following example:
Suppose, a machine learning model X takes hyperparameters a1, a2 and a3. In grid searching, you first define the range of values for each of the hyperparameters a1, a2 and a3. You can think of this as an array of values for each of the hyperparameters. Now the grid search technique will construct many versions of X with all the possible combinations of hyperparameter (a1, a2 and a3) values that you defined in the first place. This range of hyperparameter values is referred to as the grid.
Suppose, you defined the grid as:
a1 = [0,1,2,3,4,5]
a2 = [10,20,30,40,5,60]
a3 = [105,105,110,115,120,125]
Note that, the array of values of that you are defining for the hyperparameters has to be legitimate in a sense that you cannot supply Floating type values to the array if the hyperparameter only takes Integer values.
Now, grid search will begin its process of constructing several versions of X with the grid that you just defined.
It will start with the combination of [0,10,105], and it will end with [5,60,125]. It will go through all the intermediate combinations between these two which makes grid search computationally very expensive.
Let’s take a look at the other search technique Random search:
The idea of random searching of hyperparameters was proposed by James Bergstra & Yoshua Bengio. You can check the original paper here.
Random search differs from a grid search. In that you longer provide a discrete set of values to explore for each hyperparameter; rather, you provide a statistical distribution for each hyperparameter from which values may be randomly sampled.
Before going any further, let’s understand what distribution and sampling mean:
In Statistics, by distribution, it is essentially meant an arrangement of values of a variable showing their observed or theoretical frequency of occurrence.
On the other hand, Sampling is a term used in statistics. It is the process of choosing a representative sample from a target population and collecting data from that sample in order to understand something about the population as a whole.
Now let's again get back to the concept of random search.
You’ll define a sampling distribution for each hyperparameter. You can also define how many iterations you’d like to build when searching for the optimal model. For each iteration, the hyperparameter values of the model will be set by sampling the defined distributions. One of the primary theoretical backings to motivate the use of a random search in place of grid search is the fact that for most cases, hyperparameters are not equally important. According to the original paper:
“….for most datasets only a few of the hyper-parameters really matter, but that different hyper-parameters are important on different datasets. This phenomenon makes grid search a poor choice for configuring algorithms for new datasets.”
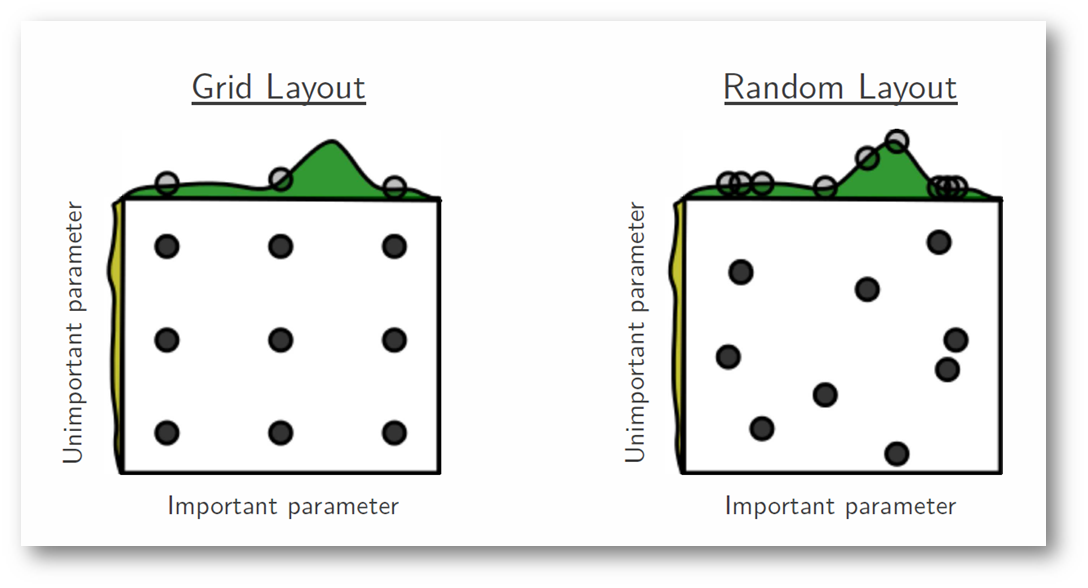
In the following figure, we're searching over a hyperparameter space where the one hyperparameter has significantly more influence on optimizing the model score - the distributions shown on each axis represent the model's score. In each case, we're evaluating nine different models. The grid search strategy blatantly misses the optimal model and spends redundant time exploring the unimportant parameter. During this grid search, we isolated each hyperparameter and searched for the best possible value while holding all other hyperparameters constant. For cases where the hyperparameter being studied has little effect on the resulting model score, this results in wasted effort. Conversely, the random search has much improved exploratory power and can focus on finding the optimal value for the critical hyperparameter.
In the following sections, you will see grid search and random search in action with Python. You will also be able to decide which is better regarding the effectiveness and efficiency.
Hyperparameter tuning is a final step in the process of applied machine learning before presenting results.
You will use the Pima Indian diabetes dataset. The dataset corresponds to a classification problem on which you need to make predictions on the basis of whether a person is to suffer diabetes given the 8 features in the dataset. You can find the complete description of the dataset here.
There are a total of 768 observations in the dataset. Your first task is to load the dataset so that you can proceed. But before that let's import the dependencies, you are going to need.
# Dependencies
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
Now that the dependencies are imported let's load Pima Indians dataset into a Dataframe object with the famous Pandas library.
data = pd.read_csv("diabetes.csv") # Make sure the .csv file and the notebook are residing on the same directory otherwise supply an absolute path of the .csv file
The dataset is successfully loaded into the Dataframe object data. Now, let's take a look at the data.
data.head()

So you can 8 different features labeled into the outcomes of 1 and 0 where 1 stands for the observation has diabetes, and 0 denotes the observation does not have diabetes. The dataset is known to have missing values. Specifically, there are missing observations for some columns that are marked as a zero value. We can corroborate this by the definition of those columns, and the domain knowledge that a zero value is invalid for those measures, e.g., zero for body mass index or blood pressure is invalid.
(Missing value creates a lot of problems when you try to build a machine learning model. In this case, you will use a Logistic Regression classifier for predicting the patients having diabetes or not. Now, Logistic Regression cannot handle the problems of missing values. )
(If you want a quick refresher on Logistic Regression you can refer here.)
Let's get some statistics about the data with Pandas' describe() utility.
data.describe()

This is useful.
We can see that there are columns that have a minimum value of zero (0). On some columns, a value of zero does not make sense and indicates an invalid or missing value.
Specifically, the following columns have an invalid zero minimum value:
Now you need to identify and mark values as missing. Let’s confirm this by looking at the raw data, the example prints the first 20 rows of data.
data.head(20)

You can see 0 in several columns, right?
You can get a count of the number of missing values in each of these columns. You can do this by marking all of the values in the subset of the DataFrame you are interested in that have zero values as True. You can then count the number of true values in each column. For this, you will have to reimport the data without the column names.
data = pd.read_csv("https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv",header=None)
print((data[[1,2,3,4,5]] == 0).sum())
1 5
2 35
3 227
4 374
5 11
dtype: int64
You can see that columns 1,2 and 5 have just a few zero values, whereas columns 3 and 4 show a lot more, nearly half of the rows. Column 0 has several missing values although but that is natural. Column 8 denotes the target variable so, '0's in it is natural.
This highlights that different “missing value” strategies may be needed for different columns, e.g., to ensure that there are still a sufficient number of records left to train a predictive model.
In Python, specifically Pandas, NumPy and Scikit-Learn, you mark missing values as NaN.
Values with a NaN value are ignored from operations like sum, count, etc.
You can mark values as NaN easily with the Pandas DataFrame by using the replace() function on a subset of the columns you are interested in.
After you have marked the missing values, you can use the isnull() function to mark all of the NaN values in the dataset as True and get a count of the missing values for each column.
# Mark zero values as missing or NaN
data[[1,2,3,4,5]] = data[[1,2,3,4,5]].replace(0, np.NaN)
# Count the number of NaN values in each column
print(data.isnull().sum())
0 0
1 5
2 35
3 227
4 374
5 11
6 0
7 0
8 0
dtype: int64
You can see that the columns 1:5 have the same number of missing values as zero values identified above. This is a sign that you have marked the identified missing values correctly.
This is a useful summary. But you'd like to look at the actual data though, to confirm that you have not fooled yourselves.
Below is the same example, except you print the first 5 rows of data.
data.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148.0 | 72.0 | 35.0 | NaN | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85.0 | 66.0 | 29.0 | NaN | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183.0 | 64.0 | NaN | NaN | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89.0 | 66.0 | 23.0 | 94.0 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137.0 | 40.0 | 35.0 | 168.0 | 43.1 | 2.288 | 33 | 1 |
It is clear from the raw data that marking the missing values had the intended effect. Now, you will impute the missing values. Imputing refers to using a model to replace missing values. Although there are several solutions for imputing missing values, you will use mean imputation which means replacing the missing values in a column with the mean of that particular column. Let's do this with Pandas' fillna() utility.
# Fill missing values with mean column values
data.fillna(data.mean(), inplace=True)
# Count the number of NaN values in each column
print(data.isnull().sum())
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
dtype: int64
Cheers! You have now handled the missing value problem. Now let's use this data to build a Logistic Regression model using scikit-learn.
First, you will see the model with some random hyperparameter values. Then you will build two other Logistic Regression models with two different strategies - Grid search and Random search.
# Split dataset into inputs and outputs
values = data.values
X = values[:,0:8]
y = values[:,8]
# Initiate the LR model with random hyperparameters
lr = LogisticRegression(penalty='l1',dual=False,max_iter=110)
You have created the Logistic Regression model with some random hyperparameter values. The hyperparameters that you used are:
Later in the case study, you will optimize/tune these hyperparameters so see the change in the results.
# Pass data to the LR model
lr.fit(X,y)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=110, multi_class='ovr', n_jobs=1,
penalty='l1', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
It's time to check the accuracy score.
lr.score(X,y)
0.7747395833333334
In the above step, you applied your LR model to the same data and evaluated its score. But there is always a need to validate the stability of your machine learning model. You just can’t fit the model to your training data and hope it would accurately work for the real data it has never seen before. You need some kind of assurance that your model has got most of the patterns from the data correct.
Well, Cross-validation is there for rescue. I will not go into the details of it as it is out of the scope of this blog. But this post does a very fine job.
# You will need the following dependencies for applying Cross-validation and evaluating the cross-validated score
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# Build the k-fold cross-validator
kfold = KFold(n_splits=3, random_state=7)
You supplied n_splits as 3, which essentially makes it a 3-fold cross-validation. You also supplied random_state as 7. This is just to reproduce the results. You could have supplied any integer value as well. Now, let's apply this.
result = cross_val_score(lr, X, y, cv=kfold, scoring='accuracy')
print(result.mean())
0.765625
You can see there's a slight decrease in the score. Anyway, you can do better with hyperparameter tuning / optimization.
Let's build another LR model, but this time its hyperparameter will be tuned. You will first do this grid search.
Let's first import the dependencies you will need. Scikit-learn provides a utility called GridSearchCV for this.
from sklearn.model_selection import GridSearchCV
Let's define the grid values of the hyperparameters that you used above.
dual=[True,False]
max_iter=[100,110,120,130,140]
param_grid = dict(dual=dual,max_iter=max_iter)
You have defined the grid. Let's run the grid search over them and see the results with execution time.
import time
lr = LogisticRegression(penalty='l2')
grid = GridSearchCV(estimator=lr, param_grid=param_grid, cv = 3, n_jobs=-1)
start_time = time.time()
grid_result = grid.fit(X, y)
# Summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
print("Execution time: " + str((time.time() - start_time)) + ' ms')
Best: 0.752604 using {'dual': False, 'max_iter': 100}
Execution time: 0.3954019546508789 ms
You can define a larger grid of hyperparameter as well and apply grid search.
dual=[True,False]
max_iter=[100,110,120,130,140]
C = [1.0,1.5,2.0,2.5]
param_grid = dict(dual=dual,max_iter=max_iter,C=C)
lr = LogisticRegression(penalty='l2')
grid = GridSearchCV(estimator=lr, param_grid=param_grid, cv = 3, n_jobs=-1)
start_time = time.time()
grid_result = grid.fit(X, y)
# Summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
print("Execution time: " + str((time.time() - start_time)) + ' ms')
Best: 0.763021 using {'C': 2.0, 'dual': False, 'max_iter': 100}
Execution time: 0.793781042098999 ms
You can see an increase in the accuracy score, but there is a sufficient amount of growth in the execution time as well. The larger the grid, the more execution time.
Let's rerun everything but this time with the random search. Scikit-learn provides RandomSearchCV to do that. As usual, you will have to import the necessary dependencies for that.
from sklearn.model_selection import RandomizedSearchCV
random = RandomizedSearchCV(estimator=lr, param_distributions=param_grid, cv = 3, n_jobs=-1)
start_time = time.time()
random_result = random.fit(X, y)
# Summarize results
print("Best: %f using %s" % (random_result.best_score_, random_result.best_params_))
print("Execution time: " + str((time.time() - start_time)) + ' ms')
Best: 0.763021 using {'max_iter': 100, 'dual': False, 'C': 2.0}
Execution time: 0.28888916969299316 ms
Woah! The random search yielded the same accuracy but in a much lesser time.
That is all for the case study part. Now, let's wrap things up!
In this tutorial, you learned about parameters and hyperparameters of a machine learning model and their differences as well. You also got to know about what role hyperparameter optimization plays in building efficient machine learning models. You built a simple Logistic Regression classifier in Python with the help of scikit-learn.
You tuned the hyperparameters with grid search and random search and saw which one performs better.
Besides, you saw small data preprocessing steps (like handling missing values) that are required before you feed your data into the machine learning model. You covered Cross-validation as well.
That is a lot to take in, and all of them are equally important in your data science journey. I will leave you with some further readings that you can do.
Further readings:
For the ones who are a bit more advanced, I would highly recommend reading this paper for effectively optimizing the hyperparameters of neural networks. link
If you would like to learn more about Machine Learning, take the following courses from DataCamp:
Learn more about Machine Learning
Course
Course
Course
Tutorial
Nishant Singh
Tutorial
Zoumana Keita
Tutorial
Bunmi Akinremi
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes


