
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
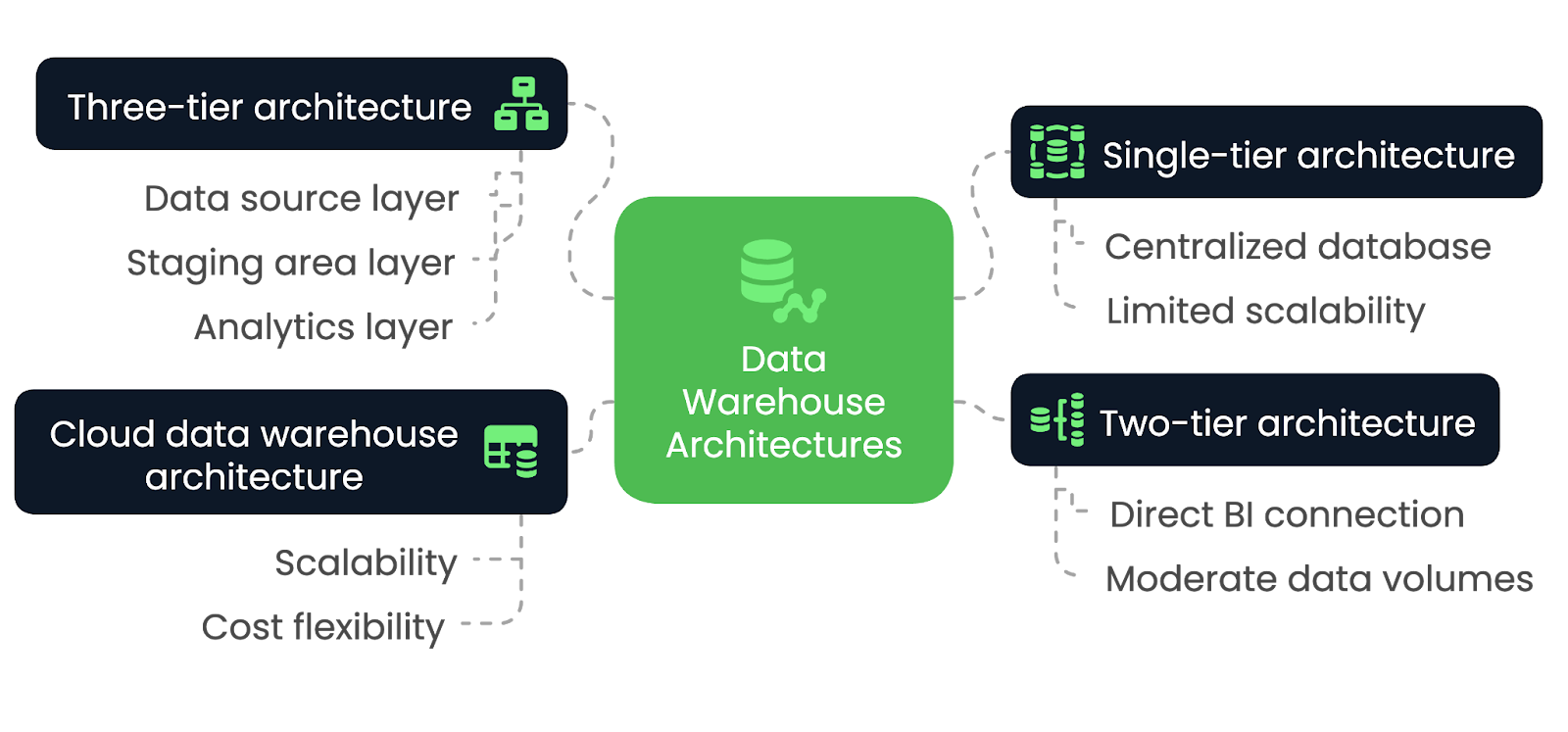
Die Wahl der richtigen Data-Warehouse-Architektur ist entscheidend für die Erfüllung der Leistungs-, Skalierbarkeits- und Integrationsanforderungen deines Unternehmens. Verschiedene Architekturen bieten jedoch einzigartige Vorteile und Kompromisse, die von verschiedenen Faktoren abhängen. In diesem Abschnitt wollen wir sie erkunden.
In einer einstufigen Architektur baut das Data Warehouse auf einer einzigen, zentralen Datenbank auf, die alle Daten aus verschiedenen Quellen in einem System zusammenführt. Diese Architektur minimiert die Anzahl der Schichten und vereinfacht das Gesamtdesign, was zu schnellerer Datenverarbeitung und schnellerem Zugriff führt. Allerdings fehlt ihr die Flexibilität und Modularität, die in komplexeren Architekturen zu finden ist.
Die einstufige Architektur eignet sich am besten für kleine Anwendungen und Unternehmen mit begrenztem Datenverarbeitungsbedarf. Sie ist ideal für Unternehmen, die Wert auf Einfachheit und schnelle Implementierung statt auf Skalierbarkeit legen. Wenn jedoch das Datenvolumen steigt oder fortschrittlichere Analysen erforderlich sind, kann diese Architektur diesen Anforderungen nicht mehr gerecht werden.
In einer zweistufigen Architektur ist das Data Warehouse direkt mit BI-Tools verbunden, oft überein OLAP-System. Dieser Ansatz ermöglicht zwar einen schnelleren Zugriff auf die Daten für die Analyse, kann aber bei größeren Datenmengen zu Problemen führen, da die Skalierung aufgrund der direkten Verbindung zwischen dem Warehouse und den BI-Tools schwierig wird.
Die zweistufige Architektur eignet sich am besten für kleine bis mittelgroße Unternehmen, die einen schnelleren Datenzugriff für ihre Analysen benötigen, aber nicht auf die Skalierbarkeit größerer, komplexerer Architekturen angewiesen sind. Sie ist ideal für Unternehmen mit moderaten Datenmengen und relativ einfachen Berichts- oder Analyseanforderungen, da sie eine direkte Integration zwischen dem Data Warehouse und Business Intelligence-Tools ermöglicht.
Wenn die Daten jedoch wachsen oder die analytischen Anforderungen anspruchsvoller werden, kann diese Architektur Schwierigkeiten haben, zu skalieren und die steigenden Arbeitslasten effizient zu bewältigen.
Die dreistufige Architektur ist das gängigste und am weitesten verbreitete Modell für Data Warehouses. Es trennt das System in verschiedene Schichten: die Datenquellenschicht, die Staging Area-Schicht und die Analyseschicht. Diese Trennung ermöglicht effiziente ETL-Prozesse, gefolgt von Analysen und Berichten.
Die dreistufige Architektur ist ideal für große Unternehmensumgebungen, die Skalierbarkeit, Flexibilität und die Fähigkeit zur Verarbeitung großer Datenmengen erfordern. Sie ermöglicht es Unternehmen, Daten effizienter zu verwalten und unterstützt fortschrittliche Analysen, maschinelles Lernen und Echtzeitberichte. Die Trennung der Schichten erhöht die Leistung und eignet sich daher für komplexe Datenumgebungen.
Bei der Cloud Data Warehouse Architektur wird die gesamte Infrastruktur auf Plattformen wie Amazon Redshift, Google BigQuery oder Snowflake gehostet. Cloud-basierte Architekturen bieten eine praktisch unbegrenzte Skalierbarkeit und die Möglichkeit, große Datenmengen zu verarbeiten, ohne dass dafür Hardware vor Ort benötigt wird. Außerdem bieten sie Kostenflexibilität durch Umlagemodelle, was sie für eine breitere Palette von Unternehmen zugänglich macht.
Die Cloud-Data-Warehouse-Architektur ist ideal für Unternehmen jeder Größe. Er ist ideal für Unternehmen, die eine flexible und skalierbare Lösung suchen, da dieser Ansatz es ihnen ermöglicht, Speicher- und Rechenressourcen dynamisch zu skalieren.
Data Warehouse-Architekturen im Vergleich - Bild nach Autor.
Es gibt eine ganze Reihe von Data-Warehouse-Designmustern, aber jedes erfüllt unterschiedliche Anforderungen, je nach Komplexität der Daten und der Art der Abfragen, die ausgeführt werden. Lass uns einige der gängigsten untersuchen und die geeignetsten Szenarien entschlüsseln, um sie für maximale Effizienz einzusetzen.
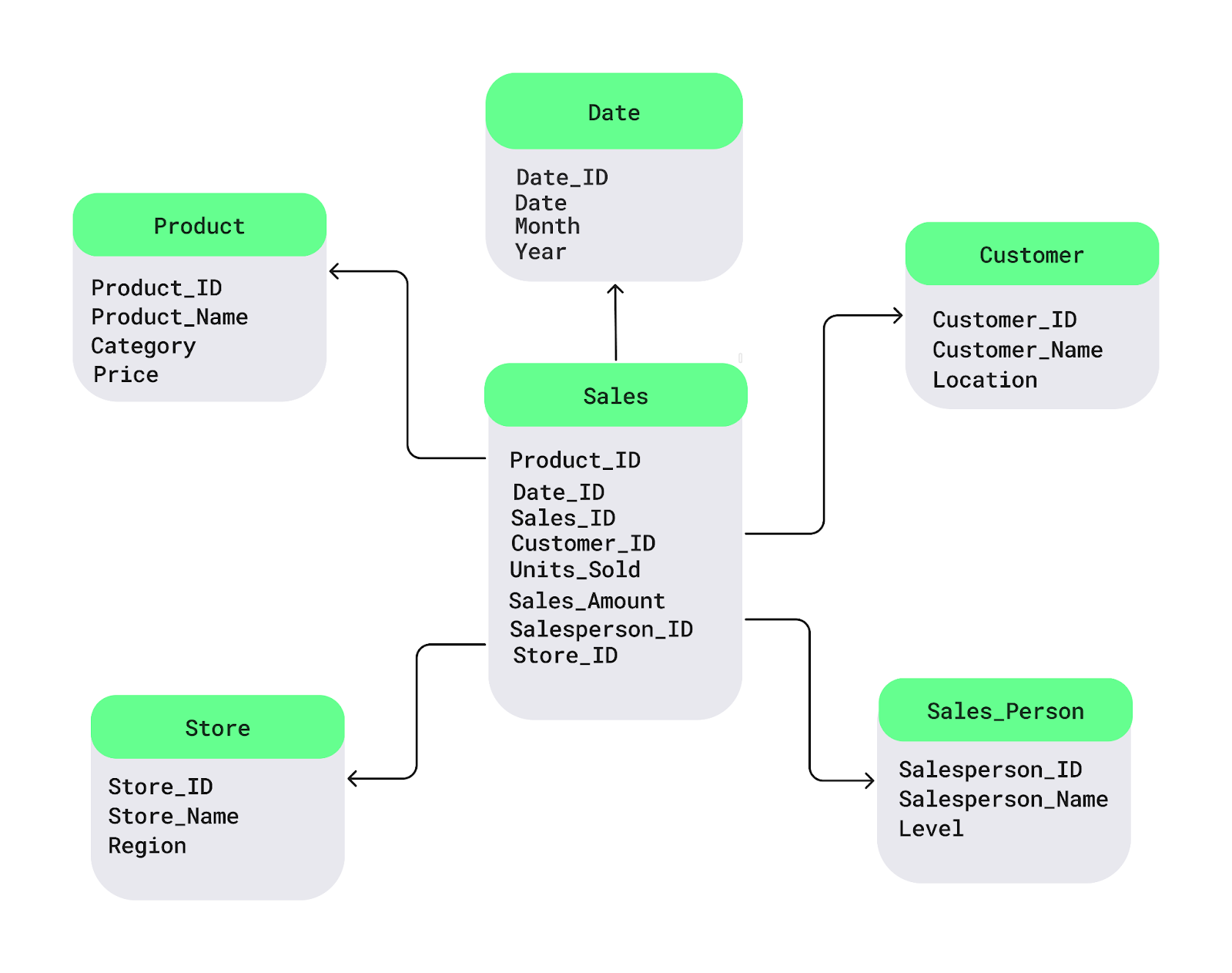
Das Sternschema ist eines der am häufigsten verwendeten Entwurfsmuster für Data Warehouses. Es strukturiert die Daten in:
In einem Einzelhandelsszenario enthält die Faktentabelle transaktionale Verkaufsdaten, während Dimensionstabellen den Kontext zu Produkten, Kunden, Geschäften und Zeit liefern. Dieses Schema verbessert die Abfrageleistung und ist daher ideal für Umgebungen mit häufigem, einfachem Berichtsbedarf.
Beispiel für ein Sternschema. Bild source: DataCamp.
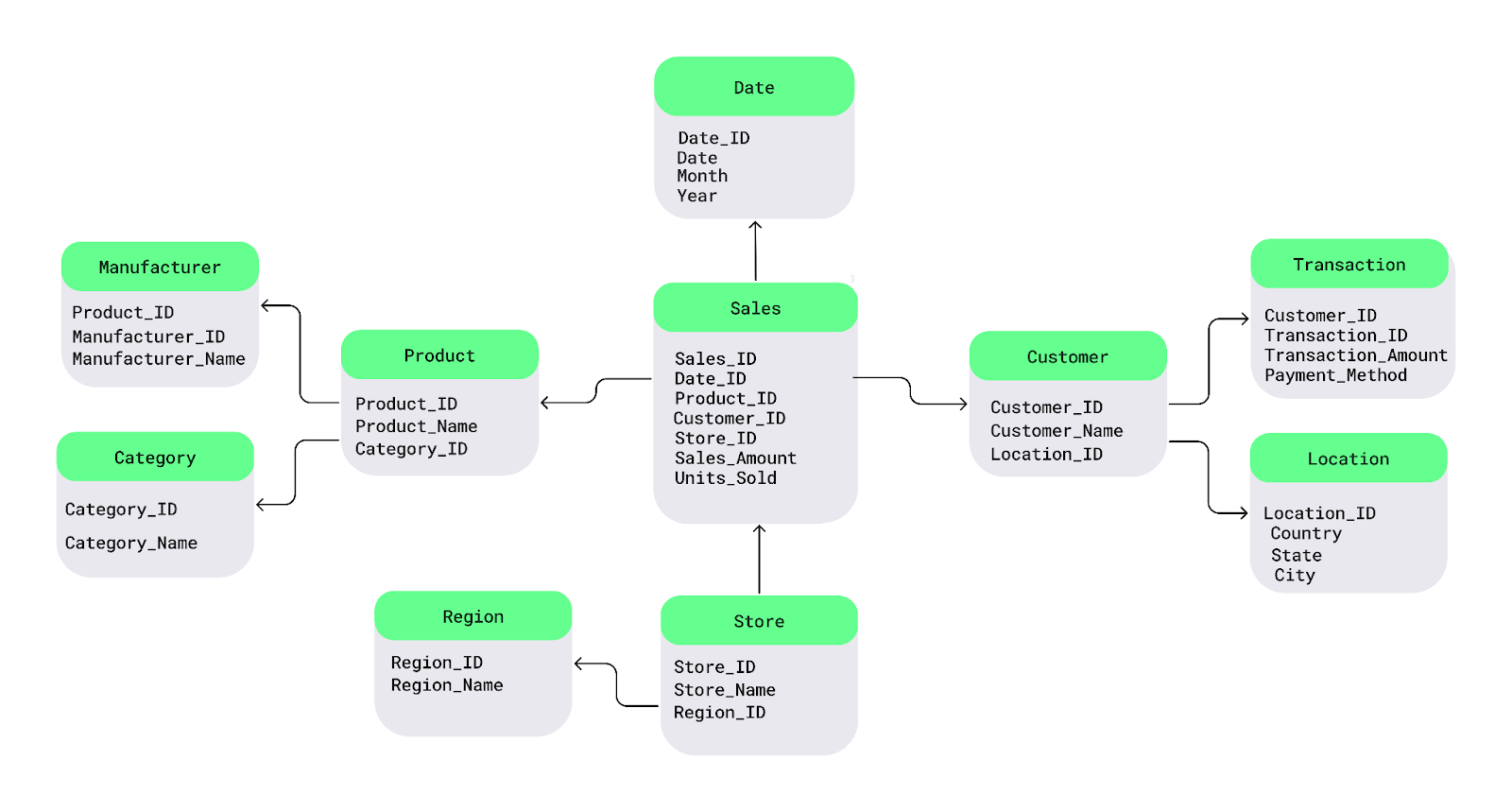
Das Snowflake-Schema ist eine Erweiterung des Sternschemas, bei dem Dimensionstabellen zusätzlich normalisiert werden. Die wichtigsten Merkmale sind:
Dieses Schema ist ideal für:
Das Snowflake-Schema spart zwar Speicherplatz, kann aber aufgrund seiner starken Strukturierung zu komplizierteren Abfragen führen.
Beispiel für ein Snowflake-Schema. Bild Quelle: DataCamp.
Die Modellierung von Datentresoren ist ein neueres Entwurfsmuster, das sich auf Flexibilität, Skalierbarkeit und die Nachverfolgung historischer Daten konzentriert. Es unterteilt das Data Warehouse in drei Kernkomponenten:
Dieser Ansatz ist sehr anpassungsfähig an Änderungen der Geschäftsprozesse und eignet sich daher gut für agile Entwicklungsumgebungen.
Das Data Vault Modeling Design Pattern erfreut sich zunehmender Beliebtheit, da es in der Lage ist, mit sich verändernden Datenumgebungen umzugehen, Änderungen der Datenquellen zu berücksichtigen und langfristige Skalierbarkeit zu unterstützen. Es hat sich zu einer idealen Lösung für Unternehmen entwickelt, die eine detaillierte historische Nachverfolgung, häufige Schemaänderungen oder eine hoch skalierbare Architektur benötigen.
Die frühzeitige Umsetzung von Best Practices ist entscheidend für den Aufbau einer robusten Architektur. In diesem Abschnitt werden daher einige der besten Praktiken vorgestellt, die beim Aufbau eines leistungsstarken Data Warehouse befolgt werden sollten.
Das Datenvolumen und die geschäftlichen Anforderungen werden im Laufe der Zeit unweigerlich wachsen. Daher ist es wichtig, dass du sicherstellst, dass die von dir gewählte Architektur mit den steigenden Arbeitslasten umgehen kann. Dies kann ganz einfach durch den Einsatz skalierbarer Speicherlösungen wie Cloud-basierte Plattformen und die Partitionierung großer Tabellen für eine bessere Leistung erreicht werden.
Optimiere die ETL-Pipeline, indem du unnötige Datenumwandlungen minimierst, inkrementelle Ladestrategien anwendest und ETL-Aufgaben wenn möglich parallelisierst. So wird sichergestellt, dass die Daten schnell und ohne Engpässe eingelesen, umgewandelt und geladen werden.
Die Aufrechterhaltung einer hohen Datenqualität ist für den Wert eines Data Warehouse von grundlegenderBedeutung. Implementiere strenge Datenvalidierungs- und Deduplizierungsverfahren, um sicherzustellen, dass die Daten, die in das Warehouse gelangen, korrekt und konsistent sind. Regelmäßige Audits und Qualitätsprüfungen sollten Teil der ETL-Pipeline sein, um Probleme zu vermeiden, die zu falschen Analysen führen könnten.
Datensicherheit sollte oberstes Gebotority sein - vor allem, wenn du mit sensiblen oder regulierten Informationen arbeitest. Es gibt drei wesentliche Maßnahmen, die du ergreifen musst:
Um das Data Warehouse effizient zu betreiben, solltest du regelmäßig die folgenden Punkte überwachen:
Tools zur Verfolgung der Leistung können helfen, Engpässe zu erkennen, damit du bei Bedarf proaktiv Anpassungen vornehmen kannst.
Solltest du dich für ein Cloud-basiertes Data Warehouse entscheiden oder alles vor Ort behalten? Was sind die wichtigsten Vorteile und Nachteile der einzelnen Ansätze? Und ist eine Hybridlösung das Beste aus beiden Welten?
In diesem Abschnitt gehen wir auf diese Fragen ein und helfen dir, die richtige Architektur für deine Bedürfnisse zu finden.
Cloud-basierte Data Warehouses bieten eine unvergleichliche Skalierbarkeit und Flexibilität. Diese Plattformen ermöglichen es Unternehmen, Speicher- und Rechenressourcen nach Bedarf zu skalieren, was sie ideal für die Bewältigung großer, dynamischer Datenmengen macht, ohne dass dafür Infrastrukturkosten anfallen.
Das Pay-as-you-go-Preismodell macht Cloud-Lösungen außerdem kosteneffizient, insbesondere für Unternehmen mit schwankenden Arbeitslasten. Cloud-Umgebungen können jedoch Bedenken hinsichtlich der Datenverwaltung und der Einhaltung von Vorschriften aufwerfen, insbesondere in stark regulierten Branchen.
Zu den beliebten Cloud-Anbietern gehören:
Vor-Ort-Data-Warehouses eignen sich am besten für Unternehmen, die eine strenge Datenkontrolle benötigen. Mit der On-Premises-Architektur behalten Unternehmen die vollständige Kontrolle über ihre Hardware und Daten, was für Branchen wie das Finanzwesen, das Gesundheitswesen und die öffentliche Verwaltung, in denen sensible Informationen geschützt werden müssen, unerlässlich ist.
Aber hier ist der Haken an der Sache. Vor-Ort-Systeme können zwar eine solide Leistung bieten, sind aber oft mit hohen Vorlaufkosten für Hardware und laufende Wartung verbunden. Auch die Skalierung kann eine Herausforderung sein, da sie manuelle Upgrades und die Beschaffung von Hardware erfordert, die weniger flexibel ist als Cloud-Lösungen.
Hybride Data-Warehouse-Architekturen kombinieren Cloud- und On-Premises-Komponenten und bieten so mehr Flexibilität für Unternehmen, die ein Gleichgewicht zwischen Sicherheit, Compliance und Skalierbarkeit finden müssen. So können zum Beispiel sensible Daten vor Ort gespeichert werden, während weniger kritische Daten oder analytische Workloads in der Cloud verarbeitet werden können.
Hybride Architekturen sind besonders nützlich für Unternehmen, die schrittweise auf die Cloud umsteigen müssen oder besondere Datenschutzanforderungen haben. Dieses Modell bietet das Beste aus beiden Welten, erfordert aber eine sorgfältige Orchestrierung, um eine nahtlose Datenintegration zwischen den Umgebungen zu gewährleisten.
|
Feature |
Cloud-basierte Architektur |
Vor-Ort-Architektur |
Hybride Architektur |
|
Skalierbarkeit |
Hoch skalierbare, bedarfsorientierte Ressourcenzuweisung |
Begrenzt durch Hardware vor Ort, erfordert manuelle Upgrades |
Kombiniert skalierbare Cloud-Ressourcen mit der Kontrolle vor Ort |
|
Kosten |
Umlageverfahren, geringere Vorlaufkosten |
Hohe Vorabinvestitionen in Hardware und laufende Wartung |
Hybride Kosten, die Einsparungen in der Cloud und Ausgaben vor Ort ausgleichen |
|
Flexibilität |
Äußerst flexibel, ideal für dynamische Arbeitslasten |
Weniger flexibel, eingeschränkt durch die physische Infrastruktur |
Flexibel, kombiniert Cloud-Flexibilität mit Vor-Ort-Kontrolle |
|
Sicherheit & Compliance |
Kann für stark regulierte Branchen Bedenken aufwerfen |
Vollständige Kontrolle über die Datensicherheit und die Einhaltung von Vorschriften |
Sicherstellung der Compliance für sensible Daten bei gleichzeitiger Nutzung der Cloud |
|
Leistung |
Kann je nach Cloud-Anbieter und Konfiguration variieren |
Hohe Leistung, aber abhängig von Hardware-Investitionen |
Ausgewogene Leistung basierend auf der Verteilung der Arbeitslast |
|
Wartung |
Minimale Wartung, verwaltet vom Cloud-Anbieter |
Erfordert laufende interne IT-Wartung |
Hybrider Ansatz mit Cloud-Diensten, die einen Teil der Wartung übernehmen |
|
Anwendungsfälle |
Am besten für Unternehmen mit großen, schwankenden Datenmengen |
Am besten für Organisationen mit strengen Sicherheits- und Compliance-Anforderungen |
Ideal für Unternehmen, die auf die Cloud umsteigen oder unterschiedliche Anforderungen haben |
Hier ist ein Überblick über einige der beliebtesten Data Warehouse-Plattformen, die in der Cloud genutzt werden.
Amazon Redshift ist eine vollständiggealterte Cloud Data Warehouse-Lösung für groß angelegte Datenanalysen. Seine Architektur basiert auf einem massiv-parallelen Verarbeitungssystem, das es den Nutzern ermöglicht, große Datenmengen schnell abzufragen. Mit seiner Fähigkeit, je nach Arbeitslast hoch- und runterzuskalieren, ist Redshift gut für Unternehmen geeignet, die kosteneffiziente Skalierbarkeit und Integration mit anderen AWS-Diensten benötigen.
Google BigQuery ist eine servicelose, hoch skalierbare Data-Warehouse-Plattform, die für schnelle Echtzeit-Analysen entwickelt wurderless. Seine einzigartige Architektur entkoppelt Speicher- und Rechenleistung und ermöglicht es den Nutzern, Petabytes an Daten abzufragen, ohne die Infrastruktur zu verwalten. Die Fähigkeit von BigQuery, umfangreiche Analysen mit minimalem Overhead zu verarbeiten, macht es ideal für Unternehmen mit hohem Datenaufkommen, die schnelle, komplexe Abfragen benötigen.
Snowflake bietet eine Multi-Cluster, Shared-Data-Architektur, die Rechen- und Speicherressourcen voneinander trennt und eine flexible, unabhängige Skalierung der Ressourcen ermöglicht. Der Cloud-native Ansatz von Snowflake ermöglicht es Unternehmen, Arbeitslasten dynamisch zu skalieren, und macht es damit zu einer attraktiven Option für Unternehmen, die eine hohe Flexibilität und ein Workload-Management über mehrere Cloud-Plattformen hinweg benötigen.
Microsoft Azure Synapse Analytics ist eine hybride Datenmanagement-Plattform, die Data Warehousing und Big Data Analytics kombiniert. Seine Architektur lässt sich mit Big Data-Frameworks wie Apache Spark integrieren, um eine einheitliche Umgebung für die Verwaltung von Data Lakes und Data Warehouses zu schaffen. Azure Synapse bietet eine nahtlose Integration mit anderen Microsoft-Diensten und ist ideal für Unternehmen mit unterschiedlichen Datenanalyseanforderungen.
|
Plattform |
Architektur |
Hauptmerkmale |
Anwendungsfälle |
|
Amazon Redshift |
MPP-Architektur, AWS-Ökosystem |
Skalierbar, schnelle Abfragen, AWS-Integration |
Groß angelegte Analysen, Cloud-native Anwendungen |
|
Google BigQuery |
Serverlose, entkoppelte Speicherung und Datenverarbeitung |
Echtzeit-Analysen, geringe Infrastruktur |
Schnelle Analysen, Datenverarbeitung in Echtzeit |
|
Snowflake |
Multi-Cluster, Shared-Data-Architektur, Cross-Cloud (AWS, Azure, GCP) |
Trennung von Computer und Speicher, dynamische Skalierung |
Flexible Skalierung, plattformübergreifende Cloud-Workloads |
|
Azure Synapse |
Hybride Big-Data-Integration |
Unified Analytics, Spark-Integration |
Hybrides Datenmanagement, Integration mit Microsoft-Tools |
Data Warehouses bieten Unternehmen zwar leistungsstarke Funktionen für die Analyse und Verwaltung großer Datenmengen, aber sie bringen auch einige Herausforderungen mit sich.
Hier sind einige der wichtigsten Herausforderungen und Lösungen, die bei der Entwicklung und Pflege einer Data Warehouse-Architektur zu berücksichtigen sind.
Unternehmen sammeln Daten aus verschiedenen Quellen, die jeweils unterschiedliche Formate, Schemata und Strukturen haben, was die Integration zu einer komplexen Herausforderung macht. Zu den wichtigsten Überlegungen gehören:
Um diese Herausforderungen zu meistern, brauchen Unternehmen flexible ETL-Prozesse und Datenmanagement-Tools, die verschiedene Datenformate und eine nahtlose Integration über Plattformen hinweg unterstützen.
Wenn Data Warehouses wachsen, wird die Aufrechterhaltung einer hohen Abfrageleistung zu einer Herausforderung. Groß angelegte Operationen müssen Millionen oder sogar Milliarden von Zeilen effizient verarbeiten und dabei langsame Abfragen, hohe Kosten und ineffiziente Ressourcennutzung vermeiden.
Zu den wichtigsten Optimierungsstrategien gehören:
Je mehr Nutzer auf das Data Warehouse zugreifen, desto wichtiger wird eine effiziente Ressourcenzuweisung. Zu den wichtigsten Überlegungen gehören:
Durch die Umsetzung dieser Strategien können Unternehmen sicherstellen, dass ihr Data Warehouse effektiv skaliert und eine hohe Leistung beibehält, wenn das Datenvolumen und die Benutzeraktivität wachsen.
Da in Data Warehouses immer mehr sensible Daten gespeichert werden, sind strenge Governance- und Sicherheitsmaßnahmen unerlässlich, um Verstöße zu verhindern, die Einhaltung von Vorschriften zu gewährleisten und die Datenintegrität zu erhalten.
In diesem Artikel haben wir die wichtigsten Komponenten der Data-Warehouse-Architektur, häufige Herausforderungen und Strategien zu deren Bewältigung untersucht. Ein gut konzipiertes Data Warehouse ist mehr als nur ein Datenspeicher - es befähigt Unternehmen, fundierte, datengestützte Entscheidungen zu treffen, die Wachstum und Innovation fördern.
Willst du tiefer in die Datenarchitektur und Best Practices eintauchen? Schau dir diese Ressourcen an:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
