
Curso
Introdução à Engenharia de Dados
4 h
127.6K
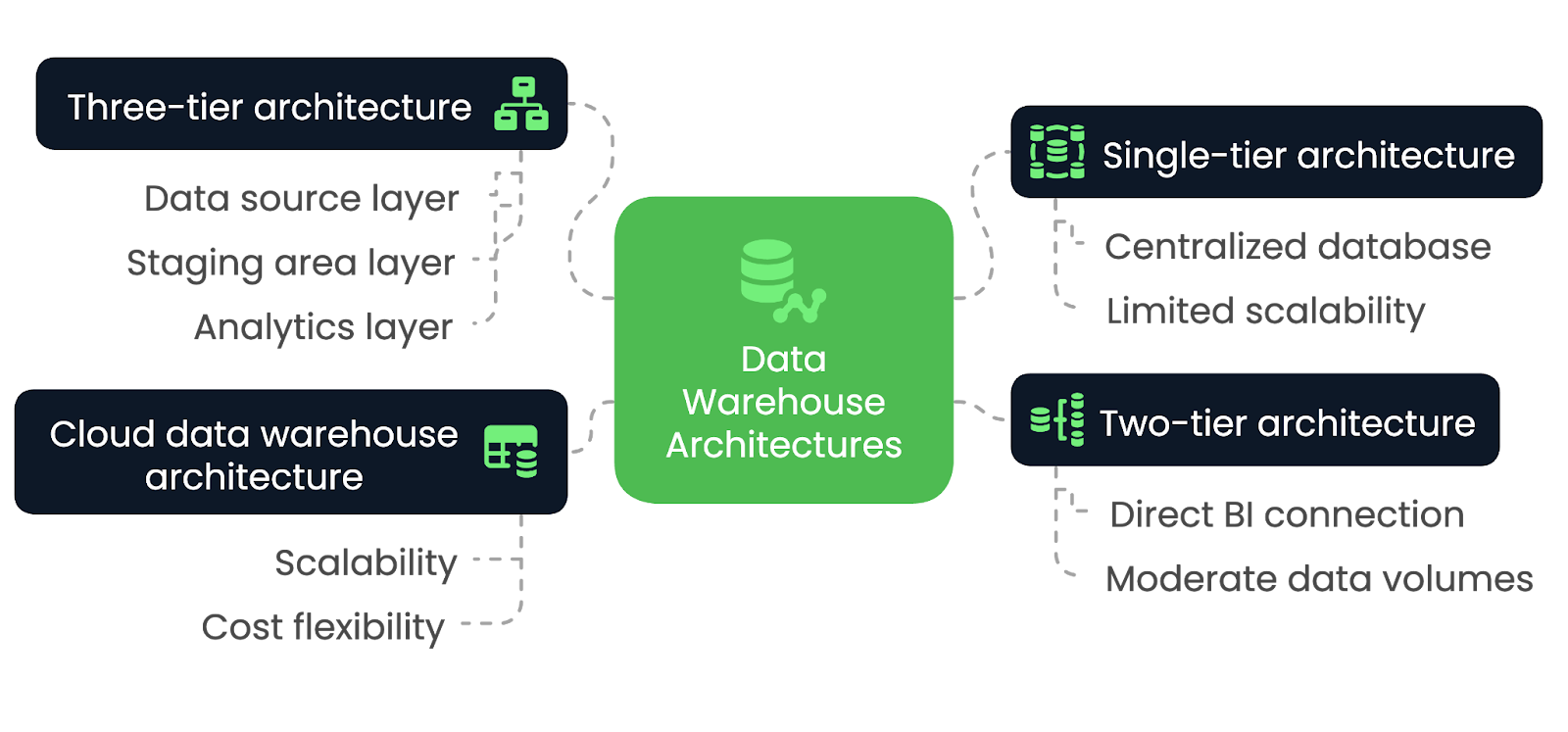
A escolha da arquitetura correta de data warehouse é essencial para que você atenda às necessidades de desempenho, escalabilidade e integração da sua organização. No entanto, diferentes arquiteturas oferecem vantagens e compensações exclusivas, dependendo de vários fatores. Vamos explorá-las nesta seção.
Em uma arquitetura de camada única, o data warehouse é construído em um banco de dados único e centralizado que consolida todos os dados de várias fontes em um único sistema. Essa arquitetura minimiza o número de camadas e simplifica o design geral, levando a um processamento e acesso mais rápidos aos dados. No entanto, ela não tem a flexibilidade e a modularidade encontradas em arquiteturas mais complexas.
A arquitetura de camada única é mais adequada para aplicativos de pequena escala e organizações com necessidades limitadas de processamento de dados. É ideal para empresas que priorizam a simplicidade e a implementação rápida em detrimento da escalabilidade. No entanto, à medida que o volume de dados aumenta ou que são necessárias análises mais avançadas, essa arquitetura pode ter dificuldades para atender a essas demandas de forma eficaz.
Em uma arquitetura de duas camadas, o warehouse de dados se conecta diretamente às ferramentas de BI, geralmente por meio deum sistema OLAP. Embora essa abordagem forneça acesso mais rápido aos dados para análise, ela pode enfrentar desafios ao lidar com volumes de dados maiores, pois o dimensionamento se torna difícil devido à conexão direta entre o warehouse e as ferramentas de BI.
A arquitetura de duas camadas é mais adequada para organizações de pequeno e médio porte que precisam de acesso mais rápido aos dados para análise, mas não precisam da escalabilidade de arquiteturas maiores e mais complexas. É ideal para empresas com volumes de dados moderados e necessidades relativamente simples de relatórios ou análises, pois permite a integração direta entre o data warehouse e as ferramentas de business intelligence.
No entanto, à medida que os dados crescem ou os requisitos analíticos se tornam mais sofisticados, essa arquitetura pode ter dificuldades para dimensionar e lidar com o aumento das cargas de trabalho de forma eficiente.
A arquitetura de três camadas é o modelo mais comum e amplamente usado para data warehouses. Ele separa o sistema em camadas distintas: a camada de fonte de dados, a camada de área de preparação e a camada de análise. Essa separação permite processos eficientes de ETL, seguidos de análises e relatórios.
A arquitetura de três camadas é ideal para ambientes corporativos de grande escala que exigem escalabilidade, flexibilidade e capacidade de lidar com grandes volumes de dados. Ele permite que as empresas gerenciem os dados com mais eficiência e oferece suporte a análises avançadas, machine learning e relatórios em tempo real. A separação de camadas melhora o desempenho, tornando-o adequado para ambientes de dados complexos.
Na arquitetura de data warehouse em nuvem, toda a infraestrutura é hospedada em plataformas como Amazon Redshift, Google BigQuery ou Snowflake. As arquiteturas baseadas em nuvem oferecem escalabilidade praticamente ilimitada, com a capacidade de lidar com grandes conjuntos de dados sem a necessidade de hardware no local. Eles também oferecem flexibilidade de custo por meio de modelos de pagamento conforme o uso, o que os torna acessíveis a uma gama mais ampla de empresas.
A arquitetura de data warehouse em nuvem é ideal para organizações de todos os tamanhos. É ideal para empresas que buscam uma solução flexível e dimensionável, pois essa abordagem permite que as empresas dimensionem dinamicamente os recursos de armazenamento e computação.
Arquiteturas de data warehouse comparadas - imagem por autor.
Existem vários padrões de design de data warehouse, mas cada um atende a diferentes necessidades, dependendo da complexidade dos dados e dos tipos de consultas que estão sendo executadas. Vamos explorar alguns dos mais comuns e decifrar os cenários mais apropriados para usá-los com o máximo de eficiência.
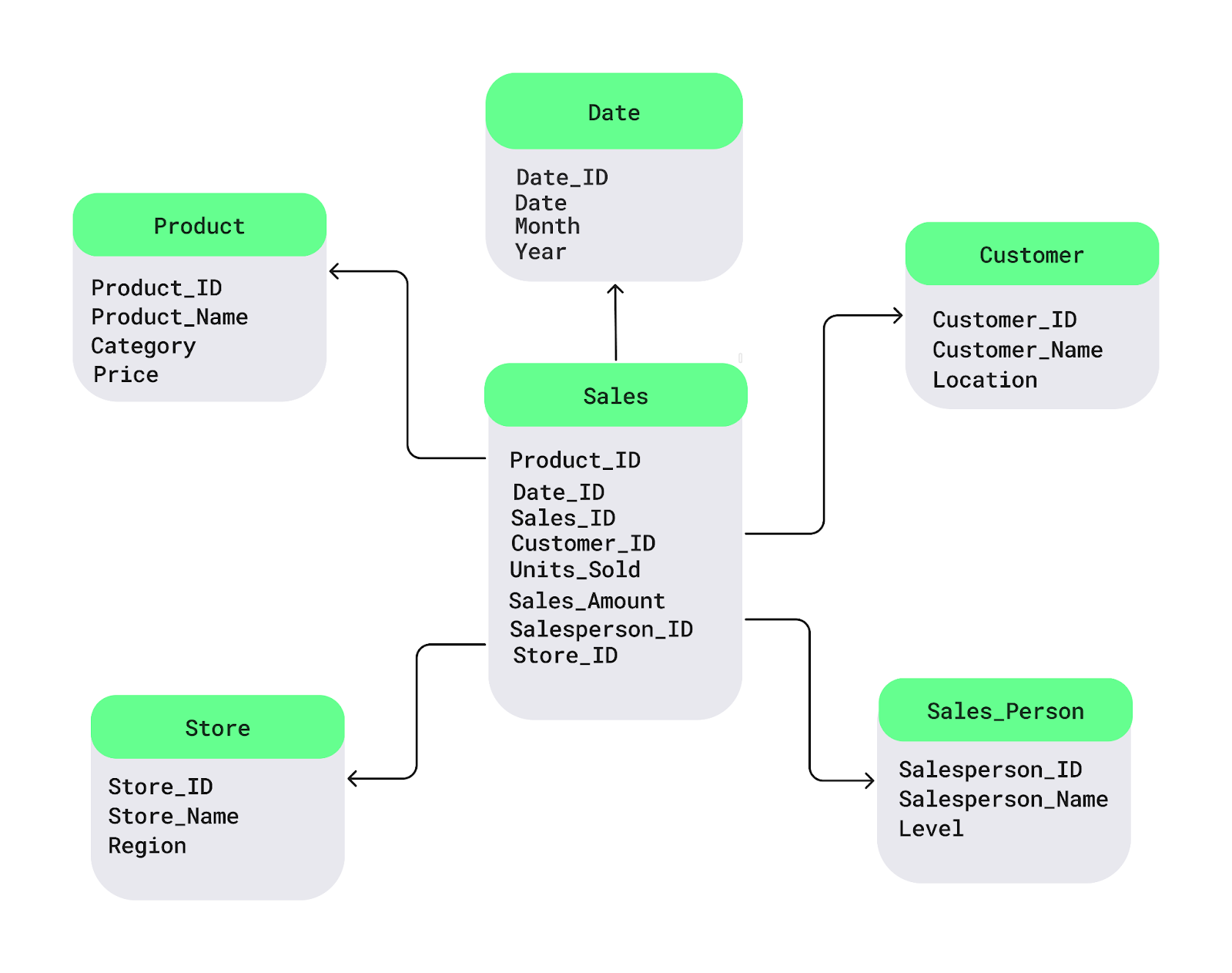
O esquema em estrela é um dos padrões de design de data warehouse mais usados. Ele estrutura os dados em:
Em um cenário de varejo, a tabela de fatos contém dados de vendas transacionais, enquanto as tabelas de dimensões fornecem contexto sobre produtos, clientes, lojas e tempo. Esse esquema melhora o desempenho da consulta, tornando-o ideal para ambientes com necessidades de relatórios frequentes e diretos.
Exemplo de esquema de estrela. Imagem source: DataCamp.
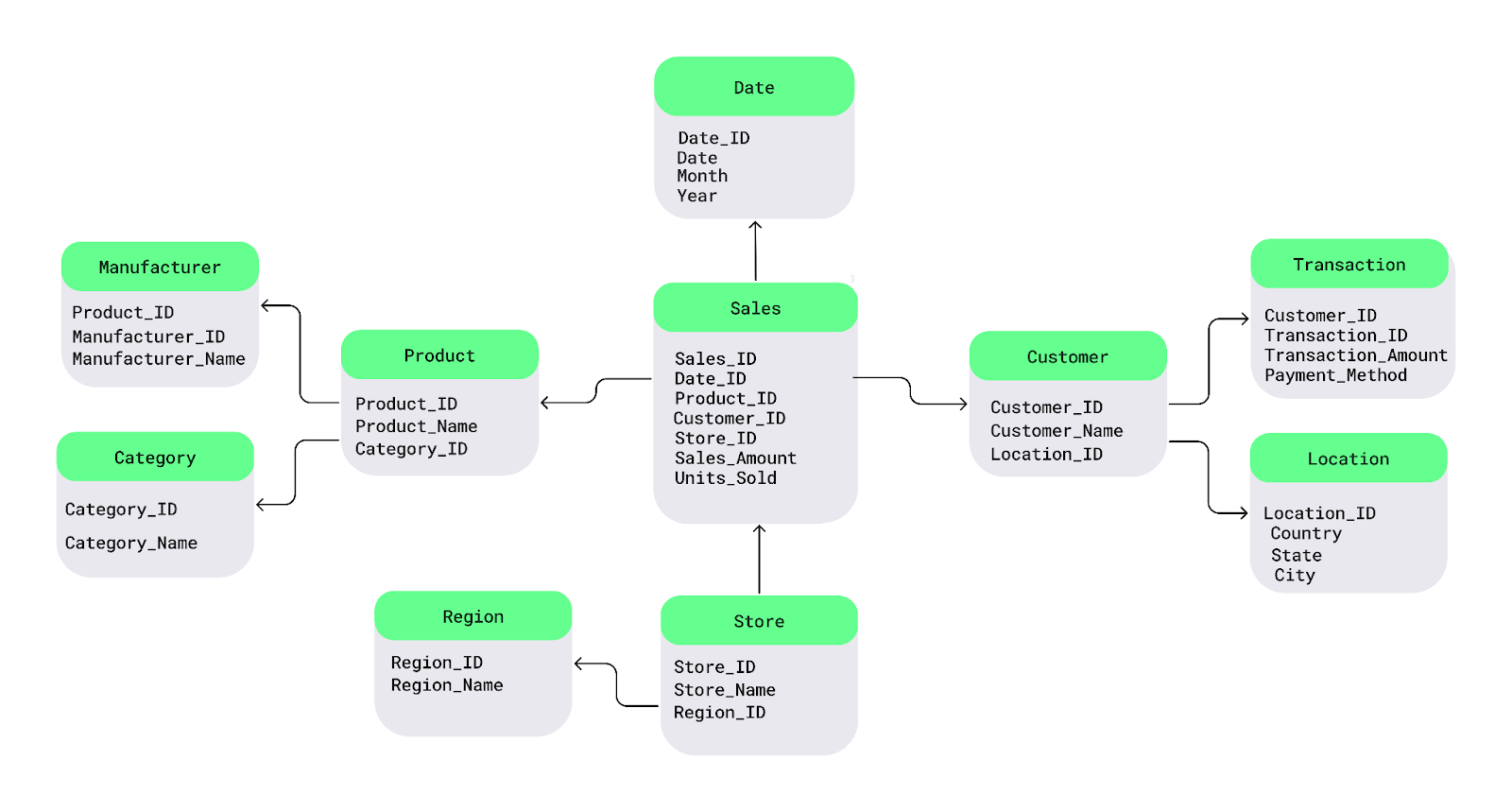
O esquema Snowflake é uma extensão do esquema estrela, introduzindo normalização adicional nas tabelas de dimensão. As principais características incluem:
Esse esquema é ideal para você:
Embora o esquema Snowflake conserve o armazenamento, ele pode levar a consultas mais complexas devido à sua natureza altamente estruturada.
Exemplo de esquema Snowflake. Imagem fonte: DataCamp.
A modelagem de cofre de dados é um padrão de design mais recente que se concentra em flexibilidade, escalabilidade e rastreamento de dados históricos. Ele divide o data warehouse em três componentes principais:
Essa abordagem é altamente adaptável às mudanças nos processos de negócios, o que a torna adequada para ambientes de desenvolvimento ágeis.
O padrão de design de modelagem de cofre de dados tem crescido em popularidade devido à sua capacidade de lidar com ambientes de dados em evolução, acomodar mudanças nas fontes de dados e oferecer suporte à escalabilidade de longo prazo. Ele se tornou a solução ideal para organizações que exigem rastreamento histórico detalhado, alterações frequentes de esquema ou uma arquitetura altamente escalonável.
A implementação de práticas recomendadas desde o início é essencial para a criação de uma arquitetura robusta. Portanto, esta seção abordará algumas das práticas recomendadas a serem seguidas na construção de um data warehouse de alto desempenho.
Os volumes de dados e os requisitos comerciais inevitavelmente crescerão com o tempo, portanto, é essencial garantir que a arquitetura que você selecionar possa lidar com o aumento das cargas de trabalho. Você pode fazer isso simplesmente usando soluções de armazenamento escalonáveis, como plataformas baseadas em nuvem, e particionando tabelas grandes para obter melhor desempenho.
Simplifique o pipeline de ETL minimizando as transformações de dados desnecessárias, aproveitando as estratégias de carregamento incremental e paralelizando as tarefas de ETL quando possível. Isso garante que os dados sejam ingeridos, transformados e carregados rapidamente, sem gargalos.
Manter a alta qualidade dos dados é fundamental para o valor de um data warehouse.mental. Implemente procedimentos sólidos de validação e deduplicação de dados para garantir que os dados que entram no warehouse sejam precisos e consistentes. Auditorias regulares e verificações de qualidade devem fazer parte do pipeline de ETL para evitar problemas que possam levar a análises incorretas.
A segurança dos dados deve ser uma prioridade, especialmente ao lidar com informações confidenciais ou regulamentadas. Há três medidas essenciais que você deve tomar:
Para manter o data warehouse operando de forma eficiente, monitore regularmente o seguinte:
Os programas para monitorar o desempenho podem ajudar a identificar gargalos, o que pode ajudar você a fazer ajustes proativos quando necessário.
Você deve optar por um data warehouse baseado em nuvem ou manter tudo no local? Quais são os principais benefícios e desvantagens de cada abordagem? E uma solução híbrida é o melhor dos dois mundos?
Nesta seção, exploraremos essas questões e ajudaremos você a determinar a arquitetura certa para suas necessidades.
Os data warehouses baseados em nuvem oferecem escalabilidade e flexibilidade inigualáveis. Essas plataformas permitem que as empresas dimensionem os recursos de armazenamento e computação sob demanda, o que as torna ideais para lidar com grandes volumes de dados dinâmicos sem custos iniciais de infraestrutura.
O modelo de preço de pagamento conforme o uso também torna as soluções em nuvem econômicas, especialmente para empresas com cargas de trabalho flutuantes. No entanto, os ambientes em nuvem podem levantar preocupações sobre a governança e a conformidade dos dados, especialmente para setores altamente regulamentados.
Os fornecedores populares de nuvem incluem:
Os data warehouses no local são mais adequados para organizações que exigem controle rigoroso dos dados. Com a arquitetura no local, as empresas mantêm controle total sobre o hardware e os dados, o que é essencial para setores como finanças, saúde e governo, onde as informações confidenciais devem ser protegidas.
Mas aqui está o problema. Embora os sistemas locais possam oferecer um desempenho robusto, eles geralmente têm altos custos iniciais de hardware e manutenção contínua. O dimensionamento também pode ser desafiador, pois requer atualizações manuais e aquisição de hardware, o que é menos flexível do que as soluções em nuvem.
As arquiteturas híbridas de data warehouse combinam componentes na nuvem e no local, oferecendo maior flexibilidade para as organizações que precisam equilibrar segurança, conformidade e escalabilidade. Por exemplo, os dados confidenciais podem ser armazenados no local, enquanto os dados menos críticos ou as cargas de trabalho de análise podem ser processados na nuvem.
As arquiteturas híbridas são particularmente úteis para empresas que precisam fazer a transição para a nuvem gradualmente ou que têm requisitos específicos de privacidade de dados. Esse modelo oferece o melhor dos dois mundos, mas requer uma orquestração cuidadosa para garantir a integração perfeita dos dados entre os ambientes.
|
Recurso |
Arquitetura baseada em nuvem |
Arquitetura no local |
Arquitetura híbrida |
|
Escalabilidade |
Alocação de recursos altamente dimensionável e sob demanda |
Limitado pelo hardware no local, requer atualizações manuais |
Combina recursos de nuvem escaláveis com controle no local |
|
Custo |
Preços de pagamento conforme o uso, custos iniciais mais baixos |
Alto investimento inicial em hardware e manutenção contínua |
Custos híbridos, equilibrando a economia na nuvem e as despesas no local |
|
Flexibilidade |
Extremamente flexível, ideal para cargas de trabalho dinâmicas |
Menos flexível, limitado pela infraestrutura física |
Flexível, combinando agilidade na nuvem com controle no local |
|
Segurança e conformidade |
Pode gerar preocupações para setores altamente regulamentados |
Controle total sobre a segurança dos dados e a conformidade normativa |
Garante a conformidade de dados confidenciais enquanto você aproveita a nuvem |
|
Desempenho |
Você pode variar de acordo com o provedor de nuvem e a configuração |
Alto desempenho, mas dependente de investimentos em hardware |
Desempenho equilibrado com base na distribuição da carga de trabalho |
|
Manutenção |
Manutenção mínima, gerenciada pelo provedor de nuvem |
Requer manutenção interna contínua de TI |
Abordagem híbrida com serviços em nuvem que lidam com alguma manutenção |
|
Casos de uso |
Ideal para empresas com volumes de dados grandes e flutuantes |
Ideal para organizações com necessidades rigorosas de segurança e conformidade |
Ideal para organizações que estão fazendo a transição para a nuvem ou com necessidades mistas |
Aqui está uma visão geral de algumas das plataformas de data warehouse mais populares usadas na nuvem.
O Amazon Redshift é uma solução de data warehouse em nuvem totalmenteenvelhecida para análise de dados em grande escala. Sua arquitetura é baseada em um sistema de processamento massivamente paralelo, que permite aos usuários consultar rapidamente vastos conjuntos de dados. Com sua capacidade de aumentar e diminuir com base nos requisitos de carga de trabalho, o Redshift é adequado para organizações que precisam de escalabilidade econômica e integração com outros serviços da AWS.
O Google BigQuery é uma plataforma de warehouse de dados altamente escalonável, sem serviços, criada para análises rápidas e em tempo real. Sua arquitetura exclusiva desacopla o armazenamento e a computação, o que permite que os usuários consultem petabytes de dados sem gerenciar a infraestrutura. A capacidade do BigQuery de processar análises em grande escala com o mínimo de sobrecarga o torna ideal para organizações com cargas de trabalho de dados pesadas que exigem consultas rápidas e complexas.
O Snowflake oferece uma arquitetura de dados compartilhados com vários lustres que separa a computação e o armazenamento, proporcionando flexibilidade em recursos de dimensionamento independente. A abordagem nativa da nuvem da Snowflake permite que as empresas dimensionem dinamicamente as cargas de trabalho, tornando-a uma opção atraente para as organizações que precisam de alta flexibilidade e gerenciamento de cargas de trabalho em várias plataformas de nuvem.
O Microsoft Azure Synapse Analytics é uma plataforma híbrida de gerenciamento de dados que combina data warehouse e análise de big data. Sua arquitetura se integra a estruturas de big data, como o Apache Spark, para fornecer um ambiente unificado para o gerenciamento de data lakes e data warehouses. O Azure Synapse oferece integração perfeita com outros serviços da Microsoft e é ideal para empresas com diversas necessidades de análise de dados.
|
Plataforma |
Arquitetura |
Principais recursos |
Casos de uso |
|
Amazon Redshift |
Arquitetura MPP, ecossistema AWS |
Consultas rápidas e dimensionáveis, integração com o AWS |
Análise em grande escala, aplicativos nativos da nuvem |
|
Google BigQuery |
Armazenamento e computação desacoplados e sem servidor |
Análise em tempo real, baixa infraestrutura |
Análise rápida, processamento de dados em tempo real |
|
Snowflake |
Arquitetura de dados compartilhados em vários clusters, entre nuvens (AWS, Azure, GCP) |
Separação entre computação e armazenamento, dimensionamento dinâmico |
Dimensionamento flexível, cargas de trabalho de plataforma entre nuvens |
|
Azure Synapse |
Integração híbrida e de big data |
Análise unificada, integração com o Spark |
Gerenciamento de dados híbridos, integração com ferramentas da Microsoft |
Embora os data warehouses ofereçam recursos poderosos para as organizações analisarem e gerenciarem grandes quantidades de dados, eles também apresentam desafios inerentes.
Aqui estão alguns dos desafios e soluções mais significativos que você deve considerar ao projetar e manter uma arquitetura de data warehouse.
As organizações coletam dados de várias fontes, cada uma com diferentes formatos, esquemas e estruturas, o que torna a integração um desafio complexo. As principais considerações incluem:
Para enfrentar esses desafios, as empresas precisam de processos flexíveis de ETL e ferramentas de gerenciamento de dados que suportem diversos formatos de dados e integração perfeita entre plataformas.
À medida que os data warehouses crescem, manter um alto desempenho de consulta se torna um desafio. As operações em grande escala precisam processar com eficiência milhões - ou até bilhões - de linhas, evitando consultas lentas, altos custos e uso ineficiente de recursos.
As principais estratégias de otimização incluem:
À medida que mais usuários acessam o data warehouse, a alocação eficiente de recursos torna-se crítica. As principais considerações incluem:
Ao implementar essas estratégias, as organizações podem garantir que seu warehouse de dados seja dimensionado de forma eficaz e mantenha o alto desempenho à medida que o volume de dados e a atividade do usuário aumentam.
Como os data warehouses armazenam quantidades cada vez maiores de informações confidenciais, medidas sólidas de governança e segurança são essenciais para evitar violações, garantir a conformidade e manter a integridade dos dados.
Neste artigo, exploramos os principais componentes da arquitetura de data warehouse, os desafios comuns e as estratégias para superá-los. Em última análise, um data warehouse bem projetado faz mais do que armazenar dados - ele capacita as organizações a tomar decisões informadas e orientadas por dados que impulsionam o crescimento e a inovação.
Você quer se aprofundar na arquitetura de dados e nas práticas recomendadas? Dê uma olhada nestes recursos:
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso