
Course
Introduction to Data Engineering
4 hr
127.6K
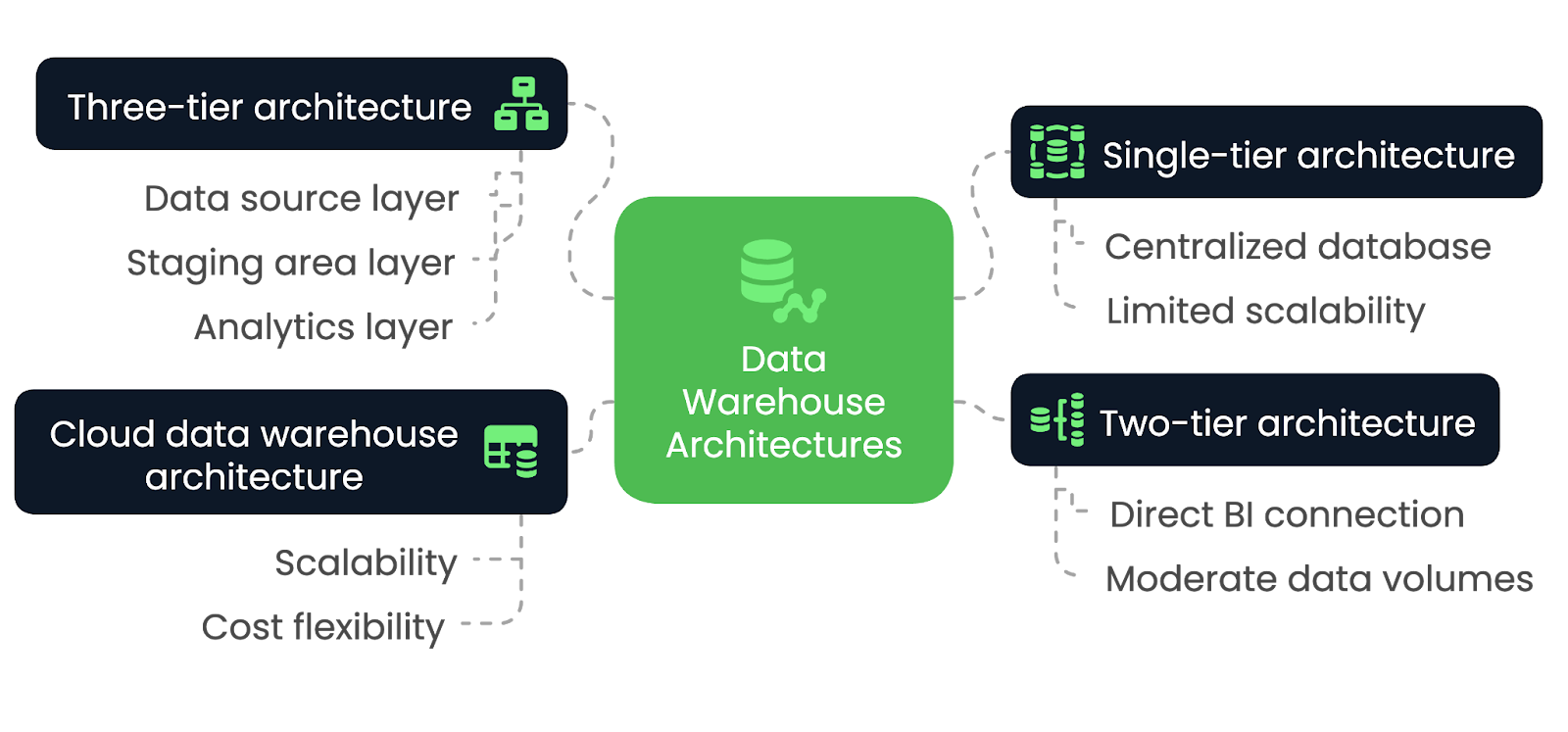
Choosing the right data warehouse architecture is essential for meeting your organization's performance, scalability, and integration needs. However, different architectures provide unique advantages and trade-offs, depending on various factors. Let’s explore them in this section.
In a single-tier architecture, the data warehouse is built on a single, centralized database that consolidates all data from various sources into one system. This architecture minimizes the number of layers and simplifies the overall design, leading to faster data processing and access. However, it lacks the flexibility and modularity found in more complex architectures.
The single-tier architecture best suits small-scale applications and organizations with limited data processing needs. It's ideal for businesses that prioritize simplicity and quick implementation over scalability. However, as data volume increases or more advanced analytics are required, this architecture may struggle to meet those demands effectively.
In a two-tier architecture, the data warehouse connects directly to BI tools, often through an OLAP system. While this approach provides faster access to data for analysis, it may face challenges in handling larger data volumes, as scaling becomes difficult due to the direct connection between the warehouse and BI tools.
The two-tier architecture is best suited for small to medium-sized organizations that need faster data access for analysis but don't require the scalability of larger, more complex architectures. It's ideal for businesses with moderate data volumes and relatively simple reporting or analytics needs, as it allows for direct integration between the data warehouse and business intelligence tools.
However, as data grows or analytical requirements become more sophisticated, this architecture may struggle to scale and handle increasing workloads efficiently.
The three-tier architecture is the most common and widely used model for data warehouses. It separates the system into distinct layers: the data source layer, the staging area layer, and the analytics layer. This separation enables efficient ETL processes, followed by analytics and reporting.
The three-tier architecture is ideal for large-scale enterprise environments that require scalability, flexibility, and the ability to handle massive data volumes. It allows businesses to manage data more efficiently and supports advanced analytics, machine learning, and real-time reporting. Separating layers enhances performance, making it suitable for complex data environments.
In cloud data warehouse architecture, the entire infrastructure is hosted on platforms like Amazon Redshift, Google BigQuery, or Snowflake. Cloud-based architectures offer virtually unlimited scalability, with the ability to handle large datasets without the need for on-premises hardware. They also provide cost flexibility through pay-as-you-go models, which makes them accessible to a broader range of businesses.
Cloud data warehouse architecture is ideal for organizations of all sizes. It’s ideal for businesses looking for a flexible and scalable solution since this approach enables companies to scale storage and compute resources dynamically.
Data warehouse architectures compared—image by Author.
There are quite a few data warehouse design patterns, but each caters to different needs depending on the complexity of the data and the types of queries being executed. Let’s explore some of the most common ones and decipher the most appropriate scenarios to use them for maximum efficiency.
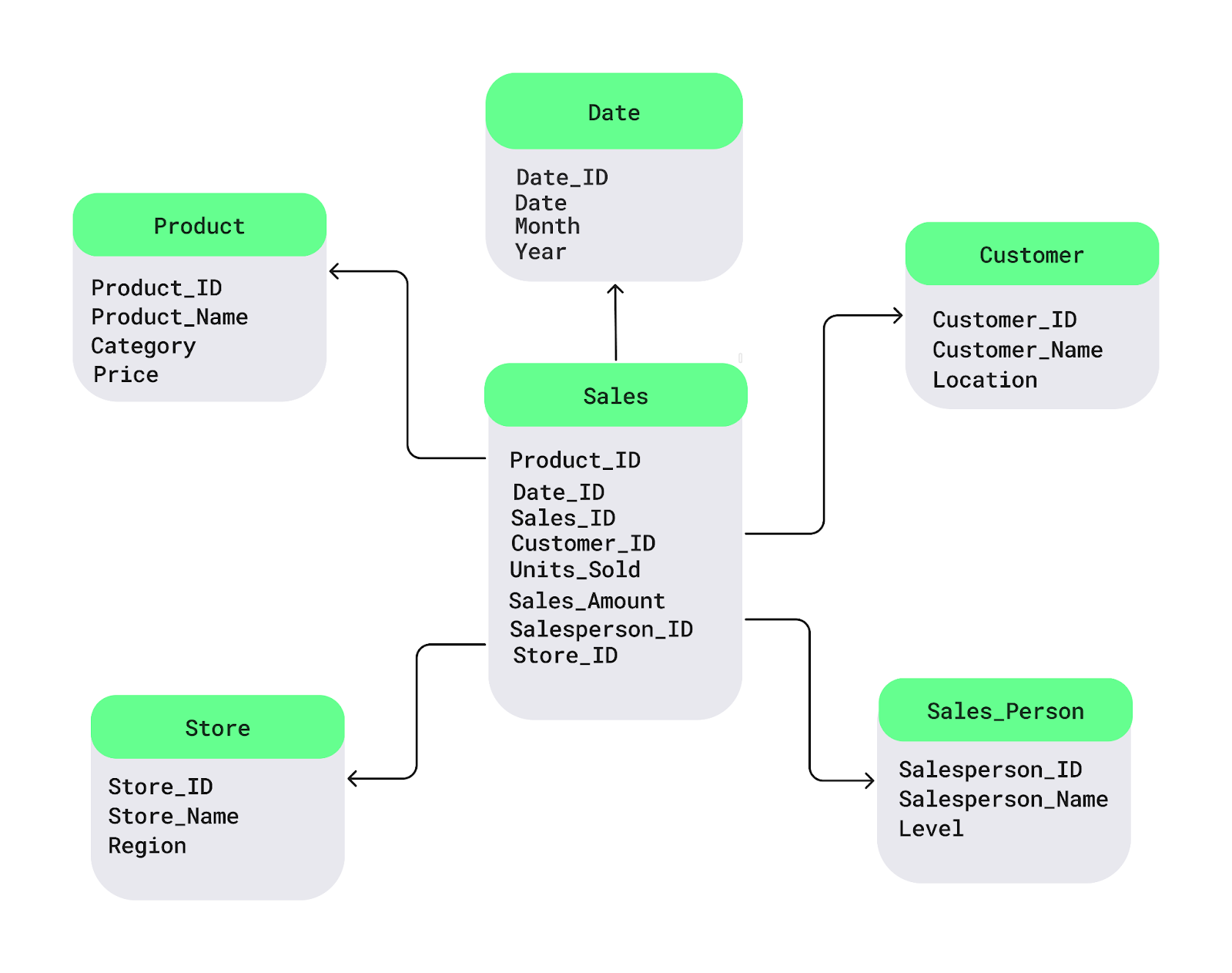
The star schema is one of the most commonly used data warehouse design patterns. It structures data into:
In a retail scenario, the fact table holds transactional sales data, while dimension tables provide context on products, customers, stores, and time. This schema improves query performance, making it ideal for environments with frequent, straightforward reporting needs.
Star schema example. Image source: DataCamp.
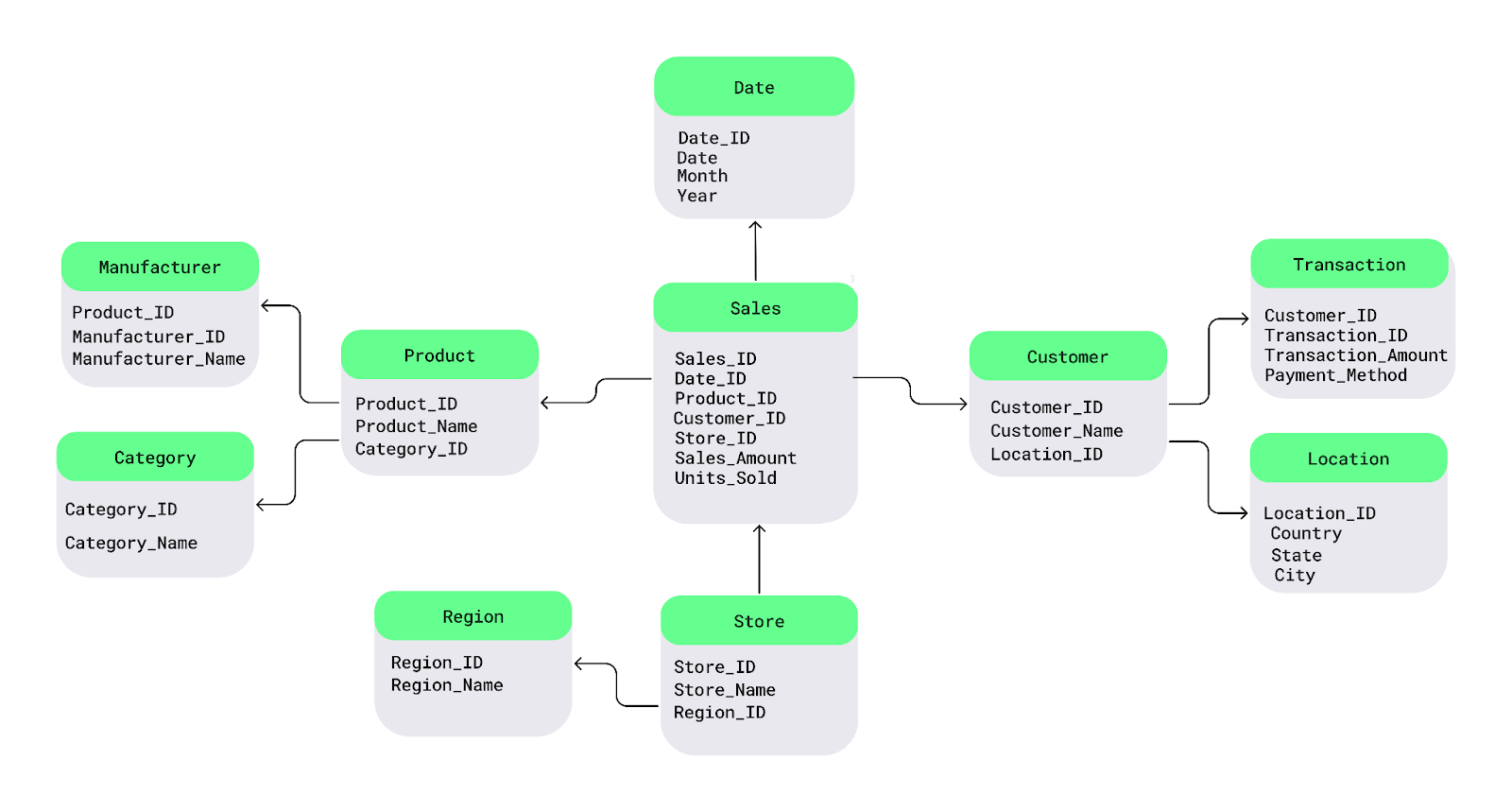
The snowflake schema is an extension of the star schema, introducing additional normalization to dimension tables. Key characteristics include:
This schema is ideal for:
While the snowflake schema conserves storage, it may lead to more intricate queries due to its highly structured nature.
Snowflake schema example. Image source: DataCamp.
Data vault modeling is a more recent design pattern focusing on flexibility, scalability, and historical data tracking. It splits the data warehouse into three core components:
This approach is highly adaptable to business process changes, making it well-suited for agile development environments.
The data vault modeling design pattern has been growing in popularity due to its ability to handle evolving data environments, accommodate changes in data sources, and support long-term scalability. It has become an ideal solution for organizations that require detailed historical tracking, frequent schema changes, or a highly scalable architecture.
Implementing best practices early on is essential to building a robust architecture. Thus, this section will cover some of the best practices to follow when constructing a high-performance data warehouse.
Data volumes and business requirements will inevitably grow over time, so it’s essential to ensure the architecture you select can handle increasing workloads. This can be done simply by using scalable storage solutions, like cloud-based platforms, and partitioning large tables for better performance.
Streamline the ETL pipeline by minimizing unnecessary data transformations, leveraging incremental loading strategies, and parallelizing ETL tasks when possible. This ensures that data is ingested, transformed, and loaded quickly without bottlenecks.
Maintaining high data quality is fundamental to a data warehouse's value. Implement strong data validation and deduplication procedures to ensure the data entering the warehouse is accurate and consistent. Regular audits and quality checks should be part of the ETL pipeline to prevent issues that could lead to incorrect analyses.
Data security should be a top priority – especially when dealing with sensitive or regulated information. There are three essential measures you must take:
To keep the data warehouse operating efficiently, regularly monitor the following:
Tools for tracking performance can help identify bottlenecks, which can help you make proactive adjustments where necessary.
Should you opt for a cloud-based data warehouse or keep everything on-premise? What are the key benefits and trade-offs of each approach? And is a hybrid solution the best of both worlds?
In this section, we’ll explore these questions and help you determine the right architecture for your needs.
Cloud-based data warehouses provide unparalleled scalability and flexibility. These platforms allow businesses to scale storage and compute resources on demand, making them ideal for handling large, dynamic data volumes without upfront infrastructure costs.
The pay-as-you-go pricing model also makes cloud solutions cost-efficient, particularly for businesses with fluctuating workloads. However, cloud environments may raise concerns about data governance and compliance, especially for highly regulated industries.
Popular cloud vendors include:
On-premises data warehouses are best suited for organizations requiring strict data control. With on-premises architecture, companies maintain complete control over their hardware and data, essential for industries like finance, healthcare, and government, where sensitive information must be protected.
But here’s the catch. While on-premises systems can offer robust performance, they often come with high upfront costs for hardware and ongoing maintenance. Scaling can also be challenging as it requires manual upgrades and hardware procurement, which is less flexible than cloud solutions.
Hybrid data warehouse architectures combine cloud and on-premises components, offering greater flexibility for organizations that need to balance security, compliance, and scalability. For example, sensitive data can be stored on-premises, while less critical data or analytics workloads can be processed in the cloud.
Hybrid architectures are particularly useful for businesses that need to transition to the cloud gradually or have specific data privacy requirements. This model provides the best of both worlds but requires careful orchestration to ensure seamless data integration between environments.
|
Feature |
Cloud-based Architecture |
On-premises Architecture |
Hybrid Architecture |
|
Scalability |
Highly scalable, on-demand resource allocation |
Limited by on-site hardware, requires manual upgrades |
Combines scalable cloud resources with on-premises control |
|
Cost |
Pay-as-you-go pricing, lower upfront costs |
High upfront investment in hardware and ongoing maintenance |
Hybrid costs, balancing cloud savings and on-premises expenses |
|
Flexibility |
Extremely flexible, ideal for dynamic workloads |
Less flexible, constrained by physical infrastructure |
Flexible, combining cloud agility with on-prem control |
|
Security & Compliance |
May raise concerns for highly regulated industries |
Complete control over data security and regulatory compliance |
Ensures compliance for sensitive data while leveraging cloud |
|
Performance |
Can vary based on the cloud provider and configuration |
High performance but dependent on hardware investments |
Balanced performance based on workload distribution |
|
Maintenance |
Minimal maintenance, managed by the cloud provider |
Requires ongoing internal IT maintenance |
Hybrid approach with cloud services handling some maintenance |
|
Use Cases |
Best for businesses with large, fluctuating data volumes |
Best for organizations with strict security and compliance needs |
Ideal for organizations transitioning to the cloud or with mixed needs |
Here’s an overview of some of the most popular data warehouse platforms used in the cloud.
Amazon Redshift is a fully managed cloud data warehouse solution for large-scale data analytics. Its architecture is based on a massively parallel processing system, which enables users to query vast datasets quickly. With its ability to scale up and down based on workload requirements, Redshift is well-suited for organizations that need cost-effective scalability and integration with other AWS services.
Google BigQuery is a serverless, highly scalable data warehouse platform built for fast, real-time analytics. Its unique architecture decouples storage and compute, which enables users to query petabytes of data without managing infrastructure. BigQuery’s ability to process large-scale analytics with minimal overhead makes it ideal for organizations with heavy data workloads that demand fast, complex queries.
Snowflake offers a multi-cluster, shared-data architecture that separates compute and storage, providing flexibility in independently scaling resources. Snowflake’s cloud-native approach allows businesses to dynamically scale workloads, thus making it an attractive option for organizations that need high flexibility and workload management across multiple cloud platforms.
Microsoft Azure Synapse Analytics is a hybrid data management platform that combines data warehousing and big data analytics. Its architecture integrates with big data frameworks like Apache Spark to provide a unified environment for managing data lakes and data warehouses. Azure Synapse offers seamless integration with other Microsoft services and is ideal for businesses with diverse data analytics needs.
|
Platform |
Architecture |
Key Features |
Use Cases |
|
Amazon Redshift |
MPP architecture, AWS ecosystem |
Scalable, fast queries, AWS integration |
Large-scale analytics, cloud-native applications |
|
Google BigQuery |
Serverless, decoupled storage and compute |
Real-time analytics, low infrastructure |
Fast analytics, real-time data processing |
|
Snowflake |
Multi-cluster, shared-data architecture, cross-cloud (AWS, Azure, GCP) |
Compute-storage separation, dynamic scaling |
Flexible scaling, cross-cloud platform workloads |
|
Azure Synapse |
Hybrid, big data integration |
Unified analytics, Spark integration |
Hybrid data management, integration with Microsoft tools |
While data warehouses provide powerful capabilities for organizations to analyze and manage vast amounts of data, they also come with inherent challenges.
Here are some of the most significant challenges and solutions to consider when designing and maintaining a data warehouse architecture.
Organizations collect data from multiple sources, each with different formats, schemas, and structures, making integration a complex challenge. Key considerations include:
To address these challenges, businesses need flexible ETL processes and data management tools that support diverse data formats and seamless integration across platforms.
As data warehouses grow, maintaining high query performance becomes a challenge. Large-scale operations must efficiently process millions—or even billions—of rows while avoiding slow queries, high costs, and inefficient resource usage.
Key optimization strategies include:
As more users access the data warehouse, efficient resource allocation becomes critical. Key considerations include:
By implementing these strategies, organizations can ensure that their data warehouse scales effectively and maintains high performance as data volume and user activity grow.
As data warehouses store increasing amounts of sensitive information, strong governance, and security measures are essential to prevent breaches, ensure compliance, and maintain data integrity.
In this article, we explored key components of data warehouse architecture, common challenges, and strategies for overcoming them. Ultimately, a well-designed data warehouse does more than store data—it empowers organizations to make informed, data-driven decisions that drive growth and innovation.
Want to dive deeper into data architecture and best practices? Check out these resources:
Learn more about data engineering with these courses!
Course
Course
Course
blog
Kurtis Pykes
13 min
blog
Joyce Chiu
3 min
blog
Moez Ali
15 min
blog
Kurtis Pykes
9 min
blog
Sanjana Putchala
10 min
blog
Bex Tuychiev
12 min
